- The paper presents a dual-control-plane architecture that integrates batch HPC and cloud-native services for pre-training, fine-tuning, and inference operations.
- It demonstrates effective resource management using Kubernetes–Slurm hybridization, achieving persistent uptime and measurable performance metrics for large models.
- The study highlights challenges in elasticity and governance, proposing dynamic node transitions and integrated MLOps for sovereign AI workflows.
Full-Lifecycle Foundation Model Operations on HPC: An Expert Analysis
This paper presents a comprehensive technical and architectural investigation into enabling the full lifecycle of Foundation Models (FMs)—spanning pre-training, fine-tuning, and inference—within a national HPC context. Focusing on developments at the Swiss National Supercomputing Centre (CSCS), the work critically addresses how capability-driven supercomputing architectures can be hybridized with cloud-native service paradigms to support "AI Factories" across scientific and industrial domains (2604.12599).
Motivations and Strategic Challenges
Traditional HPC infrastructures have excelled at pre-training large-scale FMs due to their batch-oriented, high-throughput architectures. However, downstream phases such as fine-tuning and inference display heterogeneous utilization patterns, introduce persistent interactive workloads, and often require managed service availability—conflicting with the rigid, batch-execution ethos prevalent in supercomputing environments. The push for "Sovereign AI" demands that national facilities provide end-to-end data and model sovereignty, moving beyond weight creation to encompass adaptation, safe alignment, and compliant deployment entirely on-premise.
The authors articulate the operational dilemma: whether national HPC centers should extend their mission to incorporate cloud-native, service-oriented models or risk ceding strategic control to commercial platforms. This is heightened by European "AI Factory" initiatives, which are mandating democratized, high-compliance access to both research and industry.
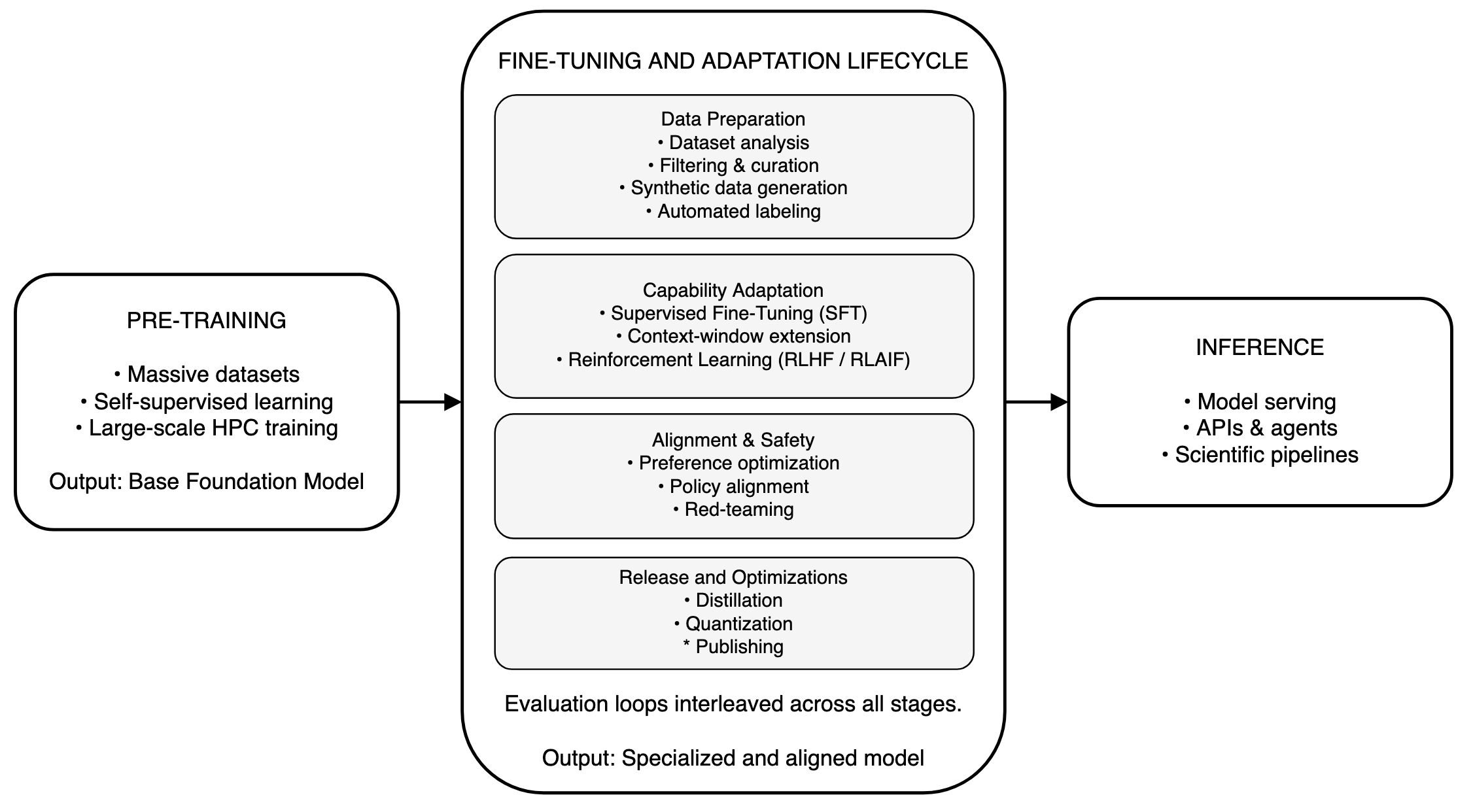
Figure 1: Lifecycle of foundation models in scientific environments. Large-scale pre-training produces a base model whose capabilities are subsequently specialized through an iterative post-training adaptation process—including datasets preparation, fine-tuning, alignment, safety validation, and release optimizations, before publishing and/or deployment for inference.
Hybrid Architectural Blueprint: "Alpernetes"
To operationalize the FM lifecycle, the proposed architecture is a dual-control-plane system (termed "Alpernetes"), where Slurm manages tightly coupled, batch-oriented workloads (pre-training/fine-tuning), and Kubernetes orchestrates long-running, interactive, or service workloads (inference, agentic services).
