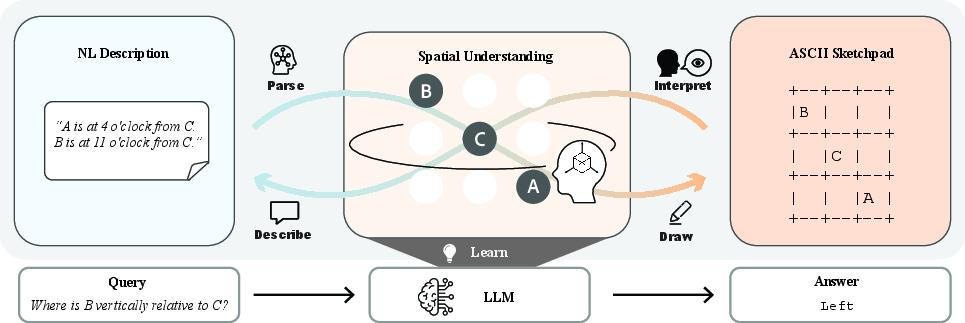
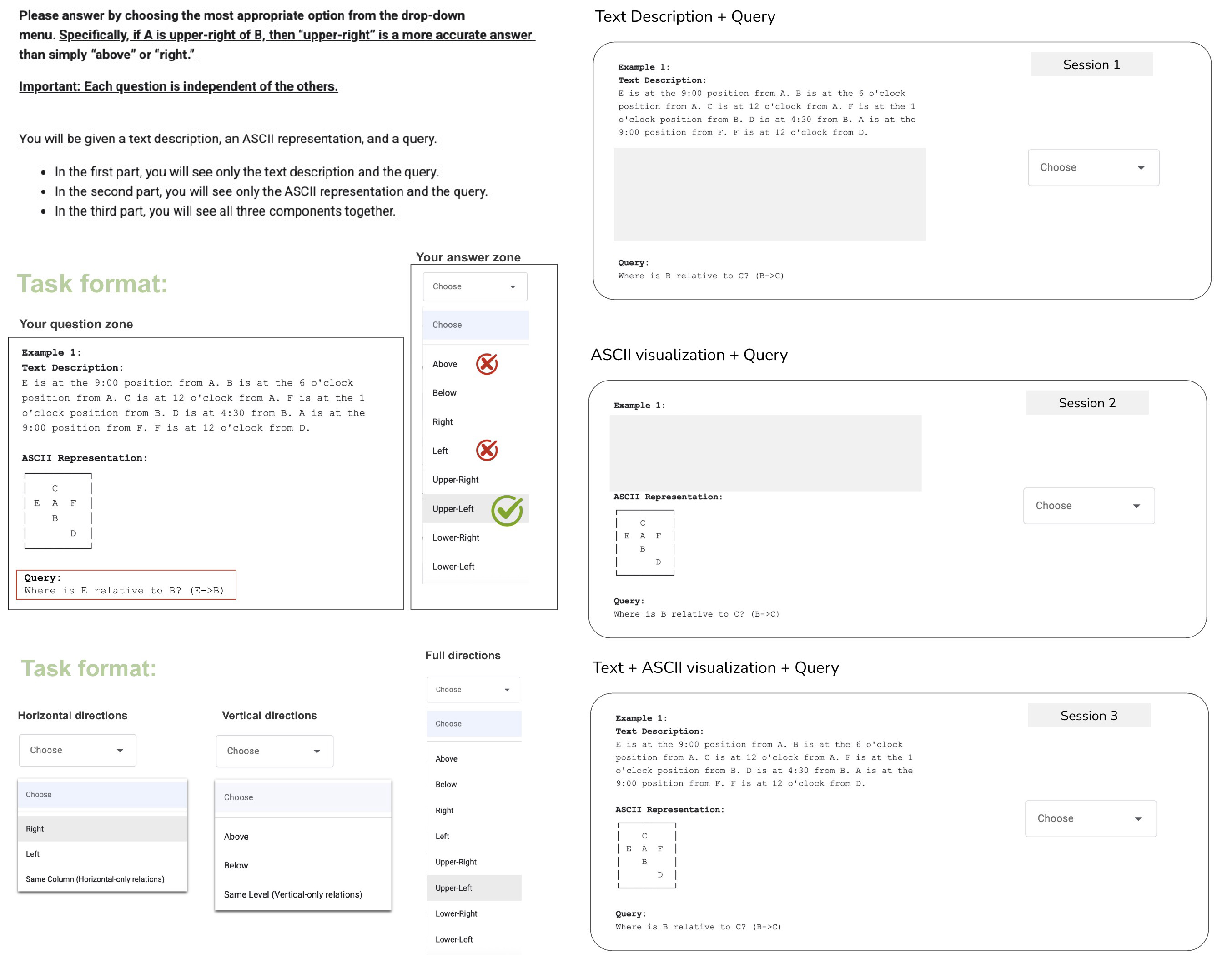
Learning to Draw ASCII Improves Spatial Reasoning in Language Models
Abstract: When faced with complex spatial problems, humans naturally sketch layouts to organize their thinking, and the act of drawing further sharpens their understanding. In this work, we ask whether a similar principle holds for LLMs: can learning to construct explicit visual layouts from spatial descriptions instill genuine spatial understanding? We introduce Text2Space, a dataset that pairs natural language descriptions with ground-truth ASCII grid layouts and spatial QA pairs, enabling us to separate failures in constructing spatial representations from failures in reasoning over them. We adopt ASCII because it is human-readable, operates entirely within the token space of LLMs, and encodes spatial relations in a structurally verifiable form. Our evaluation reveals a pronounced "Read-Write Asymmetry": LLMs interpret ASCII representations effectively but struggle to produce them from text, and these construction errors propagate to incorrect answers downstream. To address this limitation, we train models on layout construction (Text$\rightarrow$ASCII) and find that it significantly improves spatial reasoning from text alone, even without producing any ASCII at inference time. Combining construction with comprehension training further amplifies these gains. Crucially, these improvements transfer to three external spatial reasoning benchmarks, demonstrating that, much as sketching sharpens human spatial thinking, learning to construct explicit layouts instills spatial understanding that generalizes beyond the training format.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple, human-inspired question: when we solve tricky space or layout problems, we often sketch a quick map to think more clearly. Could LLMs get better at spatial reasoning if we teach them to “sketch” too—using plain text drawings made of keyboard characters (ASCII art) like +, -, |, and letters?
To test this, the authors built a new dataset called Text2Space that pairs:
- a natural-language description of where objects are (for example, “A is above B and left of C”),
- a ground-truth ASCII layout (a little map made with text),
- and questions about the layout (like “Is A to the upper-left of C?”).
