- The paper introduces an explicit step size characterization for mean-square stability in ZO methods using the standard two-point estimator.
- Empirical results on CNNs, ResNets, and Vision Transformers confirm that ZO optimizers operate near the predicted trace-based stability thresholds.
- It highlights a key divergence from first-order methods, where ZO dynamics regulate stability via total curvature energy rather than the largest Hessian eigenvalue.
Zeroth-Order Optimization Dynamics and the Mean-Square Edge of Stability
Introduction
Zeroth-order (ZO) optimization is receiving renewed attention due to its applicability in scenarios where gradients are unavailable, unreliable, or computationally prohibitive. Such scenarios encompass black-box adversarial attacks, memory-efficient large model finetuning, derivative-free control, and privacy-constrained distributed learning. Despite the practical relevance, the optimization dynamics of ZO methods in deep models remain insufficiently characterized. This work subjects ZO methods—specifically, full-batch ZO gradient descent (ZO-GD), ZO-GD with momentum (ZO-GDM), and ZO-Adam—to a rigorous dynamical stability analysis, establishing a precise connection between ZO optimization and mean-square linear stability at the so-called edge of stability (EoS).
Main Theoretical Contributions
The paper introduces an explicit, exact step size characterization for the mean-square linear stability of ZO methods based on the standard two-point estimator. Importantly, it demonstrates a robust separation between the stability mechanisms of ZO and first-order (FO) methods.
In classical FO methods such as gradient descent, the stability threshold is determined solely by the largest Hessian eigenvalue λmax—EoS theory holds that full-batch FO optimization pushes the top Hessian curvature λmax(t) to equilibrate near 2/η for step size η. In contrast, in the mean-square sense, ZO dynamics are governed by the entire Hessian spectrum, not only the top eigenmode.
This spectral distinction is substantiated both theoretically and empirically. For ZO optimizers, the mean-square stability boundary—trackable by upper and lower explicit bounds—is driven predominantly by the Hessian trace Tr(H). The step size upper-bound for mean-square stability is sandwiched between Tr(H)+cλmax(H)2 and Tr(H)2, with the extra term cλmax(H) decreasing in importance with increasing trace dominance.
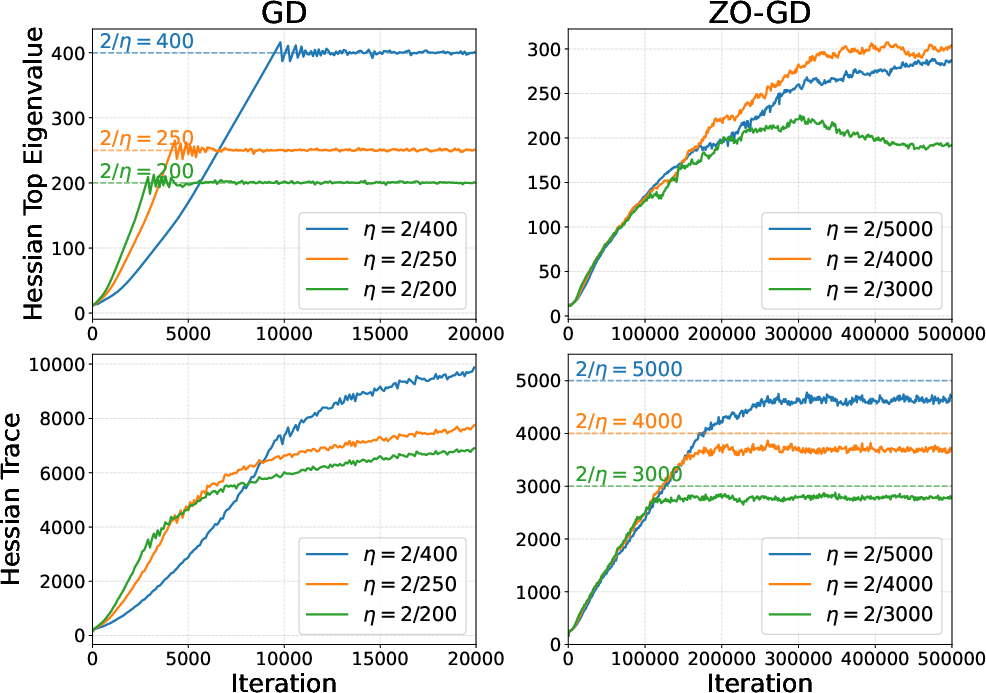
Figure 1: EoS behaviors of FO (left) and ZO (right) methods, highlighting that ZO-GD stabilizes via Hessian trace rather than the top eigenvalue.
