- The paper introduces a lightweight, blind approach using neural covariance estimation integrated with a MIMO Wiener filter to preserve spatial directionality.
- It leverages OnlineSpatialNet, a causal architecture that outputs scale-normalized Cholesky factors, ensuring effective covariance estimation and outperforming baseline methods like NICE.
- The method achieves notable SI-SDR gains, high covariance cosine similarity, and reduced computational complexity, making it ideal for real-time spatial audio applications.
Direction-Preserving Multichannel Speech Enhancement via Neural Covariance Estimation
Introduction and Motivation
Microphone array processing is foundational in robust speech acquisition for applications spanning hearing aids, telepresence, and augmented reality. Conventional multiple-input-single-output (MISO) enhancement paradigms, typified by beamforming and multichannel Wiener filtering, prioritize noise suppression at the expense of preserving spatial information, thus impeding downstream tasks such as binaural rendering, adaptive beamforming, and direction-of-arrival (DOA) estimation. To address these limitations, attention has increasingly shifted to direction-preserving multiple-input-multiple-output (MIMO) enhancement frameworks, where the goal is to produce enhanced multichannel outputs that maintain the spatial (directional) characteristics of both target speech and residual noise.
However, most direction-preserving MIMO approaches either depend on strong oracle assumptions (reverberation time, noise coherence) or are computationally inefficient, especially for real-time and embedded applications. The paper "Direction-Preserving MIMO Speech Enhancement Using a Neural Covariance Estimator" (2604.11179) proposes a lightweight, learning-based method for blind, direction-preserving MIMO speech enhancement utilizing neural estimation of the spatial noise covariance matrix—a critical component for effective MIMO Wiener filtering.
Methodology
The paper advances the state of the art by formulating speech enhancement as a fully blind problem, leveraging a neural network (OnlineSpatialNet) to estimate a scale-normalized Cholesky factor of the frequency-domain noise covariance directly from microphone array signals. This estimation is directly integrated into a direction-preserving MIMO Wiener filter (DP-MWF), enabling noise suppression while maintaining spatial properties for both the target and the residual components.
Key architectural and algorithmic details:
- Neural Covariance Estimation: Instead of time-frequency masking, OnlineSpatialNet is trained to output the lower-triangular Cholesky factor of the noise covariance, guaranteeing Hermitian positive definiteness through architectural constraints.
- Scale Normalization: To achieve input-level invariance, the covariance is normalized using the average trace, and both mixture and estimated noise covariances are rescaled accordingly before being used in the filter.
- OnlineSpatialNet: Adapted for causal online processing, this architecture employs convolutional front-end layers with interleaved cross-band and narrow-band blocks to capture spatiotemporal dependencies across microphones and frequency bins, replacing self-attention with retention mechanisms.
- Comparative Baseline: The proposed method is benchmarked against NICE, a representative mask-based estimator utilizing single-channel masks and LSTM-based temporal modeling.
The neural estimator is trained via a joint loss combining time-domain scale-invariant SDR (SI-SDR) and a normalized Frobenius loss on the Cholesky decomposition, enforcing not only output signal fidelity but also direct covariance accuracy.
Experimental Evaluation
An extensive simulated dataset was constructed using DNS Challenge speech and noise, convolved via room simulation for a 6-microphone circular array with realistic reverberation and source placements. Both OnlineSpatialNet and NICE operate on STFT-domain inputs and are trained end-to-end using Adam.
Evaluation encompasses not only classic enhancement metrics (SI-SDR, noise reduction) but also spatial preservation (covariance cosine similarity between estimated and oracle quantities), and task-relevant downstream metrics (post-beamforming SI-SDR, binaural rendering ILD error). Importantly, the analysis incorporates computational cost (parameter count, GFLOPs/s), a vital factor for practical deployment.
Spatial Response Analysis
The preservation of spatial directivity is central to the method. The authors visualize the impact of enhancement on the steered response power (SRP), demonstrating that target direction is retained post-enhancement.