They show that teaching models to draw these little maps from text makes the models better at spatial reasoning—even when the models don’t draw anything at test time.
Main Questions
The study explores three easy-to-understand questions:
- Can LLMs both read ASCII layouts and draw them from text—and where do they struggle?
- If a model draws a layout as a step in its thinking, does that help it answer spatial questions correctly?
- If we train a model to draw layouts, does that training make it better at spatial reasoning in general, even on other tasks where no drawing is used?
How They Did the Study
The Text2Space dataset
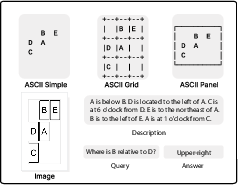
Text2Space contains many small spatial scenes made of objects placed in a grid. Each scene has:
- A text description using eight directions: above, below, left, right, and the four diagonals (upper-left, upper-right, lower-left, lower-right).
- A correct ASCII drawing of the scene (the “ground truth” map).
- A question and answer about the scene (for example, “What’s the relation between X and Y?”).
- A simple image version for reference.
Using ASCII is helpful because:
- It’s human-readable.
- It’s still just text, so LLMs can handle it.
- It can be checked automatically: the drawing either matches the description or it doesn’t.
What the models were asked to do
The researchers set up several tasks:
- Read a drawing and describe it in words (ASCII → description).
- Read a description and draw it (description → ASCII).
- Answer spatial questions from:
- Only text,
- Only ASCII,
- Both together,
- Or by first drawing a layout, then answering.
They also tried two orders for the “draw + answer” setup:
- Answer first, then draw.
- Draw first, then answer.
Finally, they trained models in three ways:
- Learn to construct layouts (description → ASCII).
- Learn to comprehend layouts (ASCII → description).
- Learn both directions together (bidirectional).
Then they checked if these skills carried over to three other popular spatial reasoning tests that don’t use ASCII at all.
How success was measured
The team measured:
- Answer accuracy: Did the model get the spatial question right?
- Drawing correctness: Does the ASCII map match the text description?
- Consistency: Do the model’s own drawing and its answer agree with each other? If they agree, is the answer more likely to be right?
