- The paper demonstrates that removing explicit positional embeddings post-pretraining, followed by rapid recalibration, retains in-context performance and enables zero-shot long-context extension.
- It shows that DroPE achieves up to 4× higher retrieval accuracy on long-context benchmarks like NIAH compared to RoPE scaling methods.
- The study reveals that while positional embeddings expedite training, they are not required for inference, opening new avenues for scalable LLM architecture design.
DroPE: Zero-Shot Context Extension in Pretrained LLMs by Dropping Positional Embeddings
Introduction and Motivation
Current LLMs based on transformers are fundamentally constrained during inference by the fixed sequence lengths used in pretraining, causing sharp failures when deployed on sequences longer than those observed during optimization. These limitations are rooted in the reliance on explicit positional embedding schemes—predominantly Rotary Positional Embeddings (RoPE)—which induce out-of-distribution behavior for unseen sequence positions, breaking generalization and causing attention to collapse to in-distribution spans. While a series of frequency scaling techniques for RoPE (e.g., PI, NTK, YaRN) have been proposed, their effectiveness critically depends on compute-intensive long-context finetuning. This work proposes and thoroughly analyzes DroPE: a method for extending the usable context of pretrained LLMs by dropping their positional embeddings after pretraining and briefly recalibrating the resulting model at the original context length.
