- The paper introduces a forward-only KL-divergence sensitivity analysis for layerwise mixed-precision allocation in SSM-Transformer models.
- It demonstrates that KL divergence outperforms traditional proxies, achieving up to 7.2× model size reduction with minimal perplexity loss on edge devices.
- The methodology enables efficient deployment without backpropagation, using rigorous empirical correlation and hardware profiling on both CPU and GPU platforms.
Introduction and Motivation
The manuscript "A KL Lens on Quantization: Fast, Forward-Only Sensitivity for Mixed-Precision SSM-Transformer Models" (2604.13440) addresses the acute challenge of deploying large-scale LLMs, particularly SSM-Transformer hybrids, on resource-constrained edge devices. Existing quantization strategies—uniform or gradient-based—fail to account for the highly non-uniform sensitivity of hybrid architectures. The paper introduces a post-training, backpropagation-free sensitivity analysis pipeline, leveraging forward-pass metrics and substantiated by formal analysis, to guide layerwise mixed-precision allocation. The practical importance is underscored by extensive ablations and real-world profiling, revealing strong numerical evidence for the KL-divergence metric as the superior proxy for quantization-induced degradation in language modeling tasks.
Related Work and Architectural Context
Quantization research for LLMs conventionally centers on homogeneous schemes—uniform INT4/INT8—facilitating hardware deployment but yielding suboptimal accuracy-efficiency tradeoffs due to layerwise variability. Early vision work established 8-bit quantization viability, later extended via outlier-aware techniques for LLMs. Mixed-precision approaches, such as HAWQ and more recent post-training algorithms, offer bit-width heterogeneity driven by sensitivity scores, with gradient-based, Hessian, or SQNR proxies.
With SSMs (e.g., Mamba, Hymba, Zamba), architectural heterogeneity (linear recurrence, MoEs, selective attention) further amplifies sensitivity differentials, as highlighted by recent studies showing SSM transitions and outputs manifest distinctive quantization regimes compared to pure Transformers. This architectural distinction motivates a more granular sensitivity-driven bit allocation.
Methodology: KL-Driven Forward Sensitivity Analysis
The proposed methodology quantitatively measures layerwise robustness to quantization, requiring only forward inference on a reference dataset and obviating gradient access. Sensitivity is scored as the impact of quantizing a single model component on perplexity and logit distributions, using metrics such as SQNR, cross-entropy gaps, and two-way KL divergence. The method is formalized via Kendall’s τ rank correlation to assess proxy metric alignment to ground-truth performance loss.
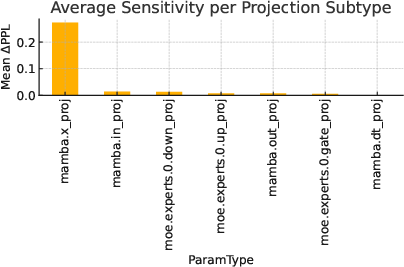
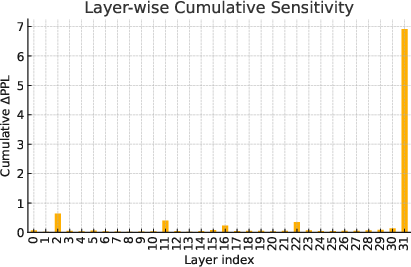
Figure 1: Quantization-sensitivity characteristics of Hymba, showing projection subtype and layerwise cumulative ablation sensitivity revealing dominant hotspots.
A distinguishing technical contribution is the formal analysis of metric suitability: KL divergence between student and teacher output distributions aligns tightly with perplexity increases, as proved via decomposition lemmas and empirical ranking correlation. In contrast, SQNR is not monotonic in perplexity, failing to reliably assess downstream task degradation, particularly in autoregressive LM settings where probability mass shifts—rather than raw signal distortion—drive semantic performance.
Empirical Study: Ablations, Metric Ranking, and Heatmaps
The ablation study on Hymba identifies that mamba.x_proj dominates quantization sensitivity, with block 31 accounting for ∼70% of cumulative perplexity impact. Coupled sensitivities in x_proj-MoE pathways highlight interconnected error propagation under quantization noise. Most other modules (e.g., mamba.dt_proj) tolerate extreme low precision, enabling aggressive compression.
