Seedance 1.5 pro: A Native Audio-Visual Joint Generation Foundation Model
Abstract: Recent strides in video generation have paved the way for unified audio-visual generation. In this work, we present Seedance 1.5 pro, a foundational model engineered specifically for native, joint audio-video generation. Leveraging a dual-branch Diffusion Transformer architecture, the model integrates a cross-modal joint module with a specialized multi-stage data pipeline, achieving exceptional audio-visual synchronization and superior generation quality. To ensure practical utility, we implement meticulous post-training optimizations, including Supervised Fine-Tuning (SFT) on high-quality datasets and Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models. Furthermore, we introduce an acceleration framework that boosts inference speed by over 10X. Seedance 1.5 pro distinguishes itself through precise multilingual and dialect lip-syncing, dynamic cinematic camera control, and enhanced narrative coherence, positioning it as a robust engine for professional-grade content creation. Seedance 1.5 pro is now accessible on Volcano Engine at https://console.volcengine.com/ark/region:ark+cn-beijing/experience/vision?type=GenVideo.
First 10 authors:




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Seedance 1.5 Pro: A simple explanation
What is this paper about?
This paper introduces Seedance 1.5 Pro, an AI model that can create videos and their soundtracks at the same time. Instead of making silent videos and adding sound later, it builds both together so the lips, music, and sound effects match perfectly. It’s designed for professional-quality results, like short films, ads, and social media clips.
What questions is the paper trying to answer?
Here are the main goals, in everyday terms:
- Can we build one model that makes video and audio together so they line up perfectly?
- Can it follow instructions well (from text or images) and still be creative and realistic?
- Can it speak and lip-sync in many languages and dialects accurately?
- Can it run fast enough to be practical for creators, without losing quality?
How did the researchers build it?
To meet these goals, the team combined data, model design, training, and speed-ups. Think of it like training a talented “multimedia director” who sees and hears at once.
- A high-quality data pipeline:
- They filtered and organized lots of video–audio examples.
- They added rich “captions” for both visuals and sounds, like a director’s notes describing what is seen and heard, to teach the model cause-and-effect across time.
- They scheduled easier-to-harder training steps (like school grades) to build skills gradually.
- A unified model that “thinks in sight and sound”:
- The core is a Diffusion Transformer with two branches—one for video and one for audio—that constantly “talk” to each other. Imagine two teammates (the “eyes” and the “ears”) working in sync through a shared meeting room.
- This setup helps the model keep timing and meaning consistent across both streams (for example, mouths move when speech happens, and a door slam sound lands exactly when the door closes).
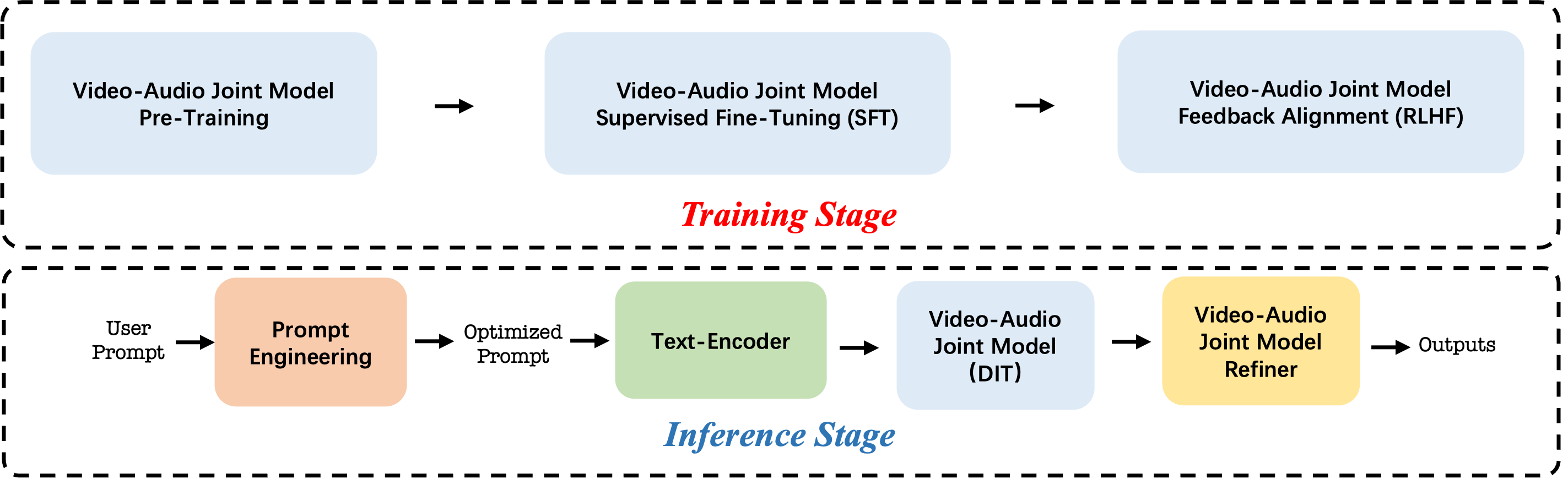
- Post-training with human feedback:
- First, they fine-tuned on carefully picked, high-quality examples (Supervised Fine-Tuning).
