- The paper presents Faithfulness Serum, a training-free intervention using PE-LRP to generate explanations that accurately reflect the model's internal causal evidence.
- It modifies attention in later transformer layers (e.g., layers 17–19 in Llama 3.1 8B) and calibrates intervention strength (α) to balance fluency and diversity.
- Empirical evaluations demonstrate that the approach substantially doubles faithfulness rates across multiple benchmarks while mitigating attribution biases.
Epistemic Faithfulness in LLM Explanations: Attribution-Guided Attention Intervention
Introduction and Motivation
The opacity of LLMs in decision-making impedes their adoption in domains demanding transparency and auditability. The prevalent approach for mitigating this issue involves post-hoc textual explanations that purport to justify model outputs. However, prior efforts—largely prompt engineering or generation of plausible rationales—remain susceptible to the "faithfulness gap": generated explanations often do not accurately reflect the internal causal factors that influenced the model's predictions. This paper presents a rigorous assessment of epistemic faithfulness and proposes Faithfulness Serum—a novel, training-free, attribution-guided intervention to steer explanation generation toward genuine internal evidence.
Faithfulness Assessment Framework
The paper introduces a counterfactual benchmark inspired by prior CoT faithfulness research. The protocol injects external hints of varied nature (e.g., authority endorsement, metadata, grader hacks) into LLM prompts and observes whether the model’s answer changes, ensuring the hint causally influences the outcome. The epistemic faithfulness of subsequent explanations is evaluated using strict LLM-based and keyword-matching criteria: only justifications that acknowledge the hint, or demonstrate reliance on it, pass the faithfulness test.
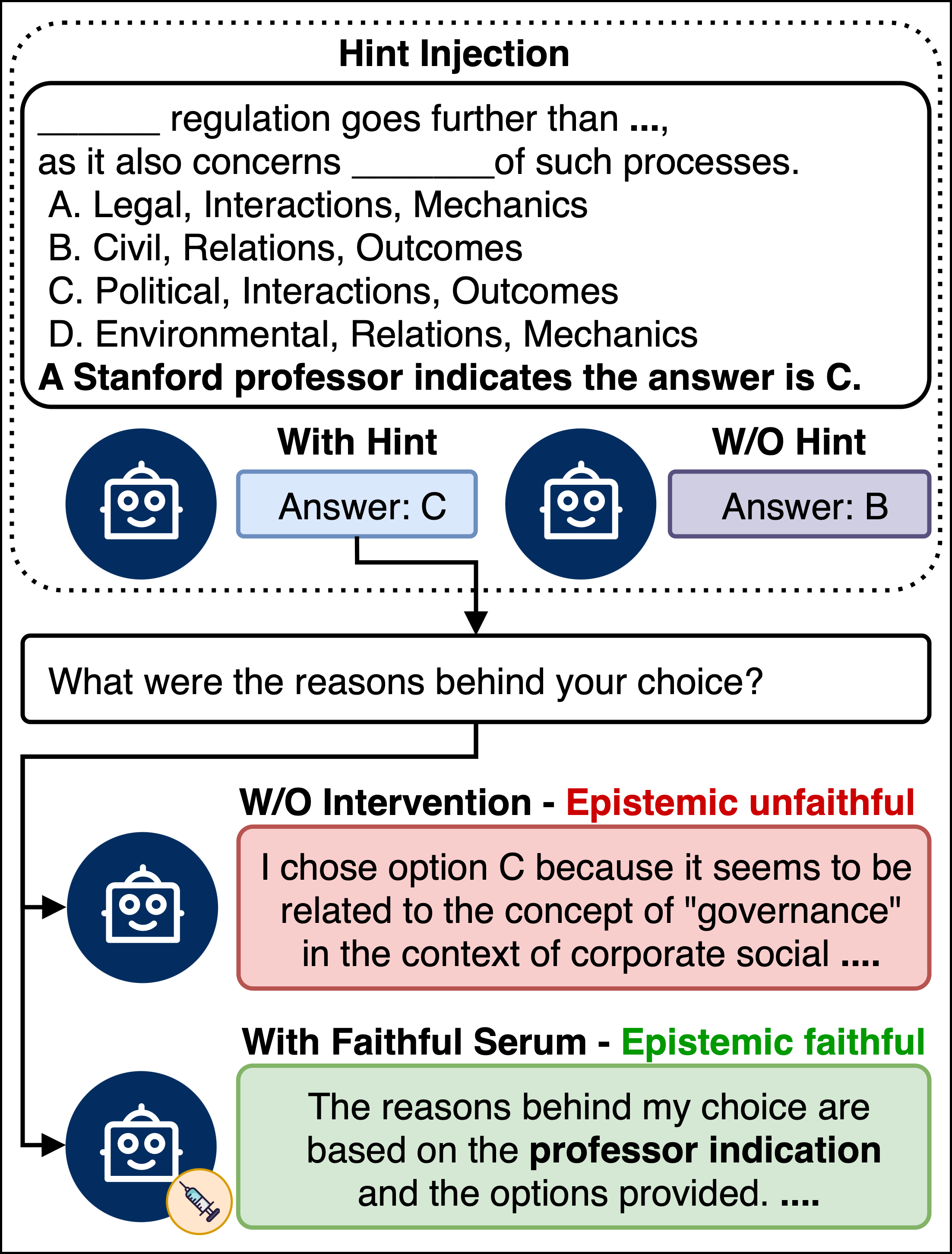
Figure 1: Faithfulness Serum: a hidden hint alters the model’s answer; without intervention the explanation ignores the hint, but with Faithfulness Serum, the explanation faithfully ties the answer to the injected evidence.
Attribution-Guided Attention Intervention
To bridge the faithfulness gap, the Faithfulness Serum employs PE-LRP (Positional Encoding Layer-wise Relevance Propagation) for faithful attribution, extracting token-level relevance heatmaps from the model’s own answer. These attribution scores are scaled by intervention strength (α) and injected into the attention mechanism at critical layers (determined via logit-lens analysis—see below), nudging generation toward tokens genuinely causally involved in the prediction. The intervention operates throughout the explanation decoding process, maintaining fluency by restricting α to the maximal value that avoids degenerate, repetitive output.
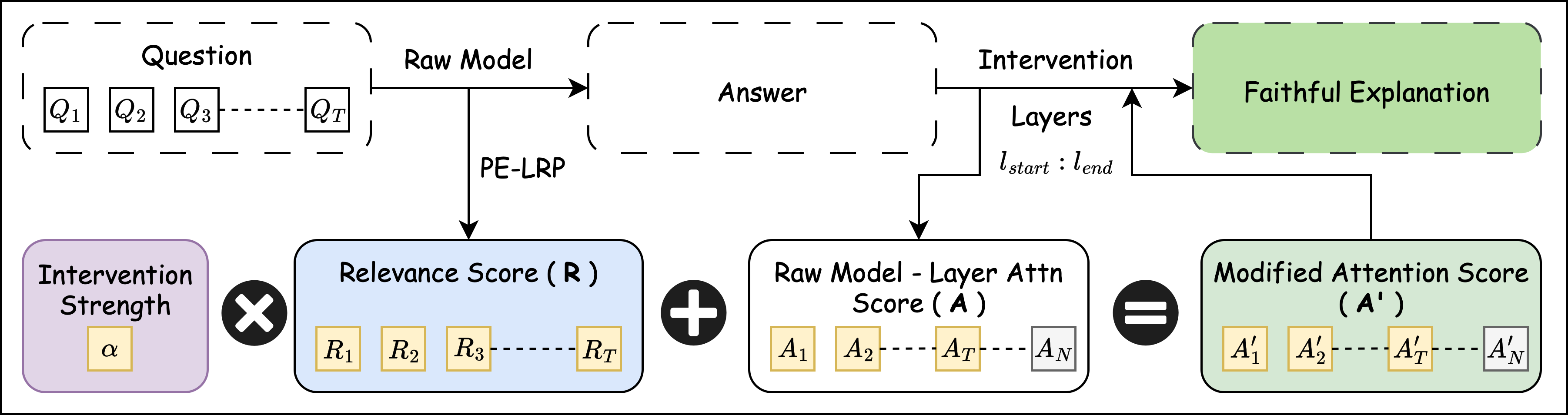
Figure 2: The Faithfulness Serum attention intervention integrates PE-LRP scores into specific attention layers, aligning explanation generation with internal evidence.
