- The paper introduces a three-stage pipeline that uses compact Sum-of-Gaussians and keyframe selection to efficiently reconstruct 3D hand-object dynamics.
- It demonstrates significant improvements with up to 75% reduction in Chamfer Distance and 65% lower MPJPE, while operating an order-of-magnitude faster than previous methods.
- The approach effectively mitigates occlusion and depth ambiguity using temporal guidance and occlusion gating, ensuring stable and generalizable tracking.
Grasp in Gaussians (GraG): Efficient Monocular 3D Hand-Object Interaction Reconstruction
Introduction and Motivation
Reconstructing dynamic hand-object interactions in 3D from monocular video is a highly underconstrained task, challenged by severe hand–object occlusion and depth ambiguity. The practical importance of this problem spans robotics, AR/VR, and manipulation benchmarking. Existing approaches are hampered by dependence on pre-scanned object templates, lack of generalization to new object categories, or prohibitive computational costs when processing unconstrained videos with heavy occlusions and complex backgrounds.
"Grasp in Gaussians" (GraG) (2604.12929) introduces a highly efficient pipeline leveraging compact Sum-of-Gaussians (SoG) representations, combined with strong initialization from recent large-scale foundational models. The method achieves temporally consistent, generalizable 3D hand–object motion and geometry reconstruction, while dramatically reducing computation time.
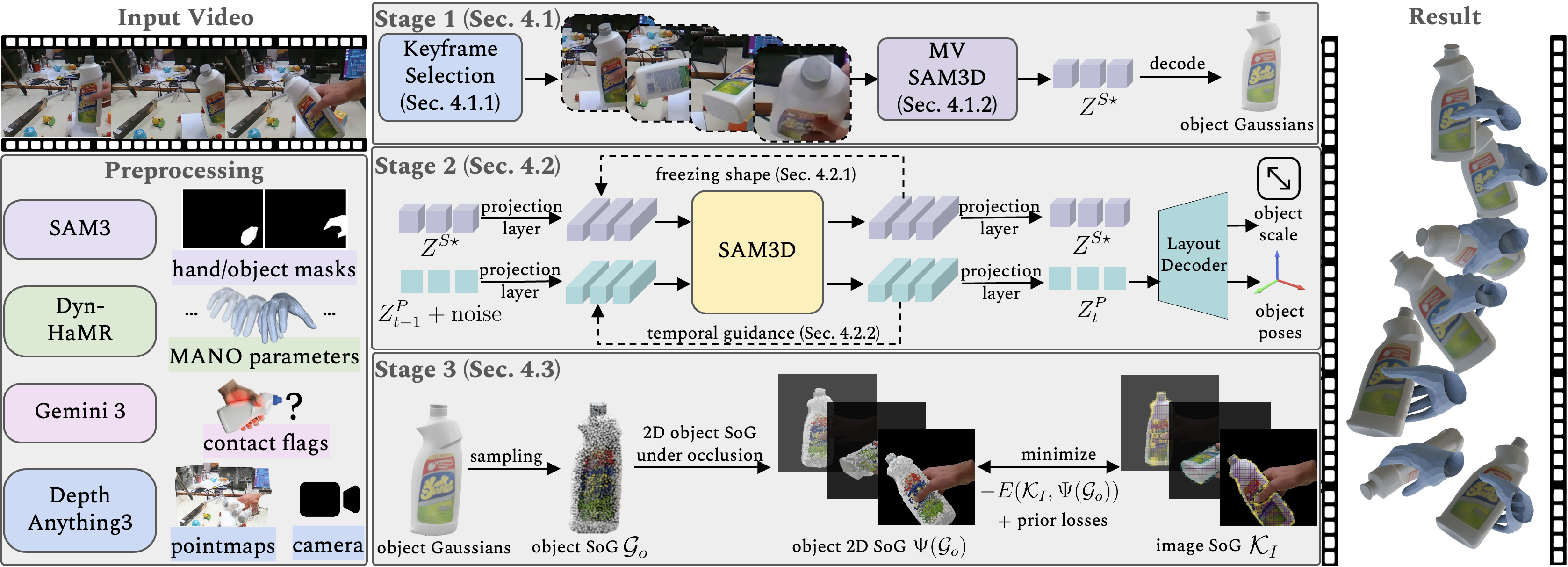
Figure 1: Overview of the GraG pipeline: a monocular video is processed to obtain keyframe-selected canonical object geometry, temporally stable per-frame object pose, and efficient SoG-based refinement for hand and object.
