- The paper presents BID-LoRA, which decouples learning, retention, and unlearning via three distinct LoRA adapters to prevent gradient interference.
- It leverages escape unlearning with geometric projection to irreversibly remove unwanted class information while preserving retained knowledge.
- Empirical results on CIFAR-100 and CASIA-Face100 demonstrate minimal knowledge leakage and high retention with only 5% parameter updates.
BID-LoRA: A Parameter-Efficient Architecture for Continual Learning and Unlearning
Introduction and Motivation
Contemporary AI systems are increasingly required to support dynamic knowledge management, encompassing not only continual learning (CL) — the ability to incrementally acquire new knowledge without catastrophic forgetting — but also machine unlearning (MU), the selective and verifiable removal of data- or class-specific knowledge. This dual capability, formalized as Continual Learning-Unlearning (CLU), is critical for real-world deployments in scenarios involving privacy requirements, regulatory mandates (such as GDPR/CCPA), and dynamic membership datasets, including identity management and face recognition systems.
While the CL literature has established a broad family of techniques for sequential knowledge acquisition, approaches to machine unlearning remain in nascent stages, and naive aggregation of CL and MU strategies results in knowledge leakage — gradual degradation of retained knowledge over repeated learning-unlearning cycles. The paper "BID-LoRA: A Parameter-Efficient Framework for Continual Learning and Unlearning" (2604.12686) provides a principled and empirically superior solution to this challenge, built upon the concept of bi-directional low-rank adaptation and robust architectural isolation of learn/retain/unlearn objectives.
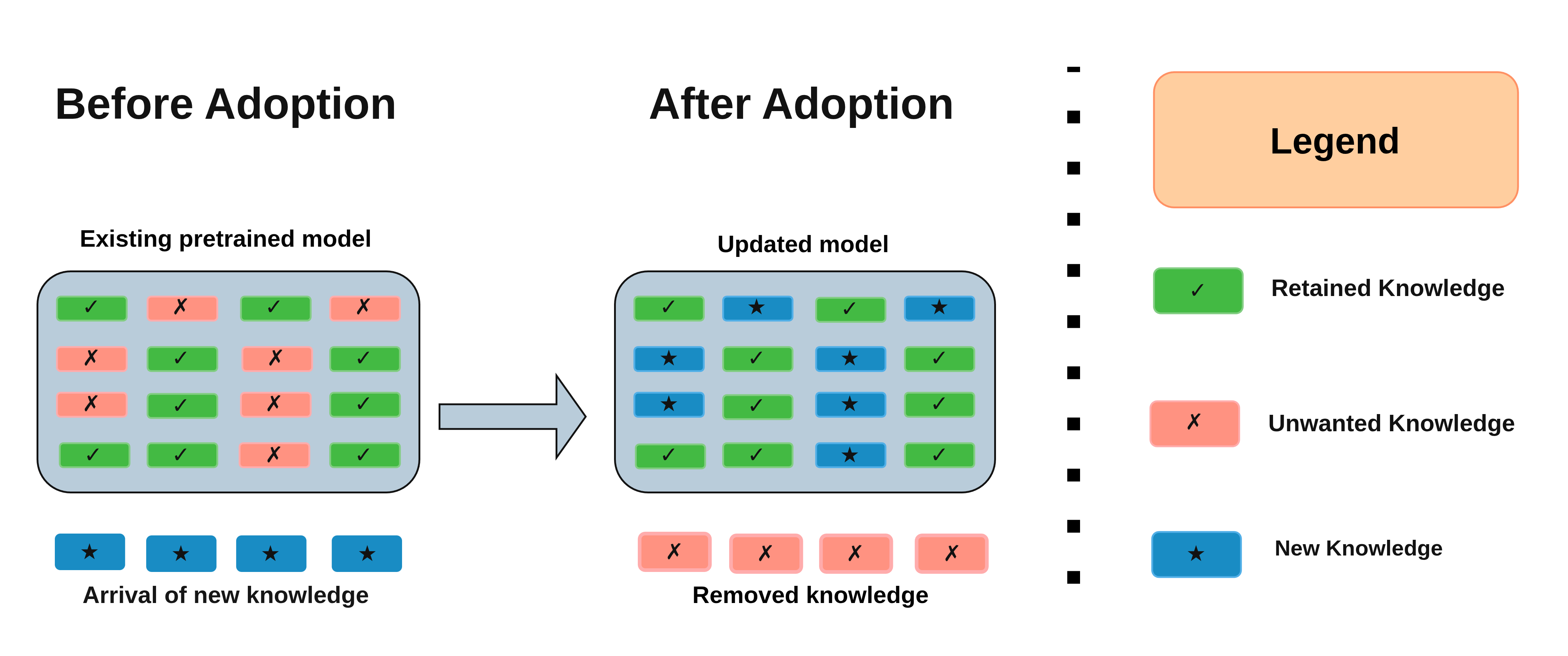
Figure 1: Overview of CLU. The CLU system removes unwanted knowledge (red), retains prior knowledge (green), and integrates new knowledge (blue).
BID-LoRA Architecture: Pathway Separation and Escape Unlearning
LoRA and Parameter Efficiency
Low-rank adaptation (LoRA) provides an established methodology for parameter-efficient fine-tuning of transformer layers by injecting low-rank matrices into pre-trained model weights; only ∼5% of parameters are updated, minimizing memory and computational costs. Standard LoRA, however, does not differentiate between learning, retention, and forgetting, which presents challenges for CLU.
Figure 2: LoRA placement in BID-LoRA at Attention Modules.
Three-Way Adapter Separation
BID-LoRA introduces adapter pathway separation by instantiating three distinct LoRA adapters within each attention module:
- Unlearn (forget) adapter for purging specified knowledge
- Retain adapter for stabilizing existing capabilities
- New adapter for accreting new knowledge
This design decouples competing gradient signals, effectively mitigating interference and the subsequent knowledge leakage endemic to prior approaches. Each adapter is associated with a dedicated loss, ensuring that parameter updates remain localized and objective-specific.