The compute substrate spans:
- Diskless HPE Cray EX Alps nodes (for high-end training/inference)
- Virtualized commodity nodes (SUSE Virtualization/VMware)
- Commodity bare-metal nodes (for direct device access)
- Integration with vCluster technology to create tenant-specific logical partitions
Combined with Rancher-managed Kubernetes and GitOps-based provisioning (ArgoCD, OpenTofu, Terragrunt), users receive namespace-isolated sandboxes with heterogeneous hardware exposure. These enable (a) "self-managed sandboxes" for arbitrary workflow deployment, (b) catalog-driven fine-tuning as a service, and (c) managed inference endpoints with full governance.
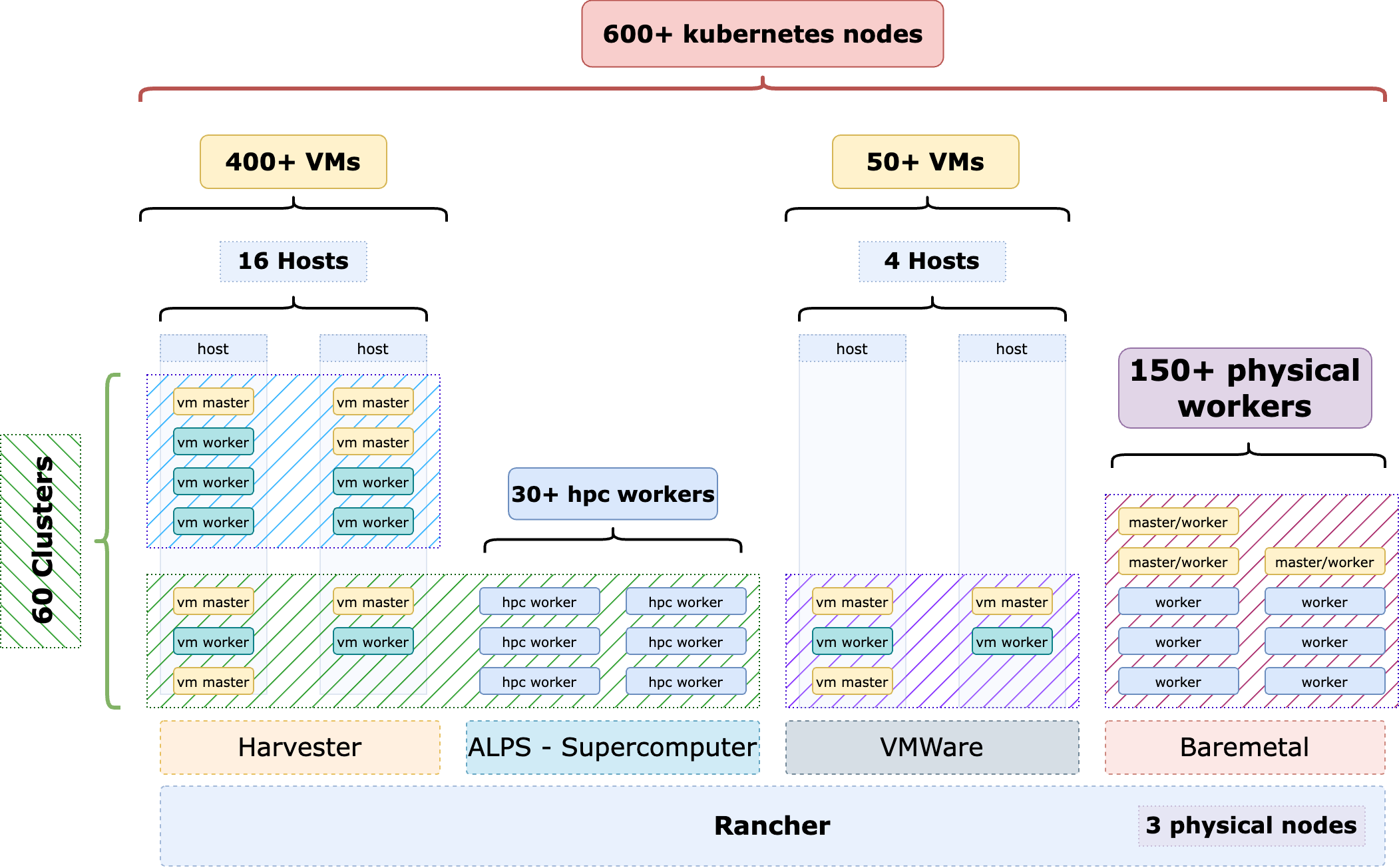
Figure 2: Kubernetes tenant distribution over host node types.
Enabling End-to-End AI Lifecycle: Practical Implementation
The "self-managed sandboxes" mechanism leverages IaC and GitOps to allow diverse user communities—including SMEs without deep HPC expertise—to deploy and manage arbitrary AI stacks with fine-grained access control, integrating project and identity management via Waldur and Dex.
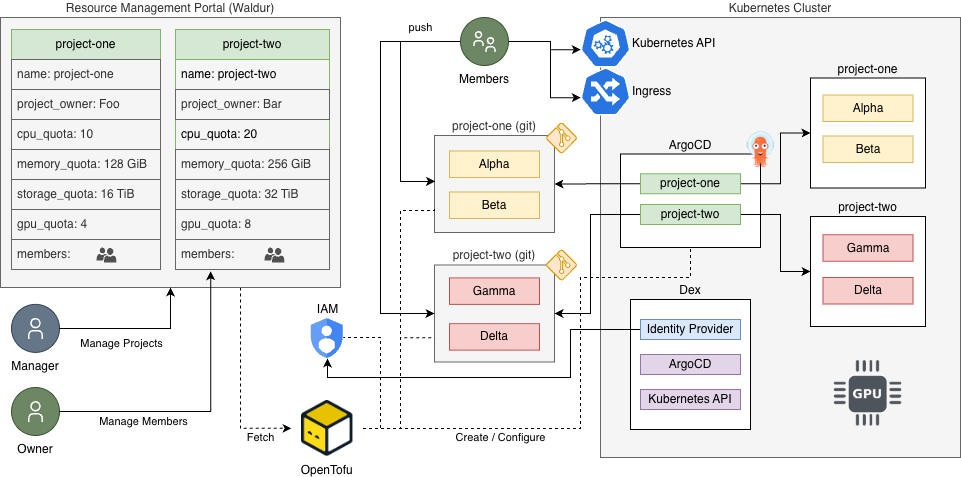
Figure 3: Sandbox provisioning and management leveraging IaC and GitOps methodologies.
