- The paper introduces UniMark, a unified adaptive multi-bit watermarking framework that operates training-free across autoregressive image generators.
- It employs adaptive semantic grouping and block-wise multi-bit encoding with BCH error correction to ensure near-perfect watermark extraction even under adversarial attacks.
- Experimental results demonstrate minimal perceptual changes, scalability across models, and robust resistance to common image distortions, advancing secure digital content attribution.
UniMark: A Unified, Adaptive Multi-bit Watermarking Framework for Autoregressive Image Generators
Introduction
The paper "UniMark: Unified Adaptive Multi-bit Watermarking for Autoregressive Image Generators" (2604.11843) addresses critical gaps in the landscape of invisible image watermarking for autoregressive (AR) generative models. While previous AR watermarking methods are limited to zero-bit schemes, prone to static partition vulnerabilities, and unable to generalize beyond specific AR architectures, UniMark is proposed as a comprehensive, training-free solution supporting robust, model-agnostic, and multi-bit content attribution. This summary explores the methodological innovations, theoretical guarantees, and empirical findings, culminating in a discussion of research implications and future directions.
Methodology
UniMark is architected around three primary innovations: Adaptive Semantic Grouping (ASG), Block-wise Multi-bit Encoding (BME), and a Unified Token-Replacement Interface (UTRI). These mechanisms coalesce into a cohesive pipeline that embeds robust, extractable, and high-capacity watermarks without access to AR model internals or retraining.
Adaptive Semantic Grouping (ASG)
ASG performs a dynamic, cryptographically-keyed partitioning of the codebook at every token position. For a given key κ and token index i, ASG generates pseudorandom green (G) and red (R) groups by permuting the codebook indices using a hash of κ∥i. In contrast to static approaches, this position- and key-dependent assignment ensures that each token replacement decision is both secure and independent (Figure 1).
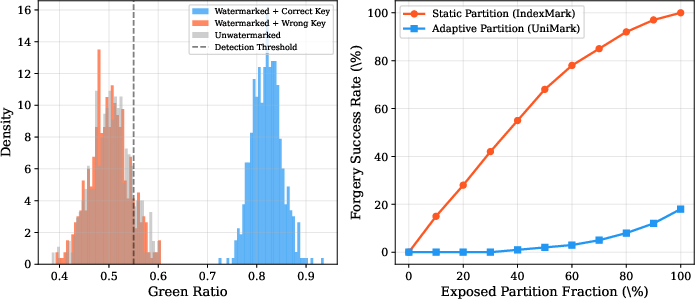
Figure 1: Security analysis: (a) green ratio distributions under correct/wrong keys; (b) forgery success rate vs. partition exposure fraction.
The semantic proximity between codebook entries, measured by the cosine similarity of their learned embeddings, ensures that token replacement occurs with visually indiscernible alterations, thus preserving output fidelity.
Block-wise Multi-bit Encoding (BME)
BME divides the generated token sequence into equal-sized blocks, with each block tasked to encode a respective bit (or set of bits) of a BCH-coded message. The embedding operation is bit-dependent: green group biasing encodes $1$, and red group biasing encodes $0$. BCH error-correcting codes are leveraged to mitigate message degradation under post-generation distortions.
During extraction, blocks are decoded via green ratio thresholding and BCH decoding, providing reliable recovery even under heavy perturbation and partial block loss (e.g., image cropping).
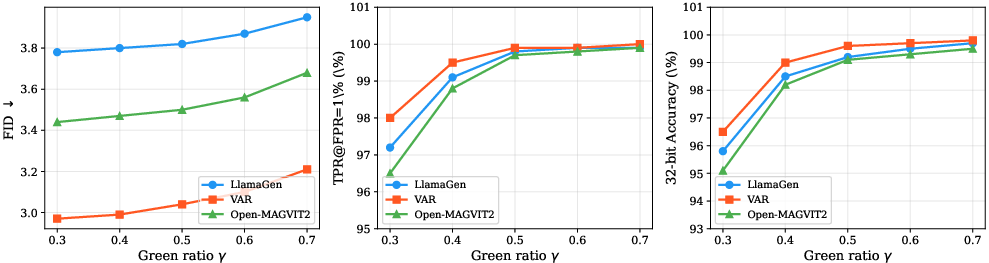
Figure 2: Parameter sensitivity analysis: effect of green ratio gamma on (a) FID, (b) TPR@FPR=1\%, and (c) 32-bit extraction accuracy.
Unified Token-Replacement Interface (UTRI)
UTRI abstracts the AR model interaction, supporting both next-token and next-scale generation paradigms (e.g., LlamaGen, VAR). This enables UniMark to operate in a model-agnostic fashion with only access to the codebook, tokenizer, and generated sequences, fundamentally advancing deployment versatility.
Theoretical Analysis
The paper establishes precise bounds on false positive rates (FPR) and embedding capacity. With the pseudorandom ASG partition and the normal approximation of the green token ratio in unwatermarked content, the FPR can be explicitly controlled by the significance parameter α.
Capacity analysis links the maximum reliably encodable message length to the token count, BCH code rate, and block size, delineating performance-enabling design trade-offs. This allows practitioners to tailor UniMark’s signal strength and robustness for diverse operating conditions.