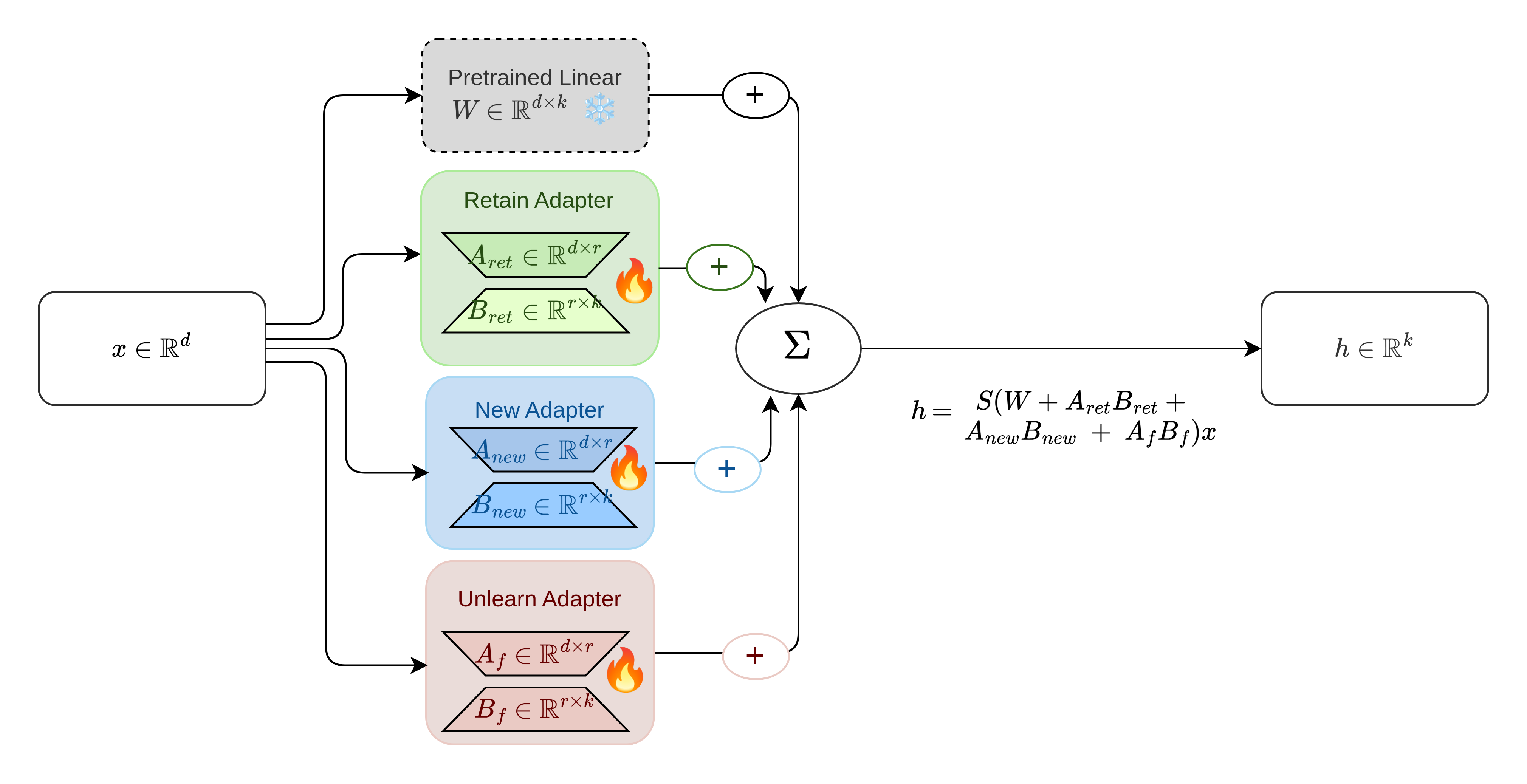
Figure 3: Pathway separation for BID-LoRA. The architecture isolates retention, new learning, and unlearning objectives.
Escape Unlearning: Geometric Forgetting
To verifiably erase unwanted knowledge, BID-LoRA proposes escape unlearning: forget-class embeddings are forced toward an "escape point" in representation space, computed to be maximally distant from all retain-class centroids. This is achieved by solving a minimax direction optimization and scaling escape points outside the embedding hypersphere, producing many-to-one forget mappings and minimizing class recoverability. Retain embeddings are regularized via a frozen teacher anchor to resist drift toward the escape manifold.
