- The paper demonstrates that OffloadFS effectively offloads I/O-intensive tasks to underutilized storage nodes, eliminating the need for distributed lock management.
- It integrates with RocksDB and ML pre-processing pipelines to reduce cache pollution and network traffic, achieving performance gains up to 3.36× over conventional systems.
- The study benchmarks OffloadFS against OCFS2 and GFS2, highlighting its scalable, multi-tenant design and efficient initiator-centric control model.
OffloadFS: Leveraging Disaggregated Storage for Computation Offloading
Overview
The paper "OffloadFS: Leveraging Disaggregated Storage for Computation Offloading" (2604.13743) addresses resource underutilization in NVMe-over-Fabrics (NVMeoF) based disaggregated storage nodes by introducing OffloadFS, a user-level file system that efficiently enables near-data processing (NDP). OffloadFS supports selective offloading of I/O-intensive tasks to storage nodes or peer nodes without requiring distributed lock management, in contrast to conventional shared-disk file systems. The study details both the architectural innovations of OffloadFS and its integration with RocksDB (as OffloadDB) and ML pre-processing pipelines (OffloadPrep), and provides comprehensive benchmarks against OCFS2, GFS2, and state-of-the-art alternatives.
Motivation and Background
Storage disaggregation, facilitated by NVMeoF, allows decoupling compute and storage resources within datacenters, providing independent scaling and improved resource pooling. However, since NVMeoF delegates most storage processing to compute nodes, the storage nodes (often JBOF appliances with multicore CPUs and significant memory) remain underutilized even as NVMeoF systems achieve high IOPS and low latency by minimizing OS-level and protocol overheads.