Main Results
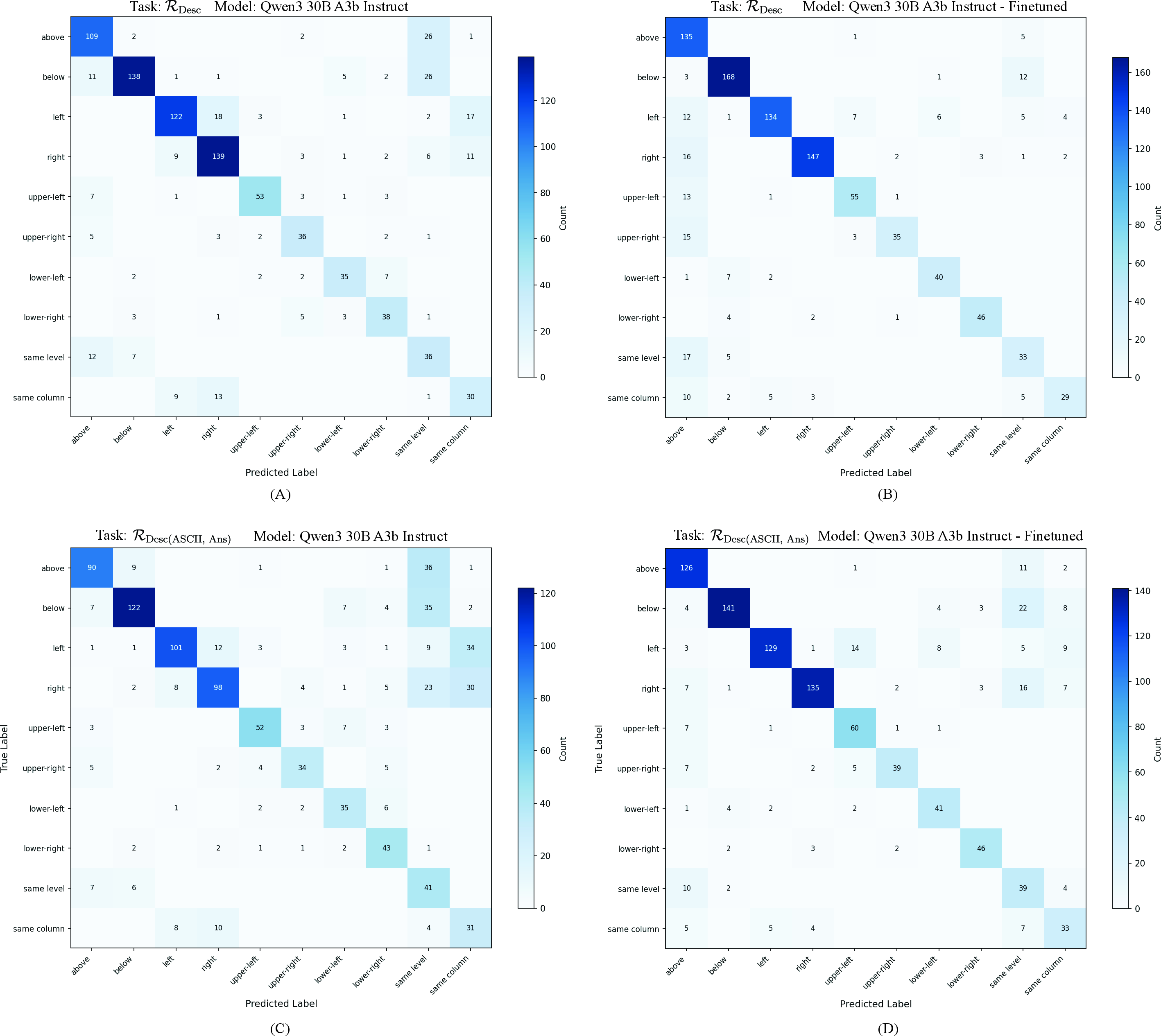
- Reading is easier than drawing (the “read-write asymmetry”).
- Models are pretty good at understanding an ASCII layout that’s given to them.
- But they often struggle to draw the layout correctly from a text description.
- This matters because a bad drawing leads to bad answers.
- Good layouts help reasoning; bad layouts hurt it.
- If a model is given a correct ASCII layout, it answers spatial questions better than from text alone.
- If the model tries to draw its own layout (and the drawing is often wrong), its answers get worse.
- So the problem isn’t the idea of “sketching,” it’s the quality of the sketch.
- Training models to draw improves their spatial thinking—even without drawing later.
- Teaching a model to construct layouts (turn text into ASCII) makes it better at answering spatial questions from text alone at test time.
- Teaching only to read layouts (ASCII → text) helps less and can even hurt in some cases.
- Training in both directions (construct + comprehend) works best overall.
- The gains transfer to other benchmarks.
- After learning to draw layouts, models did better on three separate spatial tests that don’t use ASCII: StepGame, bAbI Task 19, and SpartQA.
- This shows the model learned a deeper sense of space, not just a trick tied to ASCII.
- Consistency is a useful reliability signal.
- When a model’s drawing and its answer agree, the answer is much more likely to be correct.
- Because ASCII maps can be checked, they can act like a built-in “lie detector” for the model’s reasoning steps.
Why This Matters
- For people, sketching a quick map often makes thinking clearer. This paper shows that teaching LLMs to “sketch” with ASCII can give them a similar boost in understanding space.