- Then, they used Reinforcement Learning from Human Feedback (RLHF): humans rate outputs across many dimensions (motion, look, sound, sync, etc.), and the model learns to prefer what people like. Think of it as a coach giving multi-score report cards to guide improvement.
- They also sped up this feedback training so it runs about 3× faster.
- Making it fast to use:
- They used “distillation” (like a top teacher training a faster student) so the model can get good results with fewer steps.
- They reduced how many calculations are needed per video (fewer “Number of Function Evaluations”).
- They applied techniques like quantization and parallel processing so it runs more than 10× faster at generation time, while keeping quality high.
What did they find, and why does it matter?
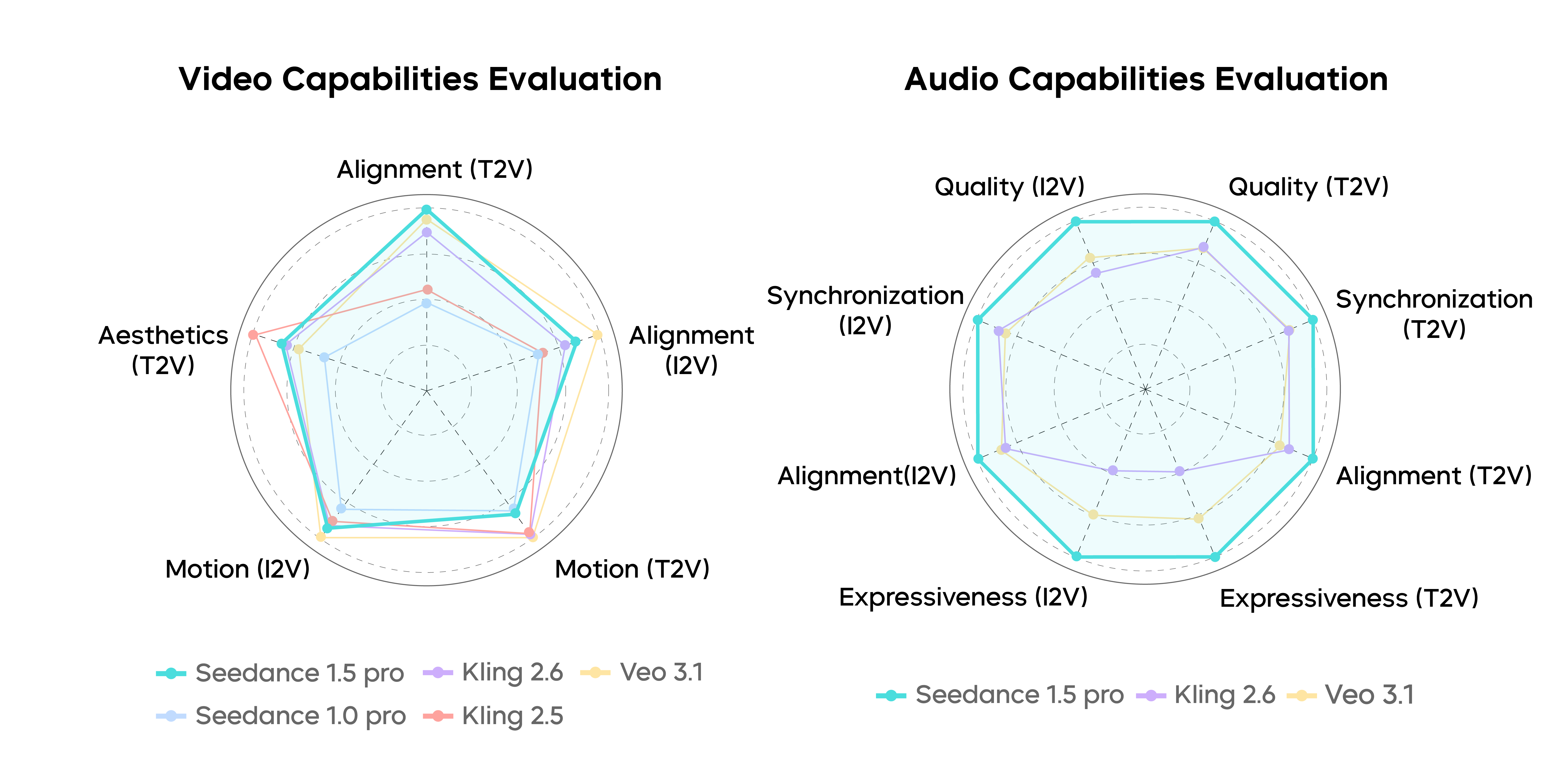
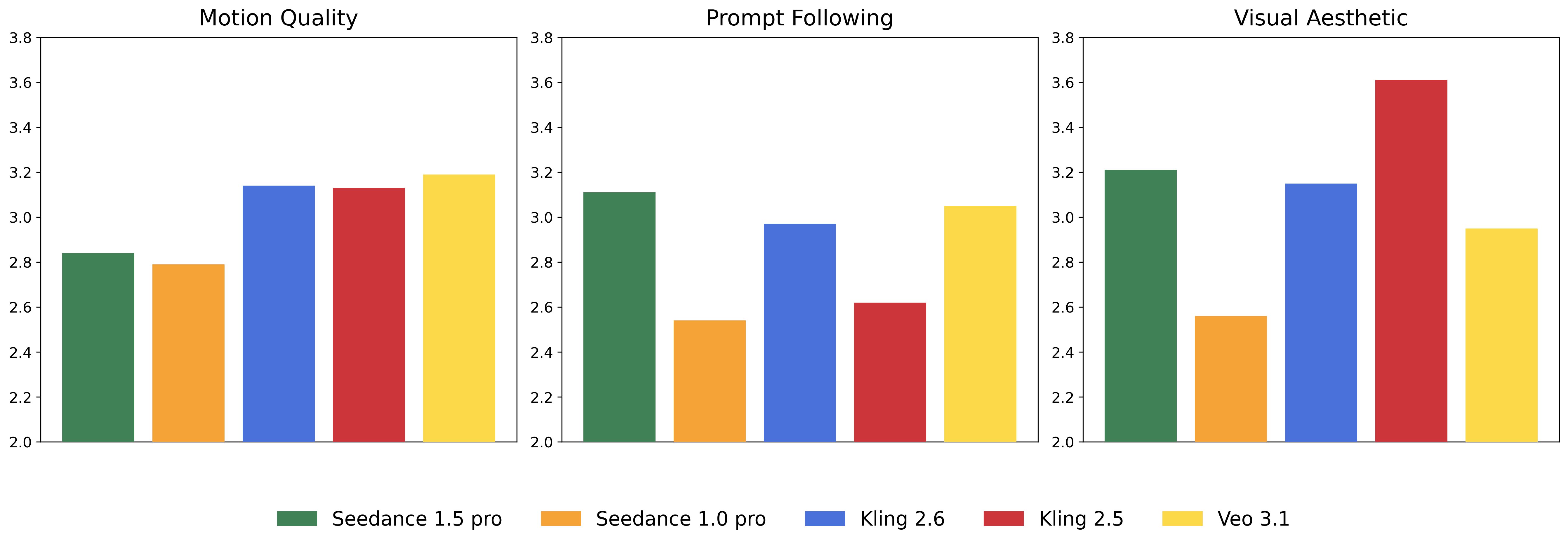
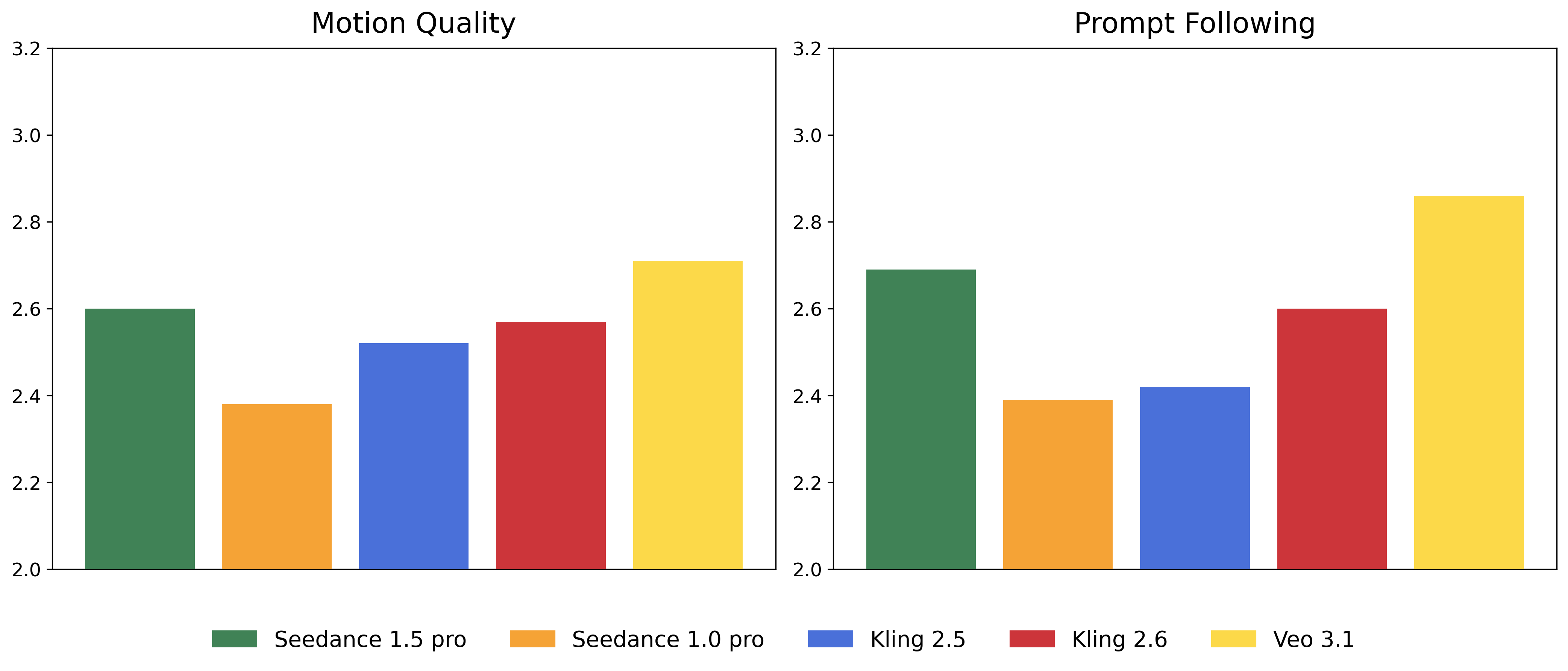
The team tested the model with a new evaluation setup (SeedVideoBench 1.5) that scores both video and audio. Experts from film and design helped define what “good” looks like.
