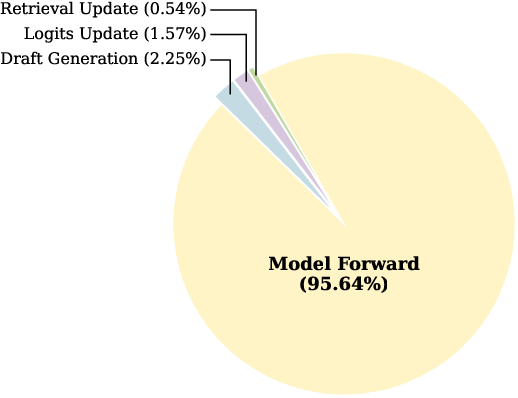
- The paper introduces RACER, which unifies retrieval-augmented drafting with logits-driven speculation to reduce inference latency in LLMs.
- The methodology leverages a dynamic logits tree alongside a capacity-bounded AC automaton for efficient candidate generation and verification.
- Experimental results show RACER consistently achieves MAT > 3 and speedups above 2× across multiple benchmarks, outperforming previous methods.
Retrieval-Augmented Contextual Rapid Speculative Decoding (RACER): An Expert Analysis
Motivation and Problem Context
The inherent sequential nature of autoregressive decoding in LLMs incurs high inference latency, since each token is generated and verified in a stepwise fashion. Speculative decoding methods address this inefficiency by proposing multiple candidate tokens in parallel (drafting phase) and subsequently verifying them with the full model (verification phase). However, prior training-free, model-free speculative decoding techniques exhibit distinct shortcomings: retrieval-based approaches suffer from brittleness due to their reliance on exact pattern matches and inability to generalize, while logits-based drafts (e.g., last-logit/copy-logit reuse) provide extrapolative capacity but lack structural context, limiting their precision and scope.
In response to these limitations, this work proposes RACER, a method designed to unify the complementary strengths of retrieval-augmented and logits-driven speculative drafting. RACER merges structural anchors from context-based retrieval with flexible, model-derived token speculation, thereby delivering a robust, training-free, and plug-and-play speculative decoding framework.
Methodology
RACER integrates two principal components: a Logits Tree leveraging predictive distributions from past model logits, and a contextually adaptive Retrieval Tree built on a capacity-bounded Aho–Corasick (AC) automaton with LRU-based eviction. Draft tokens from both components are unified and passed through the standard guess-and-verify scheme with the full LLM for token acceptance.
Logits Tree Construction
The Logits Tree is a recursive draft expansion structure, which proposes candidate continuations beyond the current token by iteratively reusing previous logits in a topology guided by copy-logit and last-logit strategies. Copy-logit reuse leverages the logits associated with the nearest matching prior token, ensuring semantically aligned projections for speculative expansion. Empirical analysis demonstrates the superiority of copy-logit over last-logit, with notably sharper and heavy-tailed acceptance distributions—i.e., most accepted tokens concentrate within the top few ranks.

Figure 1: The last-logit node (white) produces both the next-token sample and the draft tokens immediately after it. The copy-logit node (green) marks the same token ID as the next-token, whose logit is reused to approximate the next-token's logits when generating subsequent draft tokens.
The draft tree’s breadth and depth are adaptively pruned based on empirical cumulative acceptance trends, leading to a front-loaded branching structure (Figure 2). This approach allows for more aggressive speculation at shallower depths while constraining exploration at deeper layers, optimizing the allocation of the verification budget.
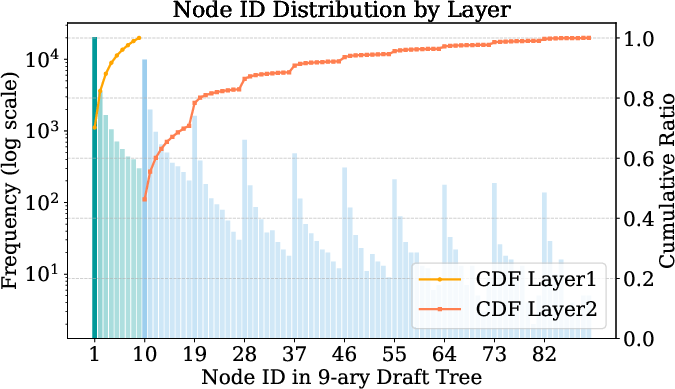
Figure 2: Analogy experiments with a fixed 9-ary draft tree of height 3.
Retrieval Tree via Bounded AC Automaton
The retrieval component maintains a capacity-limited AC automaton (Figure 3), dynamically updated with n-gram patterns extracted from the evolving context. The automaton supports efficient matching via failure links and robust LRU-based eviction for unused states, ensuring model memory remains bounded and focused on highly relevant context subsequences. Insertion and update operations achieve O(1) time complexity, compatible with high-throughput settings.
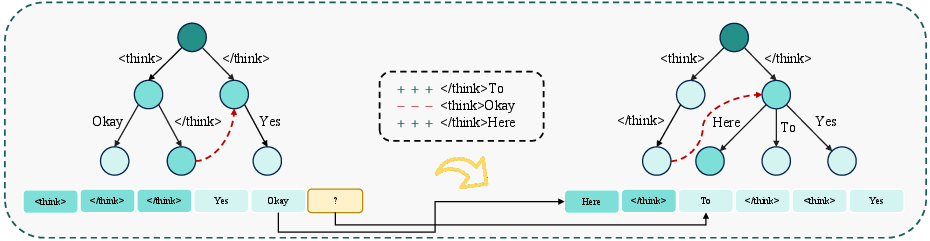
Figure 3: Illustration of the LRU-based eviction strategy in RACER’s retrieval automaton.