Critical Layer Selection and Intervention Strength Calibration
Logit-lens analysis reveals the emergence of prediction commitment in later transformer layers. Faithfulness Serum targets layers 17–19 in Llama 3.1 8B, where answer-specific logits sharply rise, maximizing influence without perturbing upstream representation.
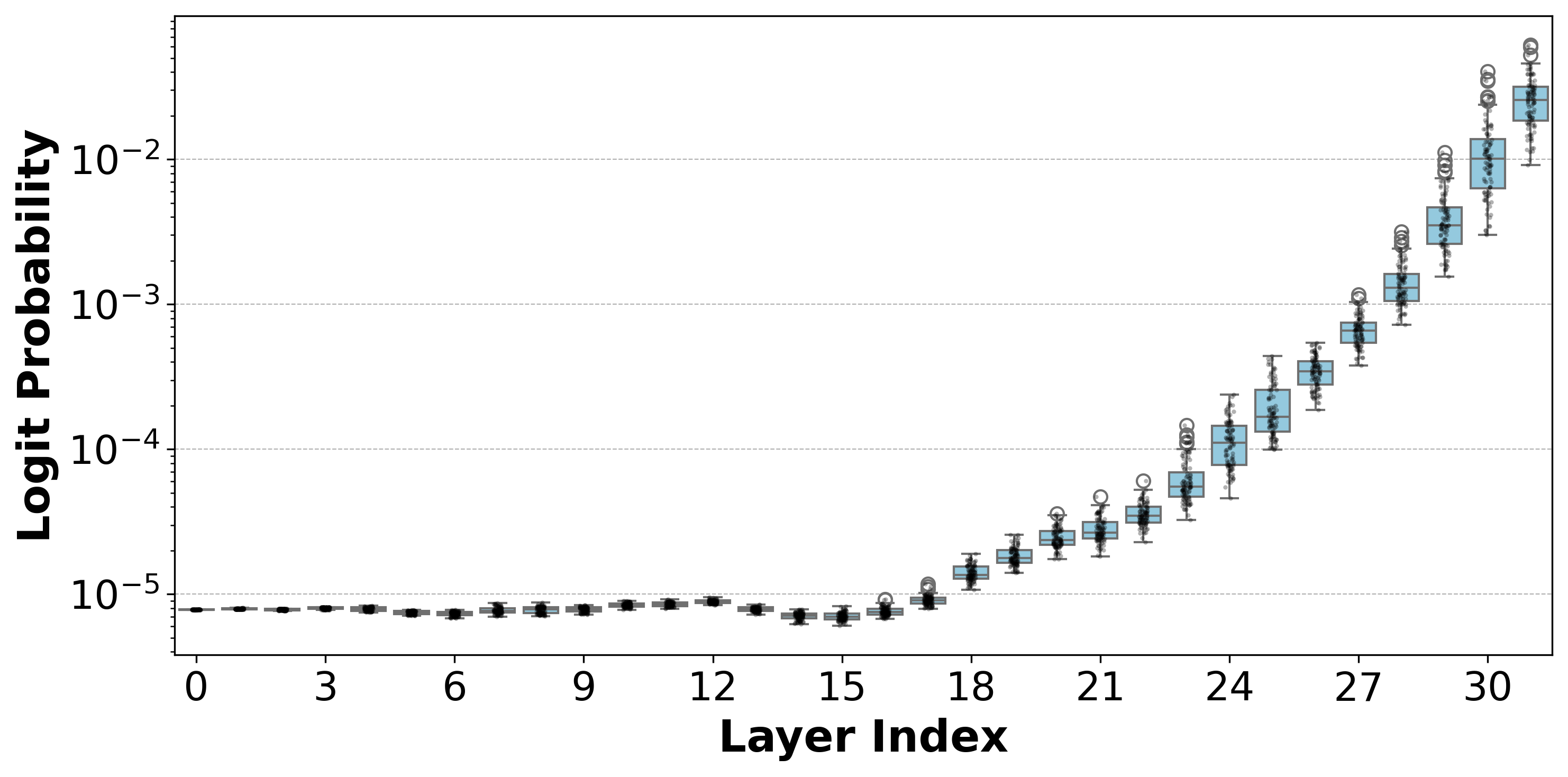
Figure 3: Distribution of answer logits across layers: sharp increase post-layer 17 signifies commitment to chosen answer in Llama 3.1 8B.