Empirical Confirmation: Mean-Square EoS in ZO Methods
The empirical analysis, conducted over standard vision architectures (CNN, ResNet, Vision Transformer) and synthetic LSTM/Mamba sequence models, exhibits a dominant trend: regardless of step size or momentum parameter, ZO full-batch optimizers consistently adapt to operate near their predicted mean-square edge of stability, as dictated by trace-based curvature terms. This persistent EoS property is both robust across architectures and invariant with respect to batch size and input domain.
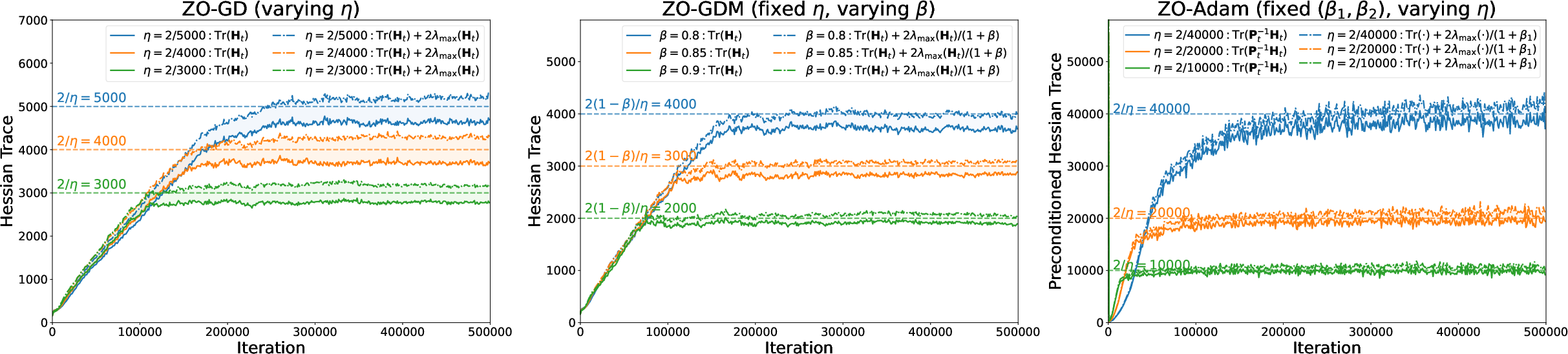
Figure 2: Zeroth-order methods operate at the mean-square edge of stability—the trace and upper/lower stability-band bounds are shown to strongly track the predicted threshold through training.
