- The paper presents an integrated framework that fuses object detection, LiDAR-enhanced depth estimation, and segmentation tailored for railway environments.
- It leverages DDRNet23-Slim, YOLOv11x, and MiDaS v3.1, achieving high accuracy in track segmentation (accuracy 0.99) and reliable detection (mAP@50 0.78).
- The modular design enables sensor fusion with temporal filtering, yielding metrically accurate distance estimates with MAE as low as 0.63 m.
Modular Multi-Sensor Obstacle Detection for Railway Environments
Introduction
The paper "Integrating Object Detection, LiDAR-Enhanced Depth Estimation, and Segmentation Models for Railway Environments" (2604.14781) presents a comprehensive, end-to-end framework for obstacle detection in railway scenarios, explicitly addressing integrated object detection, track segmentation, and absolute distance estimation by leveraging both image and LiDAR data. The modular pipeline is agnostic with respect to neural backbone choices, facilitating future extensibility. This essay reviews the key architectural components, discusses empirical performance, and situates the approach within existing literature.

Figure 1: Example output of the framework with instance segmentation, class coloring, distance annotation, and detection confidence for obstacles within the expanded track mask.
Literature Context and Motivation
Railway obstacle detection diverges significantly from automotive perception due to longer braking distances, higher safety requirements, and the scarcity of annotated real-world datasets. Prior work has frequently isolated subtasks (track detection, object detection, or relative depth estimation), often relying solely on monocular images and using bounding box-based object localization, which is suboptimal for accurate distance computation due to the inclusion of background pixels.
Multi-modal sensor fusion (camera + LiDAR or radar) and modular system design have shown benefits in the automotive domain, but are less explored in the railway context. The absence of publicly available datasets with dense ground-truth depth further hampers methodological development and reproducibility.
Modular Framework Architecture
The proposed system integrates four modular components: (1) input layer (camera + LiDAR streams), (2) a neural block comprising track segmentation, object detection, and monocular depth estimation, (3) data fusion and distance estimation, and (4) visualization.
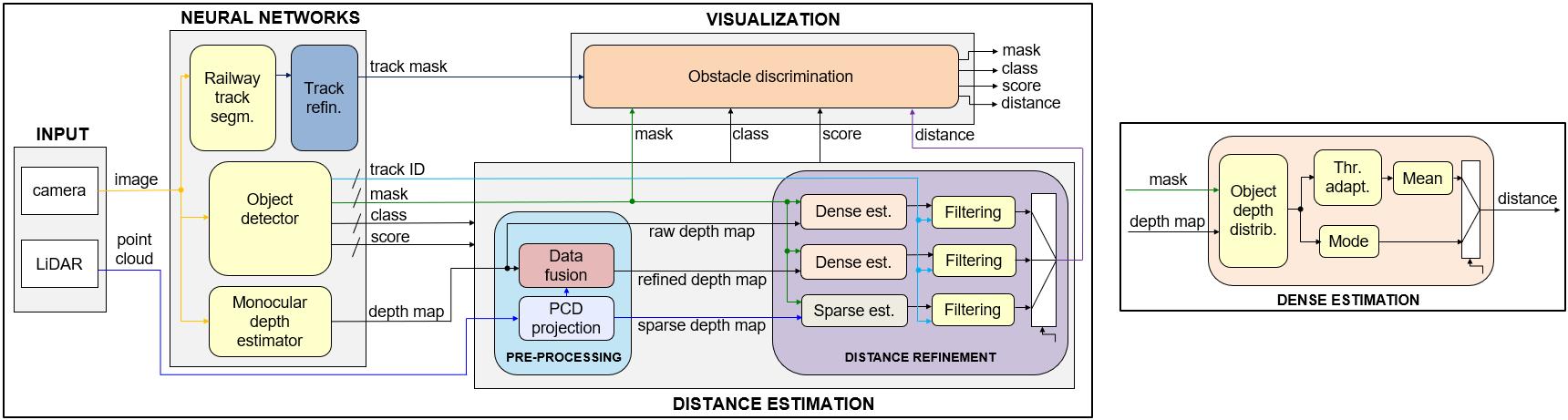
Figure 2: Block diagram of the system, detailing the neural and depth fusion pipelines.
