- The paper introduces FSDETR, a novel DETR-based detector that integrates frequency-domain modeling and spatial feature enhancement to improve small object detection.
- It employs a hybrid encoder with SHAB, DA-AIFI, and a Frequency-Spatial Feature Pyramid Network to efficiently preserve fine-grained details in cluttered scenes.
- Ablation studies show that each module contributes to performance gains on benchmarks like VisDrone and TinyPerson, maintaining strong detection with only 14.7M parameters.
FSDETR: Frequency-Spatial Feature Enhancement for Small Object Detection
Motivation and Context
Small object detection in dense or complex visual environments—such as UAV imagery or long-range pedestrian scenes—remains technically challenging due to information loss from deep downsampling, heavy background interference, and severe mutual occlusion. Standard convolutional and Transformer-based detectors suffer pronounced degradation in the representation of objects below 32×32 pixels, weakening localization and classification performance. Existing solutions rely on either extensive multi-scale feature fusion or spatially-attuned architectures, often with limited success for extremely tiny objects or at significant computational expense.
The paper "FSDETR: Frequency-Spatial Feature Enhancement for Small Object Detection" (2604.14884) introduces FSDETR, integrating frequency-domain modeling with efficient spatial representations into a DETR-style architecture. The approach leverages the complementary strengths of spatial and frequency representations to preserve fine-grained cues, robustly localizing small targets with low parameter overhead.
