- The paper proposes FRAMP, an end-to-end framework that decouples server-side synthesis from a shared backbone to generate client-specific full models via a HyperNetwork.
- It introduces adaptive submodel extraction through deterministic TopK thresholding, allowing resource-constrained clients to select informative submodels efficiently.
- Prototype-guided representation alignment minimizes the divergence between local and global semantic prototypes, resulting in consistent accuracy across diverse client capacities.
Representation-Aligned Multi-Scale Personalization for Federated Learning
Motivation and Limitations of Existing Approaches
System heterogeneity and data distribution non-IIDness present major barriers for scalable real-world Federated Learning (FL). Prevailing solutions based on model-homogeneous aggregation protocols do not account for diverse client-side computational budgets. Prominent model-heterogeneous FL methods extract personalized submodels from a shared global backbone, employing either static or dynamic submodel masking. However, these approaches exhibit strong structural overlap across clients, constrained expressivity due to client-agnostic parameter importance estimation, and fundamental limitations in representing client-specific data distributions.
Figures 1 and 2 illustrate these critical issues for FIARSE, a dynamic submodel extraction baseline. The cumulative distribution of mask selections (Figure 1) indicates that submodels for resource-constrained clients (e.g., $1/64$ size) overwhelmingly reuse a small fraction of the global parameters, undermining subnetwork diversity. This structural redundancy directly leads to substantial accuracy variance across clients (Figure 2), with smaller submodels especially underperforming.
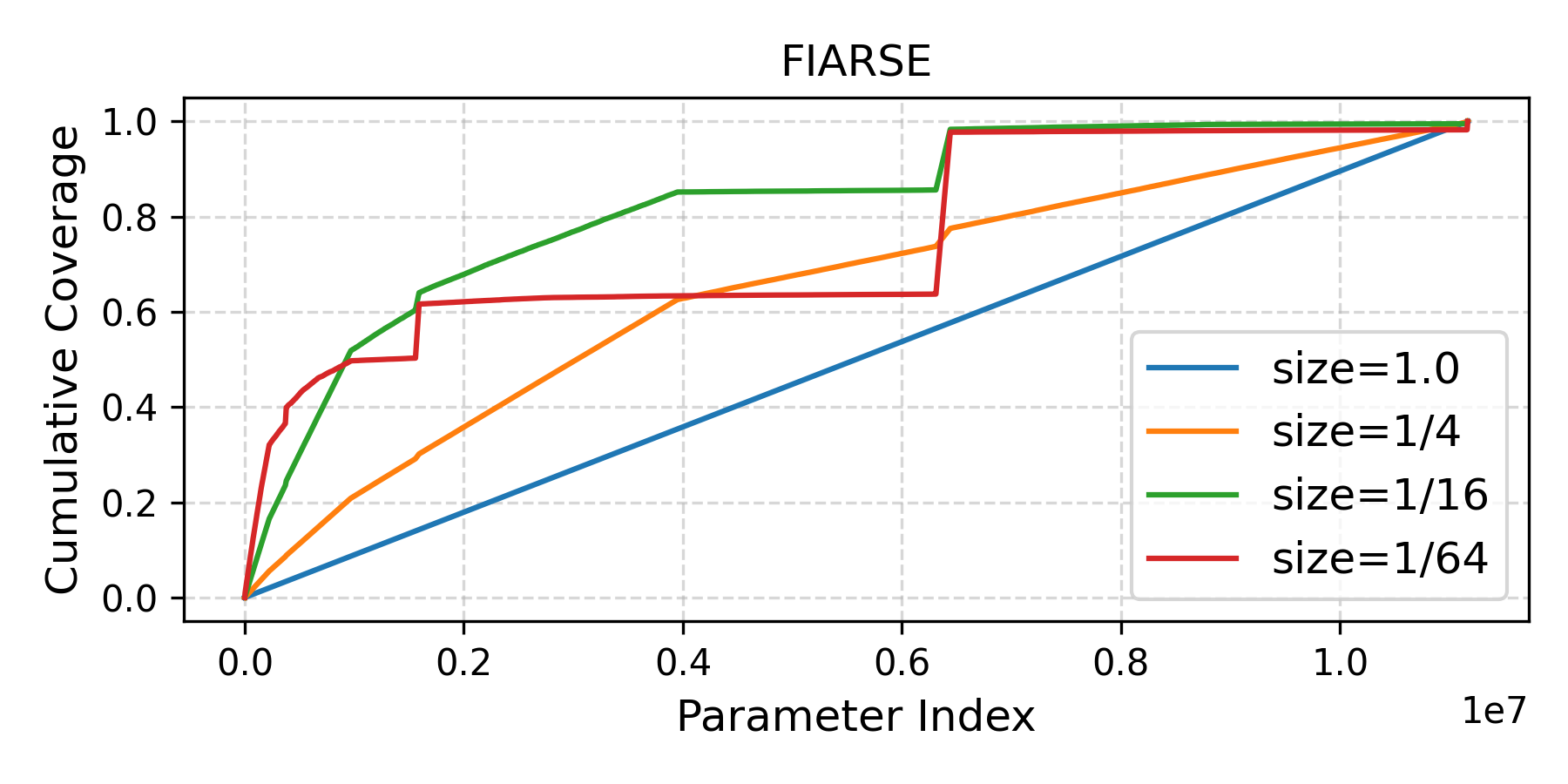
Figure 1: Cumulative distribution of preserved parameters across submodels of different sizes. Each curve represents the cumulative proportion of parameters selected (mask=1).
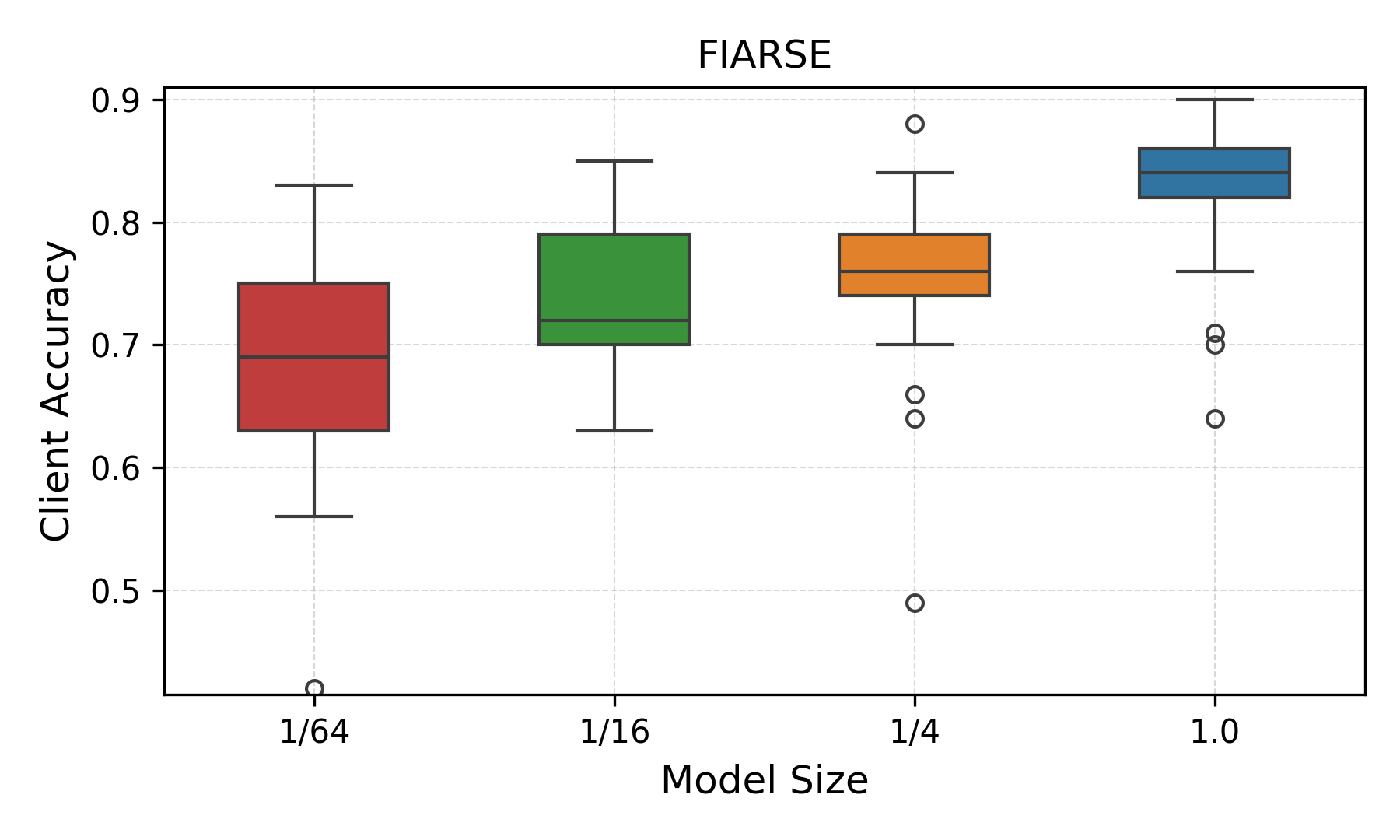
Figure 2: Client accuracy distribution of submodels across different sizes. Each box represents the variation in accuracy among clients.
