- The paper shows that structural alignment bias dramatically increases erroneous tool invocations, reaching up to a 90.4% tool invocation rate in structurally aligned settings.
- The study introduces SABEval and Contrastive Attention Attribution to disentangle semantic verification from surface-level structural matching in LLMs.
- The authors propose an attention scaling intervention that reduces tool invocation rates by 45.55% while maintaining overall tool-use performance.
Introduction
The capacity for tool augmentation has become central in the development and deployment of LLMs for real-world applications. An urgent yet under-examined challenge is ensuring LLMs recognize when external tools are semantically irrelevant to user queries and appropriately withhold invocation. The paper "Do LLMs Know Tool Irrelevance? Demystifying Structural Alignment Bias in Tool Invocations" (2604.11322) systematically dissects the tendency of modern LLMs to erroneously invoke tools based on structural, not semantic, correspondences—a phenomenon termed structural alignment bias.

Figure 1: Illustration of erroneous tool invocation driven by the model's strong reliance on structural alignment.
This essay provides a technical synthesis of the key findings, experimental methodology, mechanistic attribution analysis, and implications for future LLM development.
The study formalizes semantic irrelevance as the lack of alignment between a tool's capability and the user's intent, i.e., the tool cannot help realize the user's goal. In contrast, structural alignment refers to the ability to establish a bijective mapping between attributes in the user query and parameters of the candidate tool, regardless of semantic fit.
Existing evaluations typically pair queries and tools at random, conflating semantic irrelevance with structural misalignment. The authors instead introduce SABEval, a dataset that fully decouples these factors: each sample pairs a query with a tool possessing a structurally isomorphic but semantically irrelevant interface.
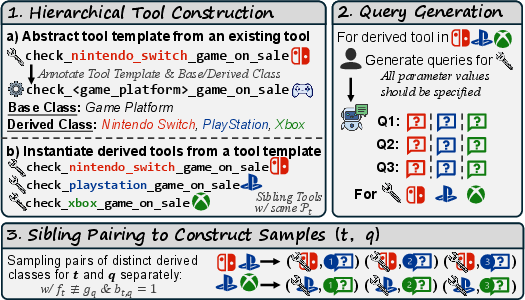
Figure 2: SABEval construction with three steps. Samples are semantically irrelevant but structurally aligned.
Comprehensive analysis across Qwen3 (4B/8B/14B), ToolACE-2.5-8B, and Watt-Tool-8B demonstrates a dramatic escalation in tool invocation rate (TIR) when structural alignment is present. For instance, TIR is negligible (<0.2%) under random pairings but rises to 41.9% when tools are structurally aligned. As the degree of alignment increases (i.e., more attributes of the query can be mapped to the tool parameters), erroneous invocation rates reach up to 90.4%.
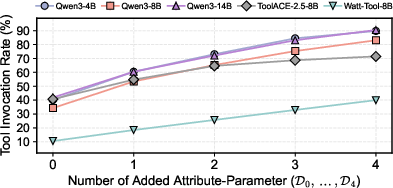
Figure 3: Tool invocation rate (\%) on SABEval subsets D0,…,D4 with increasing structural alignment degree.
Intervention experiments using structural counterfactuals—where a single tool parameter is substituted, added, or removed—result in large TIR reductions, with the largest effect seen for parameter substitution interventions (relative declines up to 83%). This causally implicates structural alignment as a decisive trigger for tool invocation, not semantic congruence.
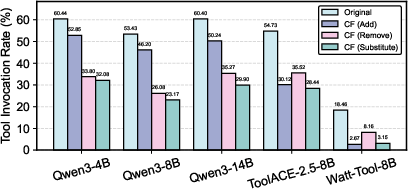
Figure 4: Tool invocation rate (\%) on original samples and their structural counterfactuals from D1.
Mechanistic Attribution: Competing Pathways in LLMs
To probe the internal mechanisms, the paper introduces Contrastive Attention Attribution (CAA)—a test-time method that identifies attention head pathways linked to semantic checking and structural matching, using zero-ablation and group-wise span aggregation on attention scores.
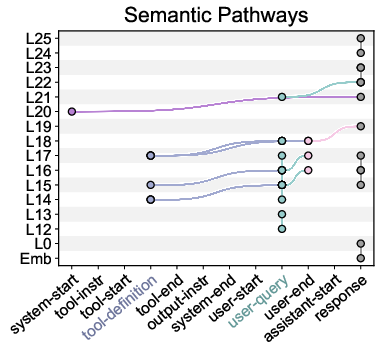
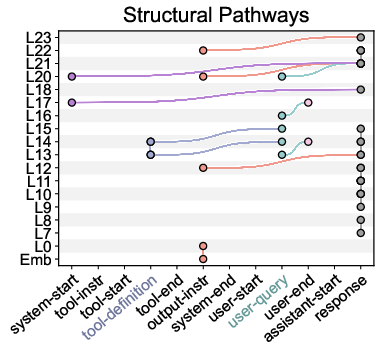
Figure 5: Semantic (left) and structural (right) pathways in Qwen3-8B from top-k attention weights (k=23, corresponding to 2\% of the attention heads).