- Better spatial reasoning could help AI with tasks like navigation, understanding directions, solving puzzles, working with robots, or answering questions about how things are arranged.
- The idea of using a structured, checkable sketch (like ASCII) can make a model’s thinking more reliable and easier to inspect, which is important for safety and trust.
Limitations and Future Directions
- ASCII grids are simplified 2D maps. Real-world space is often 3D, messy, and continuous, not neat grids.
- The dataset is synthetic (computer-generated), so future work should test more realistic, noisy descriptions and scenes.
- The paper focuses on ASCII; other formats (like coordinate lists or scene graphs) might also work and could be explored.
- Even with consistency checks, we still don’t fully see the model’s internal “mental map.” Future methods could combine sketching with self-correction loops to improve reliability further.
Bottom Line
Teaching LLMs to draw simple text maps from descriptions strengthens their internal sense of space. This makes them better at spatial reasoning, even when they don’t draw anything later, and it helps on other spatial tasks too. Like humans, models benefit from sketching to think more clearly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future researchers can act on it.
- Limited spatial scope: the dataset is restricted to discrete 2D grids with eight compass/ordinal relations; it excludes continuous geometry, metric distances, angles, sizes/scales, and richer topological relations (e.g., containment, adjacency, “between,” proximity).
- No 3D or depth: the approach and evaluation do not consider 3D spatial reasoning or projection/occlusion effects.
- Fixed frames of reference: all scenes use a global coordinate frame; performance under egocentric/intrinsic frames, and invariance to rotations/reflections of scenes and language (e.g., “north” vs “up”), is untested.
- Synthetic language only: descriptions are programmatically generated with limited linguistic phenomena; robustness to human-authored text with coreference, pronouns, ellipsis, negation, comparatives/quantifiers, and ambiguous phrasing is unknown.
- Ambiguity and under-specification are excluded: all instances guarantee a single unambiguous relation; handling multiple valid layouts, conflicting statements, or incomplete descriptions is left open.
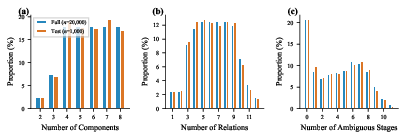
- Graph complexity ceiling: layouts max out at eight entities and twelve relations; there is no scaling analysis of accuracy vs. graph size, density, or reasoning depth (transitive chains).
- Connectivity constraint: only connected graphs are generated; disjoint or loosely connected scenes are not evaluated.
- Question diversity: the benchmark queries only pairwise relations; higher-order queries (e.g., “X is between Y and Z?”, nearest neighbor, counts at k-steps) and compositional constraints are not included.
- ASCII style robustness: although three ASCII styles exist in the dataset, experiments use a single grid style; generalization across rendering styles, spacing jitter, misalignment, or noisy diagrams is unevaluated.
- Representation equivalence metrics: evaluation for Desc→ASCII uses “proportion of relations depicted,” which may miss global validity; there is no strict isomorphism/equivalence check (e.g., translation invariance) or minimality/consistency scoring across the whole layout.
- Verifier reliability: the correctness of the ASCII parser/verifier (false positives/negatives) and its effect on reported scores are not quantified; a tested, released evaluation toolchain with error analysis is not provided.
- “ASCII as a verifier” not operationalized: consistency is measured but not used to drive detect-and-repair loops, rejection sampling, search over candidate layouts, or gated answering; the causal benefit of verification-guided inference remains untested.
- Alternative intermediates untested: it is unknown whether construction benefits are specific to ASCII or generalize to other structured formats (coordinate lists, scene graphs, SVG, raster sketches) and whether hybrids outperform ASCII alone.
- Training generality: construction fine-tuning is demonstrated only on a single model family/size (Qwen3-30B with LoRA); replication across architectures/sizes and sensitivity to tokenizer/vocabulary (e.g., box-drawing Unicode) remain open.
- Sample efficiency and scaling laws: there are no ablations on training set size, curriculum (easy→hard), or data mixture; how construction learning scales with more data or harder scenes is unreported.
- Optimization objectives: only supervised fine-tuning is explored; reinforcement learning with verifiable rewards (constraint satisfaction), process reward models, or auxiliary losses that enforce global layout consistency are not tested.
- Negative transfer: comprehension-only fine-tuning degrades some tasks (e.g., StepGame) but the causes (catastrophic interference, miscalibrated parsing) and mitigations (regularization, multi-task scheduling) are not analyzed.
- Consistency-aware deployment: pre-finetuning, generated ASCII hurts performance; strategies to use consistency/confidence thresholds to decide when to trust or discard sketches, or to trigger re-drawing, are not evaluated.