FSDETR Architecture Overview
FSDETR augments the RT-DETR backbone by embedding specialized modules for detailed feature preservation and advanced cross-domain fusion. The core pipeline comprises:
- Hierarchical Backbone: An enhanced CSPNet with C2f blocks and embedded Spatial Hierarchical Attention Blocks (SHAB).
- Efficient Hybrid Encoder: Integrates Deformable Attention-based Intra-scale Feature Interaction (DA-AIFI) and a Frequency-Spatial Feature Pyramid Network (FSFPN), which centers on the Cross-domain Frequency-Spatial Block (CFSB).
- Decoder and Head: Follows the DETR paradigm with an uncertainty-minimal query selection and standard Transformer-based decoding.
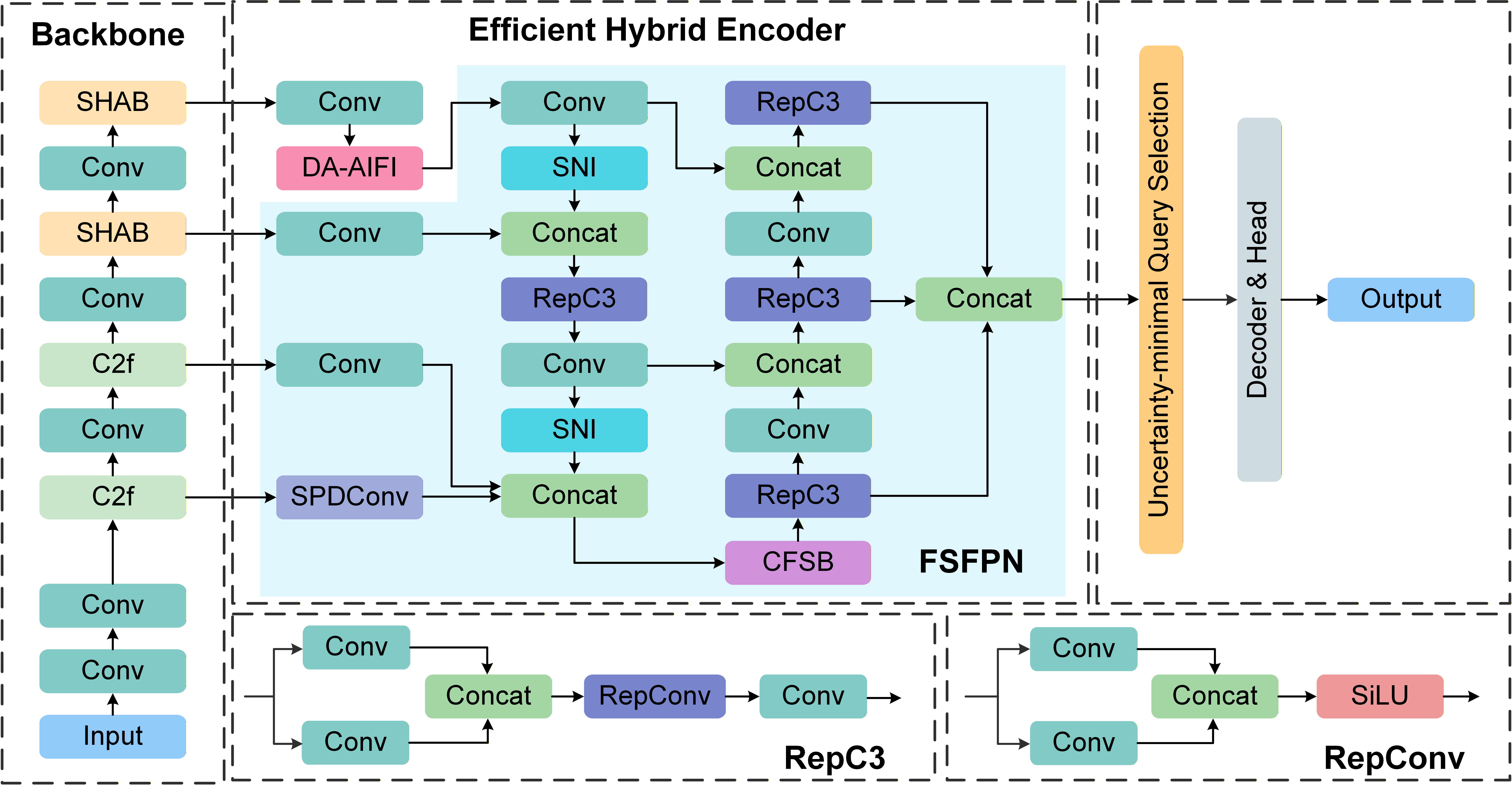
Figure 1: The overall architecture of FSDETR, showing the integration of SHAB, DA-AIFI, FSFPN, and the cross-domain fusion pipeline.
This design prioritizes efficient aggregation of both spatial and frequency cues across multiple scales, with minimal increase in compute or parameter count (14.7M parameters).
Key Components
Spatial Hierarchical Attention Block (SHAB)
SHAB is embedded in deep backbone stages to address spatial feature erosion due to layered downsampling. Utilizing a refined C2f topology, SHAB applies channel-wise partitioning where only half the channels experience targeted self-attention, enabling long-range structural modeling with reduced complexity.
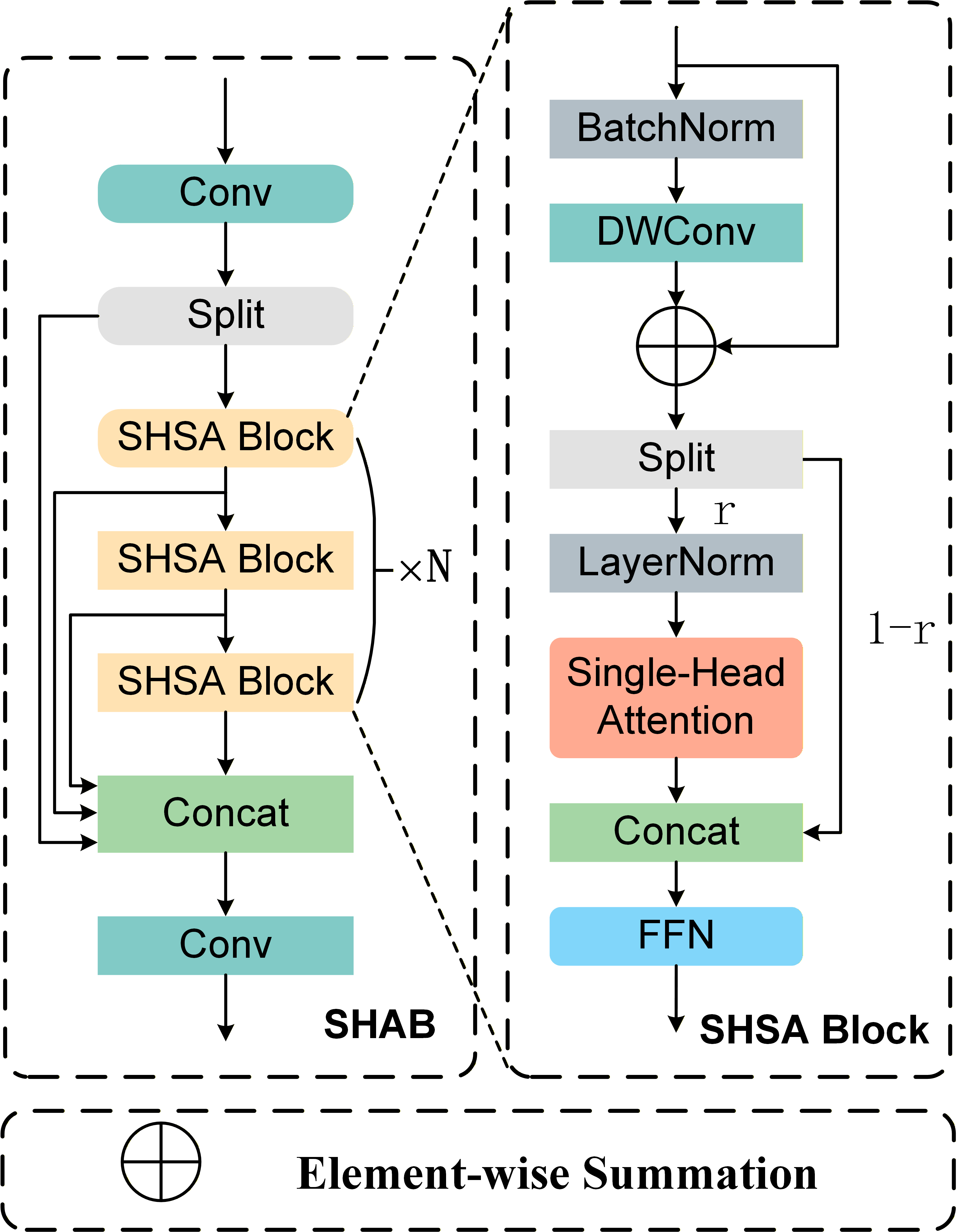
Figure 2: Structure of SHAB, leveraging a partitioned attention mechanism to enhance long-range semantics with limited overhead.