Role of Positional Embeddings During Training
An initial theoretical and empirical investigation establishes that explicit positional embeddings like RoPE serve a key optimization function: they inject inductive bias that greatly accelerates convergence during training. In contrast, transformer architectures without explicit PEs (NoPE) possess the same theoretical expressivity, but develop positional bias much more slowly under standard initialization and optimization schemes. Figure 1 quantifies this effect by measuring gradient norms of attention positional bias at initialization across transformer layers. RoPE-equipped models demonstrate substantially higher gradients toward both diagonal and off-diagonal configurations—indicative of faster learning of essential language modeling attention structures.
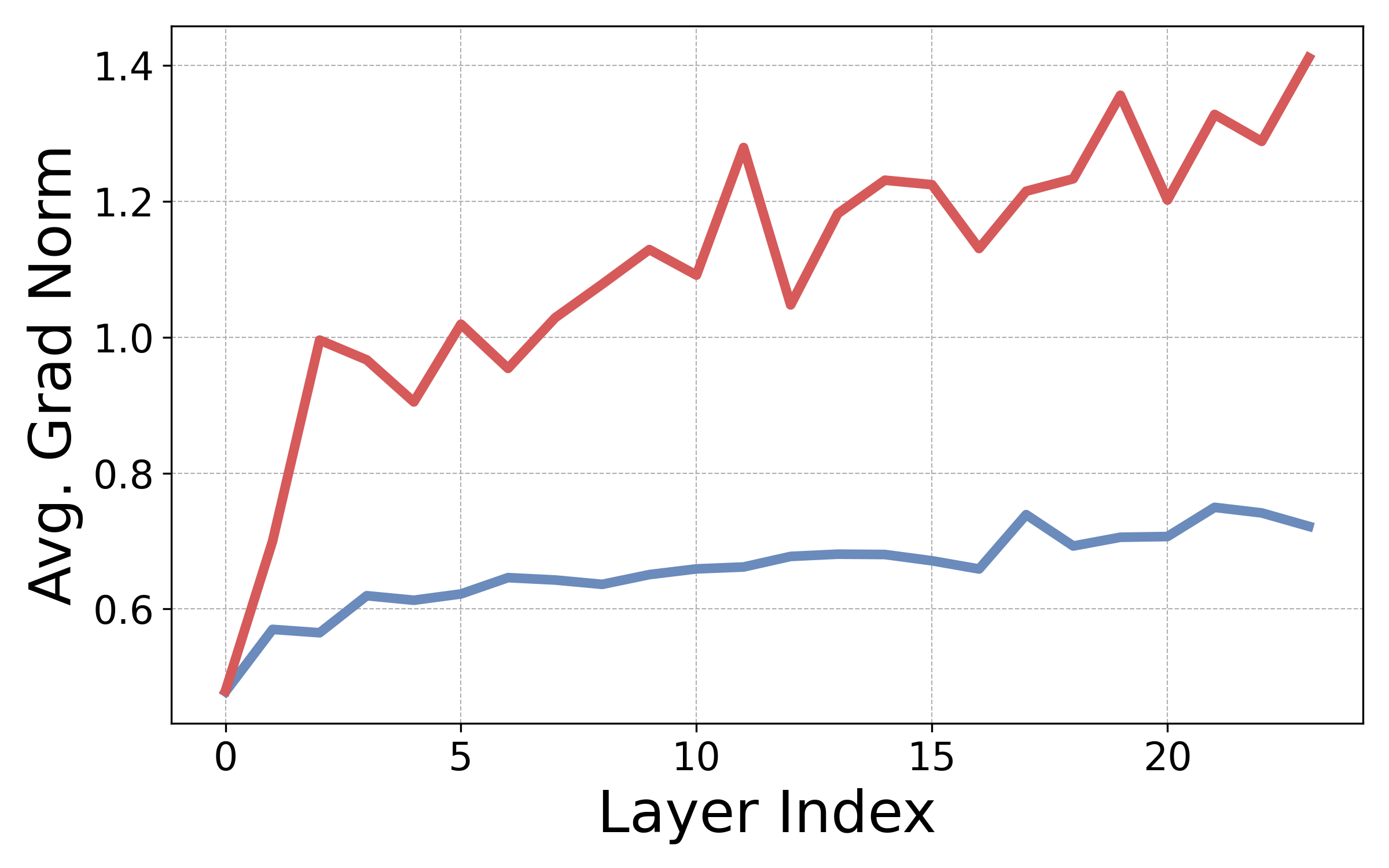
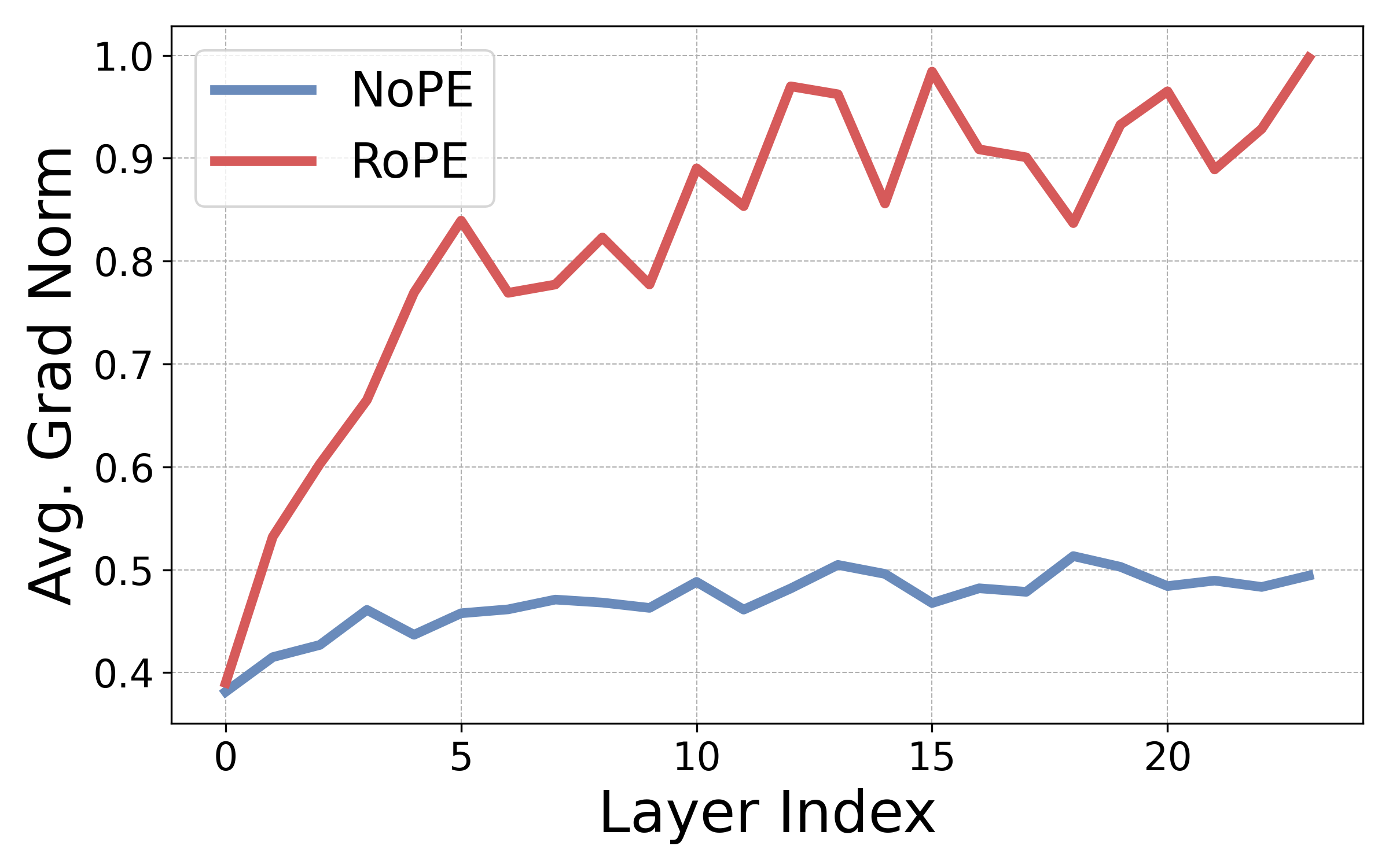
Figure 1: RoPE induces higher gradient magnitudes toward diagonal positional bias at initialization than NoPE, resulting in more efficient convergence of inductive biases needed for language modeling.
Theoretical results corroborate that in NoPE, attention non-uniformity is bottlenecked at initialization due to embedding uniformity and lack of positional signal propagation. Thus, RoPE is a strong bias useful exclusively during optimization but not a necessary architectural component at inference.