Conventional approaches to computation offloading focus on dynamic scheduler-driven offload or fixed-function near-data processing within computational SSDs. They commonly employ distributed or shared-disk file systems, implicating significant overhead in metadata management and distributed lock service, which induces performance bottlenecks even under single-client, no-contention cases.
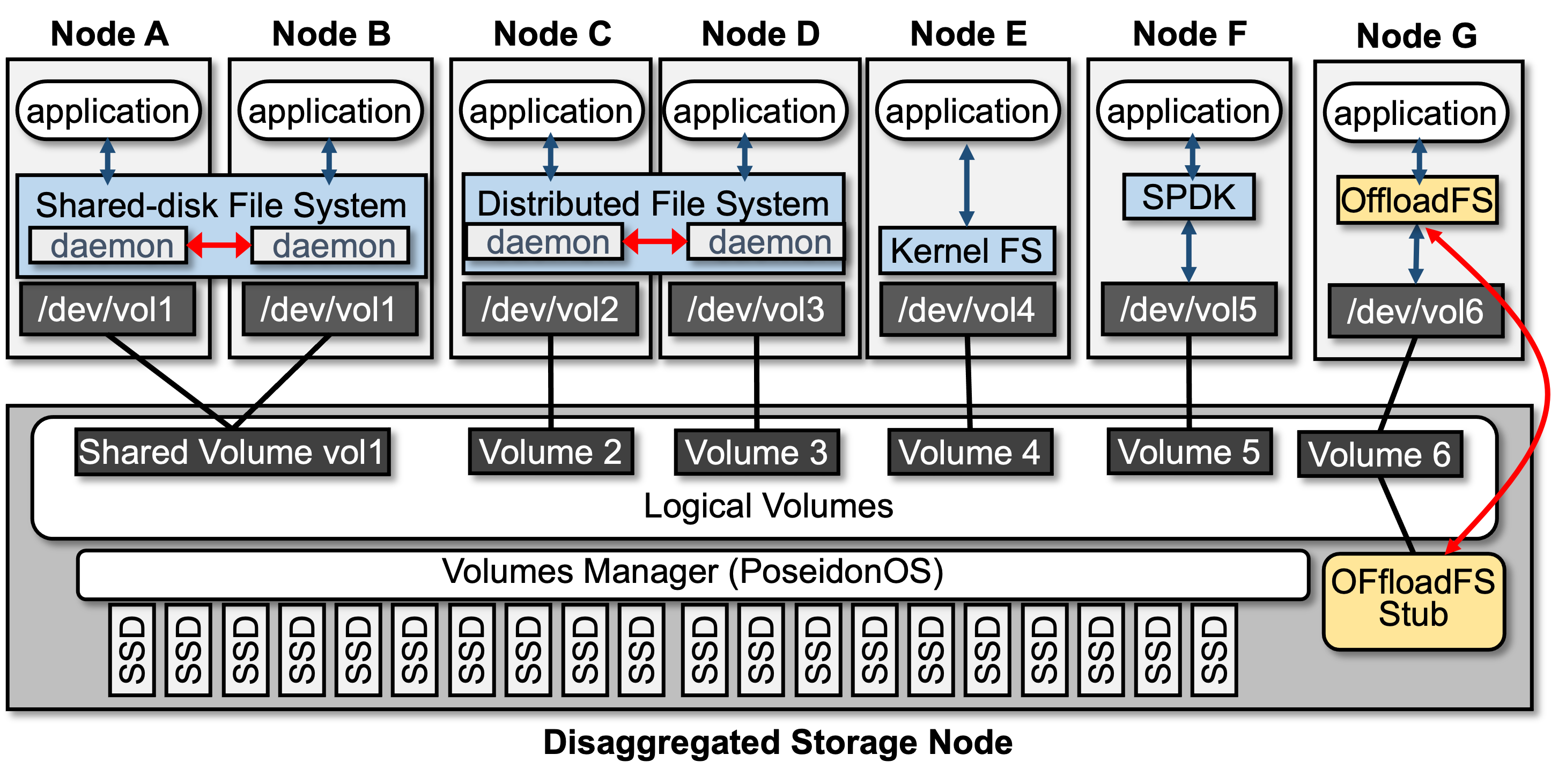
Figure 1: Various file system deployment options in NVMeoF JBOF environements, highlighting the trade-offs between shared-disk and distributed setups.
The analysis of storage node resource utilization demonstrates persistently low CPU and moderate DRAM usage on modern NVMeoF targets. Bandwidth is typically bottlenecked by the network link rather than the storage device array, placing premium on architectures that minimize network traffic and capitalize on idle local compute/memory.
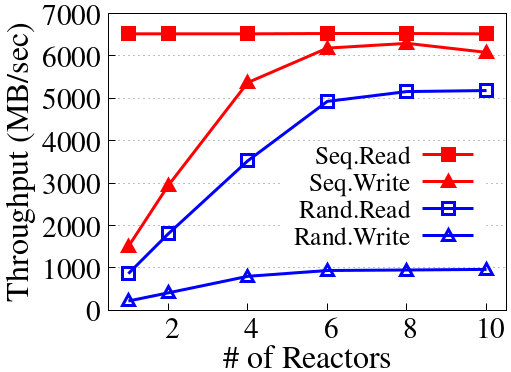
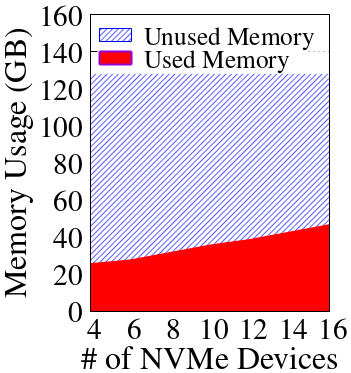
Figure 2: Storage node resource under-utilization under varying FIO workloads, showing substantial leftover compute resources in high-end NVMeoF targets.
OffloadFS Architecture and Protocols
OffloadFS is architected to enable offloading user-defined I/O workloads to storage nodes (or peer initiators), while using an initiator-centric approach to metadata and block management. Unlike classic shared-disk file systems with distributed consensus enforcement, OffloadFS statically partitions authority: the initiator allocates and exposes only those block ranges relevant for a given remote execution, guaranteeing that no coherence violation occurs, and obviating distributed locking.