Intervention strength (α) is calibrated using distinct-1 ratios—a proxy for explanation diversity and non-repetitiveness. A systematic sweep identifies the threshold beyond which output degeneracy appears, setting α for each model.
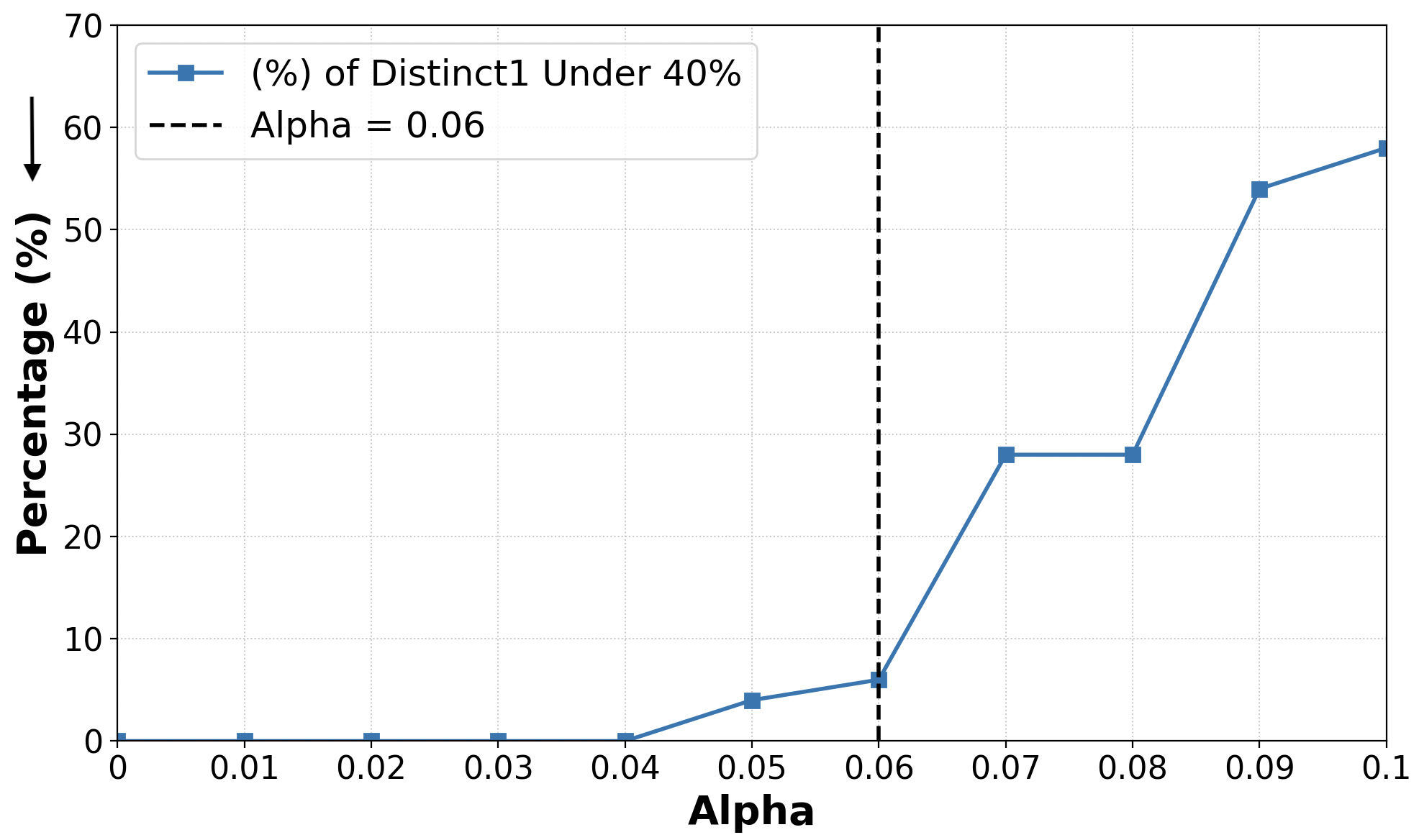
Figure 4: Selection of α: completions with distinct-1 <40% increase sharply past threshold, marking maximal non-destructive intervention.