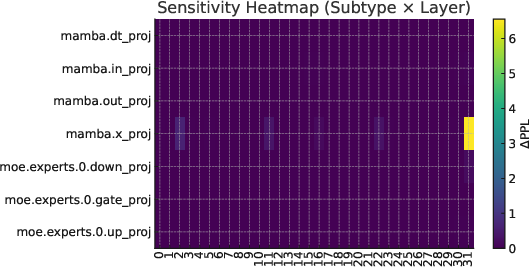
Figure 2: Sensitivity heat-map (ΔPerplexity) across projection subtypes and layers, pinpointing hotspot layers for hybrid mixed-precision strategies.
Metric ranking analysis across multiple models robustly confirms KL divergence (student-to-teacher direction) as the most consistent predictor (τ∼0.79), surpassing SQNR and other proxies. P-values support significant superiority of KL-based ranking for hybrid SSM-Transformer architectures.
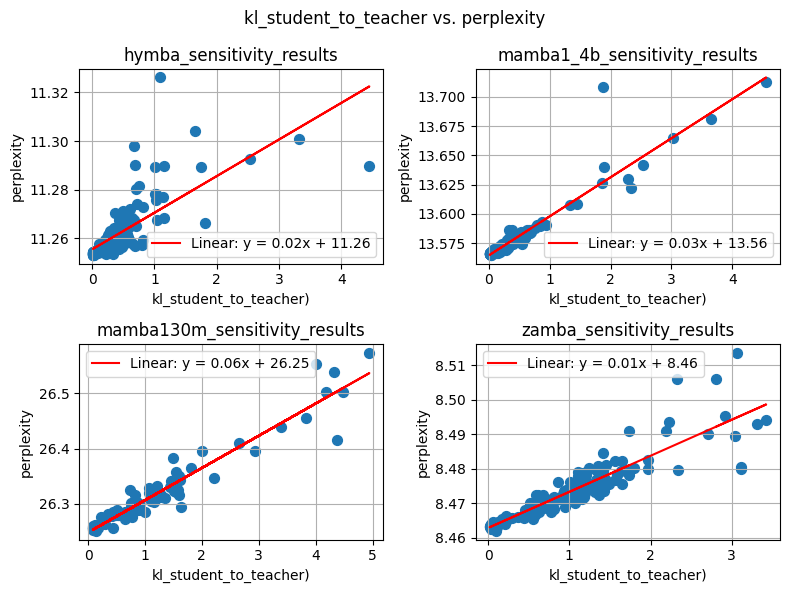
Figure 3: KL-Divergence versus Perplexity correlation, illustrating the strong monotonic relationship underlying the sensitivity-guided approach.
On-Device Profiling: CPU and GPU Results on Intel Lunar Lake
