- The paper identifies a novel risk surface arising from decoupling model reasoning from tool execution in the MCP ecosystem.
- It employs a layered defense methodology including cryptographic provenance, runtime isolation, and context sanitization to curb vulnerabilities.
- Implications stress the need for continuous governance, formal verification, and scalable policy alignment for context-aware AI systems.
Systematization of Security and Safety in the Model Context Protocol Ecosystem
Introduction
The Model Context Protocol (MCP) is rapidly emerging as the universal bridge for connecting LLMs to external resources and toolchains, impacting both research and industrial deployment of agentic AI systems. The MCP specification abstracts data and tool integration into a standardized protocol, effectively dissolving the M×N integration barrier that previously impeded scalable LLM-agent deployments. However, this architectural decoupling, which transitions LLMs from passive generators to context-sensitive, action-capable orchestrators, introduces a new and expansive security and safety threat surface. This survey provides a formal synthesis and taxonomy of the unique adversarial and epistemic risks in the MCP ecosystem, highlights the most pressing challenges, evaluates the current state of mitigations, and discusses the future of protocol-centric AI security.
MCP Architecture: Decoupling and Threat Amplification
MCP adopts a client-host-server topology that deliberately segregates model execution, tool invocation, and resource retrieval. All requests between the agent (or Model Interface) and external resources are mediated by a Host that serves as a policy enforcement boundary.
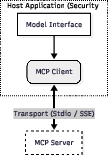
Figure 1: The host application acts as the explicit security boundary, mediating all interactions between the model execution interface and external MCP servers.
This architecture moves control flow away from static, developer-driven APIs to intent- and context-driven sessions managed by the LLM itself.
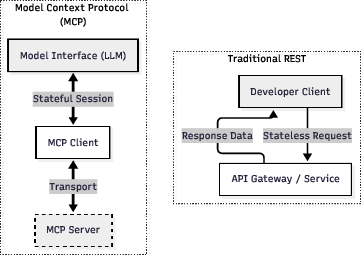
Figure 2: Unlike traditional REST APIs, MCP permits the LLM to determine the execution path by interpreting contextual cues in dynamic, intent-driven sessions.
The core protocol primitives—Resources (read-only, URI-identified data), Prompts (template-driven context injectors), and Tools (executable actions with schema-controlled parameters)—are orchestrated via JSON-RPC 2.0 and capability negotiation mechanisms, with the explicit goal of protocol-level interoperability. However, an analysis of the control and data flow reveals that the semantic decoupling of reasoning and action introduces protocol-native vulnerabilities not seen in deterministic API-based agents.
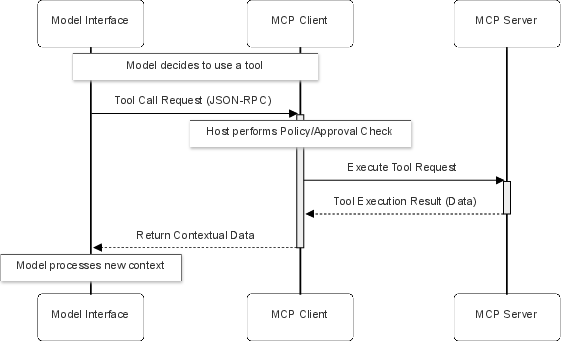
Figure 3: Model Interface requests are routed via the client, subject to host-enforced policy checks, and dispatched to context sources, making runtime policy the key line of defense.
Threat Landscape and Vulnerability Taxonomy
The surveyed attack surface in MCP is defined by adverse interactions between the protocol's semantic coupling and distributed trust boundaries. MCP’s adversary model comprehensively encompasses malicious tool developers ("rug pull" and supply chain compromise), protocol abusers (spoofed server registration, name collisions), and exploiters of context ambiguity (prompt injection, tool poisoning, unauthorized serialization).
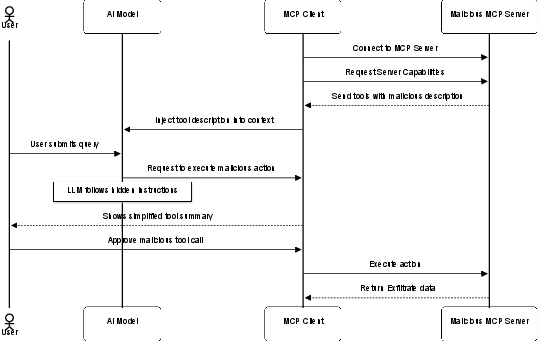
Figure 4: Context poisoning attack flow—an attacker injects malicious tool definitions so the LLM, even with nominal user approval, executes unauthorized actions.
MCP’s taxonomy of vulnerability dimensions unifies adversarial security threats (e.g., tool masquerading, model-switch attacks, protocol abuse) and epistemic safety hazards (hallucination-driven error, misaligned tool delegation, context contamination). The crucial observation is the dissolution of the traditional boundary: adversarial manipulations of context can yield both classic security breaches and genuine safety failures indistinguishable by conventional means.