The block sustains high-fidelity gradient flow through dual-branch pathways, improving context aggregation for tiny, occluded, or visually ambiguous objects.
DA-AIFI applies deformable attention over feature maps, sampling adaptively around reference points instead of the global spatial grid. Each output aggregates a learnable, sparse set of context-dependent neighbors, permitting non-uniform geometric alignment and noise suppression. This enhances the detector’s focus on small, information-rich regions, yielding better localization amid background clutter and scale shifts.
Frequency-Spatial Feature Pyramid Network (FSFPN)
The FSFPN reconceptualizes the traditional feature pyramid as a restoration and enhancement pipeline, targeting high-frequency loss and spatial aliasing.
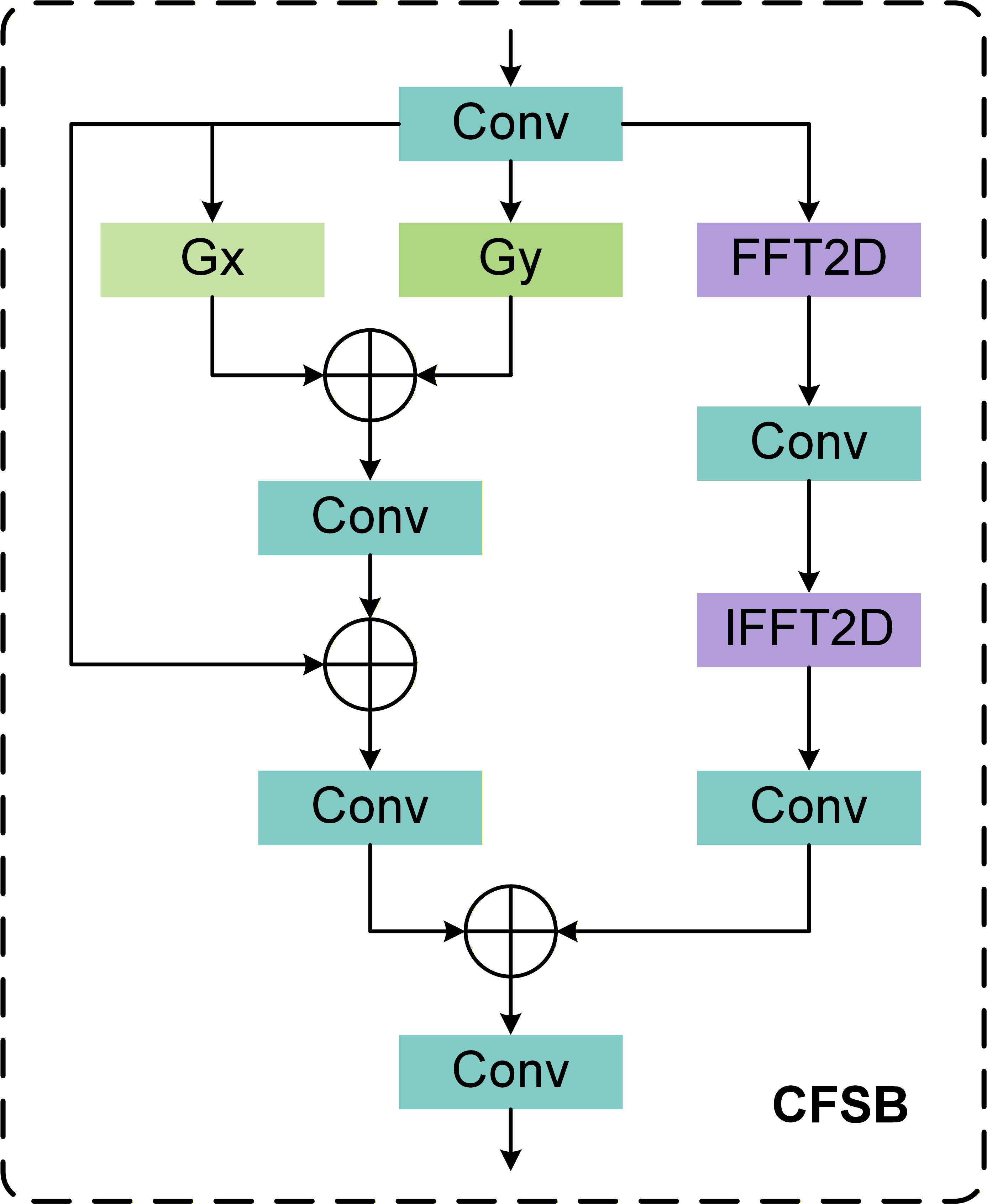
Figure 3: Structure of the Cross-domain Frequency-Spatial Block (CFSB), with parallel spatial and frequency branches followed by adaptive fusion.