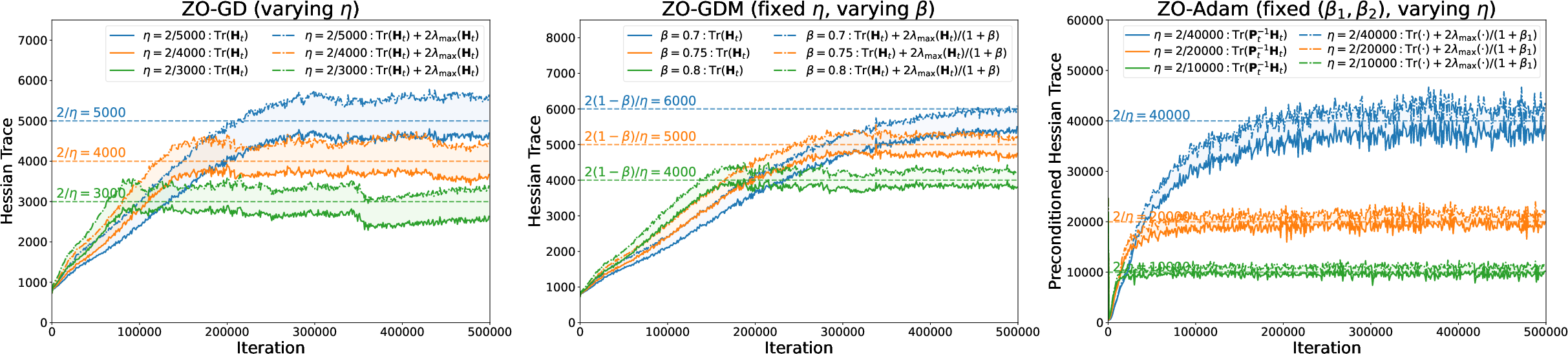
Figure 3: Mean-square EoS for full-batch ZO methods on ResNet—strong stabilization of ZO-GD, ZO-GDM, and ZO-Adam at the predicted edge.
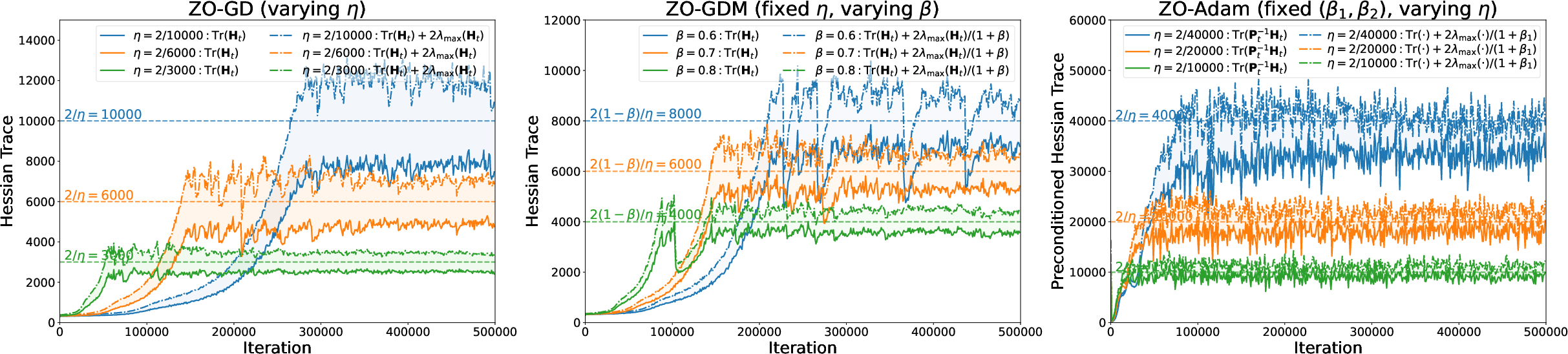
Figure 4: Mean-square EoS for full-batch ZO methods on Vision Transformer—again, stabilization manifests around the predicted trace-based boundaries.
In all tested architectures, after a transient sharpening phase, the Hessian trace or preconditioned trace (for preconditioned/adaptive methods such as ZO-Adam) stabilizes tightly around 2/η, in direct agreement with the theoretical stability boundary.
Technical Insights
Mean-Square Stability Mechanism
In ZO methods, even full-batch training retains inherent randomness, stemming from the isotropic random search directions of the two-point estimator. Therefore, "stability in mean" (the usual metric for FO methods) is not meaningful—one must examine stability in the mean of the squared norm. The authors construct a cone-preserving linear covariance operator to represent the evolution of the iterates' second-moment matrix, enabling the application of the Krein–Rutman theorem to yield precise, explicit spectral conditions for mean-square stability.
