- The paper introduces a two-stage LLM framework that filters and refines XAI-generated explanations using an explainer and a verifier.
- It employs an iterative refeed mechanism based on meta-prompting that improves explanation accuracy up to 95%, reducing error rates significantly.
- Empirical results demonstrate enhanced linguistic accessibility and stable uncertainty metrics, making XAI outputs more reliable for practical applications.
Introduction and Motivation
The translation of technical outputs from eXplainable Artificial Intelligence (XAI) methods into natural-language explanations using LLMs has become increasingly prevalent for enabling interpretability to practitioners and end-users. Despite these advances, most contemporary pipelines directly render XAI artifacts into human-readable formats without systematic validation, exposing end-users to risks of incomplete, unfaithful, or hallucinated narratives. The absence of rigorous, iterative verification mechanisms is a critical gap. The paper "A Two-Stage LLM Framework for Accessible and Verified XAI Explanations" (2604.12543) proposes a structured, meta-verification paradigm featuring an explainer LLM, a verifier LLM instantiation, and a refeed mechanism, aiming to systematically filter and refine natural language explanations generated from XAI outputs, ultimately enhancing trustworthiness and linguistic accessibility.
The proposed architecture is a modular two-stage pipeline:
- Explainer Stage: An LLM receives structured XAI outputs (feature attributions, saliency maps, attribution scores, etc.) and employs Zero-Shot Chain-of-Thought (CoT) prompting to articulate coherent natural-language explanations contextualized for the end-user.
- Verifier Stage: A separate LLM is assigned to scrutinize the generated explanation according to meta-prompted criteria—evaluating faithfulness, internal coherence, completeness, and the risk of hallucination—furnishing both a classification verdict (accept/reject) and diagnostic justification.
- Refeed Mechanism: Upon rejection, targeted feedback from the verifier is used to iteratively revise the original explanation until it passes or a maximum refinement threshold is reached.
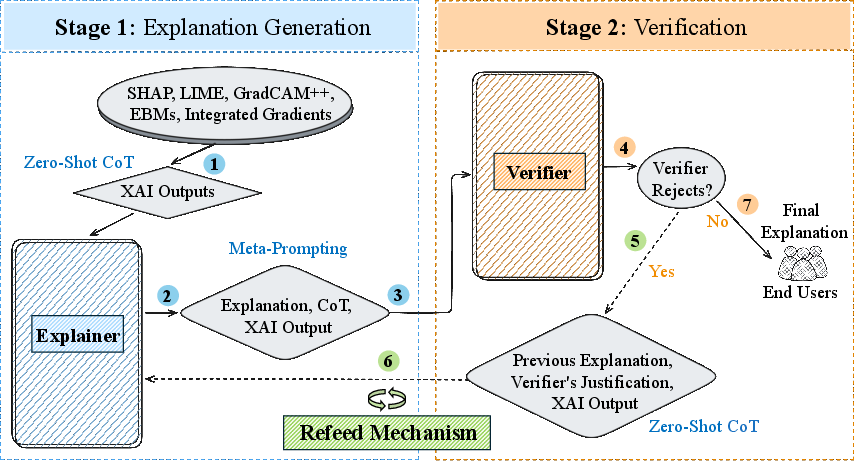
Figure 1: Two-stage framework: Stage 1 transforms XAI output to explanation; Stage 2 verifies and, if needed, refines via refeed.
Prompt design is central to this process. The explainer employs prompt templates tailored by XAI technique, combining task definition, context, model/data description, and explicit task requests. Verifier prompts leverage meta-prompting, formalizing multi-criteria evaluation and structured judgment. The refeed prompt dynamically integrates verifier feedback to enable targeted correction while retaining Zero-Shot CoT structure.

Figure 2: Structured prompt templates for explainer, verifier, and refeed correction cycles.
Experimental Design
The framework's empirical evaluation encompasses five XAI use cases spanning tabular, vision, and text modalities:
All explanation artifacts are canonicalized into textual form for input to the explainer-verifier pipeline.

Figure 3: Representative explanations generated across the five XAI/dataset modalities.
Three prominent open-weight LLM families are deployed: GPT-OSS, DeepSeek-R1, and Qwen-3, in parameter ranges suitable for efficient, on-prem deployments. Both natural error spaces (organic, unprompted failures) and synthetic error spaces (systematic, controlled perturbations) are constructed to evaluate robustness, using rigorous manual annotation for explanation correctness.
Empirical Results
Explanation Reliability and Verification Efficacy
Explainer-only accuracy ranges from 59% to 77.8%, clearly illustrating the inadequacy of unverified XAI narratives (error rates of 22–41%). When the verification stage is enforced, the accuracy across explainer-verifier pairs increases dramatically, peaking at 95.21% with the gpt-oss:20b explainer paired with qwen3:30b verifier. This equates to filtering out 78.5% of flawed explanations that would otherwise reach the user. As verifiers, Qwen-3 models display the highest discrimination, whereas DeepSeek-R1 suffers from excessive acceptance of poor explanations.