- External transfer baselines: transfer is evaluated in zero-shot only; comparisons to strong prompting (CoT, self-consistency, deliberate decoding, ToT) and tool-use baselines on the same external tasks are missing.
- Error taxonomy: large gains on SpartQA vs. modest on StepGame are reported without a fine-grained analysis separating linguistic parsing errors from spatial reasoning errors; detailed confusion/error breakdowns are needed.
- Robustness to noise: there are no tests with typos, distractor entities, contradictory statements, or adversarial phrasings; stability under prompt variations, temperature, and decoding settings is also unreported.
- Multimodal integration: images are provided in the dataset but never used for training or evaluation; whether ASCII construction complements or substitutes image-based spatial understanding in VLMs is open.
- Human studies: preliminary human validation is limited to text vs. ASCII reading; there is no study on human-authored descriptions, ambiguity tolerance, or sketching strategies that could inform model training and evaluation.
- Internal mechanism probing: whether construction training induces persistent internal spatial representations (e.g., latent coordinates, attention patterns) is not investigated; probing or mechanistic analyses are absent.
- Broader transfer: effects of construction training on non-spatial structured reasoning (tables, circuits, logic puzzles, mathematics) are not measured.
- Practicality: the inference-time cost/latency and context-length impact of generating or parsing ASCII are not quantified; trade-offs vs. direct answering and potential batching/compaction methods are unexplored.
- Reproducibility: full prompts, decoding parameters, seeds, and absolute external benchmark scores are sparse in the main text; comprehensive artifacts for exact replication and variance reporting are needed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage this paper’s findings on ASCII-based spatial representation, construction training, and consistency checking.
- ASCII–Answer Consistency Monitor for Reliability (software, safety-critical)
- What: Integrate an “ASCII as a Verifier” step into LLM pipelines to cross-check the consistency between a generated ASCII layout and the model’s textual answer, routing inconsistent cases to fallback strategies or human review.
- Tools/workflows:
- A lightweight ASCII parser and consistency checker;
- Confidence gating in agent frameworks (e.g., before executing navigation or manipulation steps).
- Dependencies/assumptions: Requires prompts/models that can produce ASCII reliably; ASCII must be expressive enough for the task’s spatial relations; additional latency from a second generation+check step.
- Sketch-to-Reason Fine-Tuning Regimen (software, robotics, logistics, education)
- What: Apply LoRA-based fine-tuning on the Desc→ASCII construction task (optionally with bidirectional alignment) to boost spatial reasoning in text-only tasks—without ASCII at inference—mirroring the paper’s gains.
- Tools/workflows:
- Hugging Face TRL SFT pipeline;
- LoRA adapters shipped as “Spatial Reasoning” add-ons for Qwen/Llama family models;
- Evaluation with Text2Space and external tests (e.g., StepGame).
- Dependencies/assumptions: Access to GPU resources and fine-tuning data; domain mismatch (synthetic → real) may require additional domain adaptation.
- Agent “ASCII Whiteboard” for Spatial Tasks (software, games)
- What: Provide LLM agents with an internal, verifiable ASCII whiteboard to sketch layouts before planning moves (e.g., in text-based games, grid puzzles, or routing within apps).
- Tools/workflows:
- Agent tool calling to “DrawASCII” and “CheckConsistency” functions;
- One-turn or two-turn (explain-then-predict) flows depending on latency tolerance.
- Dependencies/assumptions: Sketch quality affects downstream reasoning; prompts must constrain ASCII format for robust parsing.
- Text2Space as a Diagnostic Benchmark (academia, ML Ops)
- What: Use the dataset to decouple representation failures (bad layouts) from reasoning failures (bad deductions) when evaluating or debugging LLMs.
- Tools/workflows:
- Add a “representation alignment” stage in eval;
- Compare Desc→ASCII vs ASCII→Desc asymmetry across model versions;
- Track consistency metrics (Cons, C_Acc) as regression indicators.
- Dependencies/assumptions: Synthetic nature of Text2Space; supplement with domain-specific samples for better coverage.
- Customer Support Troubleshooting Aids (consumer electronics, IoT)
- What: Convert natural-language device descriptions (“the reset button is above the USB port and left of the LED”) into quick ASCII faceplate diagrams to guide users.
- Tools/workflows:
- Prompt templates to accept device parts and relations;
- Embedded consistency check to ensure diagrams reflect instructions.
- Dependencies/assumptions: Device taxonomies and canonical part names; ASCII’s granularity sufficient for small device faces.
- Accessibility: Screen-Reader-Friendly Spatial Diagrams (daily life, education)
- What: Provide accessible ASCII layouts for spatial instructions (e.g., furniture placements, room navigation) to complement text for users relying on screen readers.