Figure 5: Illustration of an indirect prompt injection where a malicious resource poisons the agent's context, leading to an unauthorized tool execution.
Supply chain attacks in open tool registries remain a potent risk vector due to the lack of global version control, continuous signature validation, or immutable provenance for MCP tool definitions.

Figure 6: Threat actors inject exploits into remote repositories, later pulled by MCP clients during tool installation or updates, enabling supply chain compromise.
Safety and Alignment Hazards in Distributed Contexts
Beyond direct security exploits, the protocol-centricity of MCP amplifies epistemic risk. Distributed retrieval amplifies context fragmentation and makes hallucination and mis-grounding both more likely and more impactful, particularly as tools become more autonomous and multi-agent workflows are composed ad hoc. Weaknesses in resource fidelity, lack of chain-of-custody for provenance, and absence of robust HITL mechanisms all raise systemic governance issues.
Alignment failures manifest in policy conflicts between organizational rules coded in the host, tool-level capabilities, and emergent model reasoning—increasing the risk of unintentional but policy-violating tool usage, such as confidential data exfiltration or “confused deputy” scenarios. This effect is exacerbated by the trend toward large-context LLMs, where conventional alignment training does not scale and indirect prompt injections may be deeply embedded in input streams.
State-of-the-Art Defenses
The strongest existing countermeasures adopt a layered, defense-in-depth architecture:
- Cryptographic Provenance (ETDI): All tool manifests and schema are signed, with host- and registry-based verification at both load and invocation time, making tool definitions immutable and auditable.
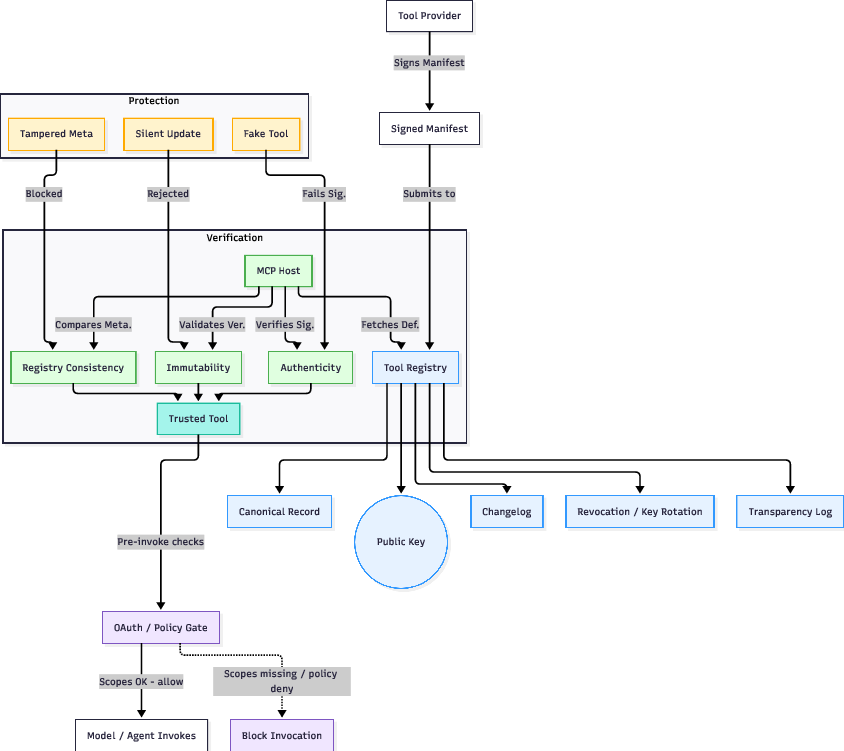
Figure 7: ETDI workflow—developer signs tool manifest, registry validates identity, and host verifies at runtime, closing the loop against supply chain and rug-pull threats.
- Access Control and Runtime Isolation: Capability tokens restrict each tool to its minimum privilege, enforced by ephemeral, sandboxed processes and session gates (gVisor, seL4).