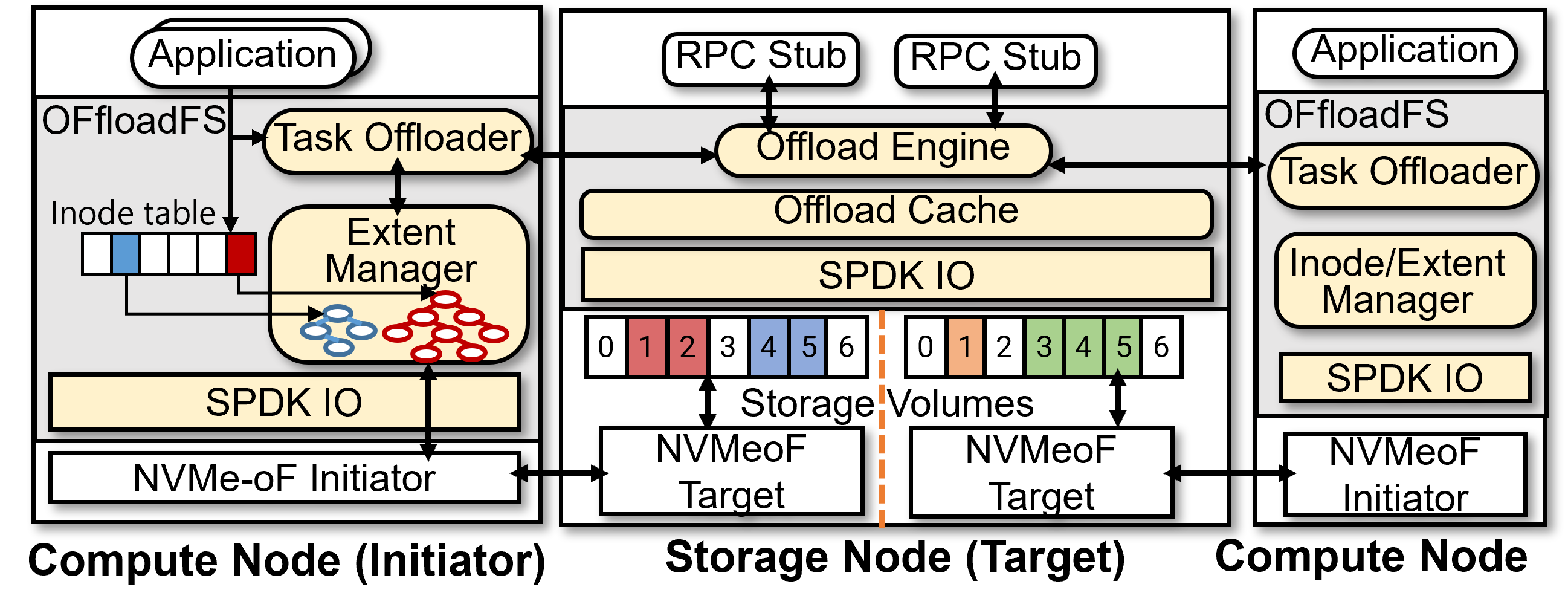
Figure 3: OffloadFS architectural modules and offloading flow with enforced access control based on initiator-driven extent assignments.
OffloadFS provides SPDK-based APIs for offloaded read and write, pinned for the duration of remote task execution. Application-level control of cache coherence on the target node further eliminates cross-node message traffic. Multi-tenancy support is implemented via load-aware rejection (CPU usage thresholds) or token-based admission schemes to prevent overload of the storage node.
OffloadDB, a modification of RocksDB, utilizes OffloadFS to offload MemTable flush and compaction operations. These tasks are traditionally highly interfering with foreground (user) operations, causing cache pollution and write stalls. OffloadDB isolates backgrounds tasks and avoids pollution by segregating I/O traffic and buffer allocation, as well as avoiding duplicate network transfers using a novel Log Recycling method by reconstructing SSTables from WALs resident on the storage node.