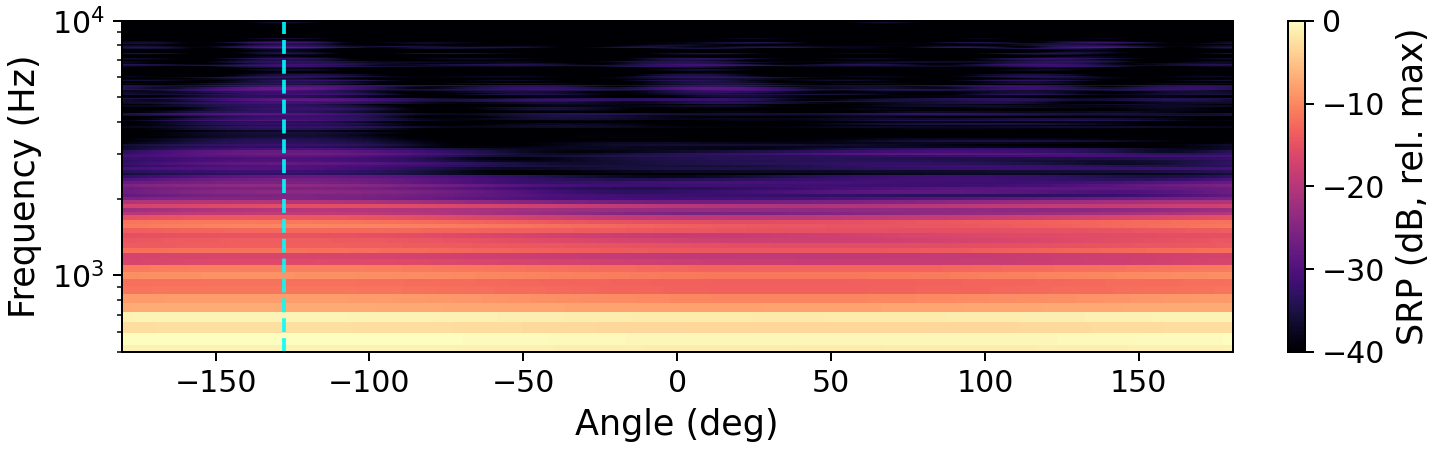
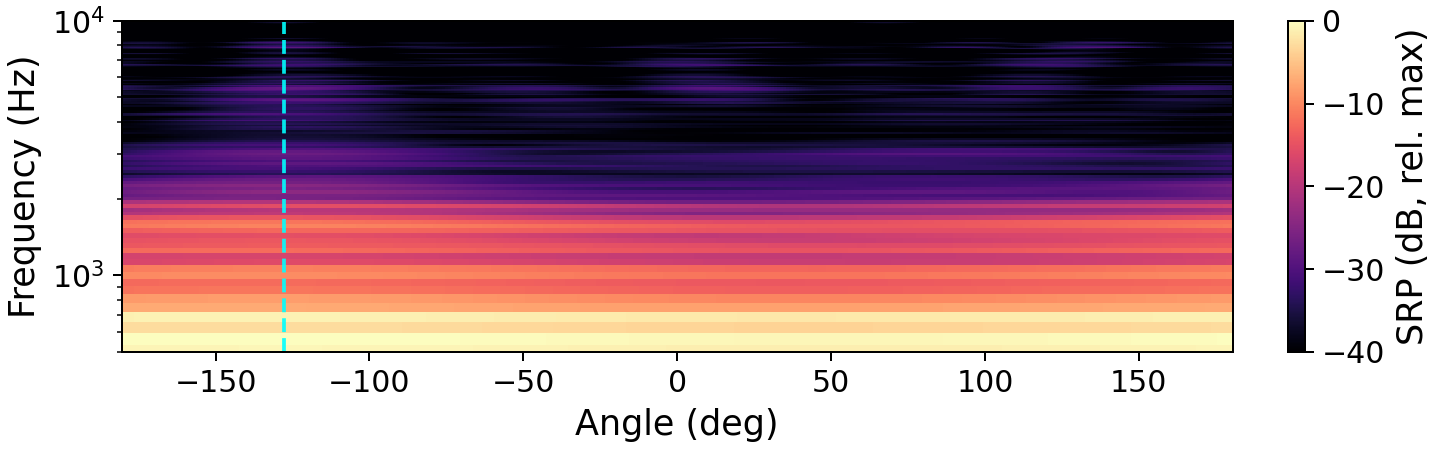
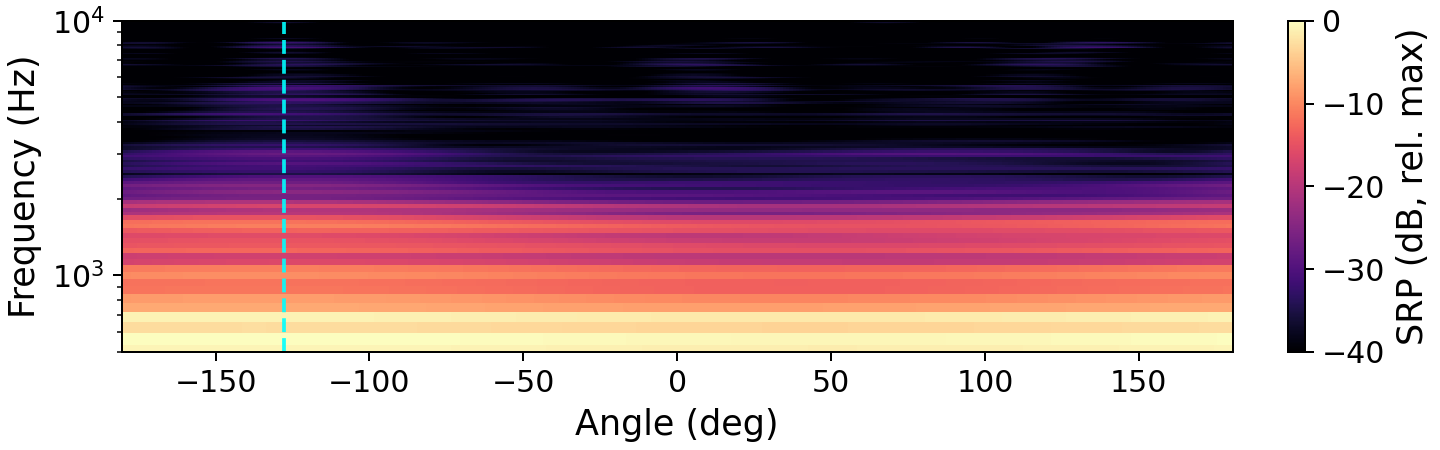
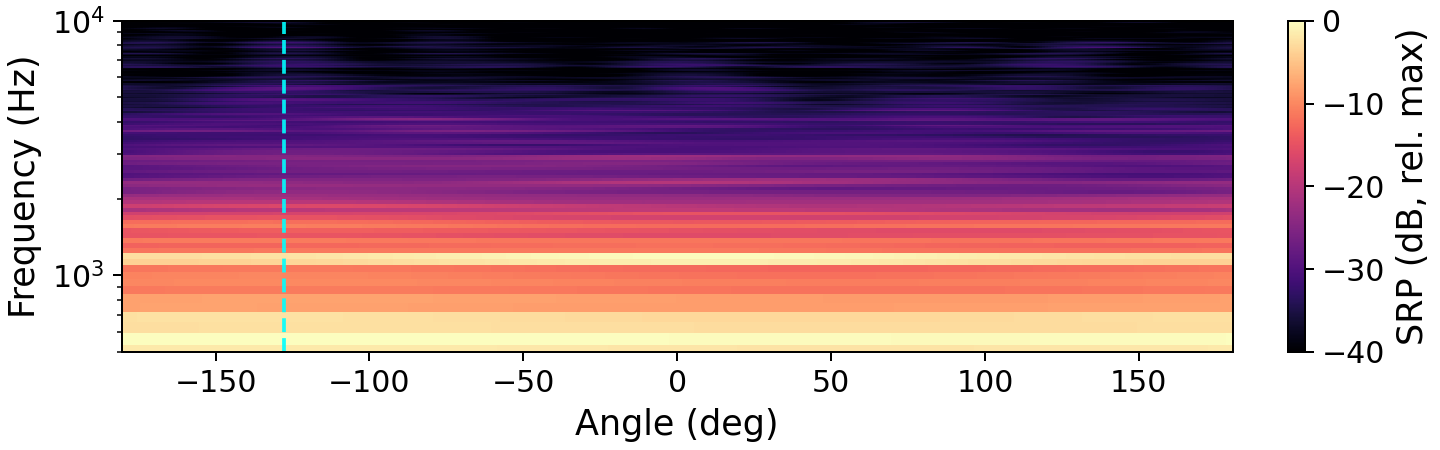
Figure 1: Steered response power maps exhibit how enhancement by OnlineSpatialNet and NICE clarifies and preserves the target source direction, in contrast to the noisy mixture. The dashed vertical line marks the true target DOA.
Main Results and Claims
Numerical Highlights:
- OnlineSpatialNet achieves an SI-SDR of 9.37 dB, closely approaching the oracle DP-MWF upper bound (11.01 dB) and surpassing NICE (8.50 dB), indicating effective blind enhancement.
- Covariance estimation accuracy: OnlineSpatialNet achieves a covariance cosine similarity of 0.93 (CovSim), with comparable results for preservation of speech and noise spatial statistics, demonstrating high fidelity to the oracle covariance.
- Computational efficiency: OnlineSpatialNet operates at roughly one third the parameter and FLOP count of NICE, underscoring its suitability for resource-constrained deployment.
- Downstream metrics: Post-beamforming SI-SDR and binaural ILD error outcomes underline the method's practical utility in beamforming and high-fidelity binaural rendering, with OnlineSpatialNet consistently outperforming NICE.