Practical Stability Tracking
Because direct computation of the full Hessian spectrum is infeasible in deep models, the paper derives tractable upper/lower stability bounds based only on λmax and λmax(t)0. During practical neural training, these statistics are efficiently estimated via Hutchinson and power iteration methods.
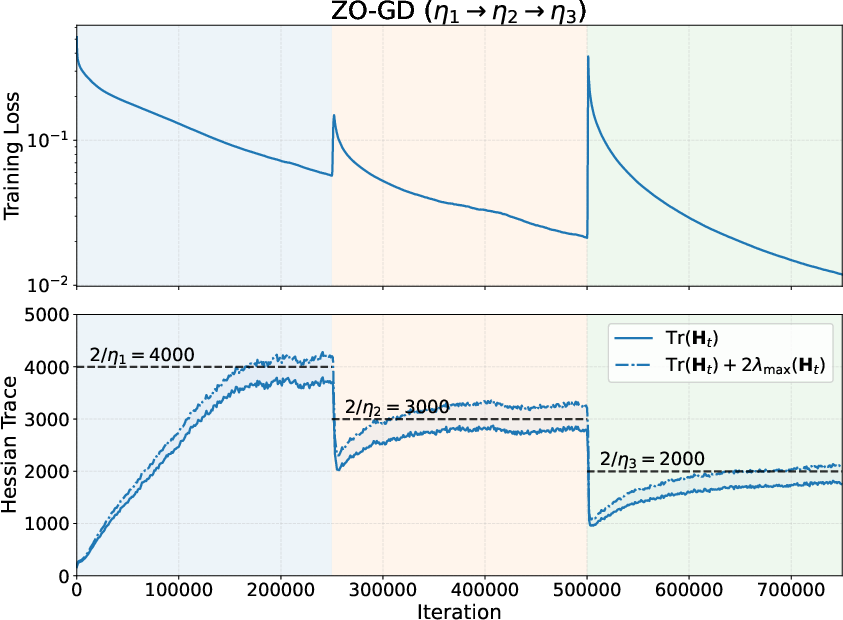
Figure 5: Catapult dynamics in ZO-GD—loss spikes and recovery in response to step size increases, and concomitant sharp drops and re-equilibration of the Hessian trace.
Contrasts with First-Order Dynamics
A principal finding is the divergence of implicit regularization behavior between FO and ZO methods under large step sizes. In FO optimization, large λmax(t)1 induces implicit regularization on the sharpest direction; training equilibrates to sets with reduced maximum eigenvalues. In ZO optimization, large λmax(t)2 primarily regularizes the trace (i.e., the total curvature energy, not just the sharpest mode).
The momentum parameter λmax(t)3 also modifies stability in a qualitatively different fashion: in FO methods, higher λmax(t)4 tends to increase the stable range of λmax(t)5 (stabilizing sharper directions), while in ZO methods, it restricts the stability range (since momentum aggregates stochastic noise in the update).
Effect of Other Hyperparameters
The smoothing parameter λmax(t)6 in the two-point estimator modulates the noise and bias in the stochastic approximation. For moderate or small λmax(t)7, the mean-square EoS persists. For large λmax(t)8, implicit smoothing suppresses curvature, and training does not approach the predicted EoS threshold.
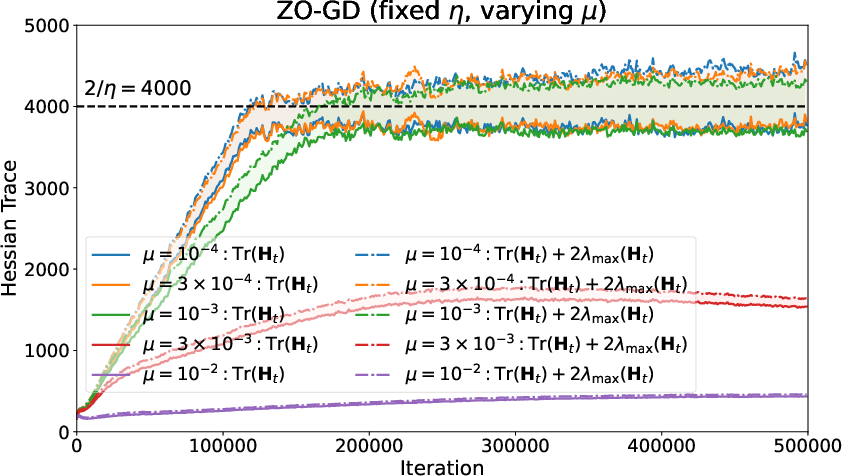
Figure 6: Effect of the smoothing parameter λmax(t)9—smaller 2/η0 values maintain EoS, while large 2/η1 suppresses approach to the stability boundary.