Limitations of RoPE and Scaling-Based Extrapolation
RoPE, while crucial for optimization, fundamentally prevents zero-shot extension to sequences longer than those seen in pretraining due to out-of-distribution positional phases. All scaling techniques (PI, NTK, YaRN) compress low-frequency RoPE rotation factors to avoid OOD phases (see Figure 2), which inadvertently shifts long-range semantic attention. Consequently, although these methods can match perplexity on longer sequences, they fail on retrieval tasks requiring reasoning over tokens outside the original training context (as in Figure 3).
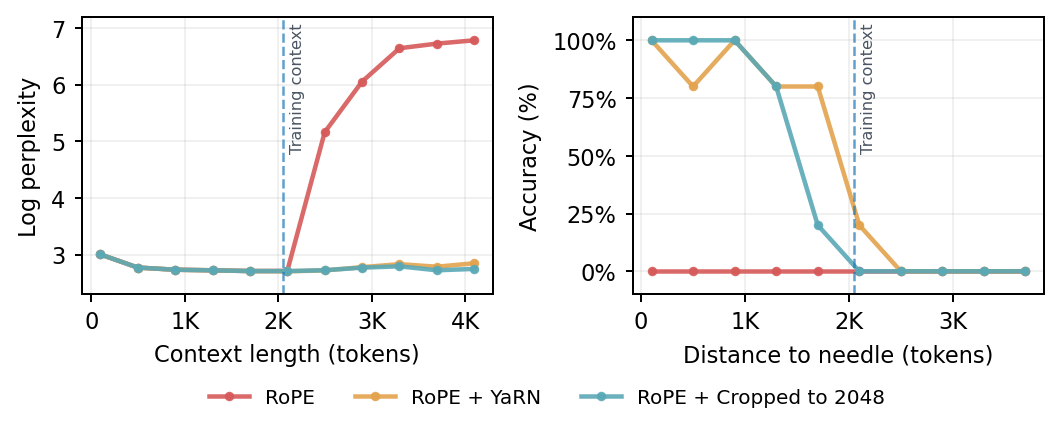
Figure 3: Both YaRN and input cropping maintain perplexity on long sequences but fail at needle-in-a-haystack retrieval when targets are outside the original context.
Empirically, RoPE-scaled models behave equivalently to naively cropping the input context: they ignore tokens positioned beyond the training window. Figure 4, drawn from NIAH probes, shows that RoPE scaling dramatically shifts semantic head attention distributions away from the target, exacerbated at large extension factors, confirming that such methods cannot generalize for retrieval at long distances.

Figure 4: Semantic head attention mass is shifted by YaRN scaling as compared to RoPE, breaking retrieval over long-range tokens.