- Better instruction following and strong visuals:
- In text-to-video tests, Seedance 1.5 Pro leads in following user instructions while keeping visuals attractive and motion vivid.
- In image-to-video tests, it stays competitive with top systems.
- Precise audio–visual sync:
- Lip movements match speech well.
- Sound effects and actions line up (e.g., footsteps match steps).
- This makes videos feel more real and “immersive,” like finished productions rather than stitched-together parts.
- Strong multilingual and dialect support:
- It performs especially well in Chinese, including dialects like Sichuanese, Taiwan Mandarin, Cantonese, and Shanghainese.
- Speech sounds clear and natural, with fewer mistakes like mispronunciations or dropped syllables.
- Cinematic camera control:
- It can simulate advanced camera moves (like dolly zooms and long takes) and smooth transitions, helping tell stories more dramatically.
- Balanced audio expressiveness:
- Compared to some systems that may overdo emotions, Seedance keeps the tone controlled and consistent—useful for professional-grade storytelling where stability matters.
- Speed without big quality loss:
- Thanks to distillation and system optimizations, it generates results over 10× faster, making it more practical for real-world workflows.
What could this change in the real world?
- Faster, more reliable creative tools:
- Because it makes video and audio together—and does it quickly—creators can iterate faster on story, mood, and timing.
- Professional-ready outputs:
- Better lip-sync, camera work, and audio quality make outputs feel like complete productions, not demos.
- Wider use cases:
- Useful for short dramas, ads, social media videos, and even styles like traditional stage opera, where timing and voice cadence really matter.
- Multilingual storytelling:
- Accurate dialects and language delivery open doors for culturally rich content.
Overall, Seedance 1.5 Pro pushes video generation from “pretty visuals” to full, well-timed audio–visual storytelling. It aims to be a practical engine for professional content creation and is being rolled out on platforms so creators can use it in real projects.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- Architecture transparency: precise dual-branch MMDiT design details (layer counts, modality-specific blocks, cross-modal joint module topology, attention routing, temporal positional encoding, audio-visual fusion points) are not disclosed.
- Joint objective formulation: loss functions for native audio-video training (e.g., diffusion/flow objectives per modality, cross-modal consistency losses, weighting schedules) and their stabilization strategies are unspecified.
- Audio representation: the paper does not define whether audio is modeled as waveform, spectrogram, parametric codec, or via a vocoder pipeline; sample rates, bit-depth, and reconstruction method remain unknown.
- Sampling and NFE specifics: baseline Number of Function Evaluations (NFE), sampler type(s), joint vs unimodal sampling schedules, and per-modality step allocation are not reported.
- Data scale and composition: dataset sizes, source domains, licensing status, and mixture ratios across tasks (T2VA/I2VA/T2V/I2V) and modalities are absent.
- Multilingual/dialect coverage: distribution and volume per language/dialect (e.g., Chinese regional varieties vs non-Chinese languages), speaker diversity (age, gender), and balance across accents are not quantified.
- Captioning system specifics: teacher models, alignment strategies (audio-visual forced alignment), caption granularity, error rates, and audit of caption quality are not described.
- Curriculum schedule: the curriculum-based data scheduling policy (stages, criteria, performance impact) is not specified or ablated.
- Privacy and consent: processes for PII removal in audio/video, consent controls for voice data, and dataset governance policies are not documented.
- Bias and fairness: no analysis of demographic, linguistic, or accent bias; per-group performance breakdowns and fairness diagnostics are missing.
- RLHF reward model: exact reward dimensions, aggregation/calibration (e.g., weighted sum, Pareto methods), annotator guidelines, inter-rater reliability, and robustness of the reward to distribution shift are not reported.
- RLHF ablations: contribution of SFT vs RLHF to motion vividness, lip-sync, audio quality, and instruction adherence is not isolated via controlled ablations.
- RLHF safety shaping: whether rewards penalize unsafe or deceptive audio (e.g., unauthorized voice cloning) and how safety criteria are enforced is unclear.
- Acceleration trade-offs: distillation targets, teacher-student configuration, quality vs speed curves, and the precise 10× speedup context (resolution, duration, hardware) are not quantified.
- Quantization details: bit-widths, per-channel vs per-tensor schemes, dynamic vs static quantization, and their impact on audio artifacts and visual fidelity are not provided.
- Hardware and throughput: latency, memory footprint, and throughput across GPUs/TPUs, consumer hardware, and edge devices at standard settings (e.g., 1080p@24/30 fps, 60s video) are not reported.
- Streaming and real-time: support for streaming generation (progressive audio-video output, low-latency lip-sync) and its engineering constraints are unaddressed.