Similarly, mini-batch ZO-SGD trains in lower-curvature regimes with reduced trace, akin to the behavior observed in stochastic FO optimization.
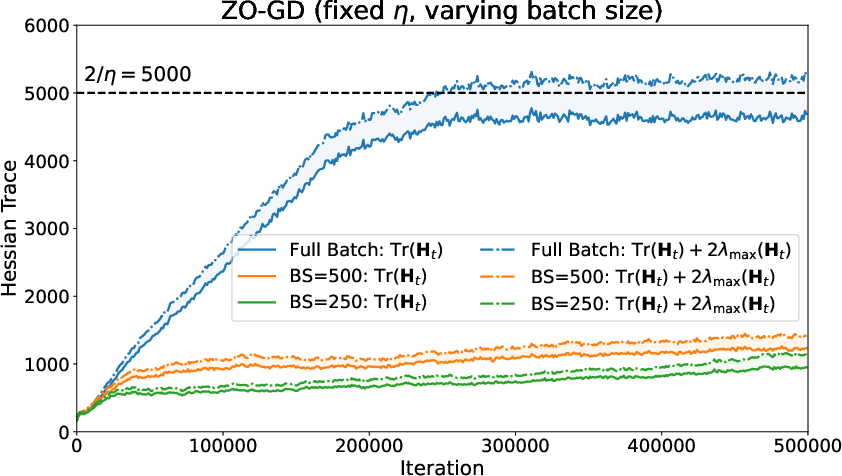
Figure 7: Effect of batch size in mini-batch ZO-SGD—minibatching leads to lower-trace regimes relative to full-batch ZO-GD.
Implications and Theoretical/Practical Ramifications
These findings position mean-square stability as the fundamental theoretical lens for understanding ZO optimization in deep networks. The paper demonstrates that ZO full-batch optimizers are not naively stochastic analogues of FO methods but are instead governed by distinct dynamical regularization properties tied to trace rather than maximum Hessian eigenvalue.
From a practical viewpoint, the trace-dominated regularization induced by aggressive step sizes in ZO methods suggests that such protocols can be exploited for efficient, memory-frugal finetuning in large models—as already evidenced by recent advances in LLM finetuning with ZO methods. Additionally, the explicit, trackable mean-square bounds facilitate automated learning rate selection and real-time diagnosis of stability in production.
The theory also implies that, for large-scale or distributed scenarios where Hessian trace may be more manageable than 2/η2, ZO methods may yield distinct or preferable generalization/robustness regimes, warranting future systematic empirical study.
Future Directions
Several open directions arise:
- Extending mean-square stability theory beyond the full-batch setting to incorporate both estimator and minibatch sampling noise.
- Integrating the mean-square stability perspective with generalization/optimization efficiency frameworks.
- Unifying ZO mean-square EoS with central-flow analyses in qualitative studies of deep learning dynamics.
Conclusion
This work establishes mean-square linear stability as the controlling principle for the training dynamics of zeroth-order optimization in overparameterized models. In sharp contrast to first-order optimizers, ZO methods are shown to operate fundamentally at the mean-square edge of stability, characterized by trace-based spectral statistics rather than maximum eigenmode. This reorients both theoretical and practical understanding of implicit regularization and stability in derivative-free deep learning optimization and provides a foundation for integrating ZO methods into robust, large-scale machine learning systems.