DroPE: Method and Empirical Evaluation
DroPE leverages the observation that positional embeddings serve primarily as a transient inductive bias for optimization, not as an essential LM component. The procedure: at the end of pretraining, all explicit positional embeddings are removed (the model is transitioned to NoPE), and the model is briefly recalibrated at the original context length. This recalibration phase (typically <1% training budget) rapidly adapts remaining parameters to operate without explicit positional signals.
Empirical results demonstrate that DroPE reproduces the in-context validation perplexity of the original RoPE model within a fraction of training steps, matching or exceeding performance on standard benchmarks (see Figure 5, Figure 6). Notably, when evaluated on zero-shot context extension (up to 8× beyond pretraining), DroPE displays robust performance on long-context benchmarks (LongBench, NIAH, RULER), substantially outperforming all RoPE-scaling techniques and alternative architectures such as NoPE and ALiBi.
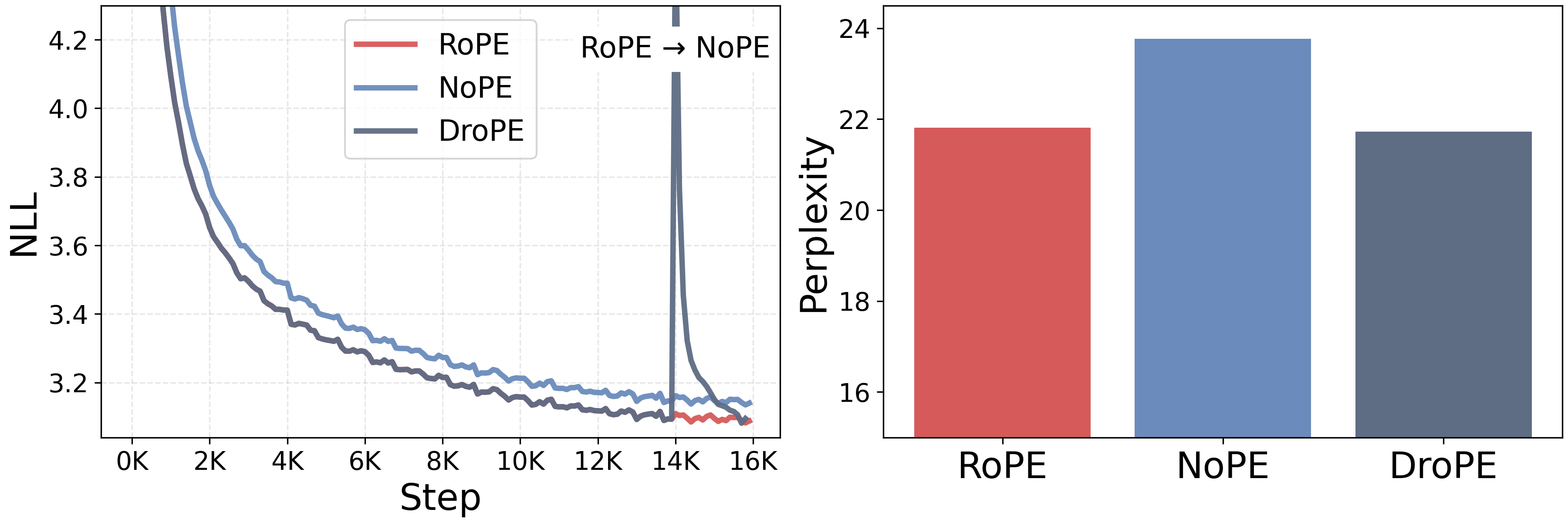
Figure 5: DroPE matches RoPE’s in-context perplexity after a short recalibration phase; the NoPE baseline cannot achieve this performance within the same compute budget.