Key Claims:
- The paper asserts that neural spatial covariance estimation tailored to multichannel signals yields superior results compared to mask-based methods—not only in enhancement metrics but especially in spatial preservation, at reduced complexity.
- Unlike prior work, the reliance on oracle knowledge is removed with no substantial degradation in spatial enhancement quality, marking a significant step for fully blind spatial speech enhancement.
- Furthermore, the method is suitable as a front-end for spatial audio applications owing to its preservation of directionality for both target and residual signals.
Implications and Future Perspectives
Practically, the proposed method aligns well with emerging requirements in AR/VR, personal audio devices, and telepresence, where spatial accuracy must be preserved under tight resource constraints. The direct estimation of spatial covariances facilitates integration with advanced downstream spatial processing, such as matrix beamforming, adaptive dereverberation, and scene-aware rendering.
Theoretically, this approach signals a shift toward spatially holistic neural models for MIMO enhancement: rather than reducing multichannel statistics to scalar masks, networks are trained to represent and manipulate high-dimensional covariance structure. This paradigm may inform future work in other spatial audio contexts, such as joint source separation, dereverberation, or spatial scene analysis, where direct modeling of full covariance is advantageous.
Possible research extensions include:
- Applying transformer-based or low-rank covariance architectures for even greater efficiency.
- Incorporating or learning further spatial priors, for instance, using microphone geometry-aware inductive biases.
- Extension to jointly enhanced speech and noise covariance modeling for fully consistent sound field rendering.
Conclusion
The paper introduces a compact, neural approach for fully blind, direction-preserving MIMO speech enhancement, centered on neural spatial covariance estimation and efficient integration with a direction-preserving Wiener framework. Empirical evidence supports the claim that this approach yields high-quality enhancement, accurate spatial structure, and competitive computational efficiency relative to mask-based architectures, paving the way for advanced spatial audio pipeline design in real-world, low-latency applications (2604.11179).