For each decoding step, border nodes of matched depth ≥2 are identified in the automaton, from which the most frequent continuations are pooled and prioritized.
Unified Drafting and Verification
The end-to-end RACER workflow is depicted in Figure 4: retrieval-based candidates are proposed first (due to their high reliability when available), and the residual capacity is allocated to logits-based draft expansion. All candidate tokens are merged into a unified trie and presented for verification. This hybrid design dramatically enhances the rate of accepted speculative tokens per verification pass, improving both throughput and latency.
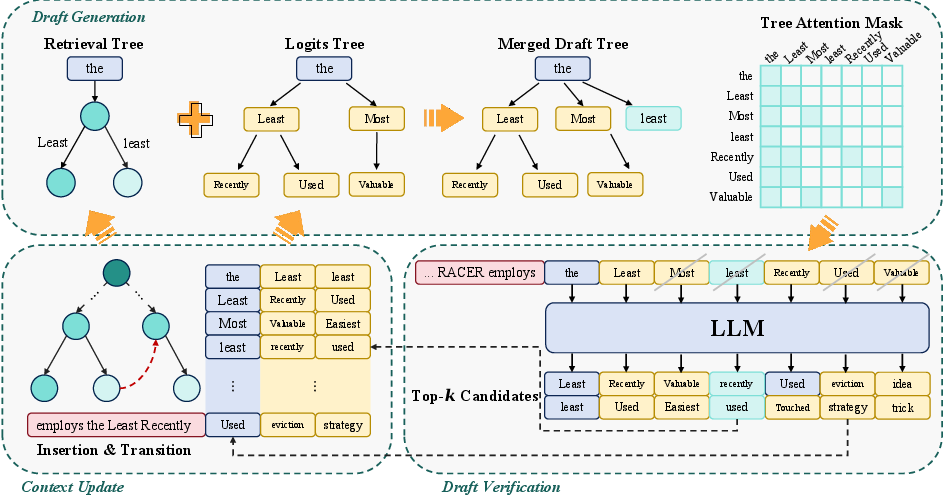
Figure 4: Overview of RACER’s drafting and verification pipeline, showing the integration of retrieval-based and logits-based speculative expansion.
Experimental Results
A comprehensive suite of experiments is conducted on multiple model families (Vicuna, LLaMA3.1, OpenPangu, Qwen3) and standard benchmarks (Spec-Bench, HumanEval, MGSM-ZH). The key metrics are mean accepted tokens per speculative iteration (MAT) and end-to-end speedup over default autoregressive decoding.
Key findings:
Ablation studies validate the necessity of both components: removal of logits-driven expansion significantly degrades performance, while exclusion of retrieval is most detrimental in domains with high context redundancy, such as mathematical reasoning tasks. Integration strategies that merge both sources according to a union-followed-by-verification paradigm yield superior throughput compared to fixed capacity splits or hard fallback switching.
Accepted token length distributions (Figure 6) reveal RACER’s balanced speculative profile: retrieval-only methods are sparse and high-variance; logits-only methods are narrow and consistent but limited in scope; RACER consistently achieves elevated accepted lengths per iteration without outlier-induced instability.
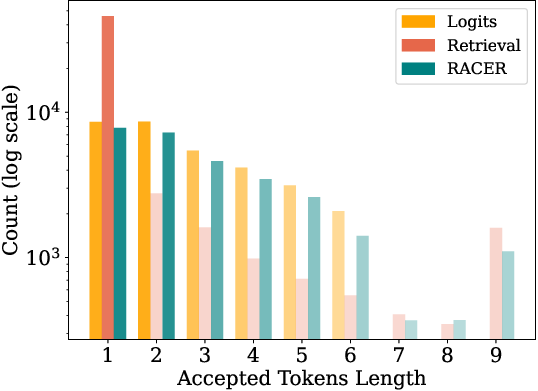
Figure 6: Comparison of accepted token lengths with Vicuna-7B across three settings: Logits-only decoding, Retrieval-only decoding, and RACER.
Theoretical and Practical Implications
RACER’s hybrid speculative mechanism bridges the gap between strictly memorized pattern completion and model-internal distributional heuristics. By efficiently leveraging both "seen" (retrieval) and "unseen" (speculative logits) cues, it robustly accommodates a broad range of sequence types—including highly repetitive, structurally diverse, and long-horizon reasoning tasks. This architectural agnosticism and lack of training-time coupling represent a marked improvement in the scalability and portability of speculative methods.
The study also validates the principle that shallow, front-heavy speculative expansion (copy-logit with aggressive top-k pruning) and capacity-limited dynamic context retrieval represent complementary inductive biases. Together, these achieve both breadth and depth in speculative token acceptance while preserving predictable, bounded computation and memory.
RACER’s design is directly applicable to real-world LLM deployments with strict latency constraints and limited compute resources. Its plug-and-play nature also points to seamless compatibility with programmable inference pipelines, distributed decoding strategies, and future multimodal extensions.
Future Directions
Prospective research directions include:
- Extension to multimodal and multilingual speculative decoding via cross-modal retrieval buffers;
- Integration with parallel and distributed speculative pipelines, leveraging hardware-agnostic automaton sharding strategies;
- Theoretical characterization of retrieval–logit synergy in context adaptation and error accumulation mitigation.
Conclusion
RACER establishes a robust and practical foundation for training-free, model-agnostic speculative decoding in LLMs. By judiciously fusing retrieval-based context anchors with dynamically constructed, logit-based draft trees, RACER delivers state-of-the-art acceptance rates and inference acceleration without the complexity or fragility of model-based draft generators. This approach addresses key limitations in the speculative decoding literature and outlines a compelling path toward scalable, high-efficiency LLM deployment for diverse domains and workloads.