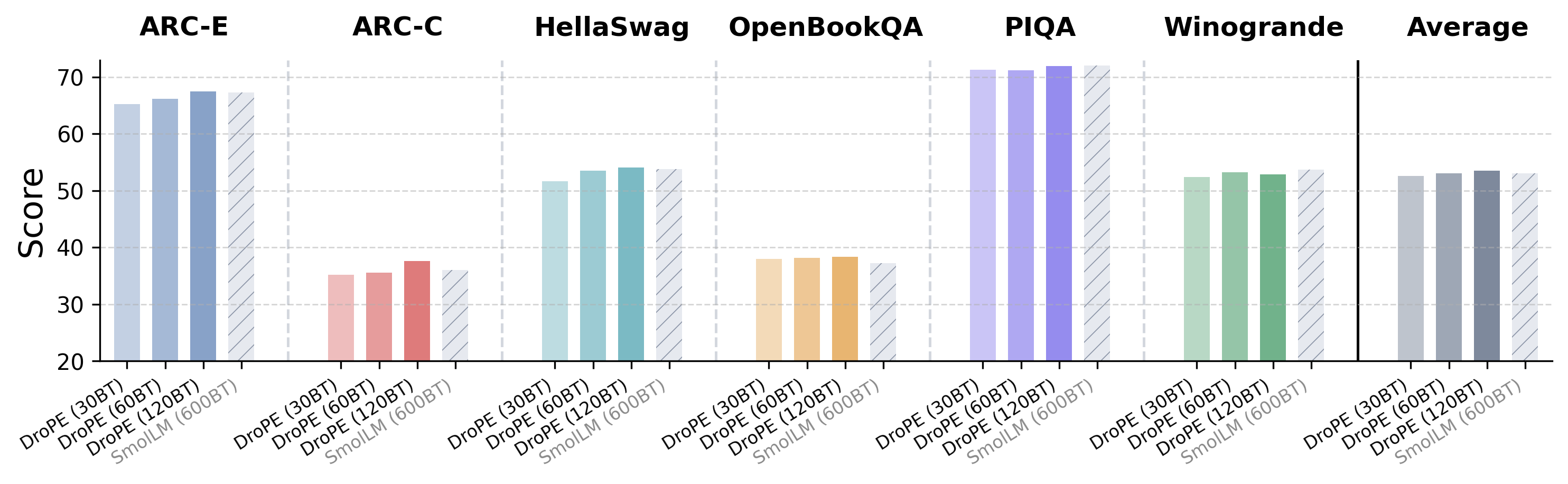
Figure 6: On multiple language modeling benchmarks, recalibrated DroPE models match original in-context performance, supporting the efficacy of the procedure.
Additionally, DroPE is validated in “LLMs in the wild” settings, being successfully applied to thoroughly pretrained public models (SmolLM, Llama2-7B) with only minimal compute. For instance, on NIAH tasks at 2× to 8× pretraining context, DroPE achieves up to 4× higher retrieval accuracy compared to the best RoPE-scaling approaches, with the performance gap increasing for more challenging benchmarks.
Architectural and Optimization Considerations
DroPE’s success relies on two central insights: (1) the sufficiency of training under RoPE for the model’s parameters (except PEs) to internalize position-dependent behaviors, and (2) the viability of rapid adaptation after PE removal with a short recalibration phase, especially when combined with robust normalization (QKNorm), as shown in Figure 7.
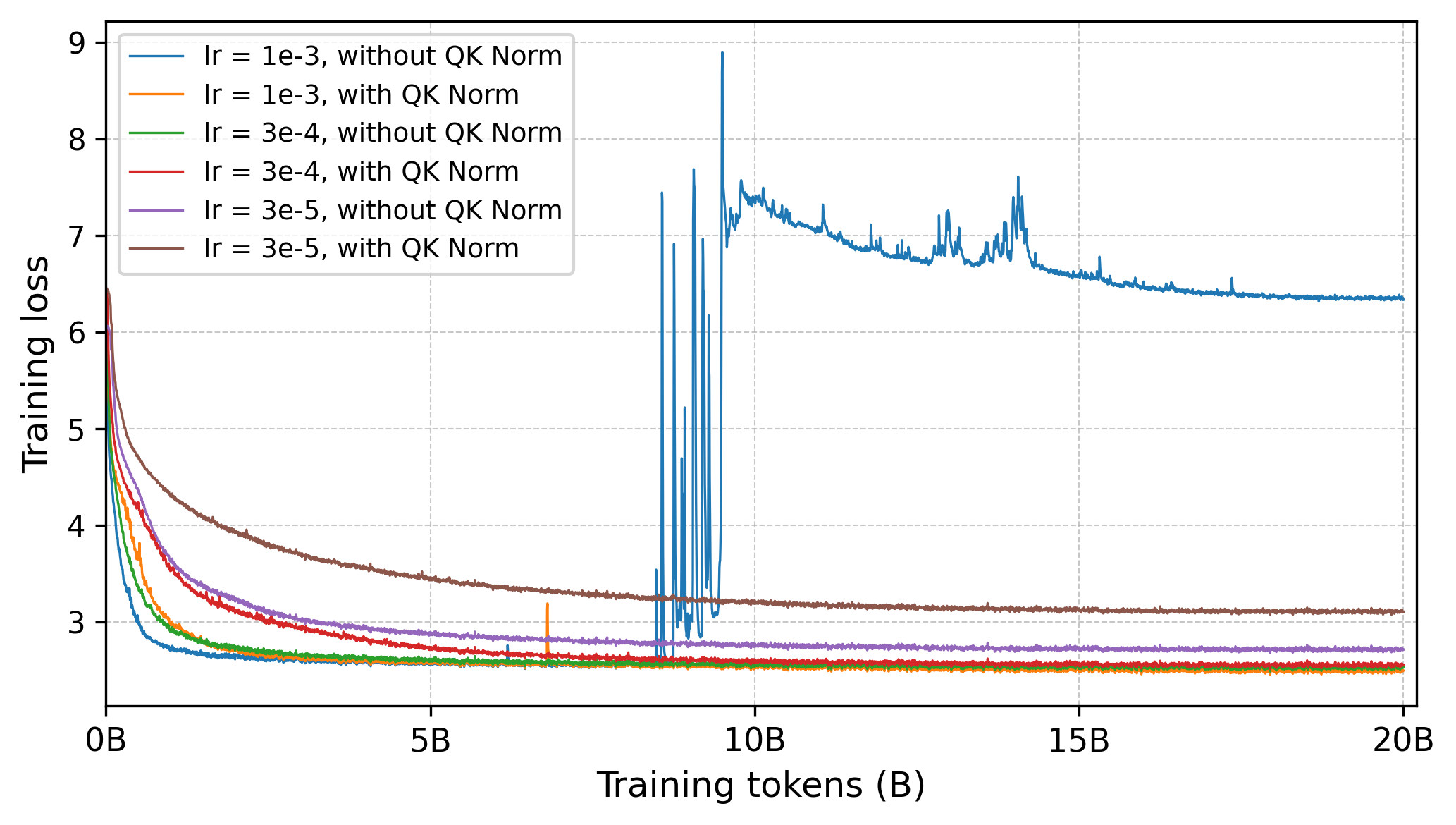
Figure 7: QKNorm enables DroPE recalibration at high learning rates without loss spikes, facilitating rapid adaptation.
Theoretical analyses show the optimal recalibration schedule involves dropping PEs toward the end of pretraining. Early PE removal ablates inductive bias before sufficient generalization is learned, degrading final perplexity. Post-hoc removal and recalibration preserve in-distribution performance while unlocking zero-shot extension.
Implications and Future Directions