Through CAA, two competing pathways are consistently identified:
- Semantic pathways: Channel information for semantic verification, reinforcing the model's ability to refuse tool use when inappropriate.
- Structural pathways: Channel information aligning query attributes to tool parameters, disproportionately driving tool invocation as alignment increases.
The relative dominance of structural over semantic pathways correlates with erroneous invocations. Patch-ablation experiments further demonstrate that modulating the strength of these pathways directly changes TIR in the expected direction.
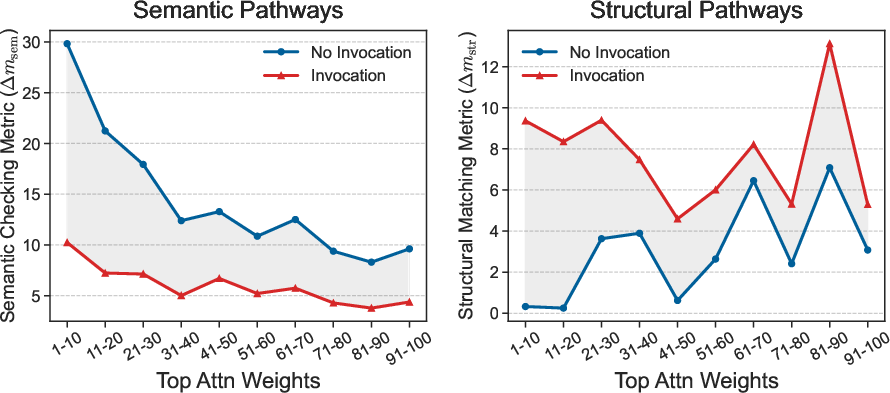
Figure 6: Comparison of pathway strengths between invocation and non-invocation cases for Qwen3-8B.
Mitigation: Pathway Rebalancing and Generalization
Leveraging mechanistic insights, the authors propose a targeted attention scaling intervention: amplifying semantic pathway attention values while suppressing those in structural pathways. This intervention yields a 45.55% average TIR reduction across models, with only marginal changes on standard tool-use benchmarks (ACEBench). Prompt-based baselines yield inferior reductions (11.19% average). The efficacy of pathway intervention generalizes across tools and templates, as evidenced by robust performance on disjoint splits.
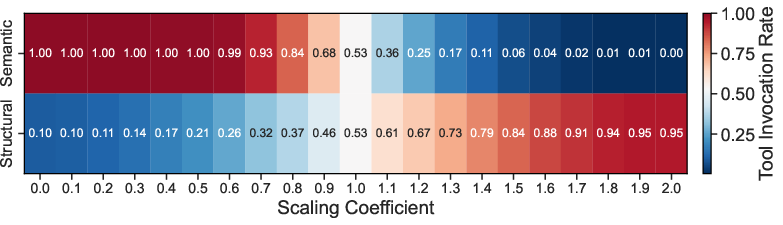
Figure 7: TIR under different scaling coefficients for Qwen3-8B (k=23).
Discussion and Implications
This work exposes a fundamental mechanistic flaw in state-of-the-art tool-augmented LLMs: a systematic, causally validated bias towards structural alignment in tool invocation that is invisible to standard benchmarks employing random query-tool pairs. Existing approaches—prompt engineering, data augmentation, and even model size scaling—provide limited or inconsistent mitigation. The introduced CAA framework is not just a method for bias reduction but also a probe for causal structure in model computation.
The main theoretical implication is that transformer-based LLMs realize tool selection via competitive attention-based subsystems for semantic verification versus surface-level slot filling. The relative activation strength of these pathways, which can be modulated without retraining, governs output behavior. Such an architecture produces impressive syntactic robustness yet renders models brittle to interface-based template matching errors.
Practical implications are sobering: unless explicitly mitigated, LLMs may introduce severe safety risks in environments where unvetted tool invocation can cause financial loss, data corruption, or security breaches. The CAA-based pathway reweighting offers an interpretable, plug-in intervention for deployed models without any parameter updates.
Future Directions
Key open problems include:
- Generalization across multi-turn, agentic, or real-time tool affordance settings, where compositional phenomena may amplify or interact with structural bias.
- Transferability of discovered pathways: Investigating whether these mechanistic insights extend to novel model architectures, tool schemas, or cross-lingual settings.
- Pinpointing the training-phase origin of the bias: Whether pretraining or tool fine-tuning introduces/strengthens the over-reliance on structural alignment remains to be dissected.
Mechanistically targeted supervised fine-tuning, e.g., updating only parameters within causal pathways, constitutes a promising approach for future work. Integration of CAA insights with more granular forms of interpretability (e.g., circuit-based or activation-level analysis) can yield still finer control over LLM tool-use behavior.
Conclusion
The paper presents rigorous empirical and mechanistic evidence for structural alignment bias in tool-augmented LLMs (2604.11322). This bias causes models to invoke semantically irrelevant tools when queries are structurally compatible. A novel dataset, behavioral analysis, and mechanistic attribution cohere to paint a comprehensive picture of the error and its root cause. Mechanistically grounded interventions can mitigate the bias with negligible trade-off in general tool-use performance, a finding with broad applicability as LLMs are increasingly entrusted with external actions.