Iterative Correction via Refeed
The refeed mechanism achieves rapid convergence: most explanations are accepted within $1$–$2$ iterations, demonstrating the mechanism's practical efficiency.
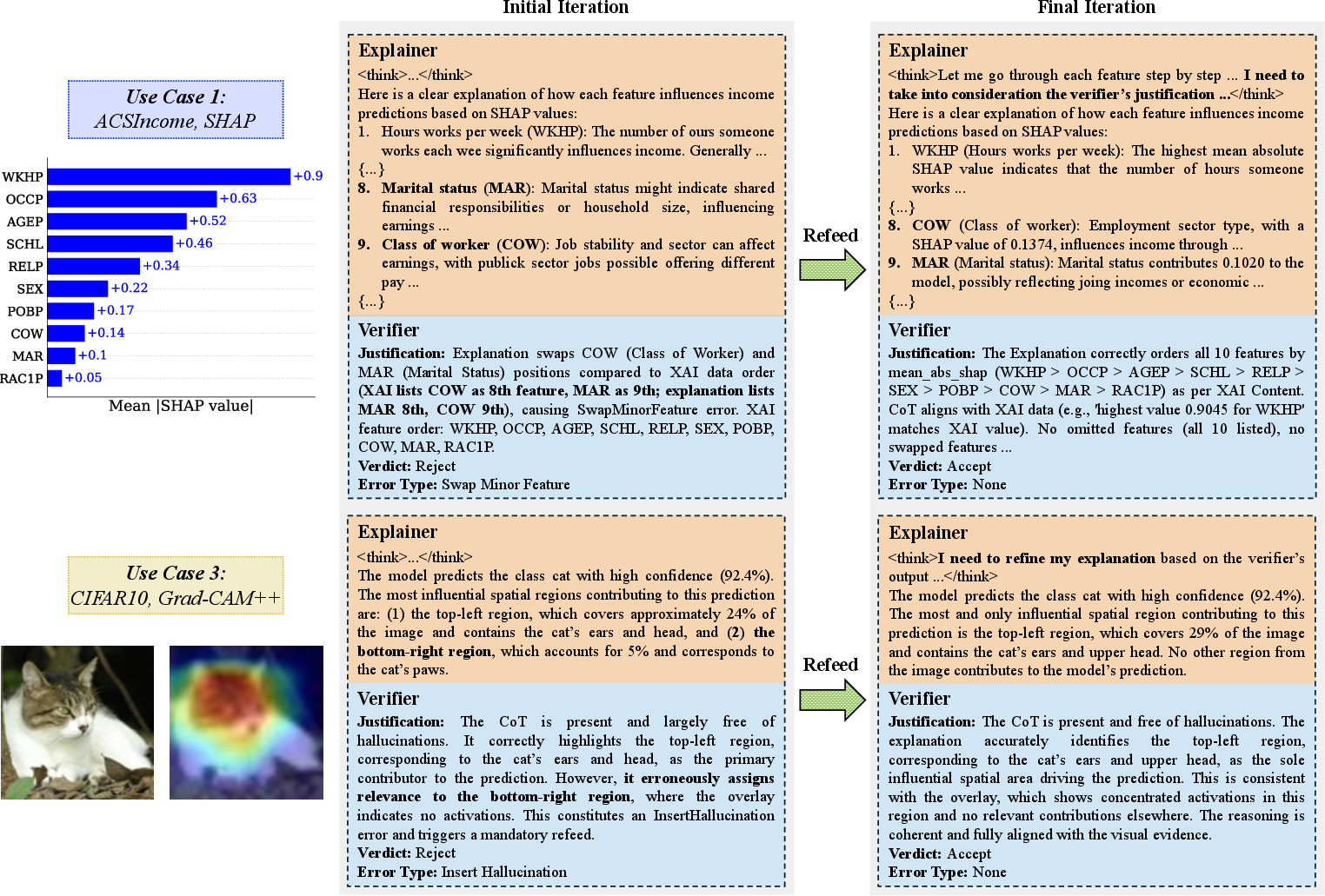
Figure 4: Framework correcting errors after verifier-guided iterative refinement.

Figure 5: Iterations to acceptance across explainer-verifier pairs; gpt-oss:20b→qwen3:30b resolves ∼75% in ≤2 cycles.
Quantitatively, convergence occurs in 96.92% of tested cases, with a moderate practical overhead (typically $5$–$7$ LLM calls, or ∼3 minutes per explanation under the test regime).
