- The paper introduces S³, a novel algebraic framework that unifies diverse structured pruning patterns for neural networks.
- It defines compositional elements—View, Block, and Scope—to rigorously specify sparsity and map patterns efficiently to hardware.
- Empirical results show S³-OBS reduces layerwise reconstruction error by up to 20% and lowers perplexity degradation by 17.9% compared to SparseGPT.
Structured Sparsity Specification: A Unified Algebraic Framework for Network Pruning
Motivation and Context
Model compression remains central to scaling neural networks efficiently, with quantization dominating for inference cost reductions. However, sparsity—especially structured sparsity—offers orthogonal compression gains, critically important for large-scale deployment and efficient inference on modern hardware. Unstructured sparsity, while yielding high theoretical reductions, is often incompatible with device memory and execution patterns. Conversely, structured sparsity is device-friendly but historically lacked a unifying, expressive formalism, forcing practitioners to rely on ad hoc implementations for each pruning structure (e.g., N:M, block, channel, or head pruning). The "Structured Sparsity Specification" (S3) (2604.11315) directly addresses this gap by providing an algebraic, compositional framework that abstracts and unifies diverse sparsity patterns, enabling the principled specification, combination, and implementation of structured pruning schemes.
Layout Algebraic Foundation
S3 is grounded in the concept of tensor layout algebra, formalizing the mapping between logical tensor coordinates and physical memory indices. The key formal elements are:
- View: A (possibly composed) layout mapping that reinterprets the tensor’s shape and stride, thus allowing the definition of structured sparsity operations on arbitrary subdomains or higher-dimensional reshaped representations.
- Block: The atomic unit of pruning, defined over the viewed tensor—this determines the parameter group that is pruned jointly (e.g., scalar, column, multi-dimensional blocks).
- Scope: Governs the grouping across which sparsity constraints are enforced (for instance, enforcing N:M structure per group or deciding channel or head pruning).

Figure 1: Representation of NVIDIA Ampere tensor core data partitioning, motivating block- and thread-group-aligned sparsity.
This compositional View–Block–Scope decomposition clarifies the space of structured sparsity from fine-grained to hardware-aware coarse-grained patterns.
Coupling
S3 includes a Coupling mechanism, which enables coordinated pruning across multiple tensors. This is essential for ensuring network invariants (e.g., channel pruning across input and output tensors, joint head pruning in attention blocks) by aligning the block grid dimensions via permutations before concatenation and mask application.







Figure 2: Visualization of representative sparsity structures captured via S3—from N:M and 4:8 to hardware-coupled group sparsity.
Expressiveness and Universality
The layout algebraic specification underpinning S3 allows the expression of any axis-aligned hyperrectangular sparsity mask—subsuming all patterns required in practice, including but not limited to:
- Classic unstructured pruning.
- N:M structured sparsity (hardware-aligned).
- Block and group-wise sparsity.
- Whole-channel or whole-head pruning (for CNNs and transformers).
- Arbitrary partial-domain or region-based sparsity (e.g., per-block, per-layer, custom hardware-aligned blockings).
This universality is exact for all axis-aligned, regular patterns due to the compositional nature of layout transforms and block/scoping semantics. Furthermore, S3 discretizes achievable sparsity ratios by scope size, making budget allocation exact and principled.
Pruning Algorithm Integration: S-OBS and S-OBD
S3 provides the structural specification, but practical pruning must be realized by integrating with heuristics or optimality criteria. The authors derive structured extensions of two classic second-order pruning paradigms:
- Optimal Brain Damage (OBD): Saliency of a block is computed by summing diagonal (Hessian) importance scores for its weights.
- Optimal Brain Surgeon (OBS): Employs the (block-wise or per-row) full inverse Hessian for both saliency computation and compensatory updates to remaining weights, supporting block-structured or coupled pruning.
The block-view naturally lifts gradients and Hessian computations to group-wise settings. Efficient blockwise Schur complement updates make multi-step (interactive) structured OBS tractable even for post-hoc pruning of large LLM layers—though with higher overhead than purely column-wise approaches.