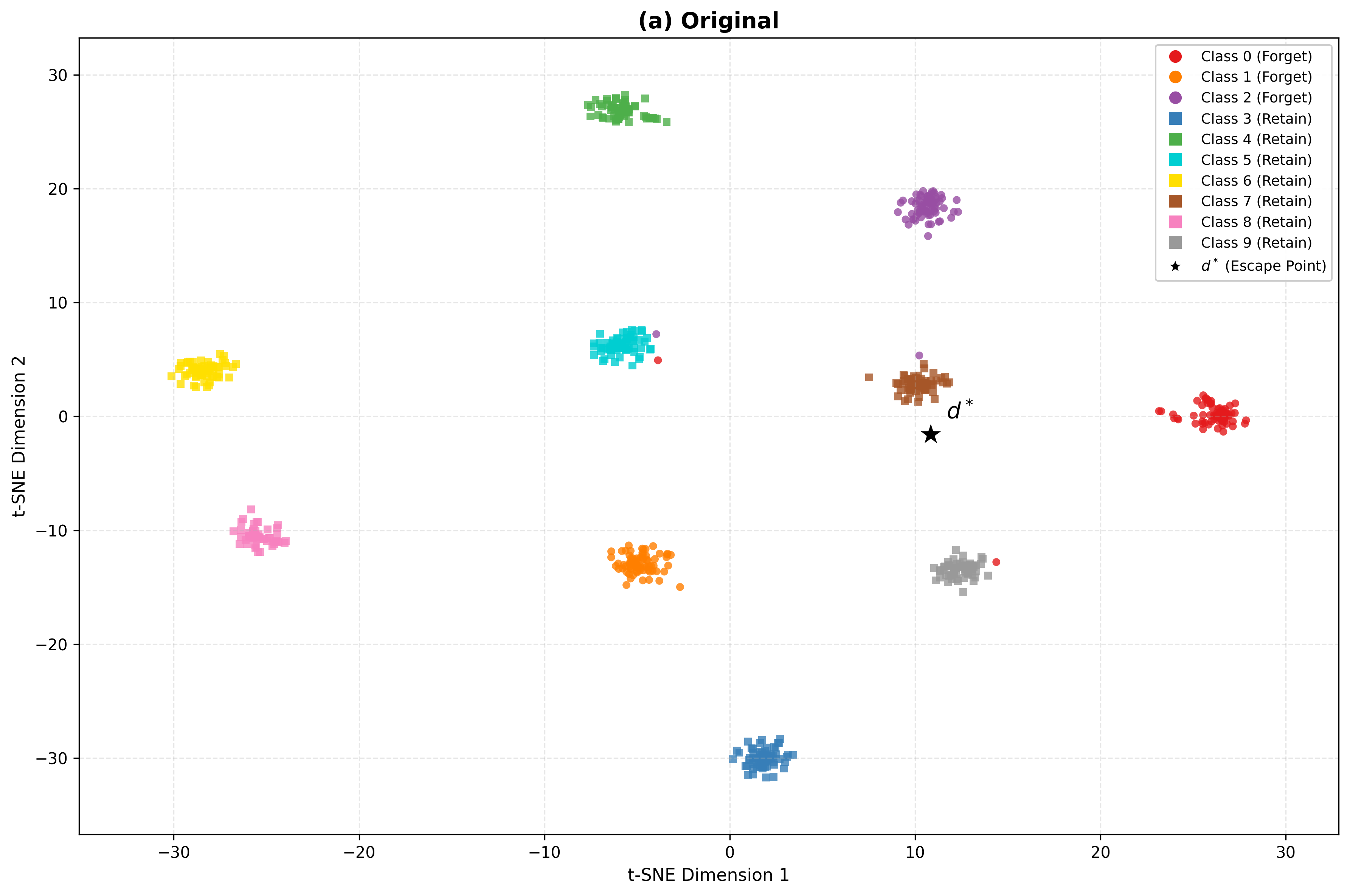
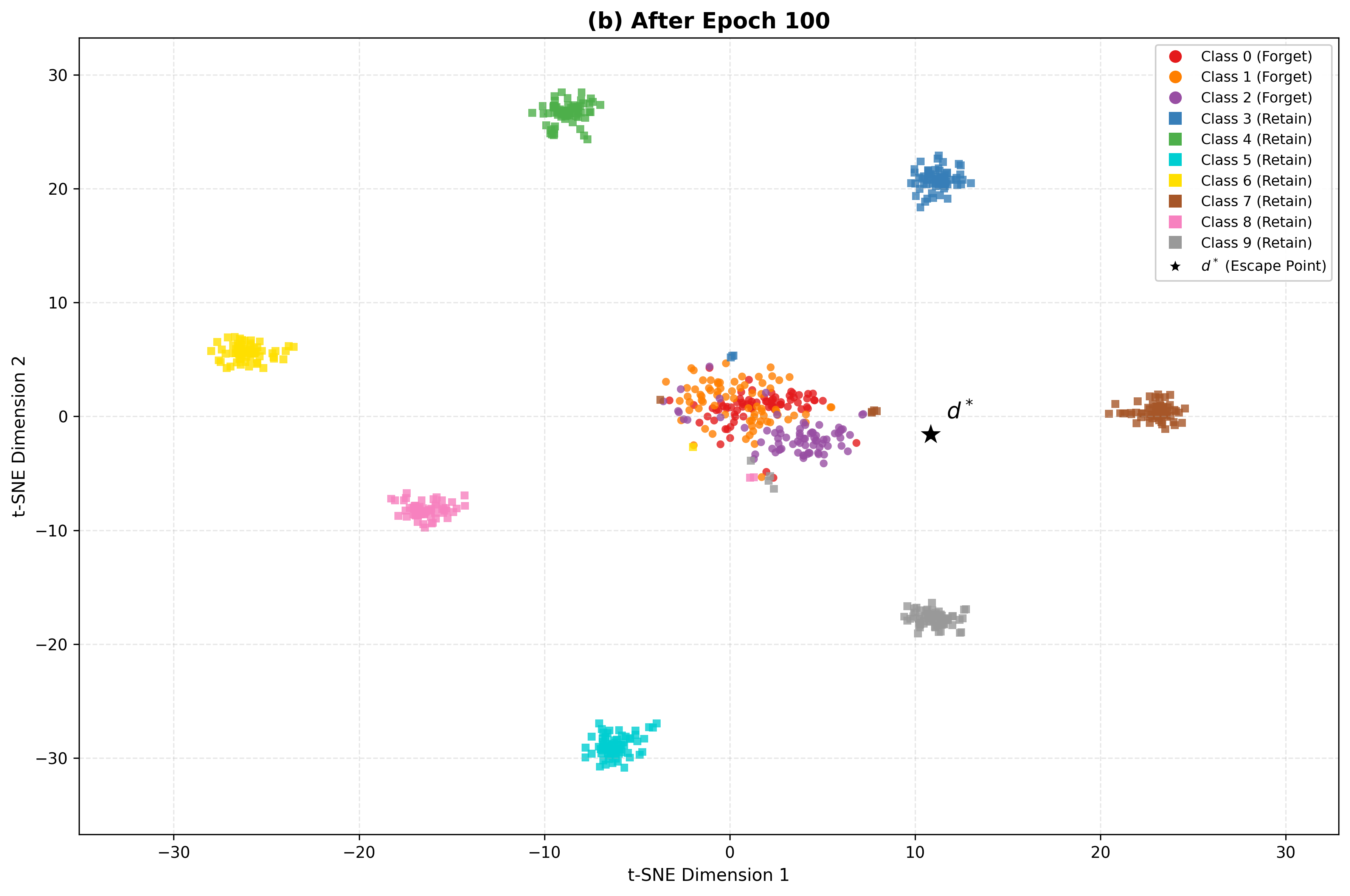
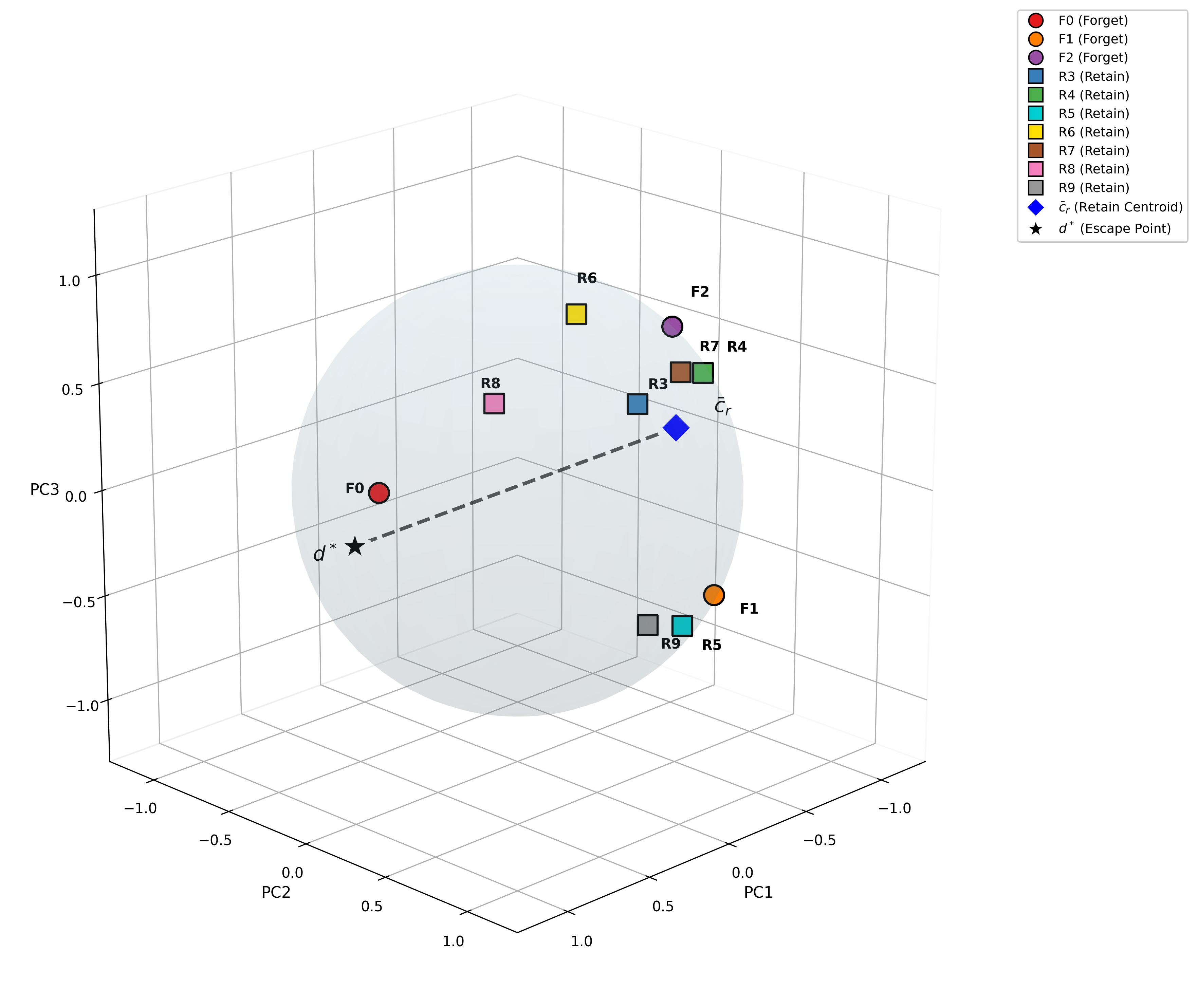
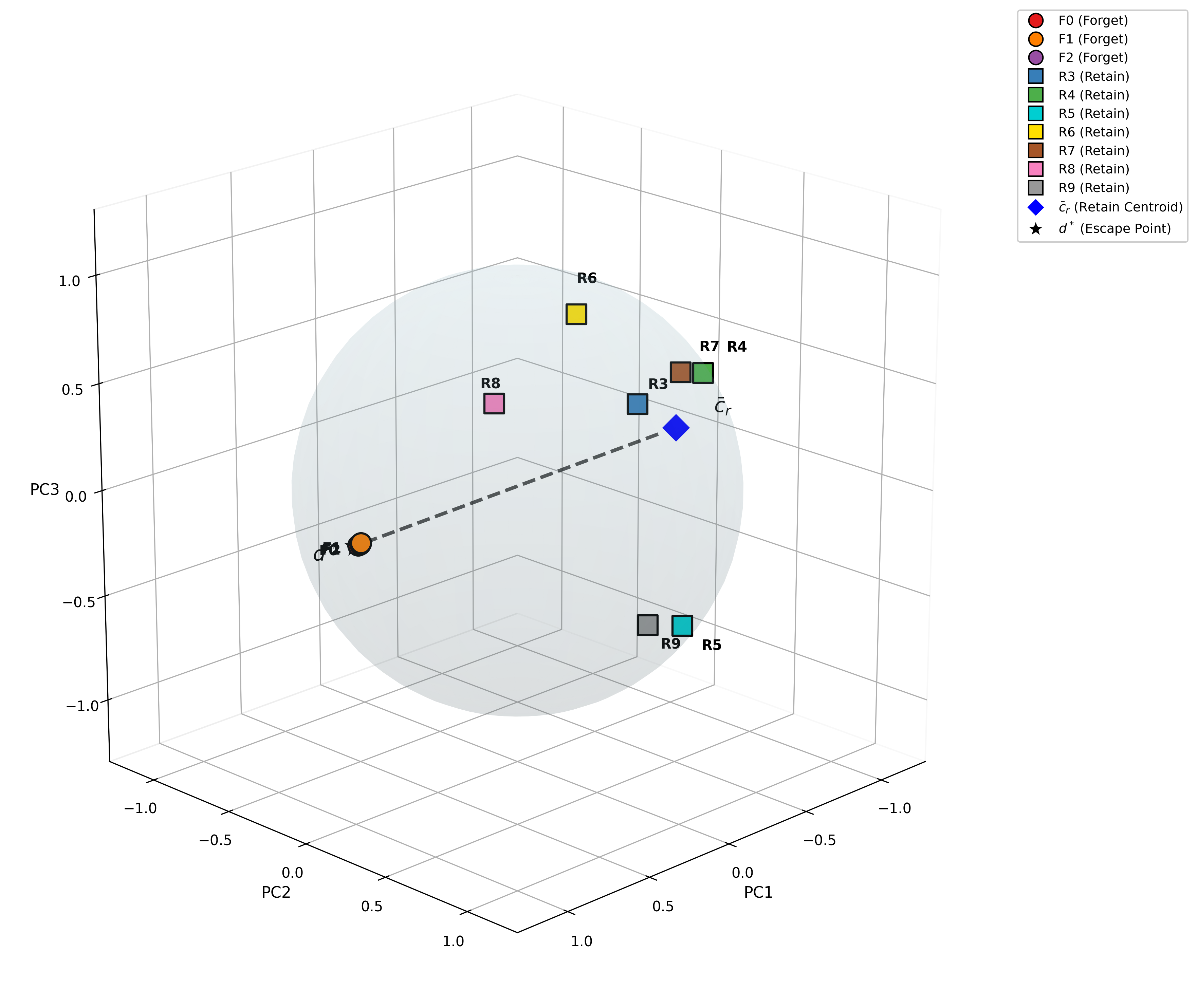 *Figure 4: Geometric verification of unlearning. Top row: t-SNE visualization showing forget classes migrating toward escape point d∗. Bottom row: 3D hypersphere visualization with dashed antipodal axis from cˉr to d∗. *
*Figure 4: Geometric verification of unlearning. Top row: t-SNE visualization