- The paper introduces MCPThreatHive, an automated threat intelligence platform that integrates multi-framework taxonomy for compositional attack modeling in agentic AI ecosystems.
- It employs a four-stage pipeline including intelligence gathering, LLM-driven threat analysis, knowledge graph construction, and risk visualization.
- Empirical validation on real incidents demonstrates its capability to effectively map semantic and inference-time risks using a composite risk scoring model.
Technical Summary of "MCPThreatHive: Automated Threat Intelligence for Model Context Protocol Ecosystems"
Introduction and Motivation
The paper articulates a new threat model for agentic AI systems leveraging Model Context Protocol (MCP), a rapidly adopted integration standard that enables LLM-driven agents to interact with external tools via semantic mediation. This paradigm shift markedly increases the blast radius and complexity of attacks, posing critical challenges for traditional security frameworks, which fail to capture semantic, compositional, and inference-time threat vectors. MCPThreatHive is introduced as an automated, end-to-end intelligence platform addressing three major gaps: lack of compositional attack modeling, absence of continuous threat intelligence, and deficiency in unified multi-framework threat classification.
MCP Ecosystem and Threat Landscape
MCP’s core innovation is delegating tool selection to an LLM, interpreting unconstrained natural-language descriptions at inference time. This opens unique semantic attack surfaces:
- Indirect Prompt Injection (IPI): Attacks propagate via external data, invisibly influencing agentic tool invocation and flow control.
- Parasitic Tool Chains: Attacks synthesized via benign tool composition, enabling unintentional privacy disclosure (UPD).
- Preference Manipulation and Tool Description Poisoning: Adversary-crafted tooling descriptions invisibly bias LLM selection and behavior.
Empirical incidents, such as the GitHub MCP prompt injection and CVE-2025-6514, validate these threat vectors in real-world deployments.
