- The paper introduces SODA, a semi on-policy strategy that leverages student-specific contrastive signals for effective black-box LLM distillation.
- It employs Direct Preference Optimization to align teacher outputs with student responses, achieving up to 2.1 benchmark gains while significantly reducing training time and GPU memory usage.
- Empirical evaluations demonstrate that SODA provides 10x faster training and improved generalization through deeper representational restructuring compared to traditional methods.
SODA: Semi On-Policy Black-Box Distillation for LLMs
Motivation and Background
Knowledge distillation is the primary mechanism for extracting capabilities from frontier LLMs and transferring them to smaller, deployable architectures. In the black-box setting, characterized by access only to teacher-generated text (e.g., closed API models like GPT-5), distillation protocols must operate without logits, gradients, or proprietary internal states. The sequence-level knowledge distillation (SeqKD) paradigm relies on supervised learning of teacher outputs, but is fundamentally off-policy: it ignores the student's own distribution, failing to correct innate student errors and suffering from exposure bias. Fully on-policy strategies, exemplified by Generative Adversarial Distillation (GAD), correct these issues by adversarially training a student-discriminator pair, but they incur severe training instability and computational overhead.
This work proposes SODA, a semi on-policy distillation strategy that bridges the efficiency gap by leveraging the invariant capability disparity between base student and teacher. SODA uses a static snapshot of the base student’s own responses as a targeted source of rejected outputs, constructing a contrastive preference dataset with no additional models or per-step sampling. Direct Preference Optimization (DPO) is then used to drive distributional alignment via a dual signal: teacher imitation and systematic mode pruning.
Methodological Contributions
SODA formalizes a semi on-policy framework for black-box distillation:
- The base student q0 is tasked with generating responses to the same set of prompts as the teacher. These student responses are paired against the teacher outputs to form preference tuples.
- A brief supervised warmup aligns the student towards the teacher, stabilizing subsequent optimization.
- DPO is applied with teacher responses as preferred and base student responses as rejected, using the warmup model as reference. This gradient efficiently targets regions of the output distribution where q0 diverges most from teacher behavior.
Critically, this approach captures nearly all benefits of on-policy error correction without continuous online rollouts and adversarial dynamics. The contrastive signal is inherently student-aware and focuses on real error modes, not generic or artificial negatives.
Empirical Evaluation
SODA is systematically evaluated on four compact models from the Qwen2.5 and Llama-3 families (3B–14B params) using GPT-5-Chat as a black-box teacher and the LMSYS-Chat dataset suite. The experimental results demonstrate:
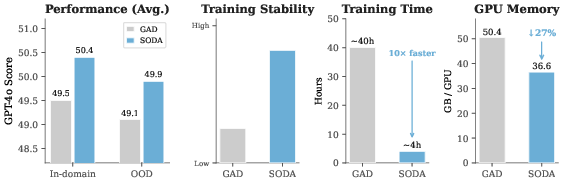
Figure 1: SODA achieves competitive or superior distillation quality versus GAD, with 10x faster training and 27% reduced GPU memory usage, plus higher training stability.
- SODA matches or outperforms GAD on 15 out of 16 model-dataset combinations, achieving up to +2.1 absolute gains on benchmarks.
- Training speed and peak GPU memory consumption are dramatically improved: 10x faster and 27% more efficient, respectively.
- Training stability is significantly better, with SODA avoiding the collapse modes and sensitivity typical of adversarial RL.
In-depth ablation shows that using the base student as the source of rejected responses substantially outperforms alternatives (cross-model outputs, low-quality GPT-4o-mini responses), confirming the necessity of student-specific negatives.
Representation and Generalization Analysis
To probe the qualitative impact of SODA, comprehensive representation analyses are performed on last-token hidden states:
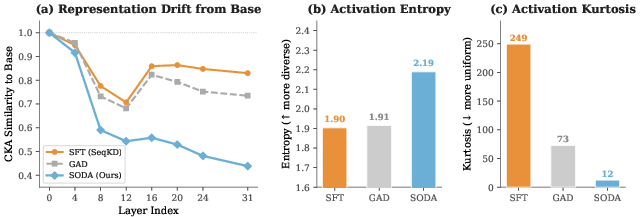
Figure 2: SODA drives deeper representational restructuring (lowest CKA similarity), highest entropy, and lowest kurtosis in last-layer activations—correlating with superior generalization and distillation performance.
- SODA induces the most divergent representations from base (CKA 0.44 vs. SFT/GAD’s higher similarity).
- Activation entropy is maximized, indicating richer and more diverse internal representations.
- Kurtosis is minimized, signaling a reduced tendency for output over-specialization.
These findings highlight SODA’s capacity to achieve robust distributional alignment and error correction, leading to enhanced generalization even on out-of-distribution prompts.
Practical and Theoretical Implications
SODA offers a paradigm shift for practitioners aiming to efficiently distill strong LLMs into compact architectures using only black-box access. Its semi on-policy protocol requires only a single offline sampling step and no additional models, making it ideal for production deployments and large-scale distillation settings. Theoretically, the work underscores the sufficiency of static student-aware contrastive signals over continuous adversarial tracking, suggesting that correction of innate student error modes is more informative than real-time adaptation.
By connecting preference optimization with inverse RL frameworks, SODA demonstrates that the intrinsic reward signal encoded by student-teacher gaps can drive highly targeted alignment, outperforming generic imitation and adversarial strategies.
Future Directions
Potential avenues for future exploration include: extending SODA-style distillation to multimodal black-box teachers; dynamic updating of the rejected response snapshot for longer training regimes; integration with self-play and augmentation-based preference datasets; and formal analysis of SODA’s limits for extremely large or structurally divergent student-teacher pairs. The demonstrated reduction in computational complexity and improvement in empirical results paves the way for broader adoption of semi on-policy distillation in both academic and industrial contexts.
Conclusion
SODA establishes a new standard for black-box LLM distillation, achieving student-aware error correction and robust distributional alignment with substantially reduced computational cost and training complexity. Its methodological simplicity and superior empirical outcomes validate the primacy of student-specific preference signals for effective alignment. SODA delivers practical and scalable distillation for small models, highlighting the central role of targeted suppression of characteristic student errors.