- The paper introduces MISID, a multimodal, multi-turn dataset capturing 9 hours of strategic deception gameplay with audio, video, and text for nuanced intent analysis.
- The paper presents a two-tier, hierarchical annotation scheme alongside the FRACTAM framework, which decouples, anchors, and constructs causal chains to enhance evidence-based reasoning.
- The paper demonstrates that applying FRACTAM improves hidden intent inference accuracy by 8.57 percentage points, outperforming conventional VideoLLMs in complex deception scenarios.
MISID: A Multimodal Multi-turn Dataset for Complex Intent Recognition in Strategic Deception Games
Introduction
This paper presents MISID, a novel benchmark for complex intent recognition, targeting the scenario of strategic deception in multi-turn, multimodal, and multi-participant environments (2604.12700). Existing intent recognition datasets primarily focus on dyadic or single-turn explicit communication, thereby neglecting the intricacies of prolonged, information-dense deception games where participants actively pursue hidden agendas. MISID addresses this shortcoming by curating temporally-aligned audio, video, and textual data from high-pressure social deduction gameplays, introducing a two-tier, multi-dimensional annotation scheme purpose-built for long-context, evidence-based intent analysis.
MISID Dataset Design and Characteristics
MISID consists of 3,962 high-quality utterance samples, captured from carefully selected strategic deception game sessions. These cover 120 role instances with 15 participants, spanning over 9 hours of interaction and up to 555 turns per session. Each utterance is complemented by video and audio modalities, allowing for precise cross-modal analysis. Speaker diarization leverages advanced pipelines, with post-processing for face detection and alignment.
The dataset introduces a granular, hierarchical annotation scheme:
- The first tier annotates micro-level states including subjectivity, basic emotion, and intensity.
- The second tier encodes discourse-level features, such as modality inconsistencies, confidence, deception, key event anchoring, and causal chain construction.
This structure enables systematic assessment of elusive and implicitly conveyed intentions within dynamic, high-stakes environments. Human annotation, following LLM-generated suggestions, employs iterative peer review and cross-modal verification for quality.
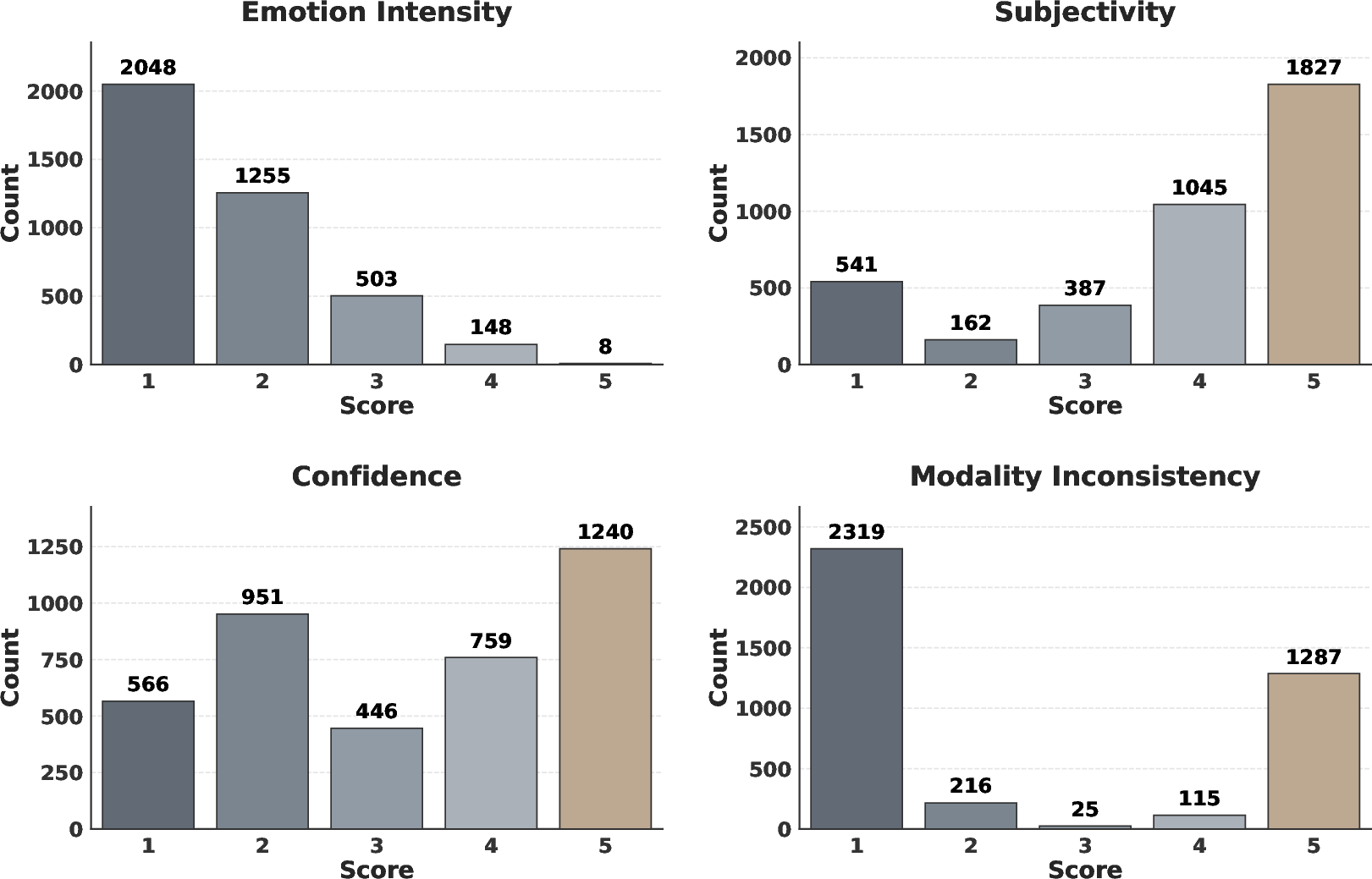
Figure 1: Distribution of multi-dimensional annotations in the MISID dataset—e.g., intensity skews towards low values, while subjectivity is bi-modal.
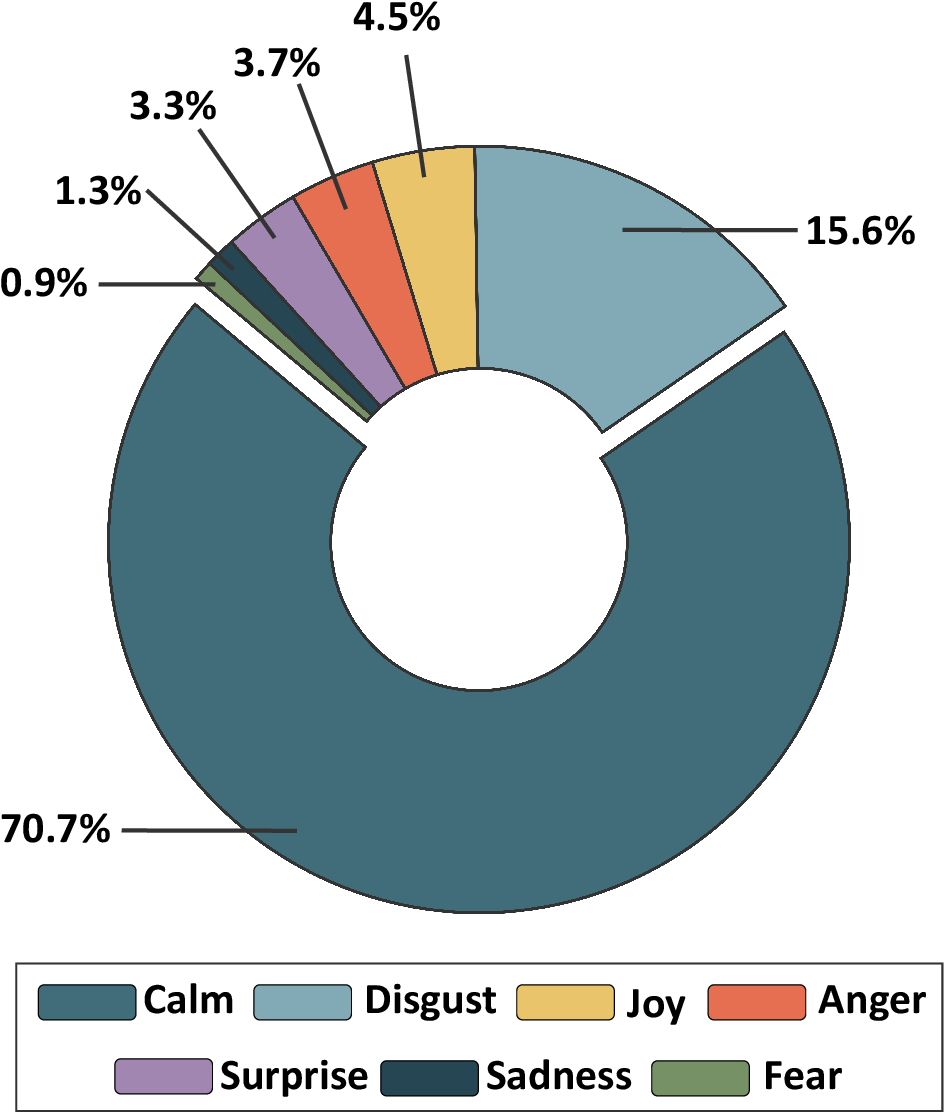
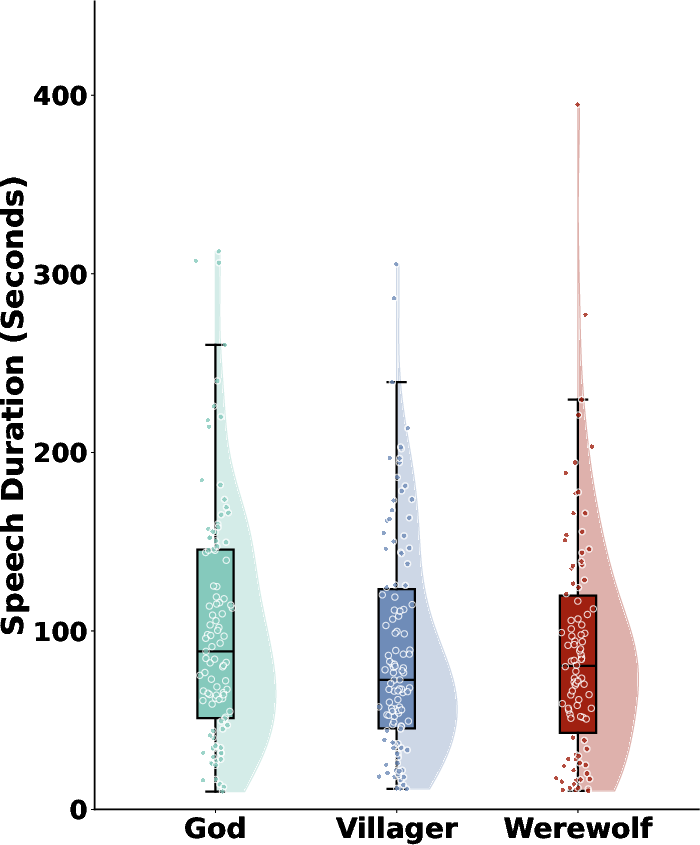
Figure 2: Emotion category and speech duration distributions, demonstrating a strong class imbalance (e.g., "Calm" dominates) and wide variance in turn lengths.