Notably, existing methods fail to ensure semantic alignment, with non-IID data and model structural heterogeneity causing divergence in learned class representations and poor generalization. These fundamental constraints set the stage for the technical contributions of the "Representation-Aligned Multi-Scale Personalization for Federated Learning" framework (FRAMP) (2604.11278).
The FRAMP Framework
FRAMP presents a unified, end-to-end approach for personalized and resource-adaptive FL, decoupling server-side model synthesis from homogeneous backbones and integrating rigorous semantic alignment. The framework consists of three components, visualized in Figure 3:
- Client-Aware Full-Size Model Generation: Each client provides a compact descriptor, typically obtained via local feature aggregation. A HyperNetwork (HN) on the server maps these descriptors to per-client, full-size model parameters, removing the constraint of a shared backbone and supporting client-specific model instantiation at scale.
- Adaptive Submodel Extraction: Submodel selection is encoded as a deterministic, parameter-magnitude-based TopK thresholding, tailored to each client’s compute budget (sparsity constraint). Unlike prior strategies requiring external importance tracking, mask selection is implicit in the learned parameter values output by the HN and adaptively updated.
- Prototype-Guided Representation Alignment: To ensure global semantic consistency, FRAMP employs prototype-level alignment. Each client computes latent class means over local data and uploads prototypes to the server; the server averages these to global class prototypes and distributes them back. A representation alignment loss regularizes the local training, minimizing the distance between local and global prototypes.
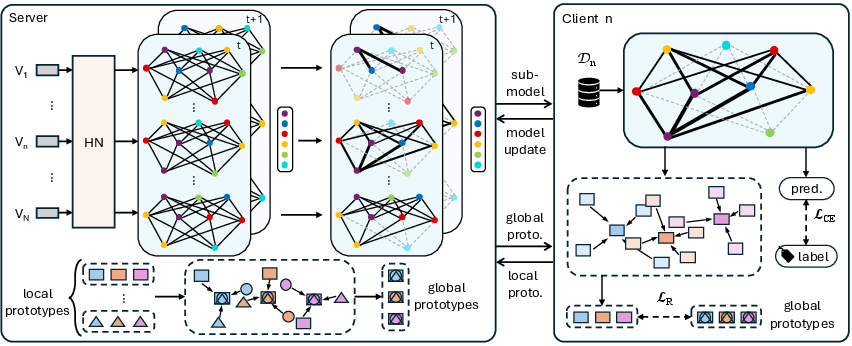
Figure 3: Overview of the FRAMP framework. The server generates personalized full models using HN and extracts submodels via dynamic masking for each client. Clients train these submodels on local data and align class-level prototypes with server-aggregated global prototypes to ensure semantic consistency. Updates are used to refine the HN and global prototypes.
This architecture supports simultaneous personalization with respect to both data and system constraints and enables the optimization of server and client parameters in a differentiable, communication-efficient workflow.
Experimental Results
FRAMP is evaluated on standard vision (CIFAR-10, CIFAR-100) and graph (ogbn-arxiv) datasets, under non-IID distributions and severe system heterogeneity (four model capacity levels). Comparative baselines include HeteroFL, ScaleFL, FedRolex, and FIARSE.