Empirical Results
Empirical validation is performed on post-training pruning of Qwen3 family LLMs under multiple S3-expressed patterns: 2:4 sparsity, 4:8 sparsity, group-coupled 2:4, and 16-column block sparsity. Highlights:
- Across all tested sparsity configurations and at 50% sparsity, the S3-structured OBS implementation (S-OBS) yields a 16–20% reduction in layerwise reconstruction error versus SparseGPT.
- End-to-end perplexity degradation is reduced by 17.9% on Qwen3-1.7B using S-OBS for 2:4 pruning, with the advantage growing monotonically as more layers are pruned.
- The reduction arises from optimal weight compensation—not mask selection alone. When SparseGPT is allowed to use optimal subset enumeration for mask selection, but without optimal compensation, performance does not improve.
- Per-layer output error and per-projection (linear/attention) analysis show S-OBS dominates in 91% of layers, although for small models (Qwen3-0.6B) late-layer error accumulation, due to Hessian rank deficiency, can eliminate the perplexity advantage.
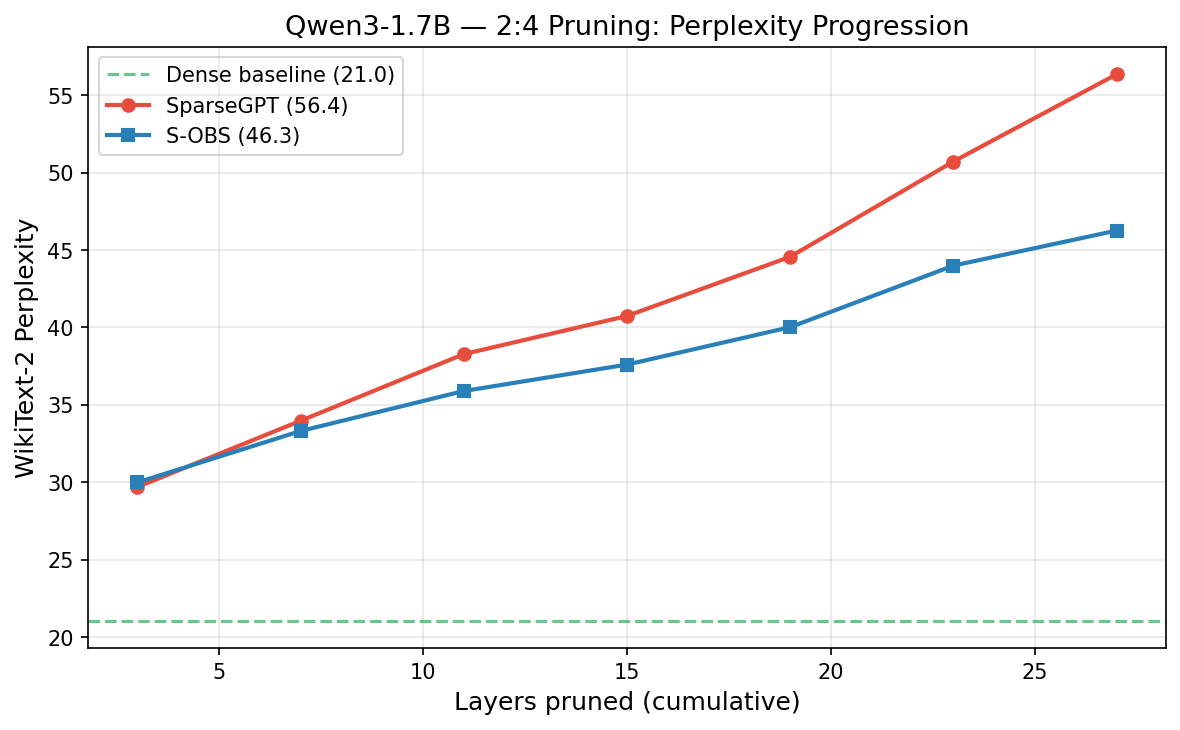
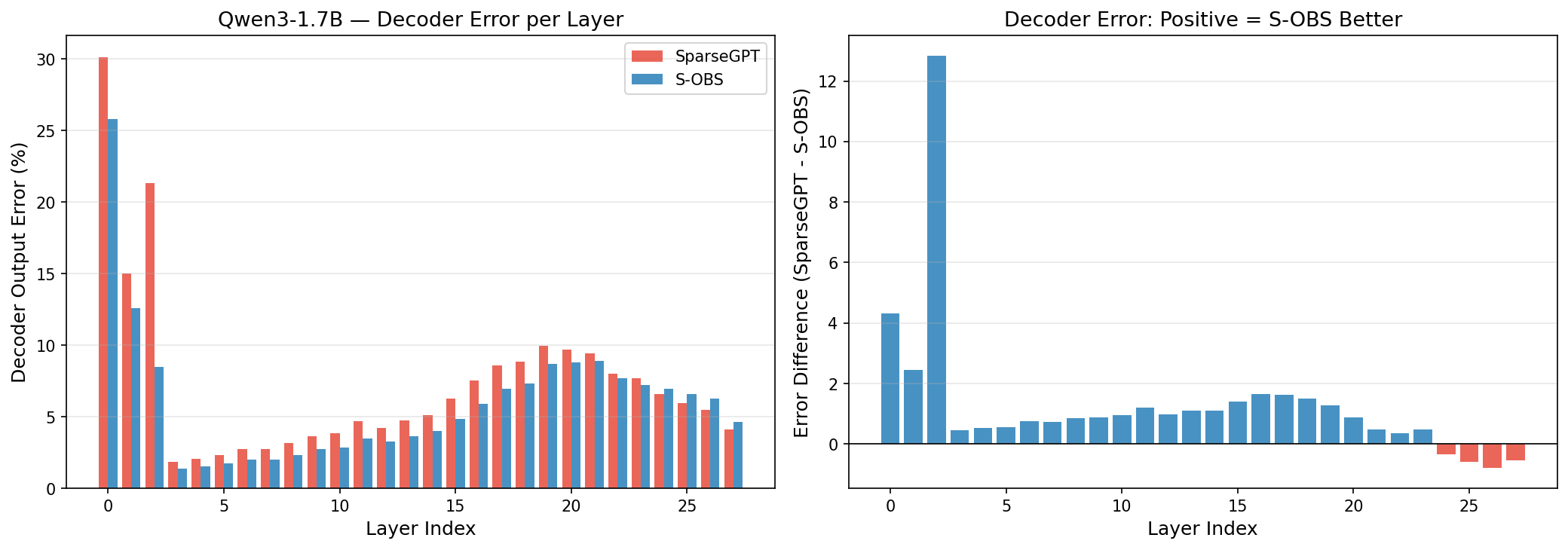
Figure 3: Perplexity progression across decoder layers for Qwen3-1.7B under S-OBS and SparseGPT 2:4 pruning; S-OBS maintains a cumulative advantage.
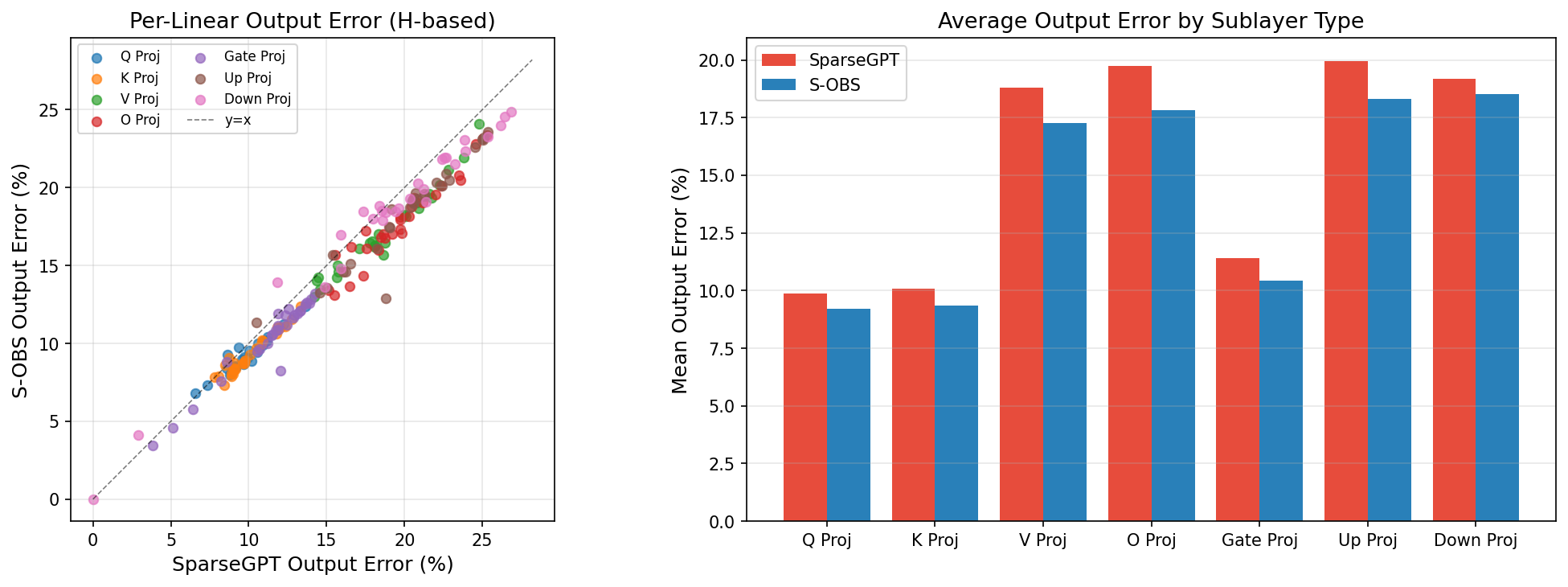

Figure 4: Per-linear output error (normalized trace-based metric) for every linear projection, showing S-OBS outperforms SparseGPT for the vast majority of layers.
Hardware Alignment and Implementation