- Tools/workflows:
- NL → ASCII conversion with consistent grid characters;
- Optional NL summary derived from ASCII for redundancy.
- Dependencies/assumptions: ASCII must be formatted for clear screen reader traversal; complex/curved geometries may be hard to convey.
- Educational Practice and Auto-Grading (education)
- What: Teach students to “sketch to think” by requiring ASCII layouts in math/logic/spatial assignments and auto-grade with verifiable structural checks.
- Tools/workflows:
- Assignment templates with required grid formats;
- Automated validators for relation coverage and error feedback.
- Dependencies/assumptions: Training students and instructors on a consistent ASCII style; limited to 2D discrete relations.
- Documentation Enhancements with Inline ASCII (software, hardware manuals)
- What: Enrich documentation with auto-generated ASCII diagrams for spatially described procedures (e.g., “place module A above B and to the left of C”).
- Tools/workflows:
- Docs plugins that parse text and inject ASCII diagrams;
- Pre-commit hooks to verify ASCII alignment with text.
- Dependencies/assumptions: Clear authoring conventions; diagrams remain small enough for readability.
- Warehouse/Inventory Instruction Parsing (logistics)
- What: Turn picking or placement instructions into small ASCII maps to reduce ambiguity and errors in bin/row/column navigation.
- Tools/workflows:
- NL instruction → grid sketch + consistency gate;
- Optional downstream mapping to WMS coordinates.
- Dependencies/assumptions: Mapping from discrete ASCII cells to real-world shelving; vocabulary normalization across sites.
- Text-Based Game and Benchmark Agents (gaming, research)
- What: Improve agents for TextWorld/StepGame-style environments by integrating ASCII construction and consistency monitoring to reduce spatial hallucinations.
- Tools/workflows:
- Fine-tune on construction;
- Use explain-then-predict mode when performance (not latency) is the priority.
- Dependencies/assumptions: Game rules align with the dataset’s directional relations; grid-like worlds.
Long-Term Applications
These use cases require further research, scaling, multimodal integration, or standardization beyond what the paper directly demonstrates.
- NL-to-Map for Robot Navigation and Manipulation (robotics)
- What: Convert natural language instructions into intermediate maps (ASCII or structured grids/graphs) that align with sensor-based world models for planning and control.
- Tools/products:
- “Spatial Adapter” modules bridging NL → discrete map → real coordinates;
- Onboard consistency gates for safety-critical decisions.
- Dependencies/assumptions: Robust alignment between discrete ASCII-like maps and continuous, noisy environments; sensor fusion and real-time updates.
- Indoor Wayfinding and Accessibility Systems (healthcare, smart buildings, public safety)
- What: Support indoor navigation (hospitals, airports, malls) by turning textual directions into intermediate layouts, then into path plans for mobile apps or assistive devices.
- Tools/products:
- NL→layout→route pipeline;
- Multilingual support and dynamic updates (closures, detours).
- Dependencies/assumptions: Accurate building maps; alignment of symbolic directions with complex floor plans; user-specific constraints (wheelchair access).
- CAD/Architecture: From Requirements to Draft Floorplans (AEC, real estate)
- What: Use construction training principles to scaffold early-stage, verifiable sketches of space allocation from textual briefs (zones, adjacency, directionality).
- Tools/products:
- Text→ASCII→parametric CAD conversion workflows;
- Constraint solvers to move beyond grids.
- Dependencies/assumptions: Extension from 8-direction discrete relations to metric, continuous, and 3D constraints; code compliance.
- UI/UX Layout Synthesis from Specifications (software, design tools)
- What: Generate draft wireframes from textual specs via intermediate ASCII grids, then translate to design systems (e.g., Figma) with constraint validation.
- Tools/products:
- “ASCII-to-Wireframe” transpilers;
- Consistency gates that check NL↔layout alignment before export.
- Dependencies/assumptions: Mapping directional relations to responsive layouts; non-grid layouts and relative sizing.
- Warehouse and Factory Agents with NL Work Orders (manufacturing, logistics)
- What: NL work orders → validated intermediate layouts → robot/human pick paths and placements, with consistency checks as quality gates.
- Tools/products:
- Agentic workflows with layout construction and verification;
- Integration with WMS/MES and indoor positioning.
- Dependencies/assumptions: Real-time state and inventory updates; calibration between symbolic grids and live facility topology.
- Multimodal Spatial Reasoning via Structured Intermediates (vision-language systems)
- What: Fuse visual perception with text by requiring models to produce structured, verifiable intermediates (ASCII/graphs) prior to answering spatial questions.
- Tools/products:
- VLMs trained to output structured layouts from images + text;
- Cross-modal consistency as a confidence metric.
- Dependencies/assumptions: Reliable detection and grounding; standardized intermediate formats across models.