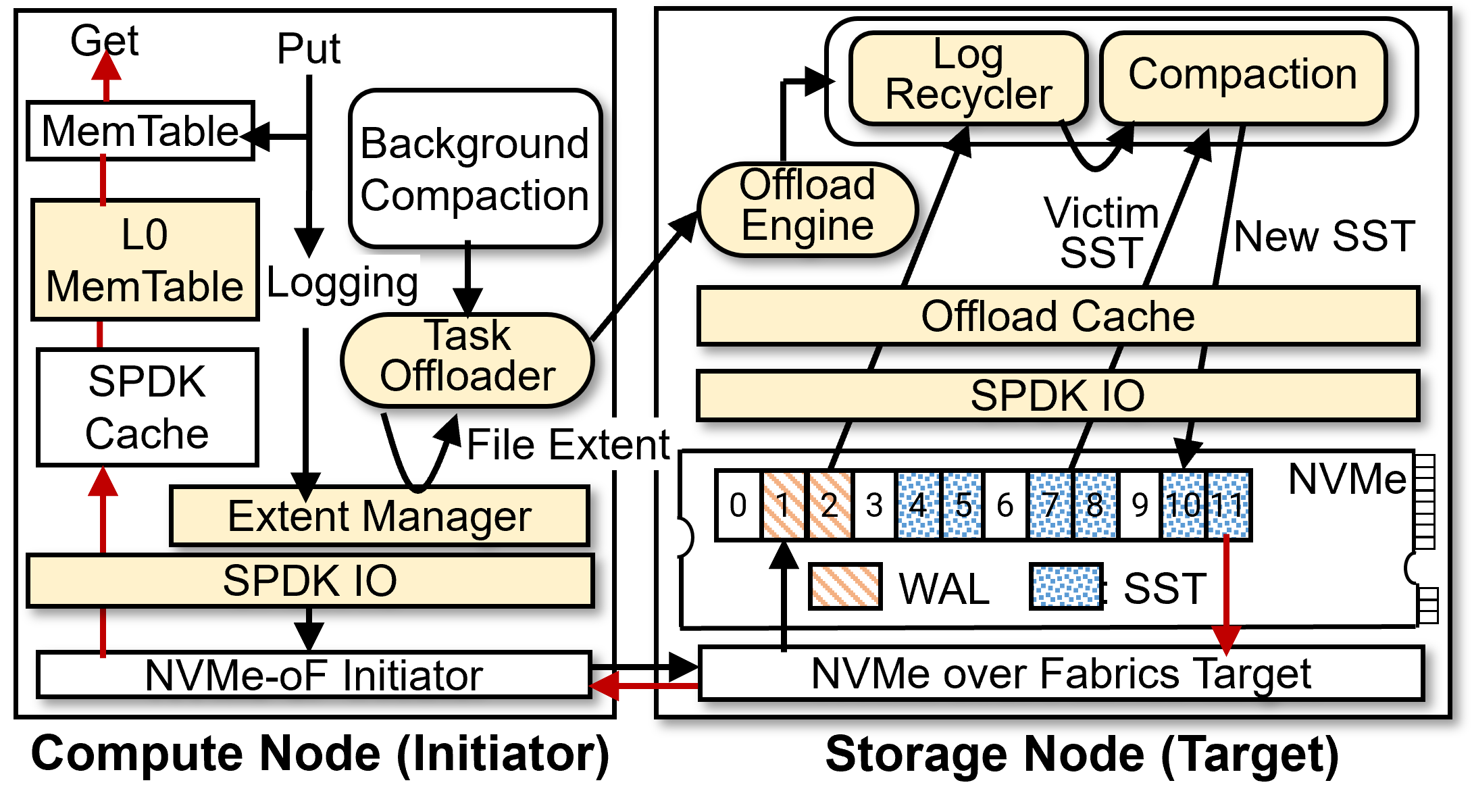
Figure 4: OffloadDB logic pipeline detailing task allocation between initiator and storage node, and interleaving RocksDB's workflows with OffloadFS APIs.