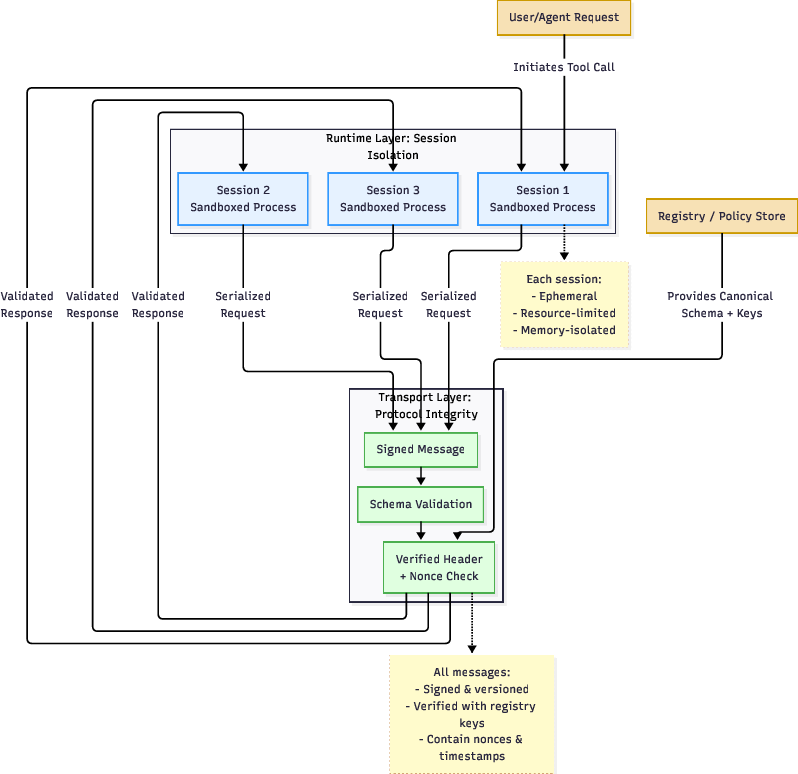
Figure 8: Dual-layer defense—ephemeral runtime isolation using system call interposition/sandboxing atop protocol-layer signature and schema validation.
- Context Sanitization and Provenance Filtering: Tools such as MindGuard and MCPTox instrument semantic context validation plus attention-based tracing to detect when tool calls originate from poisoned prompt/context metadata.
- Continuous Governance and Closed-Loop Telemetry: Monitoring frameworks (e.g., TRiSM, MindGuard) couple runtime decision logging with anomaly detection, policy-plane adaptation, and HITL escalation for high-risk operations.
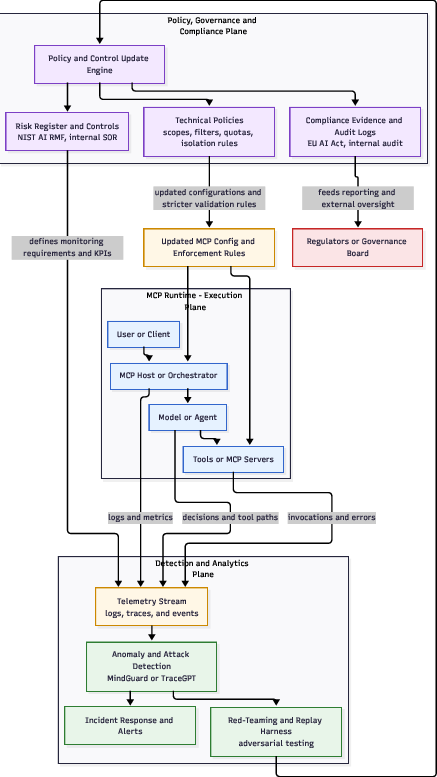
Figure 9: TRiSM’s closed-loop architecture—policy definition, runtime enforcement, and anomaly detection feed back to adapt agentic governance as threats and operations evolve.
Case Studies
Empirical incidents such as the Supabase data leak demonstrate the practical merging of safety and security risk: prompt injection via user-provided data bypassed robust human role-based access by exploiting the LLM’s authority in an MCP workflow, resulting in the exfiltration of credentials [pomerium2025airoot]. Multi-tenant LLM services have also shown KV-cache prompt leakage, revealing that even at the infrastructure layer, protocol state sharing can become a powerful side channel [wu2025promptleakage]. Supply chain attacks, tool “rug pulls,” and policy conflict failures further illustrate that MCP’s weakest links are distributed across the entire trust chain.
Open Research Directions and Future Developments
Formal verification of MCP protocol exchanges remains an unsolved challenge due to the fusion of semantic, probabilistic reasoning and deterministic protocol logic. Futuristic research must target hybrid symbolic/semantic static and dynamic analysis, regulatory policy alignment, and scalable, privacy-preserving tenant isolation mechanisms.
Adoption trajectories point toward normalization of risk: hardware-based or microkernel-level isolation for system-privileged tools, zero-trust registries, and cross-protocol compatibility layers with formalized governance. The role of automated “watchdog” agents to enforce protocol invariants, detect policy drift, and intervene on anomalous execution paths is likely to expand as agentic OS primitives are hardwired into MCP host environments.
Conclusion
The Model Context Protocol fundamentally redefines the connective fabric of agentic AI, standardizing the composition of model, tool, and resource while creating new, indistinguishable classes of security and safety risk. The systematized taxonomy presented here underscores that securing such an ecosystem requires far more than software hardening: it demands cryptographic provenance, capability-based isolation, provenance-driven context validation, and continuous runtime governance by design. The drive toward composable, autonomous agentic OS-level constructs will only accelerate these trends. Future standards must integrate these defenses as defaults—where verification, accountability, and semantic intent-checking are foundational qualities, not afterthoughts. Only under such an architecture can MCP be trusted as the backbone of context-aware, trustworthy AI systems.