- Policy and Audit: Verifiable Intermediates in High-Stakes AI (policy, governance)
- What: Encourage or require structured, auditable intermediates for AI decisions involving spatial reasoning (e.g., evacuation planning, medical facility routing).
- Tools/products:
- Procurement standards and audit trails that log NL↔layout↔answer;
- Red-teaming protocols using consistency metrics.
- Dependencies/assumptions: Community agreement on format standards; balancing transparency with IP and privacy.
- 3D and Continuous-Space Extensions (autonomous systems, AR/VR)
- What: Generalize the “construct to understand” paradigm to 3D and continuous spaces (e.g., drones, AR overlays), moving from ASCII to coordinate graphs/meshes.
- Tools/products:
- 3D scene-graph construction training;
- Differentiable constraint solvers for global spatial consistency.
- Dependencies/assumptions: New datasets and verifiers; higher sample and compute requirements.
- Assistive AR Guidance from Textual Instructions (consumer, enterprise)
- What: Translate NL instructions into intermediate layouts and then overlay step-by-step spatial cues in AR for assembly, maintenance, or training.
- Tools/products:
- NL→layout→AR overlay pipelines;
- On-device consistency checks to flag ambiguous steps.
- Dependencies/assumptions: Accurate spatial anchoring; robust NLP grounding to real-world coordinates.
- Multilingual and Noisy-Language Spatial Reasoning (global deployments)
- What: Extend datasets and training to multilingual, colloquial, or noisy instructions, with layout construction as a universal intermediate for clarity.
- Tools/products:
- Synthetic data generation with linguistic variation;
- Domain-adaptive fine-tuning packs.
- Dependencies/assumptions: Cross-lingual alignment of spatial terms; culturally varying spatial metaphors.
- Safety Cases and Certification Pipelines (aviation, medical devices, defense)
- What: Build certifiable reasoning pipelines where structured intermediates and consistency checks contribute to evidentiary artifacts for compliance.
- Tools/products:
- Formalized checklists and metrics (e.g., C_Acc thresholds) in system verification;
- Replayable traces for audits.
- Dependencies/assumptions: Acceptance of structured intermediates by regulators; traceability standards.
- Marketplace of “Spatial Reasoning Adapters” (AI tooling ecosystem)
- What: Distribute pre-trained LoRA adapters focused on construction/bidirectional alignment for different domains (indoor wayfinding, device diagrams, UI layouts).
- Tools/products:
- Adapter catalog with benchmarks and consistency scores;
- Plug-and-play with major open models.
- Dependencies/assumptions: Versioning and compatibility across model families; clear licensing.
Key Cross-Cutting Assumptions and Dependencies
- Representation limits: ASCII captures discrete 2D relations (eight directions) but not metric distances, curves, or 3D; some applications need richer intermediates.
- Data gap: Text2Space is synthetic; real-world language and layouts are messier. Domain adaptation and human-in-the-loop correction may be necessary.
- Model readiness: Benefits depend on the model’s baseline ability to “read” ASCII and learn construction; small models may need more supervision.
- Alignment to reality: For embodied or physical tasks, mapping from symbolic layouts to real coordinates and handling uncertainty is non-trivial.
- Standardization: Consistency-based verification and intermediate formats are most effective when teams agree on a canonical ASCII style and parsing rules.
Glossary
- 5-shot prompting: A few-shot learning approach where five examples are provided in the prompt to guide model behavior. "we use default settings and apply 5-shot prompting \citep{brown2020language} to ensure consistency."
- ASCII grid layouts: Text-based diagrams that encode spatial relations using ASCII characters arranged in a grid. "We introduce Text2Space, a dataset that pairs natural language descriptions with ground-truth ASCII grid layouts and spatial QA pairs"
- Bidirectional Alignment (Desc↔ASCII): Training objective that jointly learns mapping from descriptions to ASCII and ASCII to descriptions to align both directions. "Bidirectional Alignment (DescASCII) combines both tasks simultaneously."
- Box-drawing characters: Special Unicode/ASCII characters used to draw boxes and lines for structured diagrams. "The panel format employs box-drawing characters for a visually distinct layout."
- Chain-of-Thought (CoT) prompting: A prompting strategy that elicits step-by-step reasoning traces from LLMs. "The utility of intermediate reasoning steps is well-established through Chain-of-Thought (CoT) prompting \citep{wei2022chain}"
- cognitive map: An internal or external structured representation that makes spatial relations explicit for reasoning. "We propose that ASCII layouts function as a structured reasoning intermediate: a verifiable ``cognitive map'' that makes spatial relationships explicit."
- Consistency (Cons): A metric that measures whether the generated intermediate representation (ASCII) supports the generated answer. "Consistency(Cons): Measures the alignment between the generated ASCII and the generated Answer."