For DNN/ML workloads, OffloadPrep allows the offloading of image pre-processing pipelines, including computation-heavy transforms (resize, crop, flip, rotation), to the storage node using the same OffloadFS abstraction without requiring major modifications to model code.
Comparison with Shared-Disk and Distributed File Systems
Benchmarks against OCFS2 and GFS2 demonstrate the magnitude of efficiency gains enabled by avoiding distributed lock management and kernel overheads endemic to prior approaches. Under YCSB-A workloads and pre-processing pipelines, OffloadFS consistently outperforms OCFS2 by up to 3.36× for OffloadDB and 1.85× for OffloadPrep, with the gap arising primarily from user-level I/O path optimizations and cache pollution elimination.
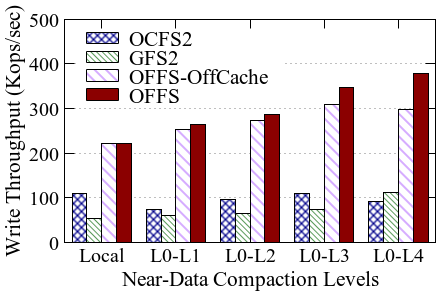
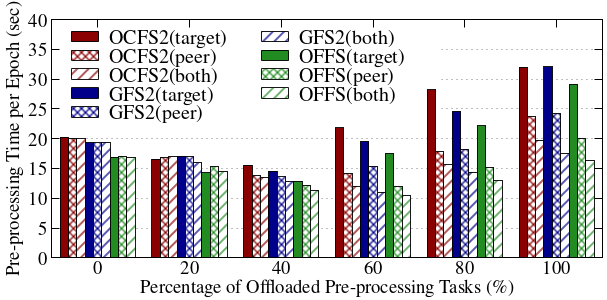
Figure 5: End-to-end throughput and latency comparison of OffloadFS, OCFS2, and GFS2 across RocksDB compaction and ML pre-processing tasks.
Offloading compaction operations to peer compute nodes, rather than storage nodes, yields limited benefits in file systems that are not designed for near-data execution due to increased network traffic and lock granularity overhead. OffloadFS, however, enables efficient peer node offloading, as the file system enforces coordinator-defined access semantics, and data/metadata management does not rely on distributed arbitration.
Scalability and Multi-Tenancy
OffloadFS supports concurrent offloading from multiple initiator nodes. With up to six concurrent OffloadDB or OffloadPrep instances, aggregate resource utilization and throughput scale nearly linearly, but performance degrades beyond hardware saturation (observed at eight clients). Token-based request admission provides smoother performance curves and improved fairness relative to reactive CPU load rejection.
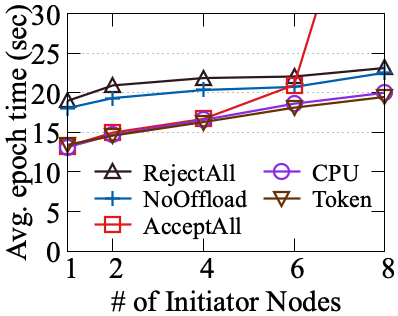
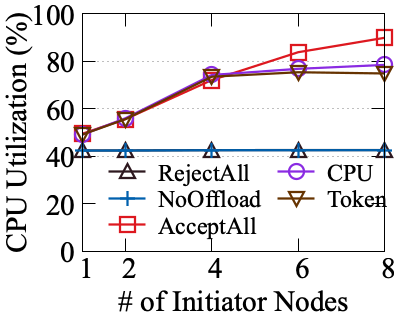
Figure 6: ML Pre-processing workload scaling as number of OffloadPrep clients increases, illustrating effective partitioning of storage node resources.