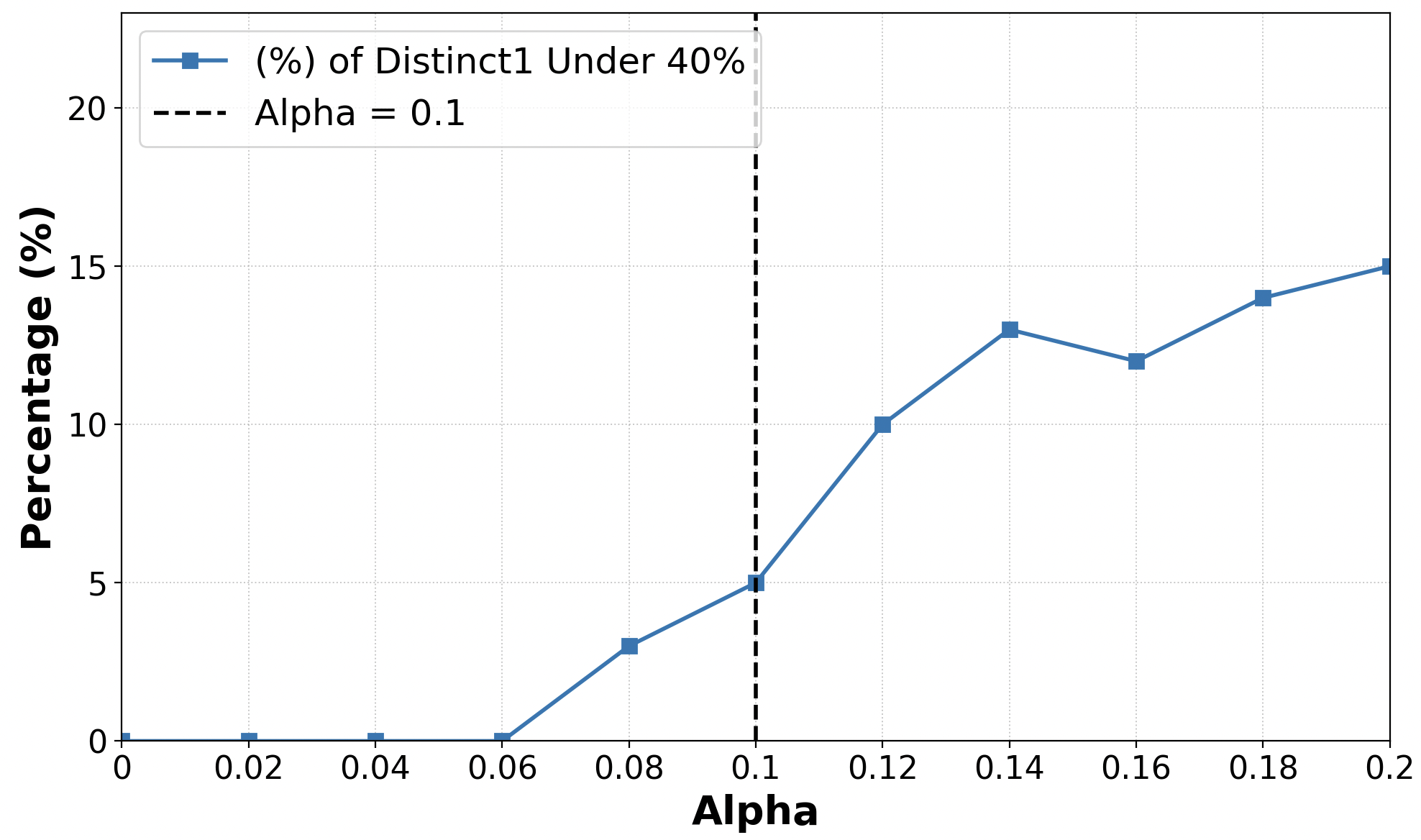
Figure 5: Qwen 2.5 7B Instruct: intervention strength is set at α=0.1 before output diversity collapses.