Accuracy distributions (Figure 4) demonstrate that FRAMP achieves higher, more consistent client-level accuracy, especially for small submodels, while alternative methods exhibit long-tailed and dispersed performance.

Figure 4: Histograms on CIFAR-10 showing client counts at different test accuracy levels under four submodel sizes for each baseline. The curves depict the accuracy distribution for each model size.
Average accuracy for the smallest models (1/64 capacity) is consistently higher for FRAMP across all datasets, indicating that the combination of dynamic masking and hypernetwork-based full-model personalization enables resource-constrained clients to select more informative submodels. Notably, the submodel accuracy (Figure 5) is less sensitive to capacity shifts and more robust to exclusion of model sizes during training, compared to all baselines.
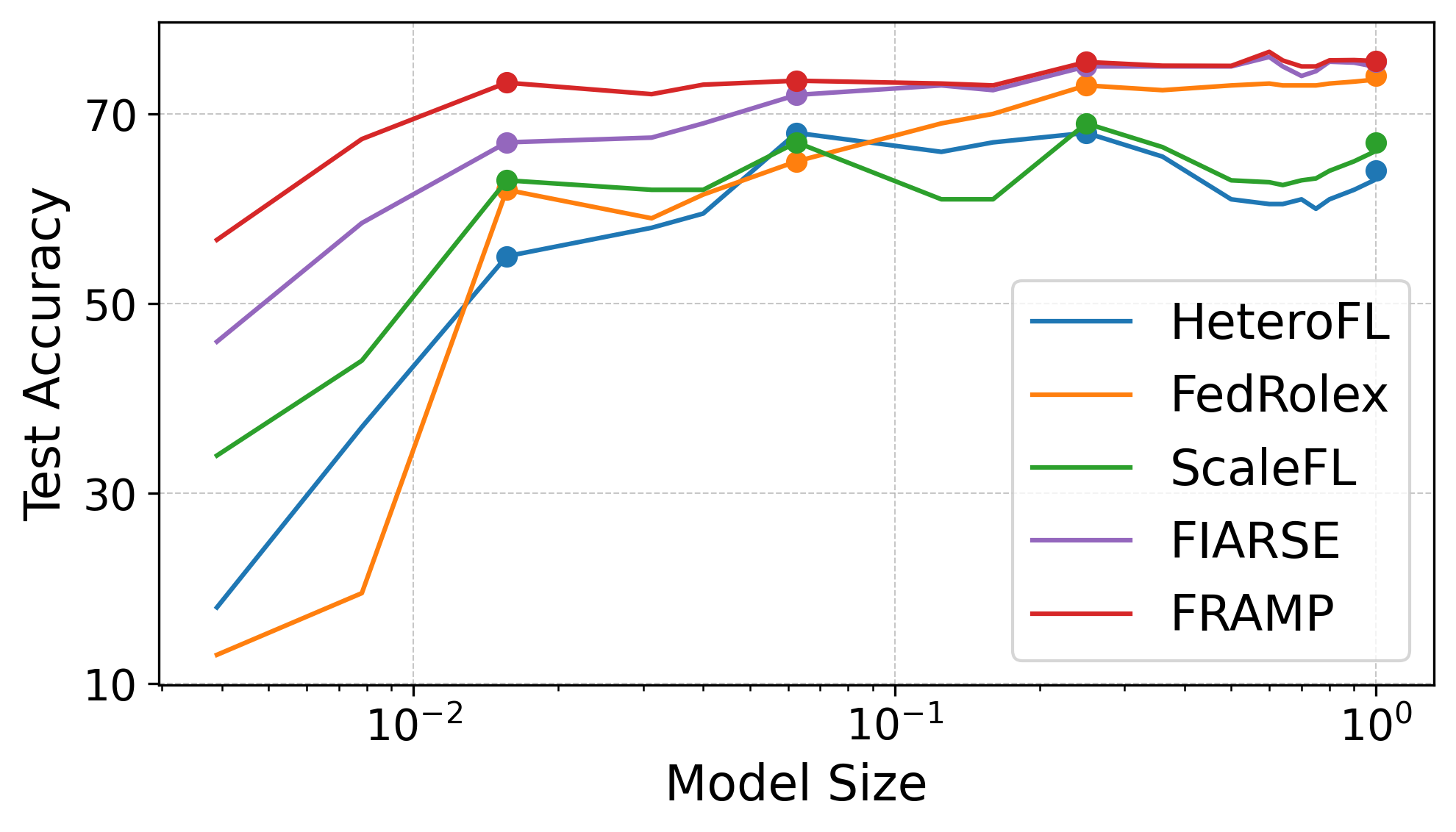
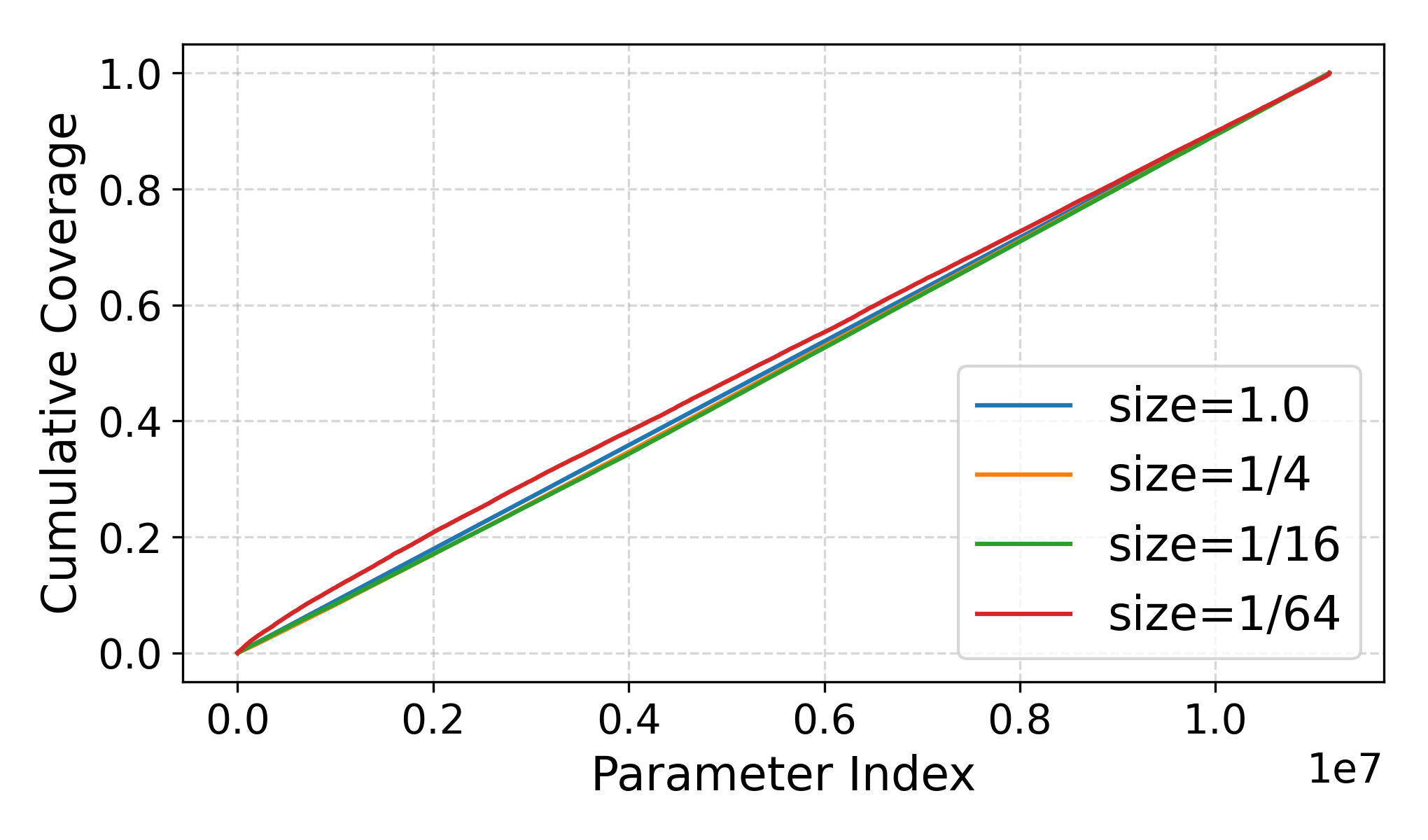

Figure 5: Submodel accuracy.