MCPThreatHive operationalizes the MCP-38 taxonomy, cross-mapped onto STRIDE, OWASP LLM, OWASP Agentic, and MCPSecBench frameworks, embodying a holistic threat model for agentic AI. The platform implements a four-stage pipeline:
- Intelligence Gathering: Multi-source, LLM-driven query and normalization from web, CVE, and advisory channels.
- AI Threat Analysis: Batch processing with chain-of-thought prompts, enforcing schema-constrained, cross-framework classification and composite risk scoring.
- Knowledge Graph Construction: Neuro-symbolic entity extraction and relationship mapping for attack chains, tool composition, and mitigation linkage.
- Visualization and Risk Planning: Interactive threat matrix, 3D attack surface views, and automated batch-aggregate-refine risk plan generation.
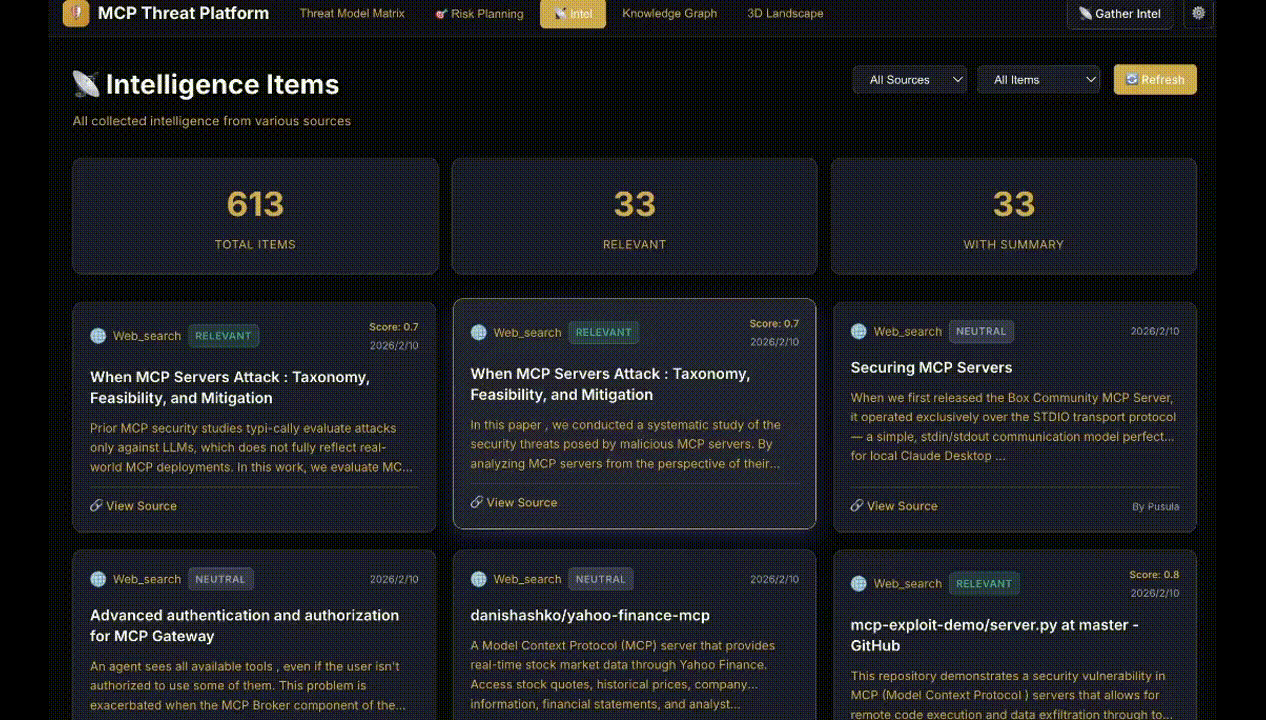
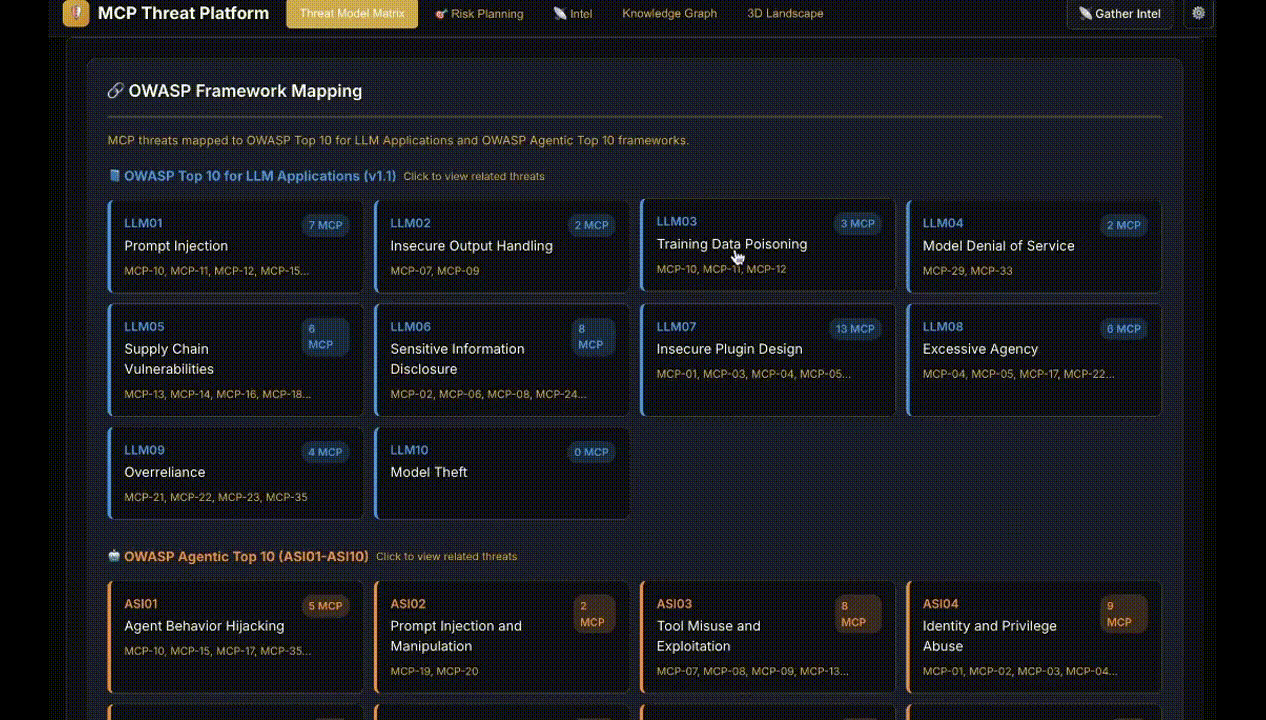
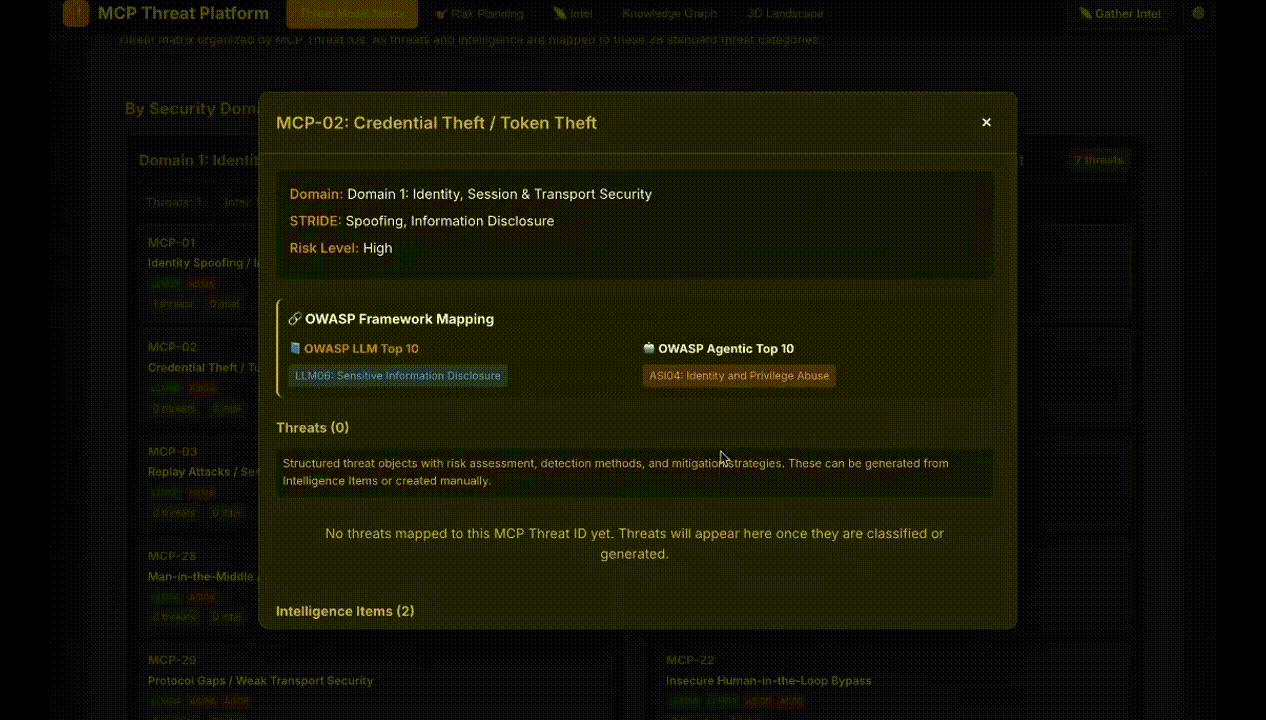
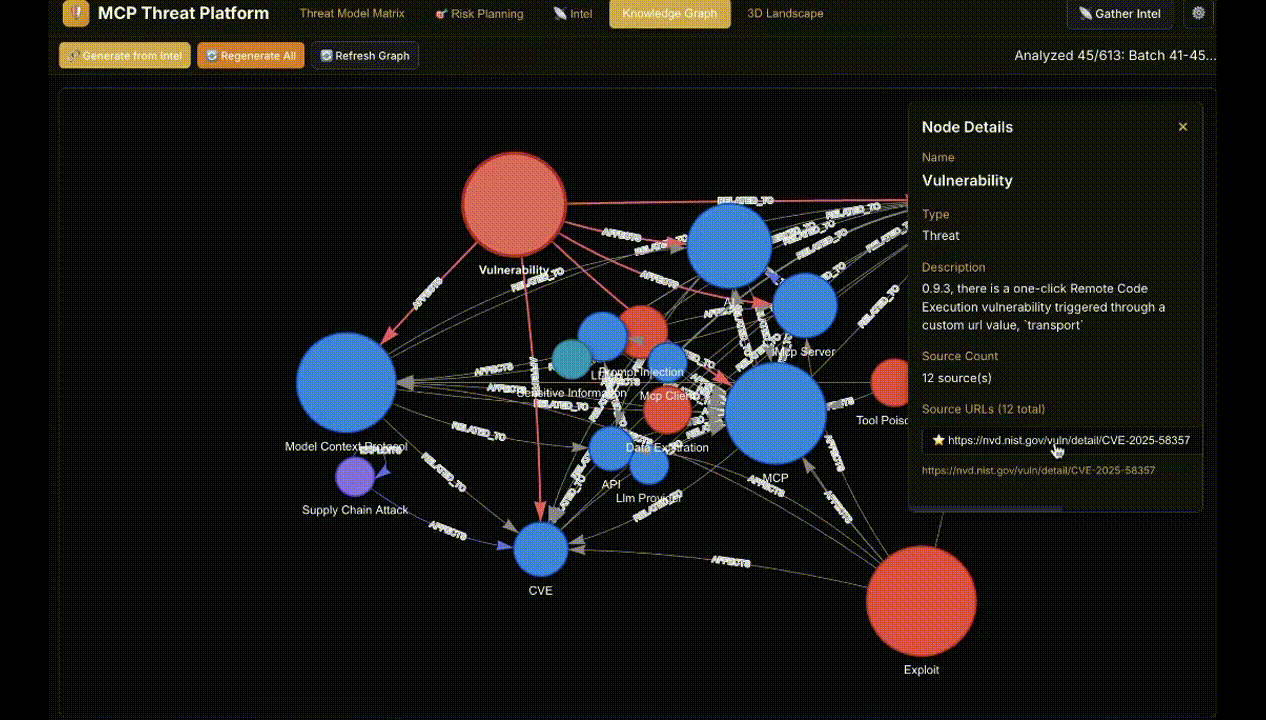
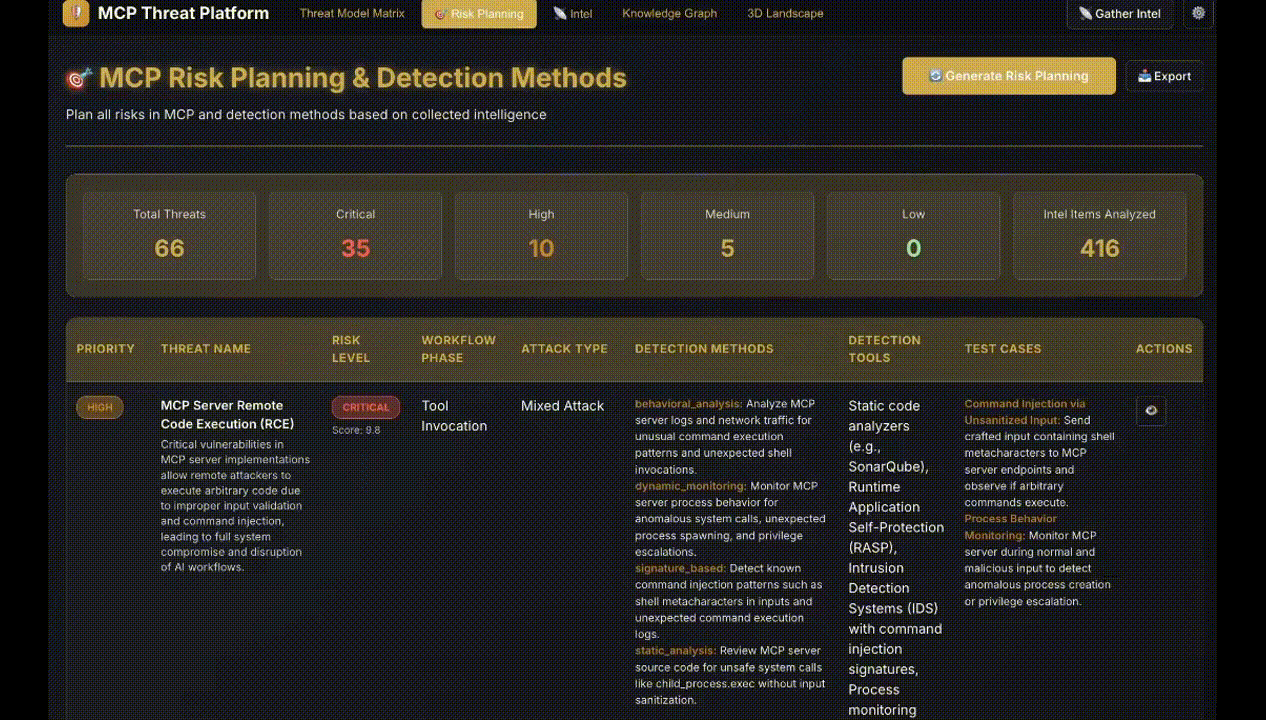
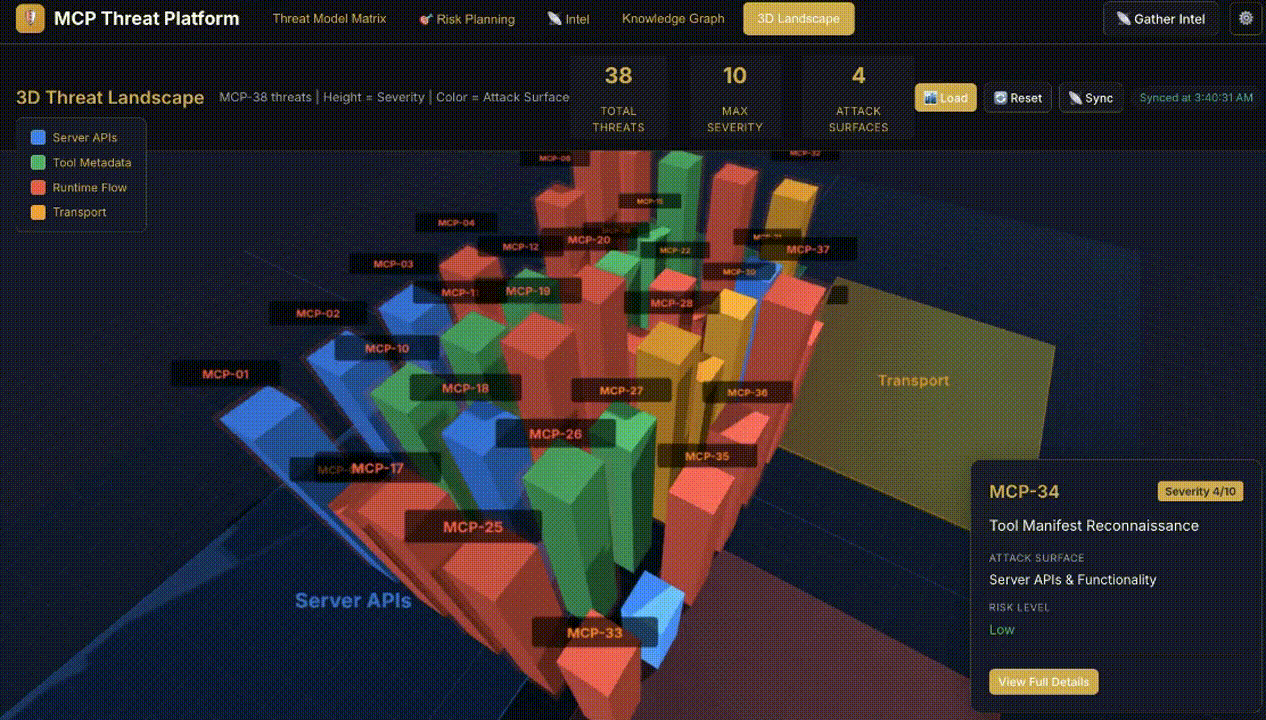