Methodology
GraG operates via a three-stage pipeline specifically designed to exploit the strengths of both modern large-scale generative 3D priors (notably SAM3D and its multi-view extension) and classical SoG-based tracking efficiency:
Stage 1: Keyframe Selection and Canonical Object Reconstruction
Rather than heavy frame-wise optimization, GraG selects a compact, diverse subset of keyframes using a diversity and balance-driven objective over ViT features. These keyframes are input to MV-SAM3D to generate a canonical object geometry by decoding shared shape tokens into a dense 3D Gaussian asset, which forms a strong geometric prior regardless of category or occlusion state.
Stage 2: Temporally Stable Per-Frame Object Pose Estimation
To mitigate drift and instability, especially under occlusion or appearance changes, GraG adapts SAM3D to videos: object shape is frozen across frames, and per-frame layout parameters (rotation, translation, scale) are estimated with explicit temporal guidance in the latent space. This penalizes abrupt pose changes and corrects orientation flips under ambiguous observations.
Stage 3: SoG-Based Hand-Object Tracking and Refinement
The dense canonical Gaussians are sparsified using farthest-point sampling, resulting in a compact 3D SoG for the object (≈2000 Gaussians). For each frame, a quad-tree clusters image regions inside the object mask into 2D Gaussians forming an image SoG. Tracking is formulated as an optimization between projected object SoG and image SoG, maximizing closed-form Gaussian overlaps. Crucially, hand masks are used for occlusion gating, ensuring only visible object parts contribute.
The hand trajectory, initialized by off-the-shelf Dyn-HaMR (MANO-based), is efficiently refined with lightweight geometric losses (2D joint reprojection, depth priors), eschewing expensive per-frame hand appearance optimization.

Figure 2: Approximating the image as Gaussians and demonstrating SoG alignment pre- and post-optimization.
Experimental Evaluation
Benchmarks and Metrics
GraG is evaluated on two major hand–object interaction datasets: HO3Dv3 (category-diverse, third-person) and HOT3D (egocentric, with rapid motion and heavy occlusions). Evaluation metrics follow standard protocols: object reconstruction is measured with ICP-aligned Chamfer Distance (CD), F-score at 10 mm, and hand-object relative CD (CDh); hand pose is evaluated via mean-per-joint position error (MPJPE). Efficiency and robustness metrics include normalized runtime (hours per 100 frames) and success rate—the latter measuring failure cases such as unrecoverable drift or broken initialization.
Quantitative Results
GraG consistently achieves superior geometric reconstruction and hand pose accuracy compared to prior SoTA methods (HOLD, BIGS, MagicHOI), with 13.4% lower CD and 65% lower MPJPE on HO3Dv3, and up to 75% reduction in CD on HOT3D. Importantly, GraG maintains a 100% success rate across both datasets, while others frequently fail on longer, unconstrained egocentric sequences. Computational efficiency is dramatically improved: only 0.56 hours per 100 frames, order-of-magnitude faster than competitors (up to 10.5 hours for HOLD).
Figure 3: Qualitative comparison on HO3D and HOT3D: GraG preserves sharper object detail and yields more plausible hand poses with fewer interpenetrations than previous methods, while providing significantly improved efficiency.
Qualitative Analysis
(GraG) outputs faithfully preserve fine geometric structure even for thin or occluded objects (e.g., scissors), maintain hand–object contact realism, and minimize hand/object interpenetration. Competing methods, dependent on correspondence-based SfM or dense Gaussian Splatting, are notably less robust under egocentric and small-object scenarios, frequently failing to reconstruct or drifting during optimization.