CFSB—the core module—operates two parallel branches:
- Spatial Branch: Applies Scharr filters (horizontal and vertical) and residual convolutions to emphasize edge structures and preserve object contours.
- Frequency Branch: Passes feature maps through DFT, applies convolutional masking (learnable), and reconstructs via IDFT, amplifying texture cues and suppressing background noise.
Adaptive cross-branch fusion enables integrated exploitation of fine locational information and global textural patterns, crucial for small-object discrimination in challenging settings.
Quantitative and Qualitative Results
On VisDrone 2019, FSDETR with 14.7M parameters achieves 13.9% APS, surpassing both RT-DETR-R18 (11.3% APS, 20.0M params) and several larger-scale detectors (e.g., YOLOv8m, 9.0% APS) with lower compute. On TinyPerson, it records 31.85% AP50tiny1 and a strong 48.95% AP50tiny, outperforming both general-purpose and specialized methods.
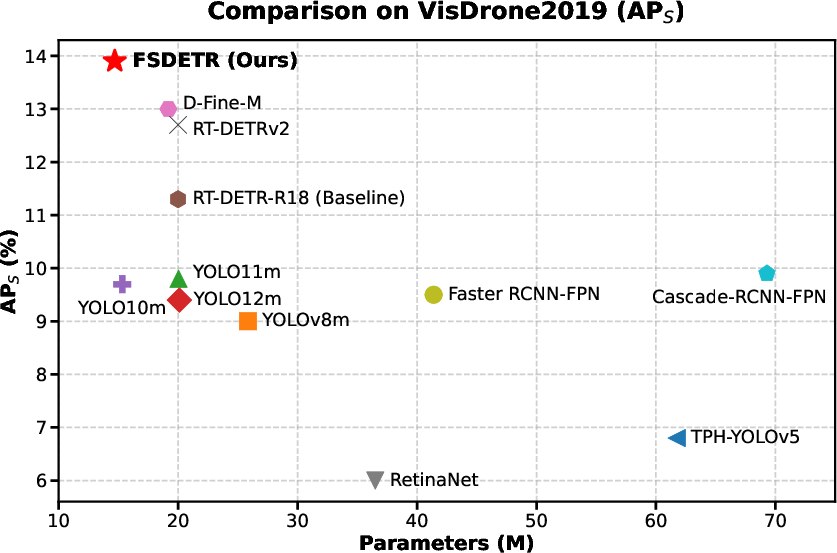
Figure 4: FSDETR surpasses competing approaches on VisDrone2019 in APS for small object detection, especially among models with comparable parameter sizes.
Visual Error Analysis
Qualitative results on VisDrone and TinyPerson reveal that FSDETR substantially reduces false negatives and false positives in high-density and low-contrast regions, clearly outperforming RT-DETR, YOLO11m, and D-Fine-M.