- Evaluation reproducibility: SeedVideoBench 1.5 prompts, clips, annotation rubrics, and raw scores are not released; baseline settings (resolution, duration, steps) per model are not standardized publicly.
- Statistical rigor: confidence intervals, significance tests, and inter-annotator agreement (e.g., Cohen’s kappa) for human evaluations are missing.
- Objective metrics: no reporting of established metrics (e.g., LSE-C/LSE-D for lip-sync, FAD/PESQ/STOI/MUSHRA for audio, FVD/VMAF/LPIPS for video) to complement human judgments.
- Multilingual intelligibility: speech intelligibility via ASR WER per language/dialect, code-switch handling, and accent classification accuracy are not evaluated.
- Camera control interface: the mechanism for specifying camera moves (APIs, control tokens, trajectories), execution accuracy, and failure cases are not defined or measured.
- Narrative coherence at scale: quantitative measures of cross-shot continuity (character identity, voice consistency, style persistence) over multi-shot/long-horizon sequences are not presented.
- Multi-speaker handling: speaker diarization, voice identity control, and accurate assignment of lip motions to multiple concurrent speakers remain unspecified and unevaluated.
- Audio mixing pipeline: separation and controllability of speech/SFX/BGM, loudness normalization (e.g., LUFS targets), dynamic range management, and clipping prevention are not described.
- Spatial audio: support for stereo vs multichannel (e.g., 5.1), spatialization methods, and alignment of spatial cues with camera movement are unexplored.
- Robustness: performance under occlusion, rapid speech, profile views, high-motion scenes, noisy prompts, and out-of-distribution content is not analyzed; failure modes are mentioned but not quantified.
- Slow-motion trade-off: the paper critiques slow-motion “stability hacks” but does not propose or evaluate principled metrics or methods to preserve vividness without instability.
- Scalability and cost: training compute (GPU-hours, FLOPs), data scaling laws, carbon footprint, and cost-efficiency relative to baselines are unknown.
- Safety and provenance: watermarking, content provenance, detection APIs, and safeguards against misuse (e.g., deepfake voices, copyrighted music) are not detailed.
- Content licensing: policies to prevent unauthorized reproduction of copyrighted music or voices and dataset compliance auditing are not covered.
- Editing workflows: capabilities for post-generation editing (locking audio while re-generating video, re-dubbing, re-timing, BGM replacement) and toolchain integration are unspecified.
- Script alignment: support for timecoded script/subtitle alignment (forced alignment, prosody control) and metrics for timing accuracy are not provided.
- Product constraints: operational limits (max duration, resolution/fps, audio sample rate/bit-depth), supported export formats, and API quotas/rate limits are not stated.
- Comparability with baselines: whether prompts were identical (language parity, translations), matched generation budgets (steps, duration), and fair access to audio generation across baselines is unclear.
- Release and reproducibility: code, model weights, training recipes, and curated datasets are not released; independent reproduction of claims is currently infeasible.
- Generalization breadth: beyond Chinese-centric scenarios, comprehensive evaluation in other languages, genres (e.g., musicals, documentary), and complex SFX/instrumental music remains untested.
Practical Applications
Immediate Applications
Below are applications that can be deployed now, leveraging Seedance 1.5 pro’s native joint audio–video generation, multilingual/dialect lip-syncing, cinematic camera control, narrative coherence, SFT+RLHF post-training, and >10× inference acceleration. Access is available via Volcano Engine and planned integrations with Doubao and Jimeng.
- Media and Entertainment (Film, Ads, Social) — Rapid production of micro-dramas, ad spots, trailers, and story-driven social clips with coherent audio–visual narration, precise lip-sync, and professional camera movements — Tools/Workflow: Volcano Engine API; Doubao/Jimeng integrations; NLE plug-ins (e.g., CapCut/Jianying); template-driven prompt libraries — Assumptions/Dependencies: Platform access; brand/legal approvals; rights for voices/music; compute quotas; safety/watermarking policies.
- Localization and Dubbing — High-quality multilingual/dialect dubbing of existing videos with accurate prosody and lip synchronization (e.g., Mandarin, Cantonese, Sichuanese, Taiwan Mandarin, Shanghainese) — Tools/Workflow: “LipSync Studio” pipeline that ingests reference video and scripts; batch processing via API; automated QC against SeedVideoBench 1.5 metrics — Assumptions/Dependencies: Licensed voice timbres; accurate transcripts/translations; watermarking to deter misuse; domain performance may be strongest for Chinese dialects.
- Social Creator Economy — One-click generation of shorts with intent-aligned dialogue, balanced emotional delivery, and auto-aligned BGM/SFX — Tools/Workflow: Creator-facing templates; prompt libraries; mobile app integration (Jimeng/Jianying) with real-time preview enabled by acceleration — Assumptions/Dependencies: Safety filters; content moderation; prompt literacy; potential limitations in non-Chinese languages or niche genres.
- Corporate Communications and Training — Multi-lingual instructional and compliance videos with synchronized narration, clear camera framing, and coherent pacing — Tools/Workflow: Enterprise CMS plug-ins; review-and-approve loops with auto-quality scoring (alignment, clarity, sync) — Assumptions/Dependencies: Human review for factual accuracy; regulatory compliance; retention of legal disclaimers.