showing forget classes migrating toward escape point d∗. Bottom row: 3D hypersphere visualization with dashed antipodal axis from cˉr to d∗. *
Continual Adaptation Evaluation and Results
Experimental Protocol
BID-LoRA is evaluated on two regimes: standard classification (CIFAR-100) and face recognition (CASIA-Face100). Both employ a sliding window continual adaptation protocol: per cycle, a subset of classes is retained, another subset is forgotten, and new classes are integrated — implemented over six progressive adaptation tasks.
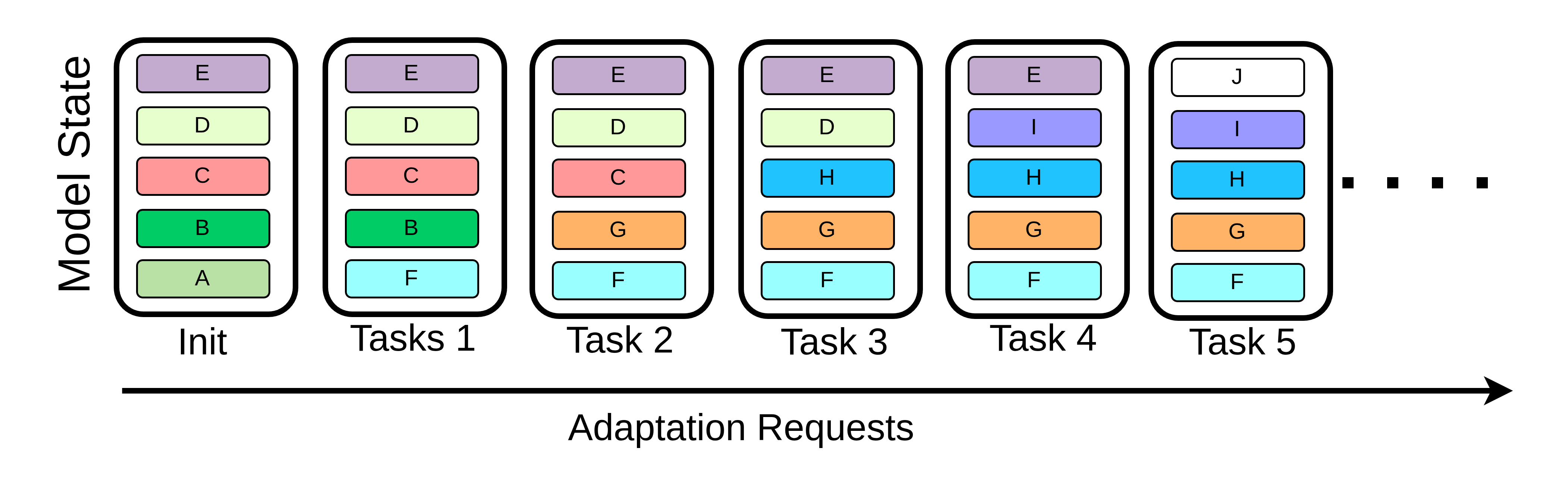
Figure 5: Illustration of continual adapting evaluation protocol. A sliding window over classes assesses adaptation stability and replacement.
The system operates under tight storage constraints (replay buffer of only 10% of retain data), and only approximately 5% of model parameters are mutable, in contrast to baselines that fine-tune the entire model.