Neural Components
Depth and Distance Fusion
The pipeline fuses dense, single-frame depth maps with sparse but highly accurate LiDAR signals. The LiDAR point cloud is projected into the image plane and interpolated to correct systemically biased monocular estimates. Three fusion outputs are available per frame: (1) LiDAR-derived sparse depth, (2) MiDaS raw dense depth, and (3) MiDaS refined via LiDAR correction (linear interpolation of residuals).
Figure 4: Top-left: ground-truth depth map, Top-right: monocular depth (pre-finetune), Bottom-left: MiDaS output post-finetune and LiDAR fusion, Bottom-right: segmentation mask-based object distance.
Object distance estimates utilize the most representative statistic (mode or mean of k% smallest depths within the segmentation mask) and are temporally smoothed using a weighted sliding window informed by object tracking. Semantic segmentation-based masks, instead of bounding boxes, yield more precise, contamination-free depth statistics.
Visualization
Detected objects within the track’s expanded mask are annotated visually with their class, distance, and confidence, omitting bounding boxes to reduce occlusion and clutter.
Experimental Design
The training and evaluation regimens are aligned closely with railway-specific challenges. Fine-tuning employs RailSem19/OSDaR23 for track segmentation, COCO (with class remapping) for detection models, and SynDRA (synthetic, photorealistic RGB-D railway dataset) for monocular depth estimation. The framework is evaluated on multiple synthetic and augmented benchmarks to overcome the lack of real-world dense depth ground-truth.
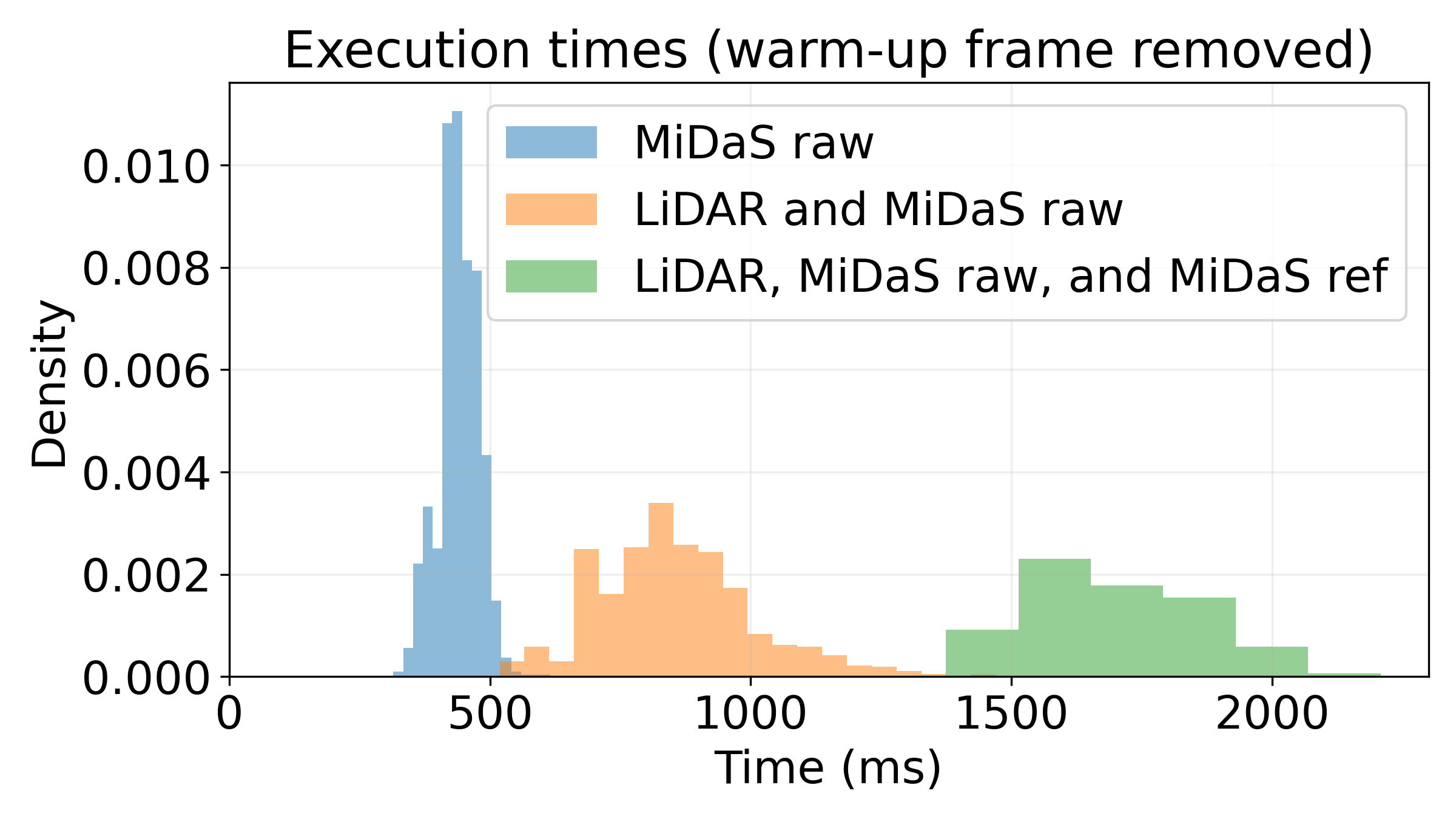
Relevant neural and data-fusion modules are executed in parallel threads, synchronized per frame. No hardware optimizations are applied, establishing a transparent performance baseline.
Empirical Results
- DDRNet23-Slim (Track Segmentation): Accuracy 0.99, IoU 0.94 on OSDaR23.
- YOLOv11x (Object Detection/Segmentation): mAP@50 of 0.78 post fine-tuning on railway-relevant classes.
- MiDaS v3.1 (Depth Estimation): MAE as low as 12.2 m in 0–200 m range (threshold-weighting), and overall MAE of 35–42 m on [0,655] m.