Linguistic Accessibility
Compared to raw XAI output (mean Flesch Reading Ease 18.53, Grade Level 21.79), explainer output—especially from gpt-oss:20b—substantially improves readability (Reading Ease up to 34.93, Grade Level down to 12.94), lowering the accessibility barrier and supporting end-user comprehension.
Uncertainty and Stability Analysis
The Entropy Production Rate (EPR) of LLM outputs is used to analyze uncertainty dynamics:
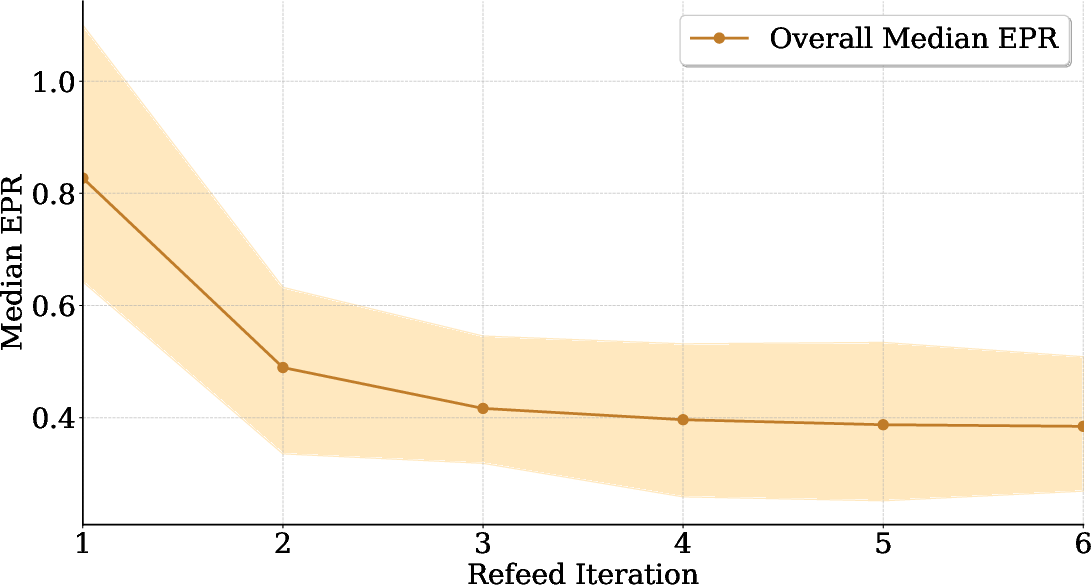
Figure 6: Explainer EPR declines monotonically over refinement; verifier feedback stabilizes reasoning.
EPR decreases across refeed iterations, indicating that verifier feedback regularizes the explainer’s output distribution toward more stable and coherent explanations. Verifier EPR distributions reveal Qwen-3’s high reliability and decisiveness, with tighter, lower-mean EPR compared to other models.
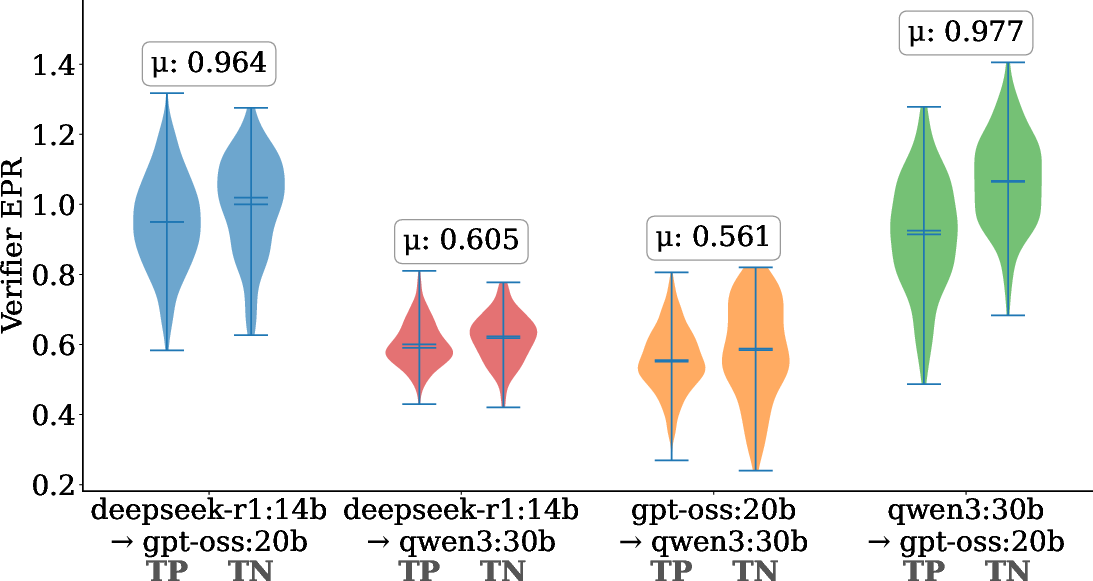
Figure 7: Verifier EPR is lower and more stable for qwen3:30b, reflecting higher verification consistency.