MISID's annotation distributions (Figure 1 and Figure 2) reveal the inherent statistical complexity: the prevalence of low-intensity emotional expressions, heavy skew toward objective subjectivity in certain segments, and a predominance of "Calm" states amid brief instances of highly charged affective events. These patterns underscore the nuanced challenges for both unimodal and multimodal LLMs.
FRACTAM Framework for Fact-Grounded Reasoning
To systematically assess the shortcomings of current state-of-the-art models, the paper introduces FRACTAM, a baseline architectural framework specifically tailored for MISID's evidence-centric paradigm. FRACTAM's core mechanism follows a "Decouple-Anchor-Reason" sequence:
- Unimodal Fact Decoupling: Each modality (text, audio, video) is independently processed and transformed into symbolic representations, eliminating the confounding influence of text-dominant fusion layers and the risk of modality hallucination.
- Hybrid Long-range Fact Anchoring: FRACTAM retrieves key historical facts through a two-stage process—an initial weighted Reciprocal Rank Fusion recall in both lexical and semantic spaces, followed by re-ranking using a cross-encoder (Qwen3-Reranker).
- Explicit Causal Chain Construction: The framework enforces explicit chain-of-evidence reasoning by compelling the inference model to trace its prediction through a sequence of factual anchors and cross-modal cues.