S30 is explicitly designed to align to hardware execution patterns. By expressing block/thread/coupling arrangements that match hardware units (e.g., tensor cores’ native tiles, coalesced memory accesses), S31 patterns avoid irregular memory access penalties associated with arbitrary mask layouts. As detailed in the hardware mapping appendix, 2:4 and 4:8 patterns map precisely to memory units handled by NVIDIA’s tensor core hardware, and S32 can fuse block- and thread-level alignment for maximal device throughput.
Figure 5: Thread-fragment assignment for the native mma.sync.aligned.m16n8k16 operation, explaining why only certain sparsity patterns are performant on GPU devices.
Implications and Future Directions
S33 provides a decisive step in decoupling sparsity structure specification from the pruning implementation, enabling rapid prototyping, direct device mapping, and uniform scaling of compressive techniques across model architectures. The compositional View–Block–Scope semantics allow research and implementation to target new forms of structured pruning without repeated code multiplications.
Practically, S34—combined with S-OBS or other block-aware heuristics—enables hardware-robust pruning of large models in zero-shot settings, with significant improvements over prior mask or column-wise heuristics in both LLM perplexity and layerwise error. The approach is released as a PyTorch library for public use, supporting immediate application and extensibility.
On the theoretical side, the exposure of sparsity decisions via formal layouts and algebraic composition brings this area closer to the rigor and modularity found in tensor compiler and memory layout research, suggesting new lines of inquiry into structured optimization with specific device and workload constraints.
For future developments, integrating S35 into dynamic sparse training regimes, enabling adaptive mask evolution with structured backbone constraints, appears especially promising given the lack of composable structure in most dynamic masking schemes. Additionally, further research into improving Hessian approximations for late-layer compensation in small or underdetermined regimes could address current limitations and enhance S36's applicability to a broader class of architectures and calibration regimes.
Conclusion
S37 introduces a robust algebraic formalism for specifying, composing, and implementing structured sparsity in neural networks. By divorcing the specification of sparse structure from pruning algorithms, and providing rigorous block/scoping semantics, the framework enables high-fidelity, hardware-aligned pruning for modern deep models, outperforming prior structured and unstructured approaches under a variety of practically relevant evaluation metrics. S38 sets a new standard for structured pruning research and practice, with broad implications for efficient model deployment and the future of sparsity-driven deep learning methods.
Reference: "S39: Structured Sparsity Specification" (2604.11315)