Profiling via OpenVINO on Intel Lunar Lake demonstrates the efficacy and practicality of KL-guided mixed precision. On the CPU, for Mamba-130M and Mamba-1.4B, KL-driven configurations reduce model size by 5.9× and 7.2× respectively with negligible perplexity loss, and achieve INT8-level or better throughput with reduced latency compared to uniform quantization baselines.
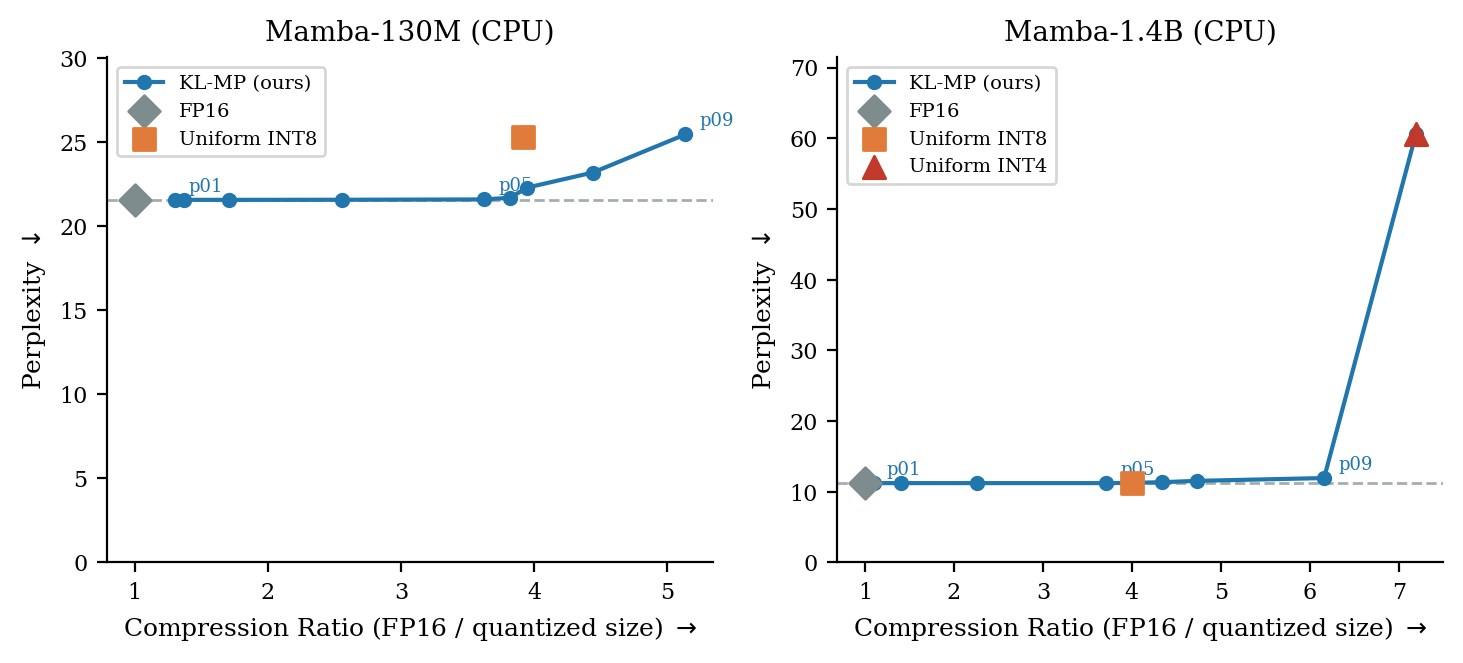
Figure 4: Perplexity versus model size (CPU), with KL-MP maintaining FP16-level accuracy across wide compression; illustrates sensitivity-induced performance cliffs.
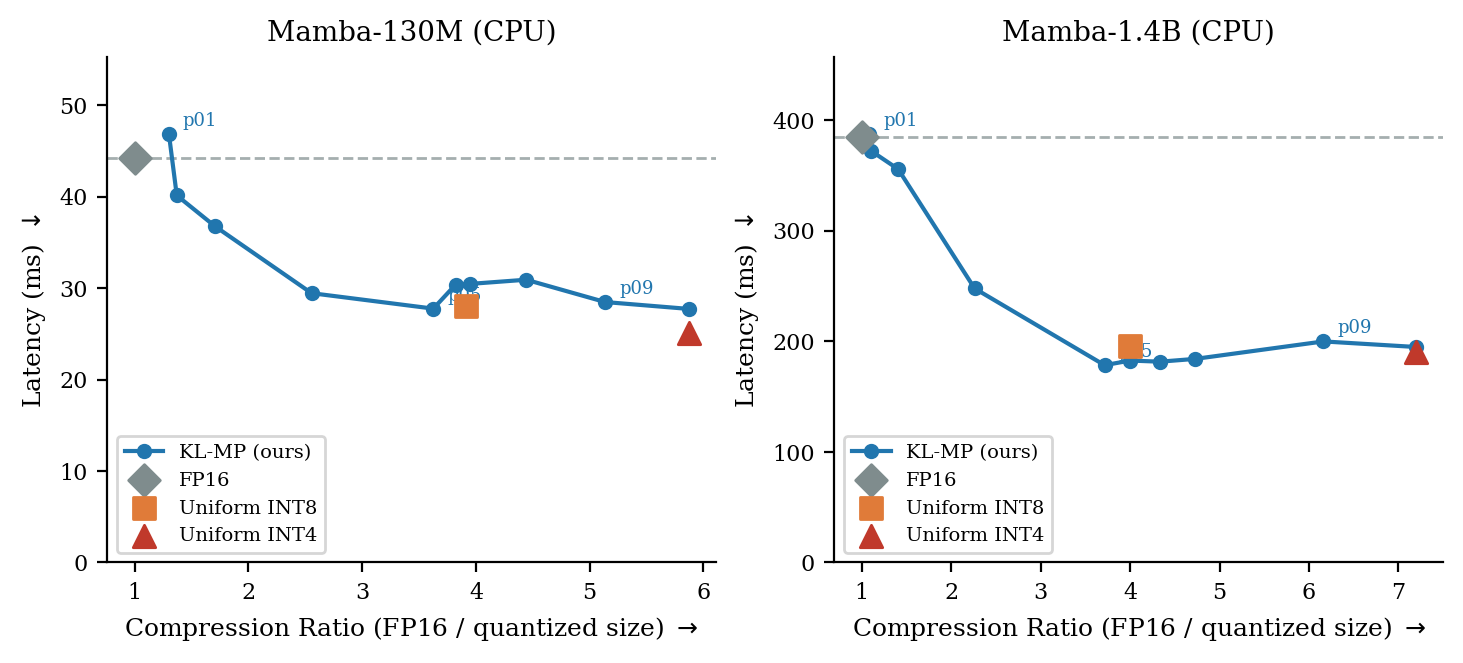
Figure 5: Inference latency versus model size (CPU), KL-MP achieving lowest latency for Mamba-1.4B, showing compute reduction due to precision-guided allocation.