Fine-tuning pipelines balance risk mitigation (e.g., catastrophic forgetting, capability collapse) via managed configuration blueprints (LoRA-based low-rank adaptation) and a bifurcated orchestration model: workflow control on Kubernetes, execution on Slurm. This enables high-quality, scalable adaptation while avoiding costly duplication of engineering when dealing with high-performance fabrics (NCCL/Slingshot). The inter-layer interface employs FirecREST as a RESTful abstraction over Slurm, facilitating automated job submission and tracking from Kubernetes origins.
Inference services are managed declaratively via GitOps, with vLLM backends on Alps nodes and LiteLLM providing unified inference APIs, usage governance, quota, and rate-limiting via Waldur.
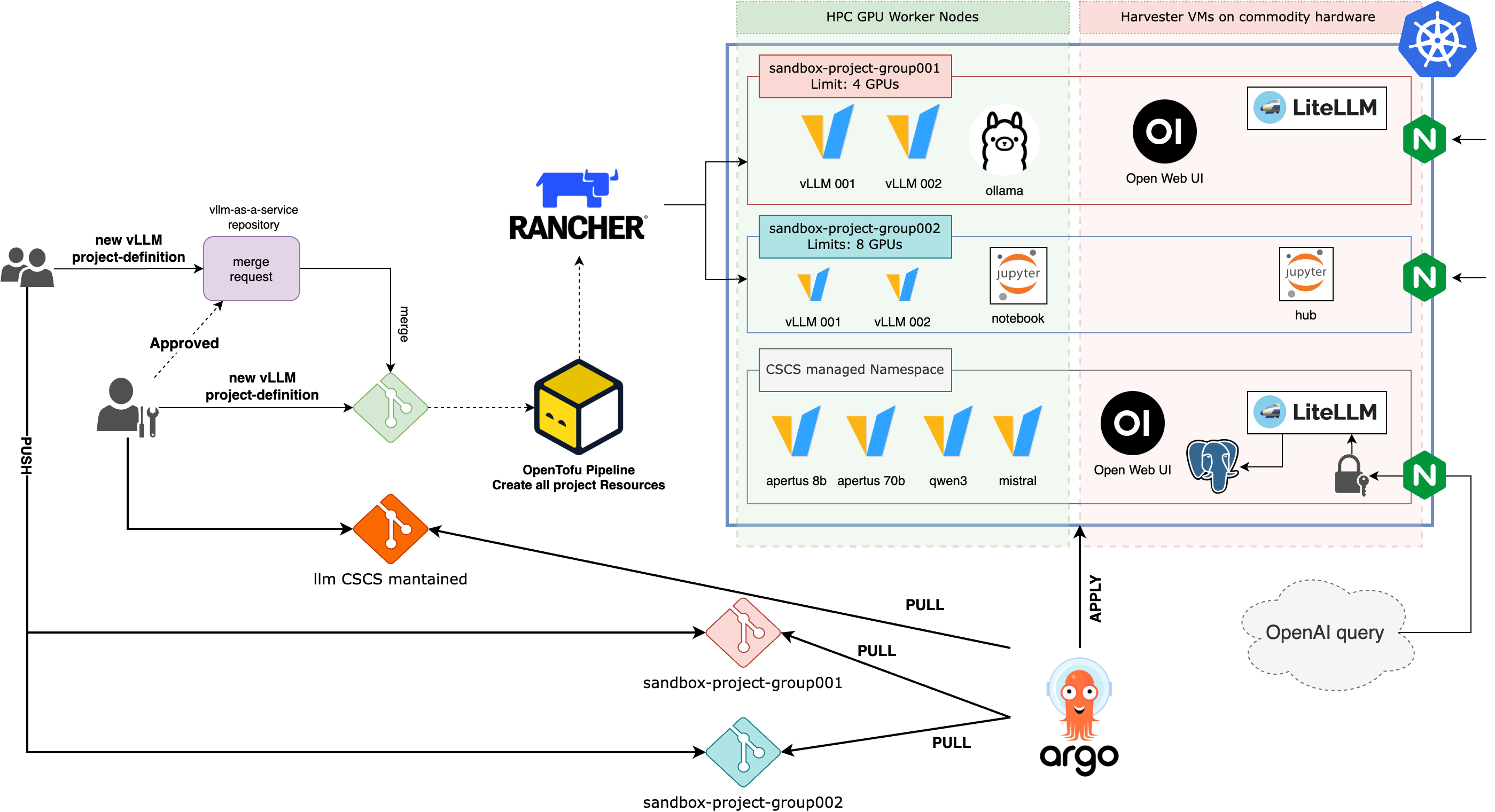
Figure 4: Alpernetes Cluster hosting inference service workloads.