Figure 5: System output on OSDaR-AR (top) and SynDRA (bottom).
Limitations and Outlook
The system, while modular and extensible, inherits standard vision model limitations: inability to detect long-tail, small, or out-of-distribution classes outside those defined for COCO, and is currently validated only with synthetic/augmented datasets. Generalization to real-world data will inevitably incur a performance gap, especially for depth due to photometric and geometric domain shift. The current pipeline is not real-time and will require architectural and engineering optimizations (e.g., hardware acceleration, pruning, quantization).
The framework’s independence from fixed backbones facilitates rapid integration of future detection and depth estimation improvements and supports adaptation to new sensor configurations. The domain-agnostic abstraction also eases benchmarking and comparison, a critical need in railway AI perception where open datasets are rare.
Conclusions
This paper extends the state of the art in railway obstacle detection, presenting a unified, modular framework integrating segmentation, instance-level detection, and dense, LiDAR-guided distance estimation with robust temporal filtering. The numerical results highlight strong localization and metrically reliable distance prediction, with MAE as low as 0.63 m using depth fusion. The framework’s flexibility, sensor fusion pipeline, and synthetic-data-based extensibility position it as a reference for both research and potential industrial deployment, contingent upon subsequent validations on real-world data and optimizations for operational speed.
Future research will entail (i) architectural optimization for real-time operation, (ii) domain adaptation and transfer validation on in-the-wild railway data, and (iii) methodological improvements in segmentation-based masking and sensor fusion to improve robustness under adverse visual and environmental conditions. The release and benchmarking methodology further reinforce good reproducibility standards for railway perception research.