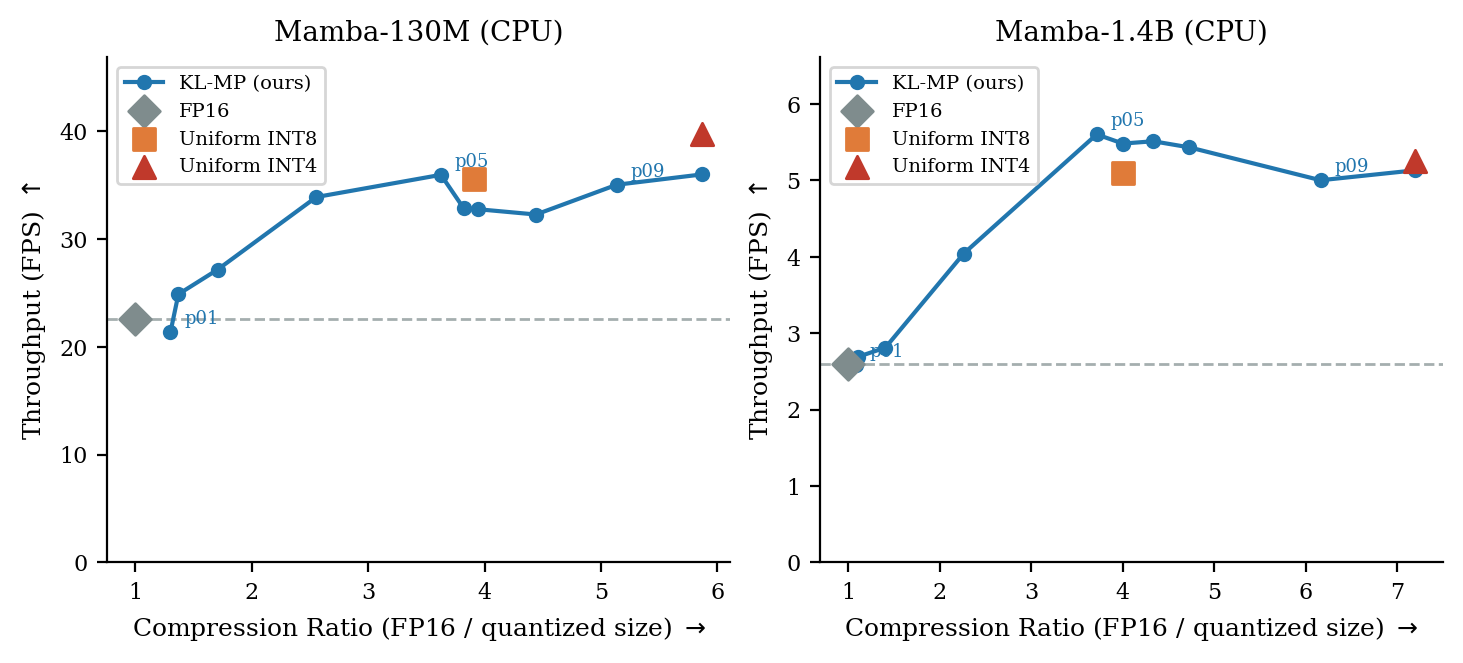
Figure 6: Throughput versus model size (CPU), KL-MP matching/exceeding homogeneous INT4 throughput while preserving high accuracy.
On GPU, the bottleneck shifts: KL-MP configurations dramatically improve throughput and latency (up to 14.5× and 17.6× respectively), but memory reductions plateau due to platform constraints (FP16 compression, embedding dominance). Perplexity remains at baseline up to critical sensitivity cliff, confirming the effectiveness of KL-based layer selection.