Numerical Results and Observed System Behavior
Preliminary metrics for model serving on the CSCS platform are presented for both 70B and 8B Apertus models:
- Apertus-70B: Average inter-token latency (ITL) ~42ms; time-to-first-token (TTFT) typically <500ms, with occasional P99 spikes; end-to-end latency (E2EL) ~5.8s for standard workloads.
- Apertus-8B: ITL ~11ms; however, E2EL can exceed 30s due to long-form synthetic generation with output >3,000 tokens, stressing GPU memory and scaling limits.
Throughput over a two-day interval reached approximately 2.5M tokens (8B) and 1M tokens (70B), reflecting robust multi-user, production testbed conditions.
Critically, the system has exhibited continuous uptime since September 2025, with the hybrid model (VM-based control plane, HPC-based workers) enabling persistence through HPC maintenance events.
Empirical evaluation of Distributed Data Parallel (DDP) training (CIFAR-10 ResNet18) highlights that running over the management network (eth0) yields 3.2x slower performance compared to a single Slingshot HSN interface. Full parity with native Slurm (using CXI RDMA and GPUdirect) remains out of reach in Kubernetes, due to outstanding container network and communication stack tuning.
Similarly, initial multi-node serving with vLLM+KubeRay is bottlenecked by TCP communication overheads; unlocking Slingshot-native NCCL via libfabric plugins is an active area of optimization.
Elastic resource provisioning remains a challenge: the current model statically partitions nodes for inference clusters, which underutilizes hardware relative to dynamic workloads. Authors propose adding "delta" elasticity by dynamically migrating nodes between Slurm and Kubernetes, with baseline and burst scaling informed by real-time demand. However, engineering obstacles in node transition, storage/state consistency, and impact minimization are non-trivial and ongoing areas of research.
Governance, Data Management, and Trusted Environments
A critical issue is artifact and data governance. Iterative fine-tuning cycles generate petabyte-scale checkpoint and artifact proliferation, demanding integrated MLOps metadata layers for lifecycle and provenance management.
The architecture extends to privacy-critical contexts via "Trusted Computing Environments" (TCE): air-gapped Alpernetes clusters under exclusive external organizational control, with hardware, storage (encrypted, locally-keyed), and network isolation, supporting compliance-bound medical and clinical AI workflows. All platform layers must be reproducible and externally portable, enforcing full data and model sovereignty.
Implications and Future Directions
The presented hybrid platform is a blueprint for converging HPC and cloud-native paradigms. The key technical assertion—hybrid orchestration is not transitional but structurally required—challenges historical dichotomies separating batch HPC and service clouds. Notably:
- Fine-tuning and inference at scale on HPC hardware are technically feasible with Kubernetes-centric orchestration, though not yet at Slurm-optimized performance levels.
- Service-oriented workflows (agentic systems, persistent APIs, interactive adaptation) require persistent, user-autonomous platform layers inaccessible via the classical HPC batch paradigm.
- Elasticity and active-active HA remain open engineering frontiers for integrating bursty, unpredictable demand with statically optimized, cost-intensive hardware resources.
Theoretically, this work questions whether the distinction between capability and service operation can be algorithmically abstracted at the scheduler and orchestration layer—a key open research topic. Practically, it is anticipated that future systems will further unify storage, identity, model/version registry, and multi-site control planes, with advanced scaling, dynamic node transitions, and fine-grained usage metering. Integration with frameworks like KServe and advanced mesh service networking is underway and expected to mature.
Conclusion
This paper delivers an operational and architectural reference model for integrating the full FM lifecycle into national HPC centers. By bridging batch-oriented and service-oriented paradigms via Kubernetes–Slurm hybridization and tool-driven user autonomy, the proposed model demonstrates both the feasibility and necessity of this convergence for supporting scientific, industrial, and sovereign AI at scale (2604.12599). While challenges in performance parity, elasticity, storage/metadata governance, and compliance remain, the blueprint provides actionable direction for supercomputing centers globally.