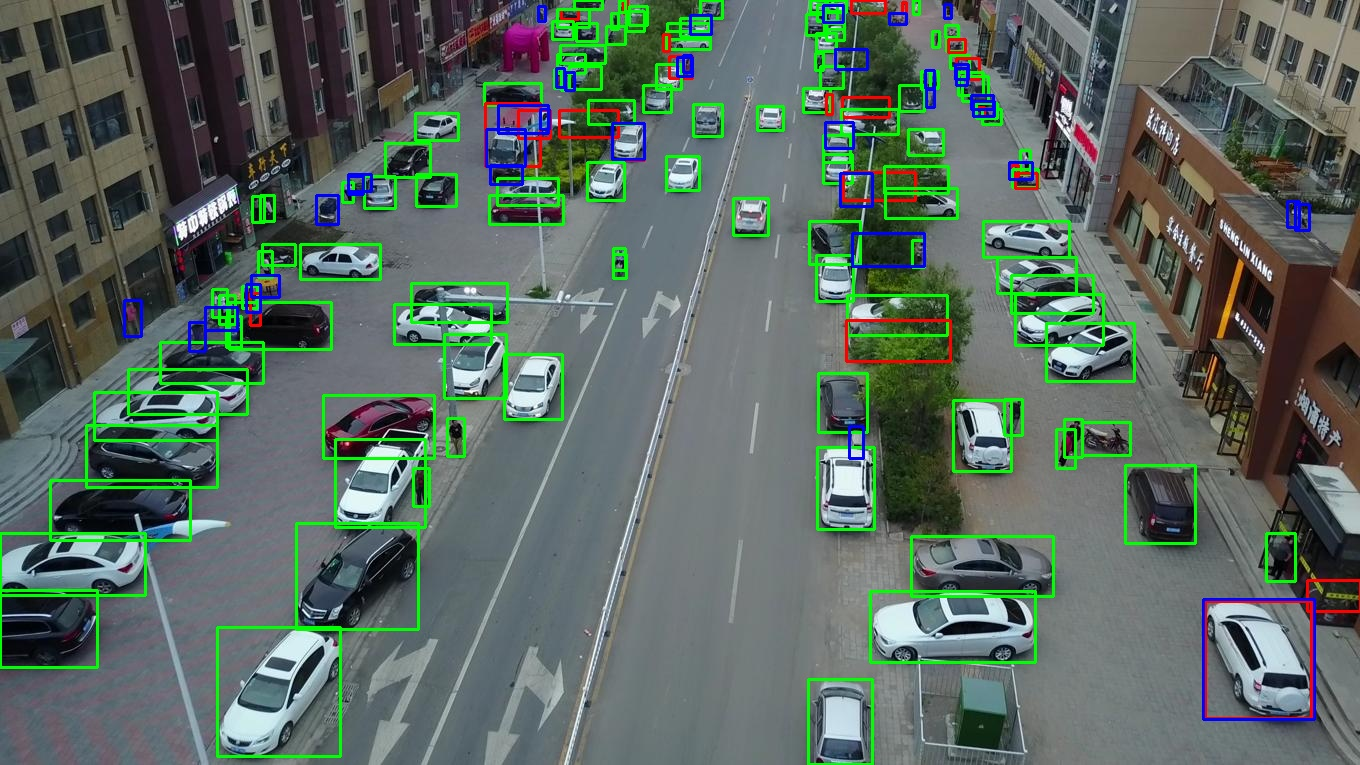
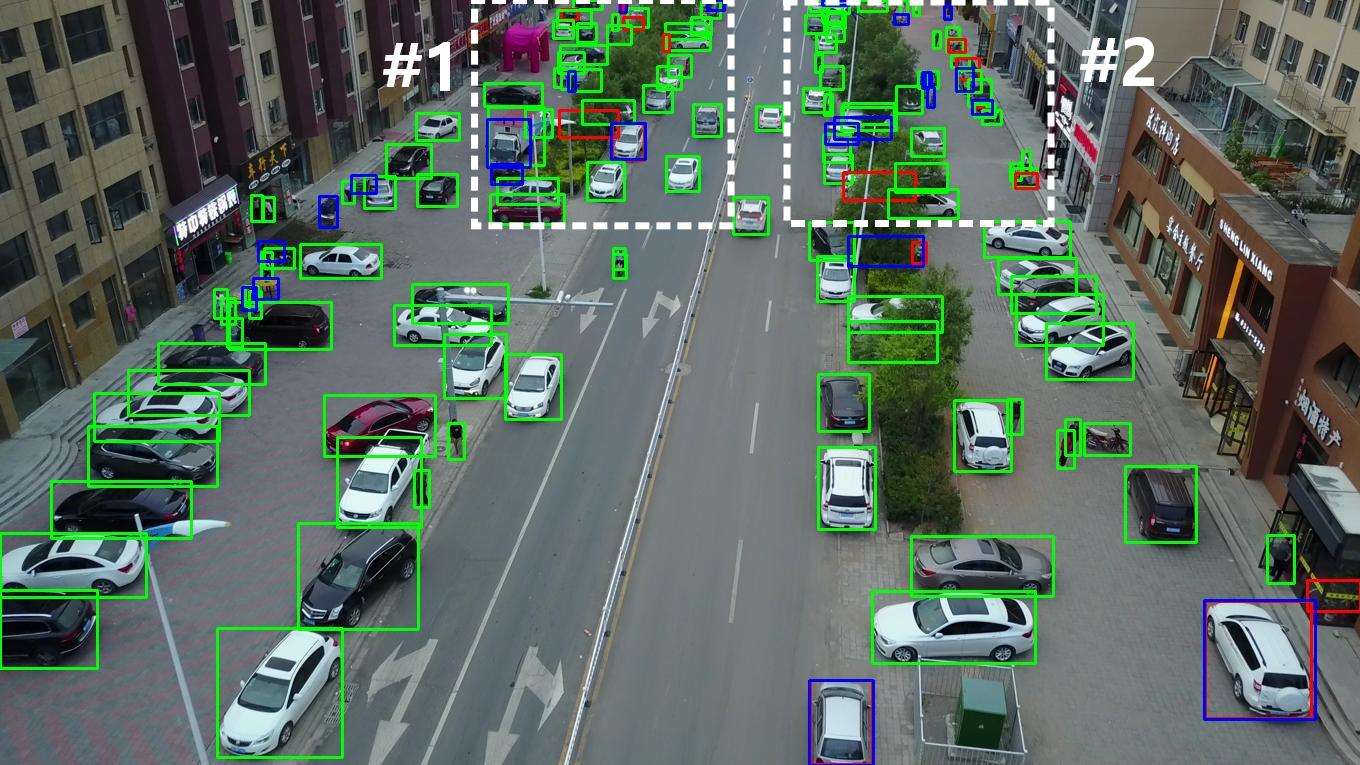