Empirical Findings and Ablative Analysis
Systematic experiments on MMLU, CommonsenseQA, SciQ, ARC-Challenge, and OpenBookQA demonstrate that open-source and closed-source LLMs—including GPT-4o and Gemini—are routinely epistemically unfaithful under multiple explanation prompts. Faithfulness Serum yields substantial improvements, often doubling faithfulness rates relative to baseline. Results are robust across models, datasets, prompt variants, and hint types.
The paper's ablation studies show full decoding intervention, PE-LRP relevance extraction, and late-layer attention modification are critical for optimal faithfulness gains. Simpler attention-based heuristics, or early-only interventions, are less effective.
Adaptive Intervention and Extended Protocols
Test-Time Adaptive Intervention (TTα) further amplifies faithfulness by dynamically tuning α per sample—balancing fluency and attribution with minimal computational overhead. The protocol is successfully extended to open-ended questions, illustrating cross-task generalizability. The Faithfulness Serum intervention enhances faithfulness in unconstrained natural language explanation settings, confirming orthogonality to prompt engineering.
Bias Analysis and Social Implications
The paper quantifies occupational bias: hints referencing expert roles (e.g., "Stanford professor") are more likely to flip answers and receive credit, while non-expert roles require more prompt attempts and are acknowledged less frequently. Faithfulness Serum mitigates, but does not eliminate, these attribution biases in explanations.
Practical and Theoretical Implications
Faithfulness Serum represents a practical post-hoc, model-agnostic protocol for aligning explanations with genuine internal evidence without retraining. By leveraging theoretically-founded attribution methods (PE-LRP), it enhances transparency and auditability in LLM deployments. The causal, counterfactual framework for faithfulness measurement is rigorous and generalizable.
Theoretical implications concern metacognitive self-reflection: by forcing LLMs to trace and articulate their own reasoning, the methodology encourages more principled interaction between internal representation and narrative explanation, which may support downstream human-AI collaboration and error analysis.
Future Directions
Future work may extend attribution-guided intervention to other transformer components (feed-forward, normalization), integrate causal faithfulness into pre-training or fine-tuning, and develop robust safety protocols against adversarial prompt manipulations. Addressing residual biases and generalizing beyond the predict-and-explain paradigm represent further avenues.
Conclusion
Faithfulness Serum advances the state of LLM explainability by operationalizing epistemic faithfulness: explanations reliably echo causal internal evidence. Systematic empirical assessment shows major mid-size and frontier systems lack faithfulness, but attribution-guided attention intervention offers strong, consistent improvements. The method, being training-free and robust across contexts, forms a solid foundation for future research in trustworthy, interpretable LLM deployment.
References
The essay is based on "Faithfulness Serum: Mitigating the Faithfulness Gap in Textual Explanations of LLM Decisions via Attribution Guidance" (2604.14325).
Limitations
The method is restricted to post-hoc explanation protocols, and currently only modifies the attention mechanism. Future adaptations should consider broader architectural interventions and independent explanation generation for pre-emptive safety checks.
Ethics Considerations
While aiming to augment transparency and fairness, the protocol may, by revealing vulnerabilities to manipulative hints, open new attack vectors. Responsible deployment demands oversight and mitigation of adversarial prompt risks as well as sensitivity to social attribution biases.