- Consistency Accuracy (C_Acc): Accuracy computed only on instances where the answer and the ASCII representation are consistent. "Consistency Accuracy(C_Acc): Measures answer accuracy strictly on instances where the ASCII and Answer are consistent."
- construction gap: The identified bottleneck where models can read spatial layouts but struggle to construct them from text. "identify a representation bottleneck (what we call the construction gap)"
- Ground-truth intermediate representations: Verified intermediate structures provided to assess or train the reasoning process, not just final answers. "introducing ground-truth intermediate representations, enabling precise diagnosis of spatial reasoning errors."
- Latent reasoning: A technique where models reason in an internal, often continuous, space rather than explicit textual steps. "and latent reasoning \citep{hao2024training}."
- LLMs: High-capacity neural LLMs trained on large corpora to perform diverse language tasks. "we ask whether a similar principle holds for LLMs"
- Learning to Comprehend (ASCII→Desc): Training that focuses on parsing ASCII layouts and verbalizing them as descriptions. "Learning to Comprehend (ASCIIDesc) focuses on parsing and verbalizing ASCII representations."
- Learning to Construct (Desc→ASCII): Training that teaches models to build ASCII layouts from textual descriptions. "Learning to Construct (DescASCII) forces the model to actively construct spatial layouts from text"
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that injects low-rank updates into model weights. "We employed Low-Rank Adaptation (LoRA)~\citep{hu2021loralowrankadaptationlarge,peft} for parameter-efficient training"
- Natural Language Inference (NLI): A framework to assess whether a hypothesis logically follows from a premise; here used for checking consistency. "prior work has applied Natural Language Inference (NLI) to assess reasoning via consistency"
- One-turn generation: Setting where both the intermediate ASCII and the answer are produced in a single response. "one-turn generation, where the model produces both outputs within a single response"
- Panel format: One of the ASCII rendering styles that uses box-drawing characters for more structured layouts. "The panel format employs box-drawing characters for a visually distinct layout."
- Parameter-efficient training: Fine-tuning approaches that modify a small subset of parameters to reduce compute and memory costs. "We employed Low-Rank Adaptation (LoRA)~\citep{hu2021loralowrankadaptationlarge,peft} for parameter-efficient training"
- Read-Write Asymmetry: Observed phenomenon where models read (interpret) ASCII layouts better than they write (construct) them. "Our evaluation reveals a pronounced ``Read-Write Asymmetry'': LLMs interpret ASCII representations effectively but struggle to produce them from text"
- Representation Alignment: Evaluation measuring how well generated representations match their references across modalities (ASCII↔Desc). "Representation Alignment: For the ASCIIDesc conversion tasks, we measure the correspondence between converted representations."
- scene graphs: Graph-structured representations encoding entities and their relationships within a scene. "we do not explore alternative formats such as coordinate lists or scene graphs"
- self-explanation paradigms: Approaches where models generate explanations (or intermediate artifacts) alongside or before answers to improve reasoning. "The two generation orders mirror established self-explanation paradigms"
- SFTTrainer: A HuggingFace TRL component for supervised fine-tuning of LLMs. "using the SFTTrainer from the HuggingFace TRL library~\citep{vonwerra2022trl}."
- SpaRP PS2: A specific evaluation split (from SpaRP) used for assessing StepGame performance. "StepGame evaluation uses the SpaRP~PS2 1k test split."
- StepGame: A spatial reasoning benchmark focusing on compositional directional navigation tasks. "StepGame \citep{stepGame2022shi,rizvi2024sparc} examines compositional directional navigation"
- Text-native grids: ASCII-based spatial layouts that live entirely in the token space of LLMs. "These text-native grids serve a dual purpose: they act not only as a reasoning source within the context but also as a verifiable representation of all spatial relations."
- Tree-of-Thoughts: A reasoning framework extending CoT by exploring branching solution paths. "and its extensions, such as Tree-of-Thoughts \citep{yao2023tree} and latent reasoning \citep{hao2024training}."
- Two-turn generation: Setting where the ASCII and answer are elicited in separate steps or calls. "two-turn generation, where the second output is elicited via a follow-up prompt."
- Visualization-of-Thought: Methods that externalize a model’s reasoning via symbolic or pixel-level visualizations. "Visualization-of-Thought \citep{wu2024mind, li2025imagine} draws on human mental imagery to generate symbolic or pixel-level visualizations for spatial reasoning."
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs for multimodal understanding. "While integrating visual modalities (VLMs) offers a potential remedy for spatial understanding"
- Zero-shot prompting setting: Evaluation where the model is tested without task-specific examples in the prompt. "we evaluate the model's performance with zero-shot prompting setting."
Collections
Sign up for free to add this paper to one or more collections.