Generalization to unseen clients and capacities is validated by excluding client groups during training (Figure 6). FRAMP maintains minimal degradation, while performance for prior baselines collapses, especially for aggressively pruned models, clearly demonstrating the adaptability and robustness derived from decoupled model generation.
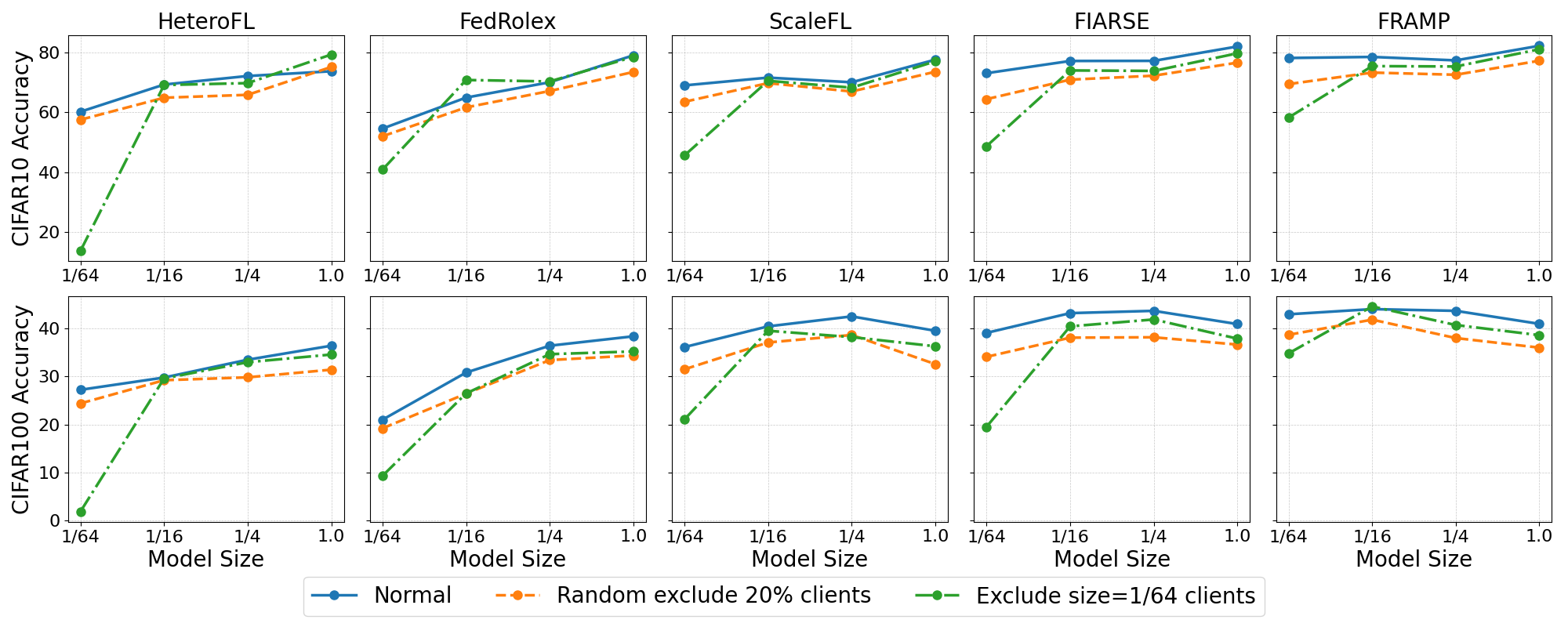
Figure 6: Test accuracy of submodels (across four model sizes) on CIFAR-10 and CIFAR-100, evaluated under three training settings: (1) training with all clients; (2) randomly excluding 20\% of clients from each model size group; (3) excluding only clients with the smallest model size (γ=1/64).