Across all tasks, BID-LoRA demonstrates:
- Retained accuracy (Accr) and new knowledge accuracy (Accn) within 2–4% of the oracle model trained from scratch
- Forget accuracy (Accf) at or near chance levels, confirming effective unlearning
- Minimal knowledge leakage: overall accuracy drops only 2.5% (classification) and 2% (face recognition) from Task 1 to Task 6, significantly outperforming baselines (which see up to 8% drop)
- Reduced vulnerability to membership inference attacks, with MIA rates converging to 0.5, informing verifiable data erasure
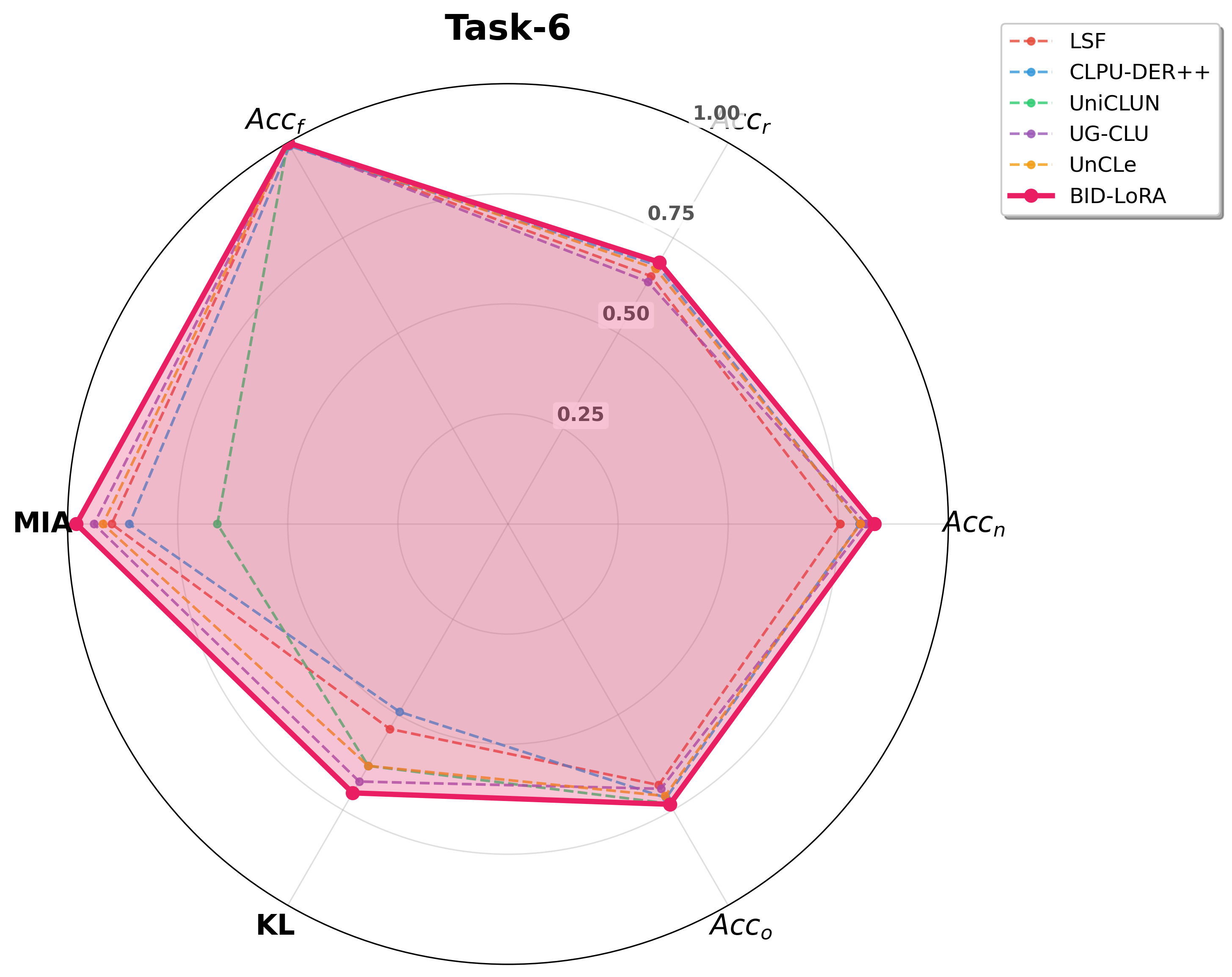
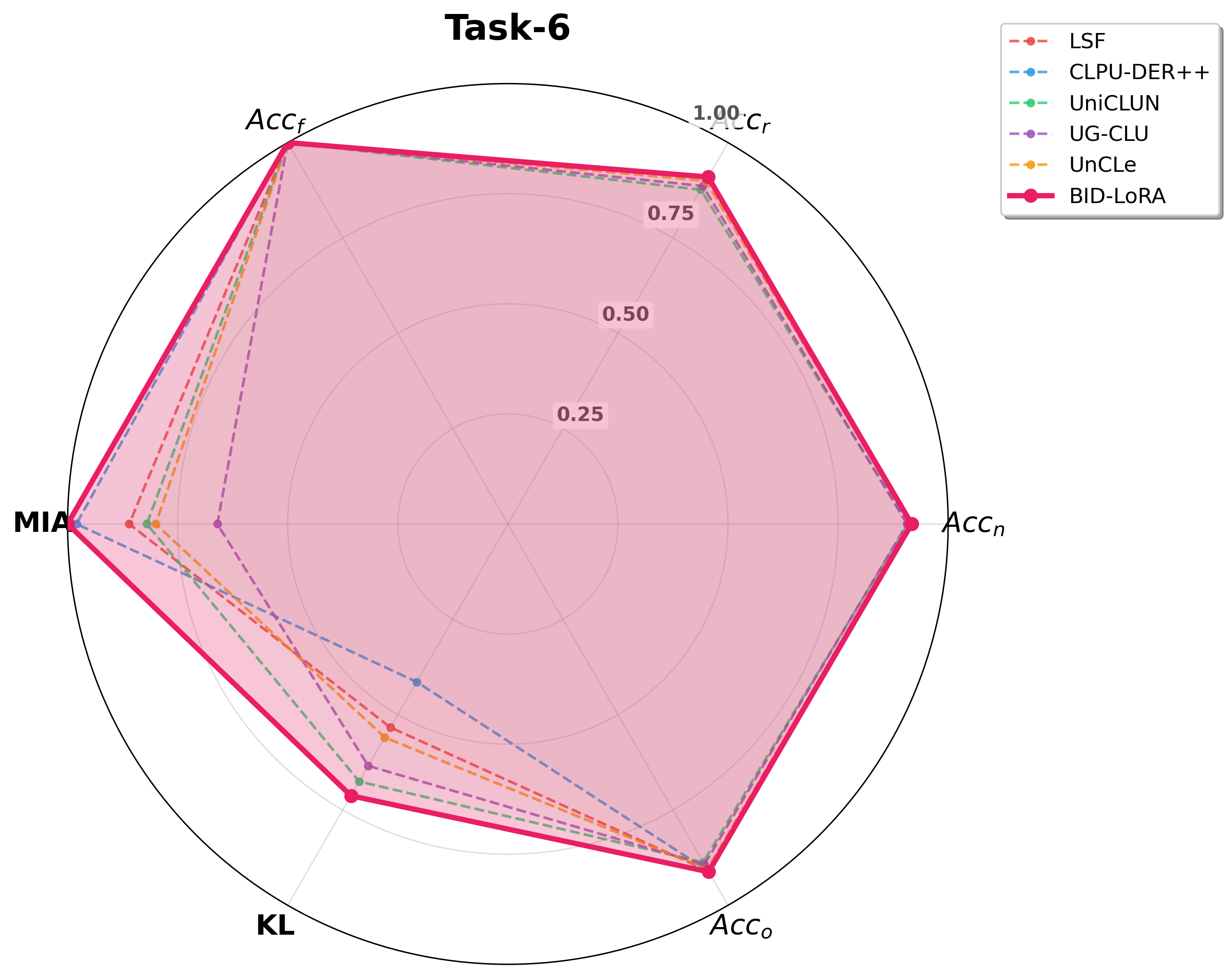
Figure 6: Radar plot comparison at Task-6. BID-LoRA consistently outperforms all baselines across metrics on both classification and face recognition tasks.