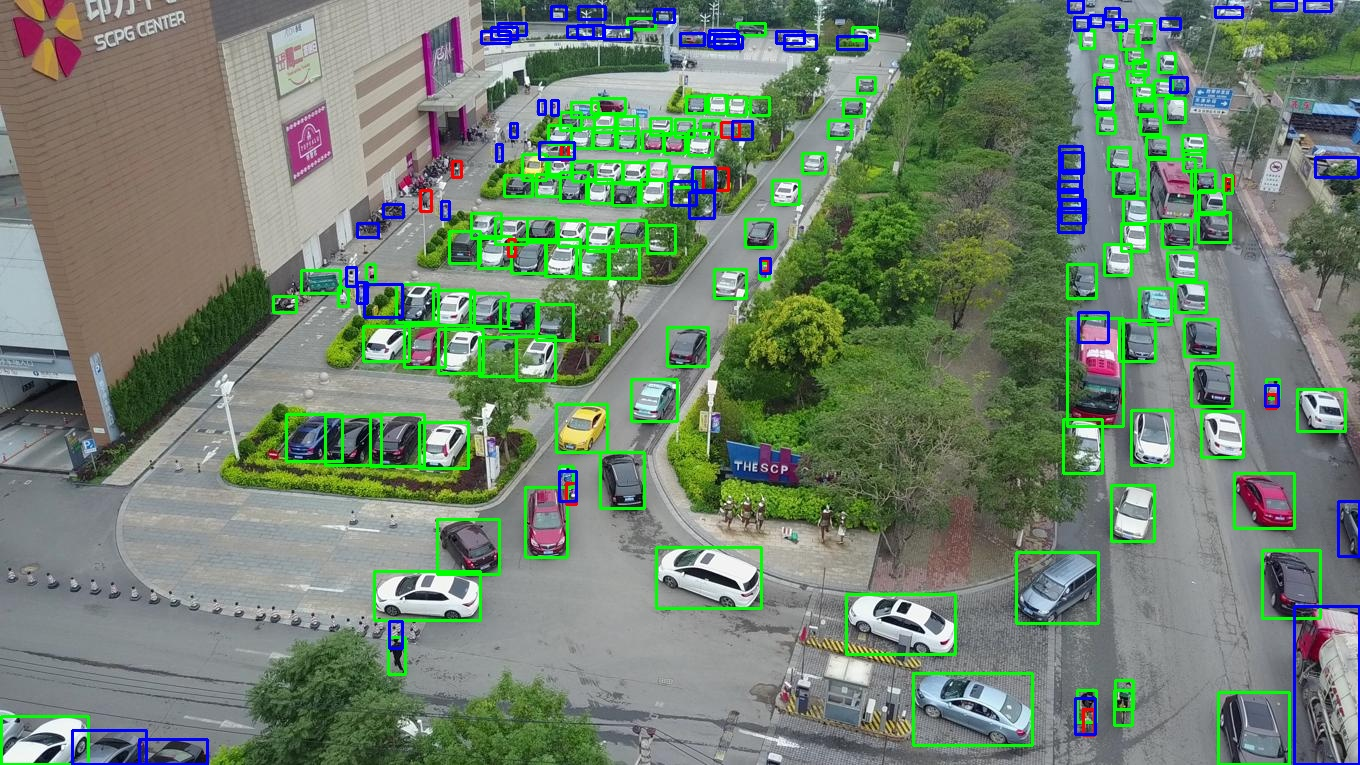
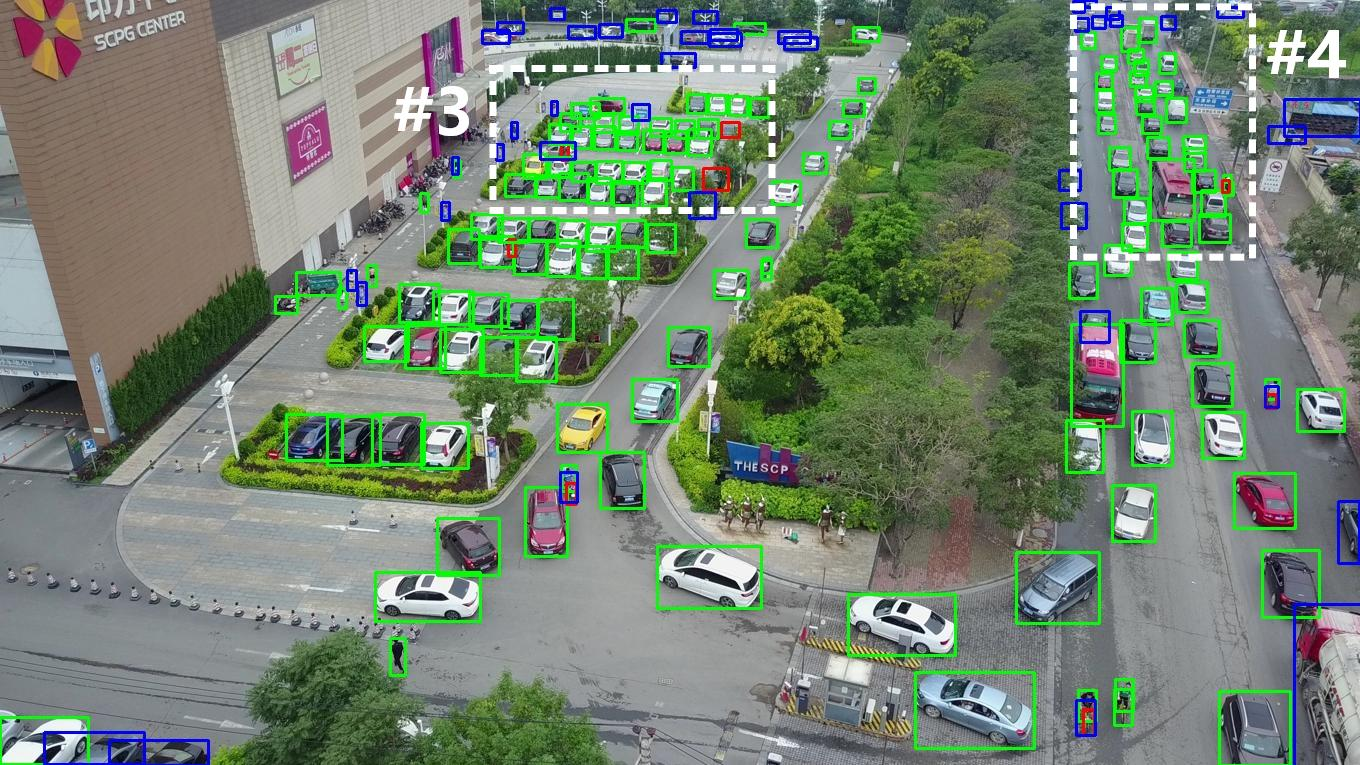
Figure 5: On VisDrone 2019, FSDETR sharply reduces missed detections (blue) and excessive false positives (red) in dense traffic scenes.