FRAMP’s performance is consistent across varying strengths of prototype regularization (Figure 7), and outperforms methods in both union and local test set settings for all considered tasks.
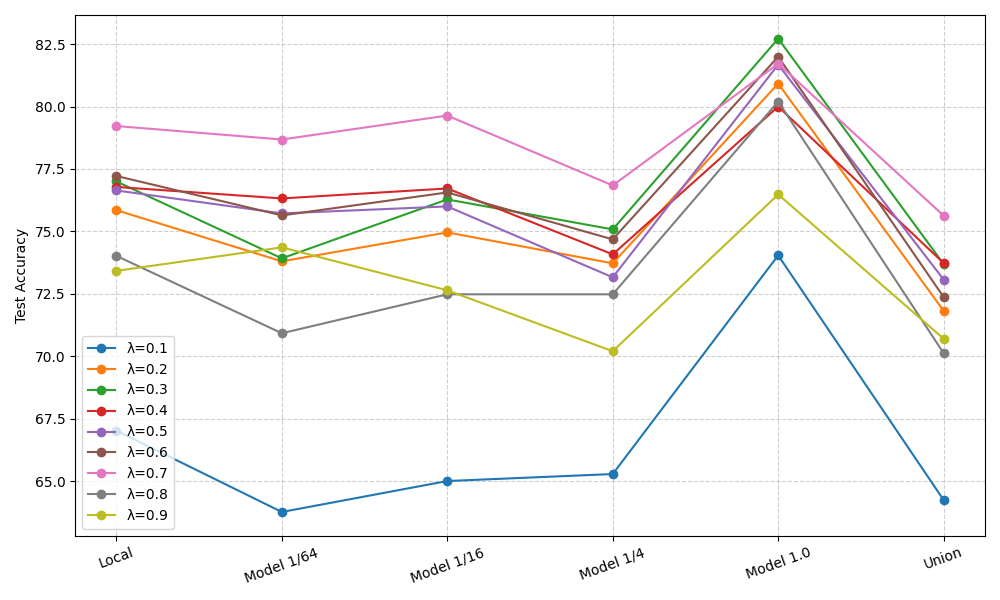
Figure 7: Test accuracy across different model sizes (Local, 1/64, 1/16, 1/4, 1.0, Union) under varying values of the alignment weight λ.
Ablations reveal that disabling either model personalization (using a shared backbone) or prototype alignment increases accuracy variance and reduces mean performance, corroborating their complementary benefits.
Analysis and Implications
FRAMP achieves uniform model parameter utilization (contrasting with Figure 1) and strong alignment of local and global prototypes under representation heterogeneity. Submodel structural diversity, semantic alignment, and compute adaptivity are attained in a server-centric, communication-efficient design. The approach is agnostic to architecture and applicable broadly, as tokenized client descriptors and hypernetworks can, in principle, be generalized to arbitrary modalities.
The prototype-sharing mechanism is robust to moderate noise and perturbation, and FRAMP supports standard privacy-preserving FL security augmentations (differential privacy, secure aggregation).
From a theoretical perspective, FRAMP shifts the paradigm toward client-conditional weight generation as a universal abstraction for personalized FL, and aligns with recent advances in hypernetwork-based meta-learning and representation transfer. Empirically, it closes performance gaps under extreme heterogeneity, scales to unseen clients and capacities, and accommodates arbitrary levels of client system and data diversity within a principled optimization protocol.
Scalability is maintained as per-client model generation complexity is offloaded to the server, with negligible client-side overhead beyond descriptor and prototype exchange (both lightweight operations).
Future avenues include generalizing importance estimators beyond parameter magnitude, using richer client descriptors, and leveraging more expressive conditional generators or parameterizations for hypernetwork outputs.
Conclusion
FRAMP establishes a principled, modular, and robust solution for resource-scalable, personalized federated learning. Through client-aware dynamic submodel extraction and explicit prototype-level semantic alignment, it eliminates the representational collapse and performance disparity endemic to methods based on shared, static backbones. The framework sets a robust foundation for further advances in both the personalization and system heterogeneity aspects of modern federated optimization, and marks a meaningful step toward resource- and data-adaptive decentralized AI (2604.11278).