Knowledge Leakage versus Prior Art
A salient finding is the progressive knowledge degradation over repeated CL/MU cycles when naively combining SOTA continual learning (e.g., ER-ACE, DER++) and machine unlearning (e.g., GS-LoRA, SalUn) algorithms. These combinations, without pathway separation or dedicated forgetting trajectories, structurally fail under extended adaptation. Knowledge leakage is visualized as a monotonic decline in retain accuracy, validating the need for unified CLU architectures.
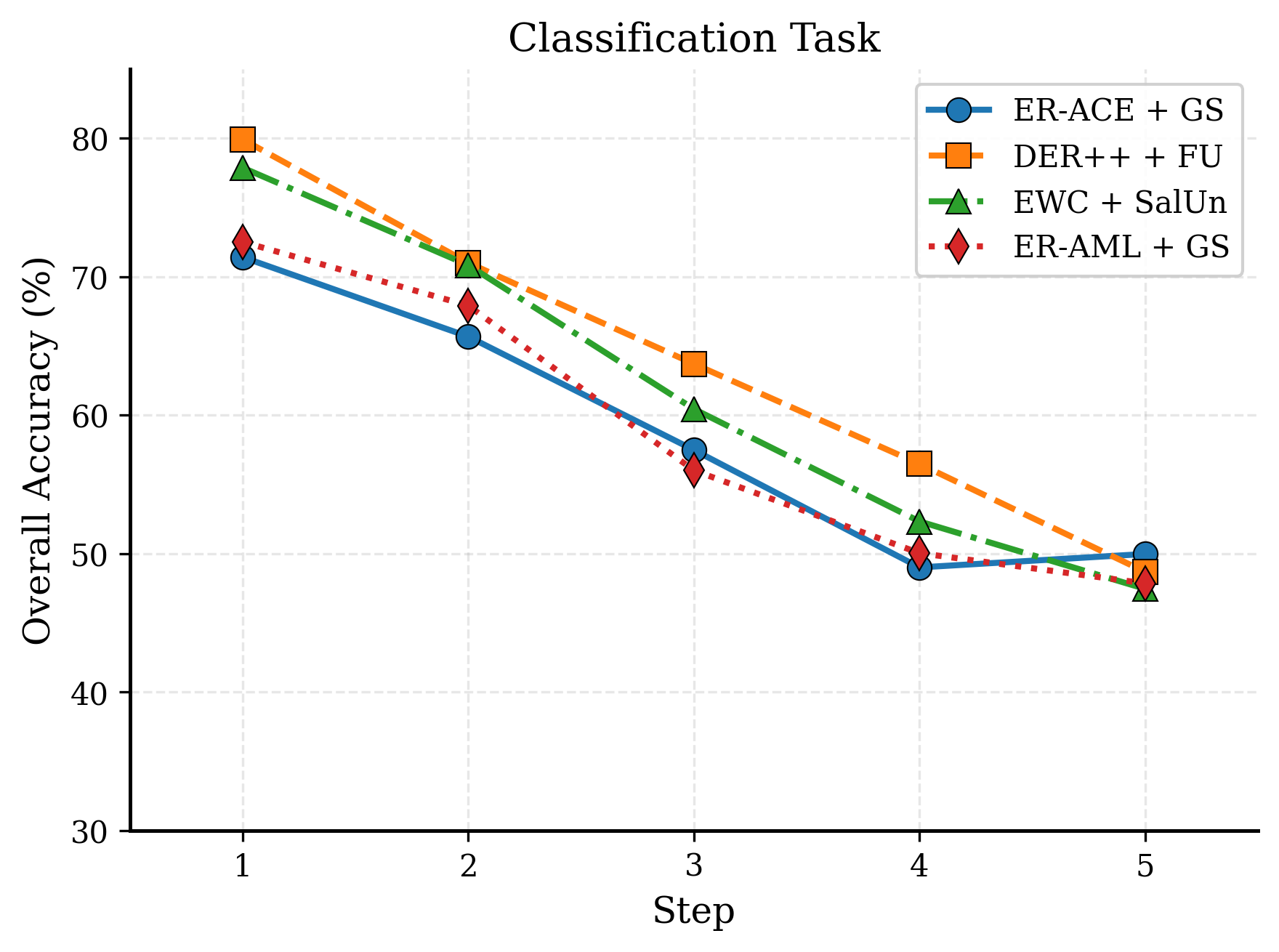
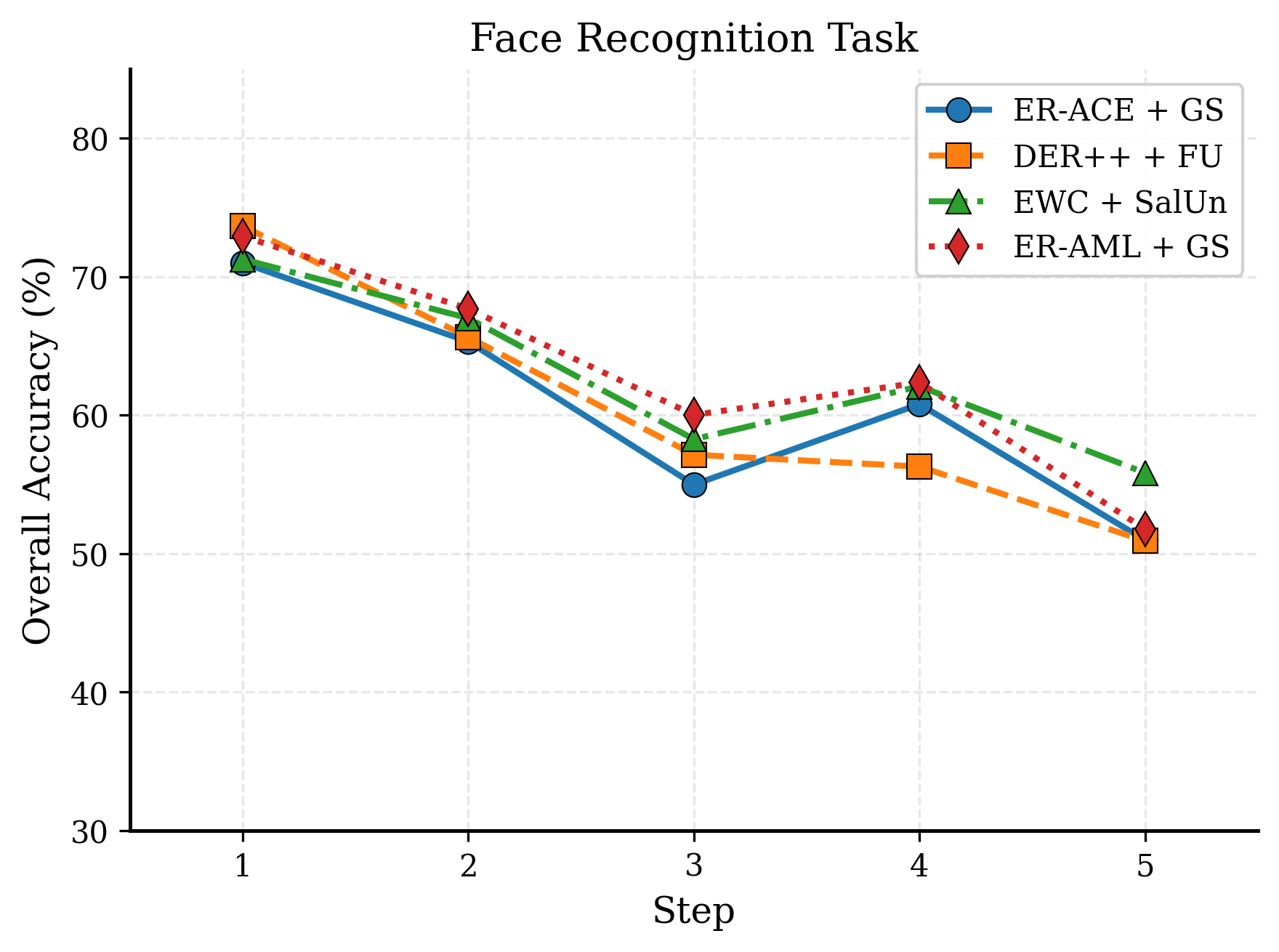
Figure 7: Knowledge leakage in CL+MU combinations. Retain accuracy degrades progressively across CLU cycles on both benchmarks.
Ablations and Theoretical Analysis
- Adapter Pathway Ablation: Disabling any pathway leads to corresponding drops (or failures) in retention, learning, or forgetting efficacy, confirming the necessity of the tri-pathway structure.
- Buffer Ratio: BID-LoRA remains robust to buffer reductions, but practical CLU remains unsolved without any access to a retain buffer for modern non-convex architectures.
- Escape Scaling and Projection: Proper scaling of the escape point is essential for stable and irreversible unlearning of forget classes; placement strictly outside the convex hull of retained class clusters yields best results.
- Parameter Efficiency: Increasing LoRA rank above 8 leads to only marginal improvements, confirming the 5% parametric footprint as optimal for most applications.
- Standard LoRA vs BID-LoRA: Standard LoRA (single adapter) consistently underperforms BID-LoRA, especially as the number of adaptation cycles increases.