Figure 1: Display of intelligence items with relevance scoring and threat mappings through MCPThreatHive’s pipeline.
The composite risk model adapts DREAD scoring with MCP-specific multipliers for semantic/inference-time risks, parasitic toolchains, and low observability. The risk assignment uses a CVSS-style scale, mapping threat types onto prioritization categories (Critical, High, Medium, Low) with numerical quantification.
Capability Analysis and Empirical Validation
MCPThreatHive, in comparison with existing tools (manifest scanners, runtime proxies, attack simulation frameworks), uniquely provides:
- End-to-end threat intelligence workflow
- MCP-38 taxonomy coverage and compositional attack modeling
- Multi-framework alignment
- Knowledge graph construction
- AI-generated risk plans
It does not function as a runtime proxy or manifest scanner; rather, it feeds upstream intelligence to runtime enforcement tools.
A platform trace on the GitHub MCP prompt injection incident demonstrated fidelity in extracting IPI and exfiltration phases, correctly mapping the compositional chain to MCP-20 and MCP-24 taxonomy identifiers and corroborating expert judgment.
Discussion: Limitations, Practical Context, and Theoretical Implications
LLM-driven classification entails nontrivial limitations: hallucination, token budget sensitivity, misclassification under domain shifts, and false positives for aggressive but legitimate tools. Mitigation steps include high-confidence indicator design, schema constraints, and entity resolution pipelines; however, expert analyst review remains essential. Empirical evaluation of precision/recall is required for production-grade assurance.
Practically, MCPThreatHive’s target users include security teams (remediation prioritization), researchers (coverage gap analysis), and compliance groups (framework-based posture reporting). The platform’s extensibility and open-source nature also enable cross-organizational knowledge integration and community-driven adversarial taxonomy refinement.
Theoretically, the platform exemplifies operationalization of neuro-symbolic hybrid threat intelligence for agentic AI—demonstrating effective chaining of semantic and statistical reasoning for complex, compositional attack modeling previously unattainable in traditional frameworks.
Future Directions
Enhancements envisaged include:
- Empirical evaluation of classification accuracy at corpus scale
- Export to runtime scanners (Semgrep/YARA integration)
- STIX/TAXII-based intelligence sharing
- Automated MCP registry monitoring for dynamic attack detection
Conclusion
MCPThreatHive presents an integrated, automated threat intelligence solution for agentic AI ecosystems, bridging compositional, semantic, and multi-framework threat modeling gaps inherent in MCP deployments. By leveraging LLM-driven analysis and structured knowledge graph storage, it facilitates actionable risk prioritization and attack chain elucidation. Its upstream intelligence complements runtime defense tools and establishes a methodological foundation for scalable, adversarial security modeling in autonomous AI systems.