- E-commerce and Product Marketing — Batch generation of product demo videos (dolly zooms, tracking shots) with intent-aligned voiceovers and synchronized SFX — Tools/Workflow: Storefront CMS integration; product feed ingestion; A/B variants scored by preference models — Assumptions/Dependencies: Accurate product data; brand style constraints; governance around synthetic claims.
- Education and Language Learning — Dialect-accurate conversational scenes for listening practice and cultural immersion; multi-lingual lesson shorts with coherent narrative — Tools/Workflow: LMS integration; content packs by difficulty and dialect; auto-captioning and dubbed variants — Assumptions/Dependencies: Pedagogical oversight; linguistic QA; bias audits for regional dialect representation.
- Game Development and XR — Previsualization of cutscenes with cinematic camera paths, synced dialogue, and atmosphere/sound design — Tools/Workflow: Engine plug-ins to export/import camera trajectories; storyboard-to-previz workflows — Assumptions/Dependencies: Asset pipeline compatibility; timeline editing; consistent character rendering across shots.
- Film/TV Pre-Production (Previs) — Multi-shot narrative prototypes with autonomous camera scheduling and balanced emotional audio — Tools/Workflow: “AV co-director” workspace that turns shot lists/story beats into animatics; rapid iteration with 10× acceleration — Assumptions/Dependencies: Human director supervision; identity and style consistency controls; scene continuity management.
- Audio Post Production — Automated BGM and SFX alignment to visuals, with expressiveness controls (stable tone vs. dramatic peaks) — Tools/Workflow: DAW plug-ins; “Auto-BGM/SFX aligner” that scores audio–visual sync and atmosphere fit — Assumptions/Dependencies: Genre/style licensing; human fine-tuning for final mix; platform support for high-bitrate audio.
- Quality Evaluation and Benchmarking (Academia/Industry) — Adopt SeedVideoBench 1.5’s multi-dimensional video/audio criteria to score outputs and guide model iteration — Tools/Workflow: “AV Quality Scorer” services; expert-label taxonomy; side-by-side (GSB) comparisons — Assumptions/Dependencies: Access to benchmark artifacts; calibration for non-Chinese contexts; inter-rater reliability.
- Accessibility and Localization at Scale — Dubbed versions of public information, training, and documentary content for regional audiences — Tools/Workflow: Auto-caption (SRT) generation; lip-synced dubbed tracks; QA-scan for linguistic and timing accuracy — Assumptions/Dependencies: Verified translations; accessibility standards; misuse prevention (deepfake risks).
Long-Term Applications
Below are applications that require further research, scaling, real-time capability, or policy development. They build on Seedance 1.5 pro’s architecture, reward modeling, and acceleration but need additional work on robustness, latency, safety, and multi-domain coverage.
- Real-Time Interactive Avatars (Customer Service, Education) — Low-latency, dialect-accurate agents with live lip-sync, intent-aligned speech, and emotional balance — Potential Tools/Products: “Live AV Agent” stack with streaming generation, guardrails, and audit logs — Assumptions/Dependencies: Sub-100 ms end-to-end latency; robust content filters; identity protection; expanded language coverage beyond Chinese dialects.
- Live Broadcast Augmentation — Dynamic camera planning, expressive audio, and SFX generation during live streams (sports, events, shopping) — Potential Tools/Products: “Live Cinematics” co-pilot for streamers — Assumptions/Dependencies: Further acceleration; fail-safe moderation; integration with broadcast encoders.
- Synthetic Data Generation for Research — Large-scale, perfectly synced audio–visual datasets for training lip-reading, ASR-visual fusion, and multi-modal alignment models — Potential Tools/Products: “AV Data Fabric” generator with controllable prosody, scenes, and camera paths — Assumptions/Dependencies: Dataset licensing frameworks; diversity controls; provenance/watermarking standards to avoid data contamination.
- Healthcare Communication and Teletherapy — Empathetic, culturally adapted explainer videos and therapy avatars with controlled expressiveness — Potential Tools/Products: “Clinical AV Explainer” and “Therapy Companion” — Assumptions/Dependencies: Clinical validation; safety and bias audits; regulatory approvals; strong identity/consent management.
- Personalized Tutors and Immersive Learning — Narrative-driven lessons with adaptive pacing, regional dialect practice, and coherent multi-shot scenarios — Potential Tools/Products: “Dialect Tutor” with scenario simulations and formative assessment — Assumptions/Dependencies: Curriculum alignment; error correction; long-form coherence; transparent synthetic media labeling.
- Robotics and Social Interfaces — Expressive robot faces/displays with synchronized speech and visually coherent emotions for human–robot interaction — Potential Tools/Products: AV-to-embodied interface bridges; on-edge inference — Assumptions/Dependencies: Real-time hardware; safety in social contexts; controllable expressivity to avoid uncanny effects.
- Marketing Optimization Loops — Closed-loop RLHF pipelines optimizing creative variants against engagement KPIs (attention, watch-time, conversions) — Potential Tools/Products: “Creative Optimizer” that iterates scripts/camera/audio within brand guardrails — Assumptions/Dependencies: Privacy-safe data collection; causal evaluation; bias/accountability safeguards.