Experimental Results
Employing LlamaGen, VAR, and Open-MAGVIT2 as testbeds, UniMark demonstrates:
- FID increases of ≤0.1 over unwatermarked baselines, outperforming competitors in almost all perceptual fidelity metrics.
- Near-perfect watermark TPR@FPR=1% and ≥99% multi-bit extraction accuracy for 32-bit messages across all models.
- Pronounced resilience to adversarial attacks (JPEG, noise, blur, crop, color jitter, random erasing), with only a marginal drop in detection or extraction post-cropping (Table: robustness on LlamaGen).
- Security analysis empirically validates that ASG blocks forgery attacks targeting static partitions: the forgery success rate remains negligible even when an adversary is privy to half the partition set.
- Capacity analysis reveals scalability with longer token sequences and larger codebooks, supporting higher bitrates at low error.
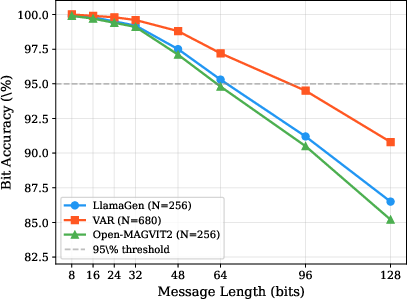
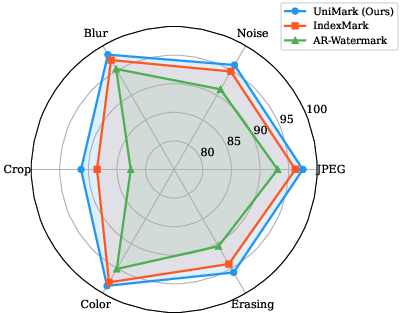
Figure 3: Embedding capacity analysis: bit accuracy vs. message length across three AR models.
Robustness against increasing attack strength (compression ratio, noise variance, crop area) and computational efficiency benchmarks show UniMark’s viability for deployment in latency-critical applications.
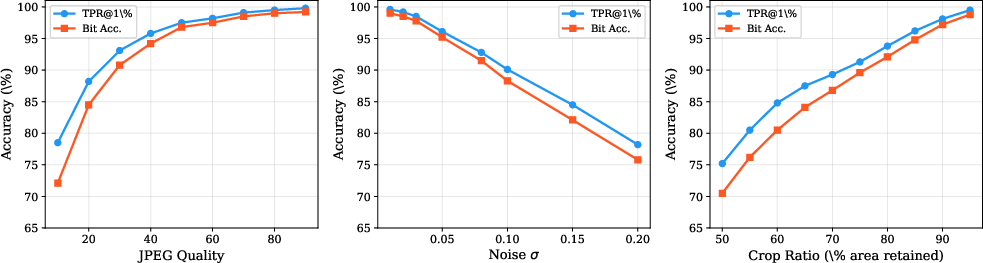
Figure 4: Attack strength analysis: (a) JPEG quality, (b) Gaussian noise sigma, (c) crop ratio vs. detection and extraction performance.
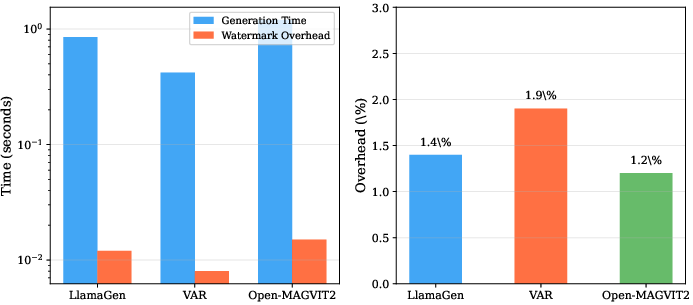
Figure 5: Efficiency analysis: (a) absolute time comparison (log scale); (b) relative overhead percentage.
Practical and Theoretical Implications
UniMark’s combination of security, robustness, and model-agnosticism addresses real-world needs for ownership tracing and content provenance, especially as AR models proliferate in production environments where retraining is infeasible. Its support for multi-bit watermarks enables granular, user- or instance-specific attribution—crucial for scalable copyright management.
The demonstrated security against partition exposure and ability to function seamlessly across AR model architectures paves the way toward unified content tracing standards. The proposed capacity analysis offers a theoretically grounded framework for optimizing detection reliability as watermark bit-rate scales.
Limitations and Future Work
While highly competitive, UniMark’s embedding rate is fundamentally upper-bounded by sequence length and codebook diversity, with diminishing returns as capacity grows. Future directions include adaptive capacity allocation, video AR extension, and adversarial regeneration resistance. Exploration of integration with post-generation or model-weight watermarking schemes could yield even stronger attribution guarantees.
Conclusion
UniMark establishes a new benchmark for invisible watermarking in autoregressive image generation. By unifying adaptive, cryptographically-secure partitioning, block-wise multi-bit embedding, and architectural generalization, it achieves state-of-the-art results in watermark fidelity, capacity, and robustness. This work constitutes a substantial advancement toward scalable, practical, and secure content attribution for synthetic visual media.