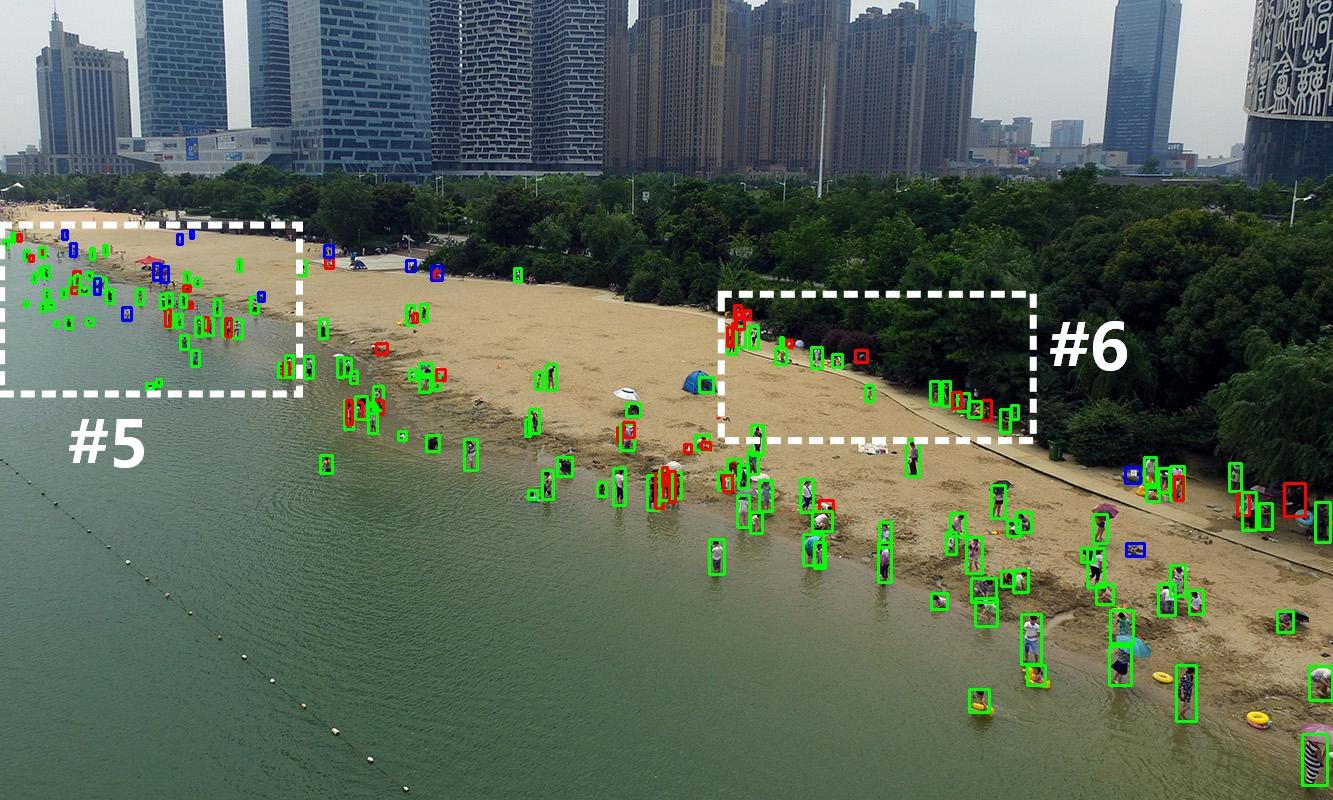


Figure 6: In low-contrast, tiny-target environments (TinyPerson), FSDETR localizes small objects more precisely and lowers false alarms relative to competing methods.
Ablation Analysis
Component ablation demonstrates that SHAB improves AP50 by 1.2%, DA-AIFI by 0.8%, and the addition of FSFPN (CFSB) elevates APS by 1.4%. The complete system achieves the highest small-object performance and overall detection scores, highlighting the complementary impact of spatial, deformable, and frequency-domain enhancements.
Theoretical and Practical Implications
FSDETR’s architecture validates that explicit frequency-spatial collaboration, not merely stacked convolutions or Transformers, is essential for high-fidelity small object detection. Frequency-domain feature processing (via CFSB and DFT-based masking) robustly complements spatial attention, directly addressing the loss mechanisms endemic to deep networks. These mechanisms may generalize to other domains requiring precise small-scale representation (e.g., biomedical imaging, satellite analytics), and can inform future hybrid modeling in real-time, memory-constrained vision systems.
The efficient design, modularity, and strong performance suggest FSDETR principles could underpin new generations of lightweight detection frameworks or be extended to video/temporal domains (by coupling with frequency-temporal modeling and further deformable data association).
Conclusion
FSDETR advances small object detection by deeply coupling spatial attention, deformable intra-scale feature extraction, and frequency-domain modeling in a parameter-efficient DETR-based architecture. Strong empirical performance on VisDrone 2019 and TinyPerson benchmarks, validated by ablation and qualitative analysis, underscores the necessity and efficacy of frequency-spatial feature integration. These architectural concepts provide a promising basis for future investigation into hybrid-domain, lightweight, and robust small object recognition networks.