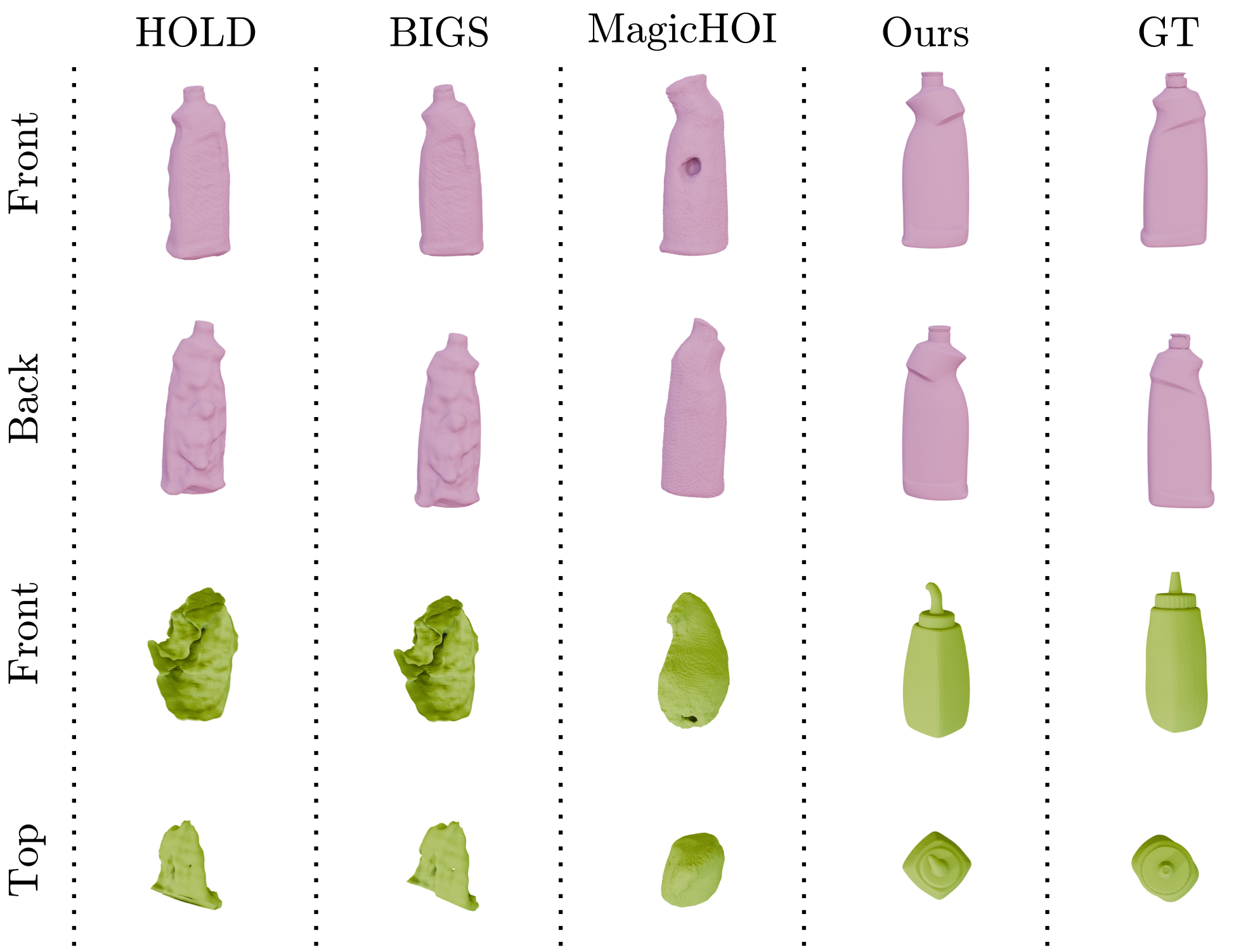
Figure 4: Object-only reconstruction comparison for four methods, showing GraG's superior preservation of geometry across both datasets.
Ablations and Design Analysis
GraG's design choices are empirically validated through extensive ablations. Random keyframe selection leads to degraded object geometry; removing shape freezing or temporal guidance increases hand-relative object pose error; omitting SoG refinement (or visibility gating for hand occlusion) markedly reduces alignment quality. Replacing compact SoG tracking with dense Gaussian Splatting decreases stability, impairs convergence, and increases computational cost.