DroPE’s results highlight a paradigm shift: explicit positional embeddings, heretofore assumed necessary for transformer inference, are best viewed as a training-time scaffold to accelerate optimization and can be safely eliminated post-training with correct recalibration. This disassociates the pretraining and inference architectures, enabling models to generalize arbitrarily in context length with negligible additional compute and without modification of model weights for new sequences.
Practically, this approach dramatically reduces the need for long-context pretraining and finetuning in LLM deployment pipelines, allowing efficient adaptation of existing RoPE-equipped models to demanding long-context workloads. Theoretically, it motivates further exploration of architectural hybridization, where core architectural biases are leveraged transiently during optimization and purged for generalization at inference.
Open research directions include integrating alternate frequency representations within DroPE, investigating the potential of position-adaptive normalization, and exploring the mechanism by which deep layers internalize positional behaviors during optimization in the presence of strong PE-induced bias.
Conclusion
DroPE demonstrates that explicit positional embeddings—while essential for efficient transformer training—are a hurdle to zero-shot context extension and can be safely omitted at inference after limited recalibration. The resulting models robustly generalize to long-context tasks and outperform all previous RoPE-scaling and alternative positional encoding schemes. DroPE offers a new standard for scalable LLM training and deployment and raises foundational questions about the separation of training dynamics and inference architectures in deep learning.
References
For full citation details, see the original paper: "Extending the Context of Pretrained LLMs by Dropping Their Positional Embeddings" (2512.12167).