EPR measured on initial explanations provides weak early-warning signals (maximum AUC 0.66) for predicting explanations likely to require correction, suggesting limited yet potentially actionable uncertainty-aware triage.
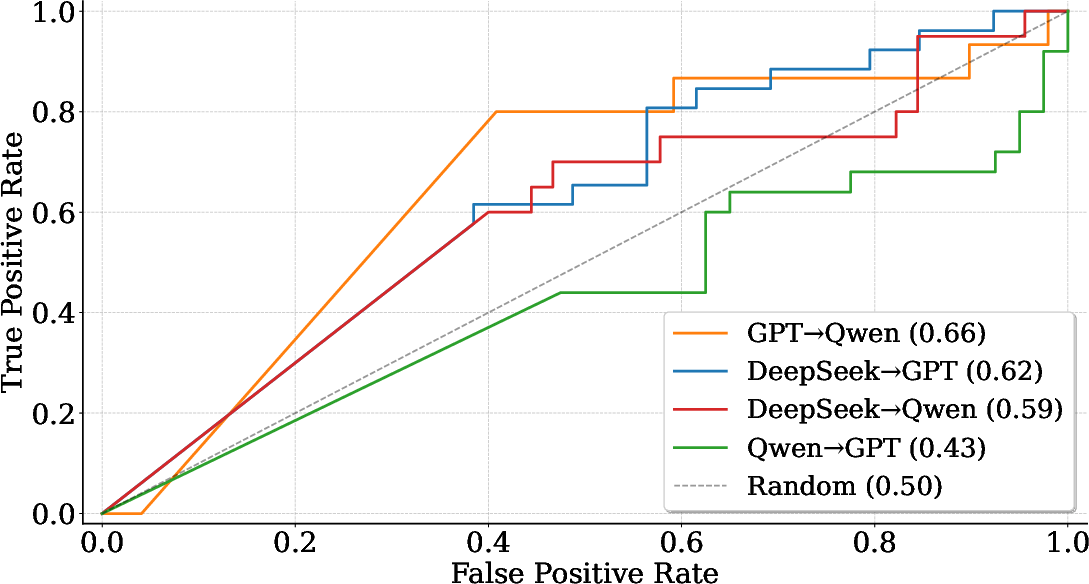
Figure 8: ROC curves for EPR-based prediction of the need for explanation refinement.
Prompt ablation studies illustrate that meta-prompting (complete high-level reasoning instructions) is critical: without it, verification accuracy drops (from perfect to as low as 23.3% depending on the verifier), demonstrating that explicit structured prompting is necessary for robust XAI explanation assessment, particularly for less capable models.
Theoretical and Practical Implications
The results empirically substantiate the necessity of independent, specialized verifier LLMs in XAI pipelines: absent verification, explanations remain error-prone and untrustworthy. Structured meta-prompting enables method-agnostic assessment, supporting seamless extension across XAI domains. The refeed mechanism’s iterative, targeted feedback loop is crucial for error correction without excessive computational cost.
By quantifying uncertainty dynamics and verifying explanation faithfulness, coherence, and hallucination absence, this framework operationalizes trustworthy XAI narratives—directly benefitting both technical and general audiences. However, verification reliability remains partially model-dependent and prompt-sensitive, motivating continued evaluation as LLM architectures and prompting strategies mature.
Practically, these insights inform robust XAI deployment in regulated or high-stakes environments (e.g., healthcare, finance), where explanation integrity directly affects safety and compliance. Theoretically, the demonstrated effectiveness of the meta-verification paradigm motivates further study of multi-agent LLM systems, formal error taxonomies, and dynamic prompting, advancing toward self-policing, self-correcting AI interpretability frameworks.
Future work includes extending to multimodal explanation formats (enabling direct verification of visual/counterfactual outputs), scaling to larger LLMs and domain-specialized models, refining dynamic uncertainty-based refinement scheduling, and performing in-depth human-centered user studies to evaluate perceived trust and utility.
Conclusion
The Two-Stage LLM Meta-Verification Framework advances the frontier of XAI explanation reliability and accessibility. Results demonstrate that an independent Verifier, enabled by structured meta-prompting and iterative refeed, is essential for trustworthy XAI narrative delivery—yielding strong improvements in both accuracy and clarity while regularizing output uncertainty. The findings motivate further LLM-based meta-verification research for practical, robust, and transparent AI systems.

