- The paper introduces retention-prioritized gradient synthesis that redefines LLM unlearning through an asymmetric two-task framework emphasizing retention over forgetting.
- It leverages PCGrad and SAGO to manage gradient conflicts effectively, achieving up to 96% retention on benchmarks like WMDP Bio with minimal loss in forgetting strength.
- The study provides both theoretical and empirical validation for improved trade-offs between targeted knowledge removal and overall model performance.
Retention-Prioritized Gradient Synthesis for LLM Unlearning
The paper "Modeling LLM Unlearning as an Asymmetric Two-Task Learning Problem" (2604.14808) introduces an asymmetric two-task perspective for LLM unlearning, where retention constitutes the primary objective and forgetting is treated as an auxiliary objective. This framing diverges from the loss-balancing paradigm commonly found in classical multi-task learning (MTL), emphasizing retention as the anchor while strategically injecting forgetting gradients to minimize harm to model utility. In this context, machine unlearning aims to remove targeted knowledge (forget set) from an LLM while retaining general capabilities (retain set), addressing fundamental challenges posed by dual-use risks, privacy violations, and jailbreak vulnerabilities.
Retention-Prioritized Gradient Synthesis: PCGrad and SAGO
The authors propose a modular gradient synthesis framework, instantiating it with two conflict-aware techniques: module-wise PCGrad and Sign-Align Gradient Optimization (SAGO). PCGrad addresses gradient conflicts by projecting the forget gradient orthogonally onto the retain gradient, preventing antagonistic updates and prioritizing retention. SAGO refines this approach by implementing element-wise sign alignment: forgetting gradients are gated to pass through only when their signs agree with retain gradients, otherwise the retain gradient is used exclusively. This ensures strict non-negative cosine similarity between the synthesized update and the retain direction, effectively eliminating gradient opposition and preserving directional fidelity.
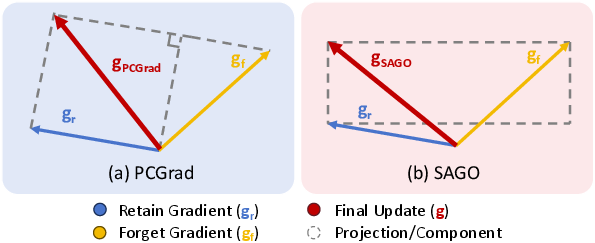
Figure 1: Illustration of final gradient updates in PCGrad and SAGO, highlighting SAGO's strict sign-constrained alignment with the retain gradient gr.
Theoretical analysis confirms that both PCGrad and SAGO guarantee acute alignment with the retain gradient, but SAGO achieves strictly tighter alignment and better orthogonality between forget and retain components due to element-wise gating.
Empirical Evaluation on WMDP and RWKU
Experiments were conducted on WMDP (biosecurity/cybersecurity) and RWKU benchmarks using open LLMs (Zephyr-7B-beta, LLaMA3-8B-Instruct). Baselines included methods optimized solely for forgetting (GA/NPO/SimNPO) and variants that combined forget and retain objectives (GradDiff, NPO+GD, SimNPO+GD). The retention-prioritized synthesis methods (PCGrad, SAGO) were applied atop these baselines.
Numerical results demonstrate substantial retention gains with retention-prioritized synthesis. On WMDP Bio, integrating SimNPO with retention-prioritized gradient synthesis improves MMLU from 44.6% (naive baseline) to 94.0% (+PCGrad) and 96.0% (+SAGO), with minimal compromise in forgetting strength—establishing an improved Pareto frontier.
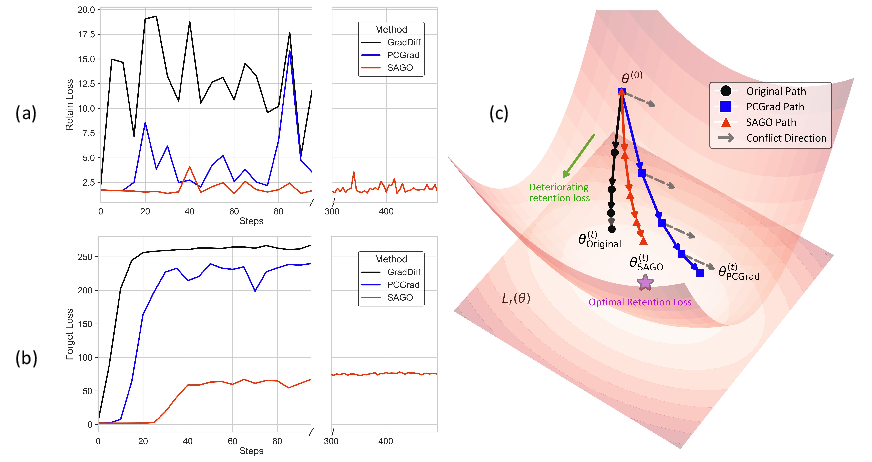
Figure 2: SAGO outperforms GradDiff and PCGrad by maintaining lower retain loss and higher forget loss, reducing gradient conflicts and improving retention during unlearning.