Microarchitectural Insights
OffloadFS's initiator-centric cache management eliminates the classic cache pollution of shared buffer caches, as demonstrated by higher cache hit ratios and increased throughput for foreground reads in OffloadDB over RocksDB and direct I/O compaction variants. The block cache can be downsized at the initiator, as background tasks buffer at the storage node, freeing compute node memory for application use and enabling better hit rates—especially as more compaction is offloaded.
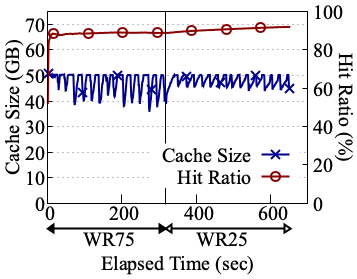
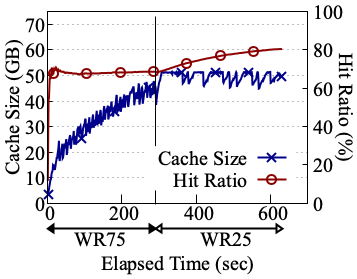
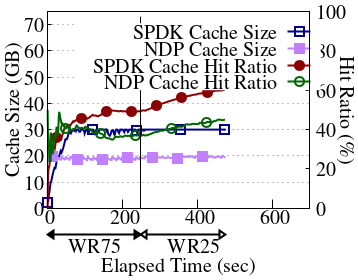
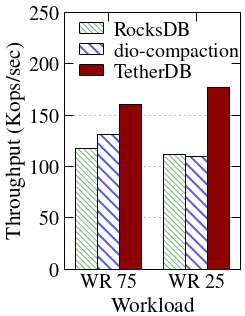
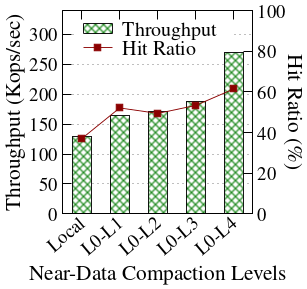
Figure 7: Memory usage and cache hit ratio over time, comparing RocksDB, dio-compaction, and OffloadDB setups, highlighting foreground read cache effectiveness when using OffloadFS.
OffloadDB's Log Recycling eliminates redundant network traffic for WAL and SSTable flushes, further reducing latency and amplifying bandwidth gains in disaggregated setups.
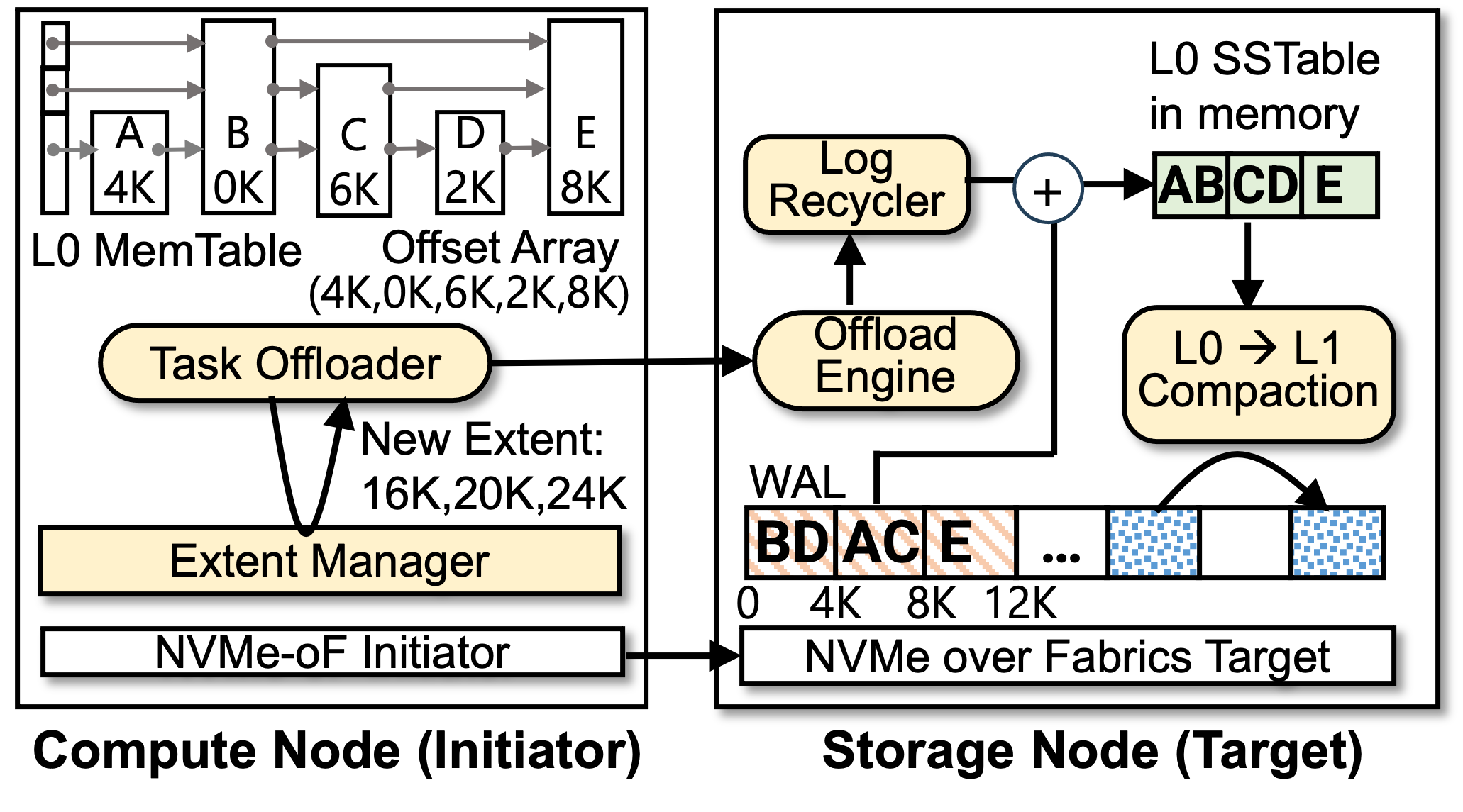
Figure 8: Log Recycling in OffloadDB, minimizing network data transfer during MemTable flush by reconstructing L0 SSTables directly on the storage node from WALs.
Implications and Future Directions
OffloadFS demonstrates that lightweight, user-level file systems with application-controlled metadata protocols can unlock the heretofore untapped compute and memory capacity of storage nodes in NVMeoF-based disaggregated infrastructures. The implications extend to both transactional processing—by reducing interference and obviating write stalls/corresponding tail latency inflation in LSM-tree stores—as well as to data-centric workloads such as machine learning, where storage node resources can serve as cost-effective pre-processing accelerators.
The OffloadFS design paradigm raises prospects for broader integration of NDP, especially as newer storage appliances integrate more substantial onboard compute. Integrating richer task scheduling—potentially based on fine-grained queue depths or hardware telemetry, rather than static token/CPU thresholds—could further optimize multi-tenancy. Extending OffloadFS to accommodate more complex parallel computation graphs, or to cooperate with computational SSD or DPU-equipped nodes, is a plausible direction as hardware evolves.
Moreover, OffloadFS's initiator-centric control model exposes APIs that enable applications to assign trust boundaries and control delegation explicitly, opening research avenues into secure NDP execution and cross-domain infrastructure.
Conclusion
OffloadFS provides an efficient, practical approach for leveraging the abundant, but underutilized, compute and memory resources of NVMeoF disaggregated storage nodes. By eschewing complex distributed coordination and relying on initiator-controlled task partitioning and access management, it not only circumvents the pitfalls of prior shared-disk architectures, but enables significant throughput and latency improvements for I/O- and data-intensive applications including LSM-tree based key-value stores and ML pre-processing pipelines. OffloadFS thereby sets a new standard for practical near-data processing in modern datacenter architectures.