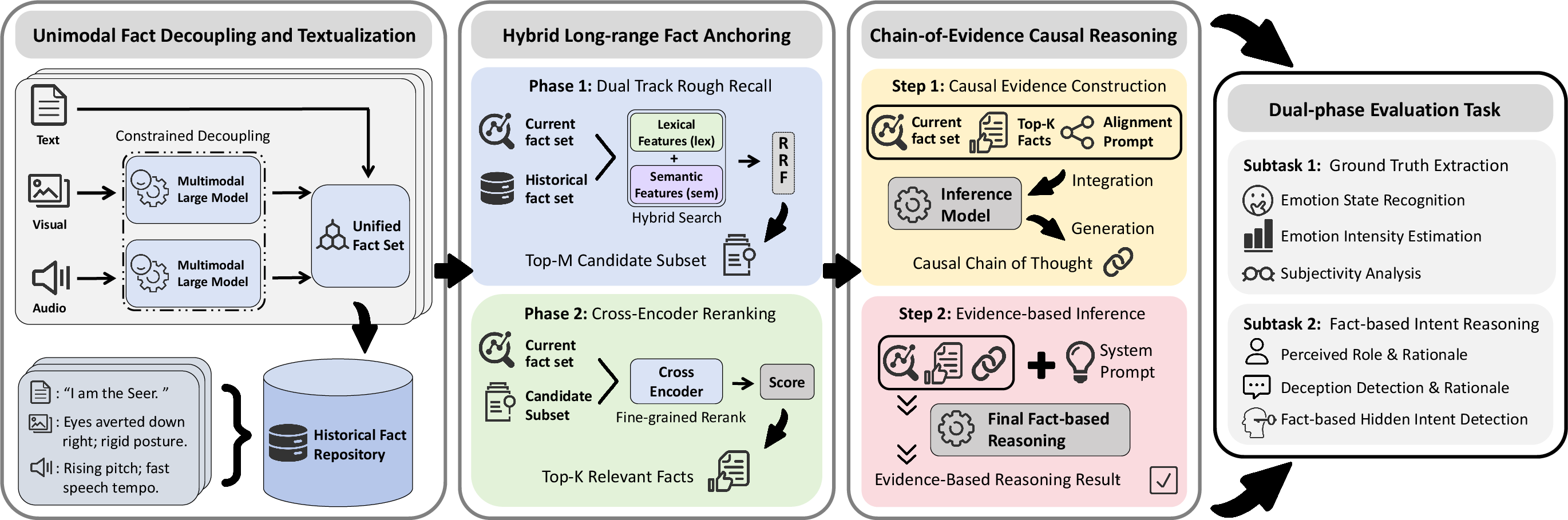
Figure 3: FRACTAM architecture overview; the pipeline comprises unimodal decoupling, dual-stage retrieval, and explicit causal chain reasoning.
This method robustly addresses previously observed deficiencies such as text-prior visual hallucination, causal threading failures, and degraded modal synergy in both baseline VideoLLMs and LLMs.
Critical Evaluation and Empirical Analysis
Systematic benchmarking of mainstream VideoLLMs (e.g., Gemini, GPT-4o, Qwen3-VL series) and text-only LLMs (e.g., Claude Sonnet, DeepSeek, GLM, GPT-5.1) reveals several key findings:
- Text-prior Visual Hallucination: VideoLLMs frequently override genuine visual cues with spurious textual alignment, leading to degraded intent inference—average hidden intent recognition accuracy for VideoLLMs is just 29.73%.
- Causal Threading Limitations: Both unimodal and multimodal models struggle with causal attribution, as reflected by the gap between accuracy in binary deception classification (e.g., ~44.25%) and the lower average reasoning consistency scores (~42.51%).
- Impaired Modal Synergy: Contrary to expectation, raw visual modality injection negatively impacts higher-level reasoning: text-only LLMs outperform VideoLLMs in all strategic metrics, highlighting the noise introduced by naively concatenated vision features.
FRACTAM demonstrably improves performance across all axes. Notably, post-FRACTAM, the average Hidden Intent Inference Score rises to 42.79% (an 8.57 percentage point improvement over vanilla LLMs), and the accuracy of role and deception recognition is consistently higher. State-of-the-art text LLMs, when augmented with FRACTAM, frequently surpass their VideoLLM counterparts in both judgment and explainability metrics. This attests to the necessity of explicit, evidence-chain-constrained reasoning in overcoming current model limitations.
Implications and Future Directions
MISID represents a substantial advance for the evaluation of artificial social intelligence. Practically, the dataset and framework enable the community to rigorously probe the opaque gap between surface communication and latent intent. Theoretically, they further illuminate the challenges of fact-centric, multi-hop causal reasoning, modal alignment, and context lifespan management in multimodal LLMs.
Empirical findings highlight the urgency for models that can (a) systematically decouple and represent objective, modality-specific facts, (b) retrieve, align, and chain key causal events across long temporal windows, and (c) robustly infer underlying psychological states without succumbing to cross-modal hallucinations or memory decay.
Anticipated directions include the design of multi-hop memory architectures that maintain modality invariance, novel causal-retrieval-augmented LLMs, and hybrid architectures integrating neuro-symbolic reasoning constraints for improved interpretability and reliability.
Conclusion
MISID delivers a paradigm shift for intent analysis research by operationalizing high-fidelity, multi-turn, multimodal, evidence-anchored discourse in strategic deception games. The provided baseline, FRACTAM, establishes a new state-of-the-art for fact-grounded intent recognition, significantly outperforming black-box LLMs on all major axes in this challenging setting. Taken together, these contributions provide an essential resource, challenge, and methodological roadmap for the next generation of interpretable, robust, and socially intelligent multimodal conversational AI systems.