Pareto visualizations indicate that SAGO consistently expands the performance envelope: at fixed levels of forgetting effectiveness, SAGO achieves higher retention across both WMDP and RWKU tasks.
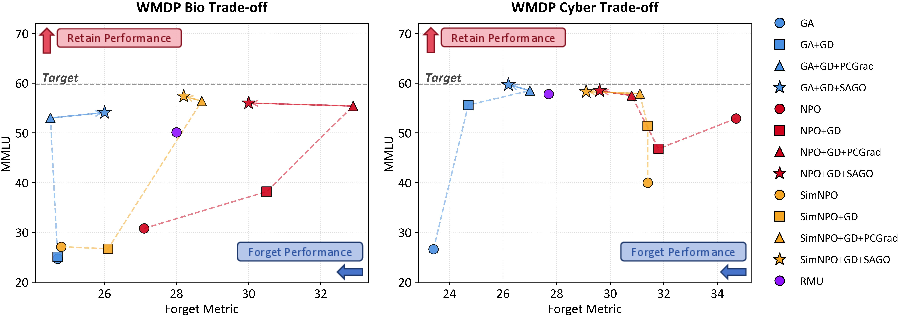
Figure 3: SAGO consistently pushes the Pareto frontier upward for comparable forgetting effectiveness in WMDP Bio and Cyber, outperforming baseline and PCGrad variants.
On RWKU, SAGO strictly dominates baselines and PCGrad, producing an improved trade-off frontier.
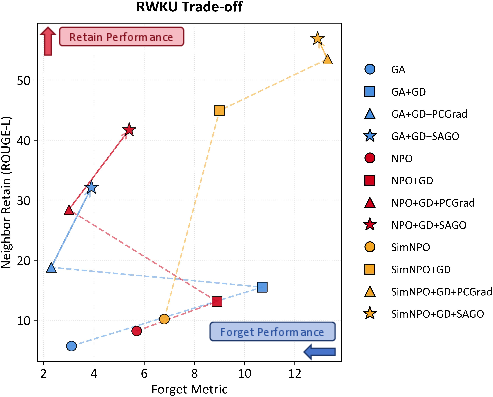
Figure 4: Trade-off between forgetting and retention scores on RWKU, showing SAGO's expansion of the performance frontier over PCGrad and base methods.
Gradient geometry analysis further corroborates that SAGO yields the highest cosine similarity between the final update and the retain gradient, empirically validating retention-prioritized optimization.
Practical and Theoretical Implications
This work underscores that reshaping gradient geometry—rather than re-balancing losses—is key to mitigating unlearning-retention trade-offs in LLMs. Retention-prioritized synthesis (especially SAGO) preserves model utility while ensuring targeted knowledge removal, without introducing antagonistic updates. This approach is modular and extensible, adaptable to various unlearning objectives and architectures, reinforcing inherent safety guarantees even under adversarial conditions.
Practically, the proposed methods are applicable to regulatory and privacy scenarios, improving compliance with data removal mandates by minimizing collateral utility loss. Theoretically, the asymmetric framing of the unlearning problem paves the way for future research into fine-grained, conflict-aware optimization in continual learning, privacy-preserving AI, and robust alignment.
Speculation on Future Developments
Advances in retention-prioritized gradient synthesis may generalize to multimodal and code LLMs, broader domains, and settings requiring real-time unlearning or ultra-low resource constraints. Further exploration into hierarchical and modular conflict mitigation techniques, coupled with efficient per-parameter gating strategies, could refine utility preservation and enable scalable, reliable knowledge editing. Integration with inference-time unlearning and self-distillation frameworks may synergistically enhance practical utility in compliance, safety, and customization contexts.
Conclusion
The asymmetric two-task perspective and retention-prioritized gradient synthesis framework articulated in this work provide a robust, modular paradigm for LLM unlearning. SAGO, with its strict sign alignment, achieves superior retention trade-offs, substantiated by both theoretical and empirical evidence. This research advances principled approaches to conflict mitigation in unlearning, with significant implications for privacy, safety, and adaptive LLM deployment.