- Long-Form, Multi-Scene Production — Generating entire episodes/films with consistent characters, narrative arcs, and scene-to-scene continuity — Potential Tools/Products: “Long-Form Story Engine” with identity persistence, character bibles, scene graphs — Assumptions/Dependencies: Strong identity/style persistence; sophisticated scene management; human-in-the-loop editorial control; significant compute.
- Sign-Language and Gesture-Accurate AV — Synthesizing sign-language overlays or avatars with precise hand shapes, facial expressions, and timing synced to speech — Potential Tools/Products: “SignSync Studio” — Assumptions/Dependencies: High-quality multimodal training data; motion capture; cultural/linguistic correctness review.
- Policy, Safety, and Standards — Benchmark-informed regulations for AV sync quality, watermarking, and synthetic media labeling across languages/dialects — Potential Tools/Products: “Synthetic Media Compliance Suite” grounded in SeedVideoBench-like metrics — Assumptions/Dependencies: Cross-industry consensus; interoperable watermark standards; detection and provenance infrastructure.
- Enterprise Knowledge Reenactment — Automatically generated explainers that reenact complex procedures (finance, energy, software) with coherent narration and camera focus — Potential Tools/Products: “Procedure-to-AV” generator — Assumptions/Dependencies: Verified source knowledge; rigorous factuality checks; domain-specific safety constraints.
These applications leverage Seedance 1.5 pro’s core strengths—native audio–visual joint generation, precise lip-sync across dialects, autonomous camera scheduling, narrative coherence, RLHF-driven quality, and >10× accelerated inference—while acknowledging dependencies such as platform access, regulatory compliance, data rights, multi-language coverage, hardware constraints, and robust safety/watermarking to mitigate misuse.
Glossary
- AIGC: Acronym for AI-generated content; refers to media created by AI systems. "As AIGC video generation evolves toward deeper multimodal integration"
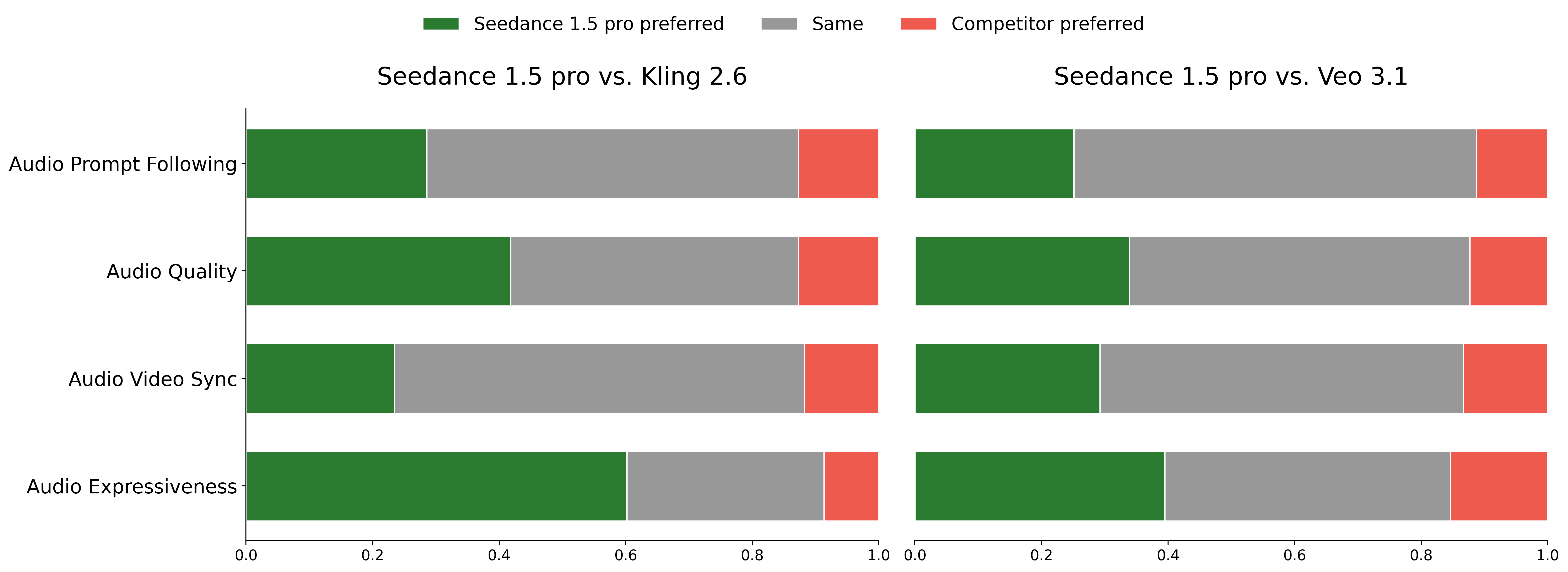
- Audio Expressiveness: The degree to which audio enhances emotional resonance, atmosphere, and narrative coherence. "Comparative Analysis of Audio Expressiveness."