Implications, Limitations, and Future Directions
BID-LoRA enables realistic, scalable, and privacy-compatible continual adaptation for transformer-based models. Its practical impact is significant for identity management systems, compliance-driven contexts, autonomous agents, and any system requiring both knowledge accretion and expungement. From a theoretical perspective, the study highlights the necessity of architectural modularity for objective isolation in sequential adaptation regimes.
Key limitations and future work:
- Complete elimination of retain buffers remains unsolved for non-convex models; generative and linear models without Dr rely on fundamentally different mechanisms.
- Extension to additional biometric, time-series, and NLP modalities is compelling for broadening the framework's applicability.
- Further research is warranted into non-data-driven (synthetic or regularizer-only) retention methods and unlearning verification protocols for black-box and federated systems.
Conclusion
BID-LoRA establishes a new state-of-the-art for Continual Learning-Unlearning by resolving the gradient interference and cumulative knowledge leakage challenges that stymie established CL/MU algorithms in extended settings. With strong, empirically validated performance across classification and face recognition domains, minimal parameter footprint, and built-in privacy guarantees, it provides a robust paradigm for dynamic AI in compliance-critical and evolving-data environments. The architectural and geometric design choices demonstrated herein set foundational precedents for future research at the intersection of continual learning and responsible machine unlearning.