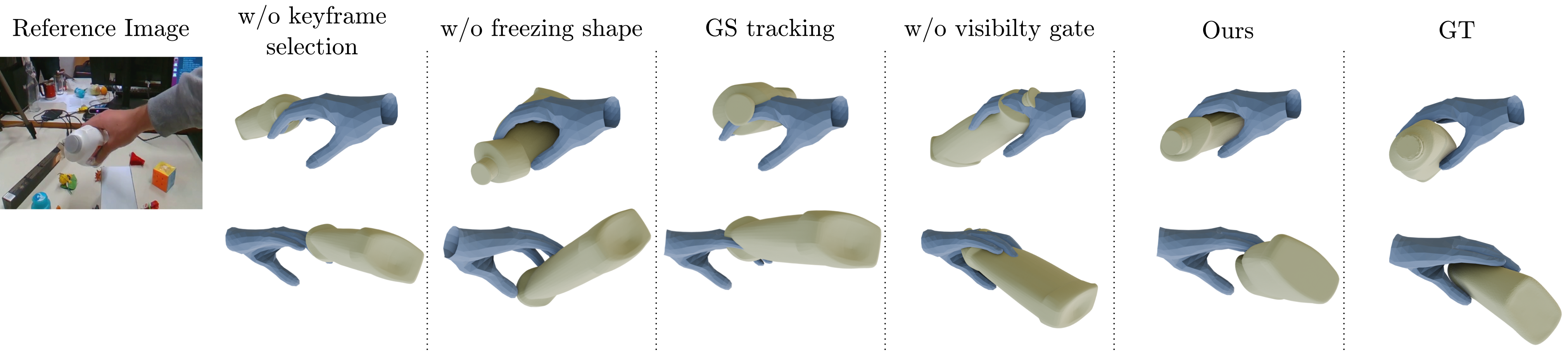
Figure 5: Ablation results, visualizing the impact of key design factors—including keyframe selection, shape freezing, SoG tracking, and visibility gating—on reconstruction quality.

Figure 6: Impact of keyframe selection on reconstructed shape and scale—demonstrating multi-view selection yields the most accurate canonical objects.
Limitations and Depth-Scale Ambiguity
Though robust to modest foundation model errors, GraG inherits residual weaknesses from monocular depth predictors: if pointmap depth estimation is grossly erroneous, subsequent refinement can result in spurious scale or pose. The SoG objective, focused on image-silhouette alignment, may compensate for erroneous depth by over-scaling the object, thus inflating hand-relative CD even when trajectories are otherwise correct.

Figure 7: Incorrect object depth in pointmaps leads to erroneous scale and translation alignment, disrupting hand–object pose.

Figure 8: Depth-scale ambiguity: when depth prior is too large, the optimizer compensates by inflating object scale, leading to higher CDh despite correct trajectories.
Theoretical and Practical Implications
GraG demonstrates that carefully integrated classical tracking paradigms (SoG), fueled by strong 3D generative priors from foundation models, can supersede both template-based and per-frame neural optimization approaches in efficiency, generalization, and tractability. This approach is especially compelling for out-of-domain, long-duration video and general hand-object manipulation in the wild.
The method exposes a promising direction: sparse, analytic models as intermediates between data-driven single-view asset generators and physically plausible motion capture. The explicit handling of hand-induced occlusions, leveraging rich 2D and segmentation cues, is a step toward robust, task-agnostic pipelines.
Future Directions
Extensions to multi-object and multi-hand scenarios, as well as deformable object reconstruction, are immediate avenues. Incorporation of richer physical plausibility constraints and expanding the pipeline to leverage self-supervised or multi-modal temporal cues may further stabilize depth/scale ambiguities. As foundation models for monocular depth and 2D mask extraction improve, downstream SoG-based pipelines will naturally inherit their gains.
Conclusion
GraG achieves efficient, accurate, and highly generalizable monocular 3D hand–object interaction reconstruction, outperforming prior SoTA both in speed and prediction fidelity across challenging domains. The synergy between strong learned priors and compact analytic tracking is shown to be both effective and practical, supporting real-world deployments where rapid, robust generalization is required.