- Audio Prompt Following: Fidelity of generated audio (speech, effects, music) to user instructions and intended semantics. "Audio Prompt Following: Analogous to text-video alignment, this metric assesses the fidelity with which vocal elements, dialogue, and sound effects adhere to user instructions and intended semantics"
- Audio Quality: Intrinsic acoustic quality of outputs, including artifacts, clarity, timbre realism, and spatial rendering. "Audio Quality: This metric quantifies the intrinsic acoustic quality of the output"
- Audio–Visual Synchronization: Temporal alignment between audio and visual streams (e.g., lips to speech, effects to events). "Audio–Visual Synchronization: This metric measures the temporal alignment between auditory and visual streams."
- Background Music (BGM): Music track that supports mood and storytelling in video. "It considers the thematic appropriateness of background music (BGM)"
- Camera scheduling: Autonomous planning and control of camera movements and shot transitions during generation. "The model possesses autonomous camera scheduling capabilities"
- Color grading: Adjusting color and tone of video to achieve a specific aesthetic or mood. "professional color grading"
- Cross-modal interaction: Information exchange between different modalities (audio and video) during generation. "This design facilitates deep cross-modal interaction, ensuring precise temporal synchronization"
- Cross-modal joint module: A component that explicitly couples audio and video representations for joint synthesis. "integrates a cross-modal joint module"
- Curriculum-based data scheduling: Strategy that stages training data by difficulty or structure to improve learning. "curriculum-based data scheduling"
- Diffusion Transformer: Model class that combines diffusion generative processes with Transformer architectures. "dual-branch Diffusion Transformer architecture"
- Dolly zoom (Hitchcock zoom): Cinematic effect where the camera moves while zooming to alter perspective and emotional impact. "dolly zooms (Hitchcock zoom)"
- Good-Same-Bad (GSB): Pairwise human evaluation protocol categorizing outputs as better, equal, or worse. "Good-Same-Bad (GSB): This metric involves pairwise comparisons to assess relative video quality"
- Image-to-Video (I2V): Generating video from a single input image, possibly with additional guidance. "Image-to-Video (I2V) tasks."
- Image-to-Video-Audio (I2VA): Generating both video and synchronized audio from an input image. "Image-to-Video-Audio (I2VA)"
- Intent-aligned creative flexibility: Allowing models to add or adjust content if it remains faithful to the user’s underlying intent. "models are permitted a degree of intent-aligned creative flexibility"
- Likert scale: A standardized rating scale (often 1–5) for human preference evaluation. "5-point Likert scale (ranging from 1 for
Extremely Dissatisfied'' to 5 forExtremely Satisfied'')" - Lip–Audio Synchronization: Alignment of mouth movements with spoken audio content. "In terms of lip–audio synchronization, the model accurately corresponds to the number and identity of speaking characters"
- Lip-syncing: Matching lip movements to speech for perceptual realism. "precise multilingual and dialect lip-syncing"
- MMDiT: A specific diffusion-transformer architecture for multimodal joint generation. "based on the MMDiT \cite{esser2024scaling} architecture."
- Multi-dimensional reward model: RLHF reward function capturing multiple aspects (motion, aesthetics, audio fidelity). "Specifically, our multi-dimensional reward model enhances performance"
- Multi-stage curation pipeline: A structured, phased process for collecting and filtering high-quality training data. "integrates a multi-stage curation pipeline"
- Multi-stage distillation framework: Progressive teacher–student compression to speed inference while preserving quality. "We further optimized a multi-stage distillation framework"
- Number of Function Evaluations (NFE): The count of sampler steps (or evaluations) required during diffusion generation. "to substantially reduce the Number of Function Evaluations (NFE) required during generation."
- Prosody: Rhythm, stress, and intonation patterns of speech that convey emotion and meaning. "vocal prosody"
- Quantization: Reducing numerical precision to accelerate inference and lower memory costs. "such as quantization and parallelism"
- Reinforcement Learning from Human Feedback (RLHF): Training approach aligning model outputs with human preferences via feedback-driven rewards. "Reinforcement Learning from Human Feedback (RLHF) with multi-dimensional reward models."
- SeedVideoBench-1.5: An internally curated, multi-dimensional benchmark for video and audio evaluation. "we introduce the enhanced SeedVideoBench-1.5."
- Supervised Fine-Tuning (SFT): Post-training on labeled, high-quality examples to refine model behavior. "Supervised Fine-Tuning (SFT) on high-quality datasets"
- Temporal synchronization: Precise alignment of events and dynamics across time between modalities. "ensuring precise temporal synchronization"
- Text-to-Video (T2V): Generating video directly from textual prompts. "across both Text-to-Video (T2V) and Image-to-Video (I2V) tasks."
- Text-to-Video-Audio (T2VA): Generating both video and audio jointly from textual prompts. "Text-to-Video-Audio (T2VA)"
- Tracking shots: Camera moves that follow subjects through space to maintain framing and continuity. "executes orbital, arc, and tracking shots"
- Unimodal: Single-modality generation (e.g., video-only) without joint audio. "unimodal video generation (T2V, I2V)"
- Ventriloquism effects: Perceptual mismatch where audio appears to originate from a different visual source or time. "mitigating perceptual ventriloquism effects"
- Video Vividness: Composite measure of dynamic expressiveness across action, camera, atmosphere, and emotion. "places renewed emphasis on Video Vividness"
Collections
Sign up for free to add this paper to one or more collections.