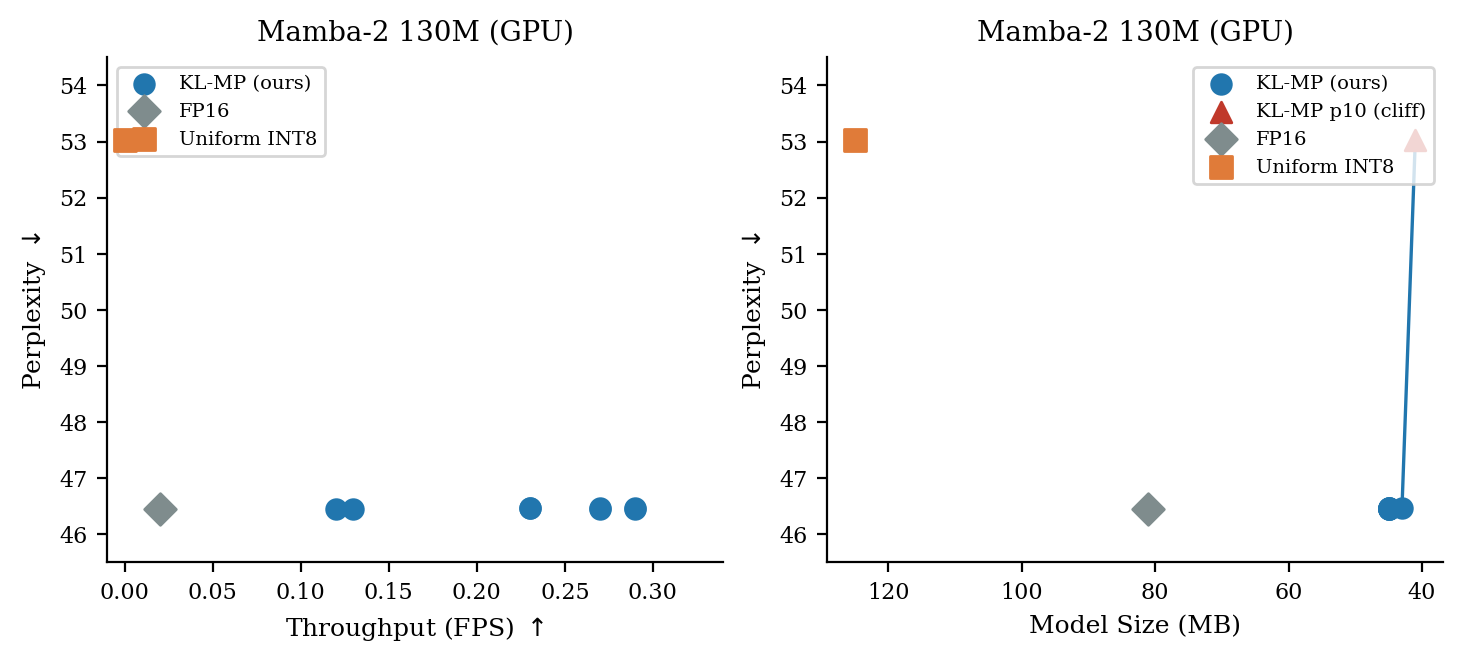
Figure 7: GPU profiling of Mamba2-130M, showing that KL-guided quantization delivers large throughput gains without perplexity cost up to the precision cliff.
Implications and Forward Outlook
This work offers a rigorous quantization sensitivity metric—KL divergence—that addresses the limitations of legacy proxies in hybrid sequence models. The forward-only approach is highly scalable, avoiding retraining and adaptation cycles, and is amenable to proprietary and privacy-sensitive deployment contexts. The empirical results substantiate mixed-precision allocation as a clear improvement for edge deployment of advanced LLMs, with substantial reductions in size, compute, and latency, while preserving accuracy.
The theoretical framework suggests future research into dynamic sensitivity-guided quantization, possibly adaptive at runtime, and extension to more complex hybrid architectures (e.g., multi-modal, emergent memory designs). Integration with hardware profiling pipelines and refined bit allocation could further optimize the Pareto frontier for on-device intelligence.
Conclusion
The paper rigorously demonstrates that KL-divergence-driven sensitivity analysis outperforms prior mixed-precision quantization strategies for SSM-Transformer hybrids, both theoretically and empirically. The methodology advances post-training quantization by leveraging forward signals and probability-space metrics, enabling efficient deployment on real-world edge hardware. The findings imply substantial practical improvements for sequence modeling on resource-constrained platforms, and set a foundation for future advances in quantization-aware model design and deployment (2604.13440).