- The paper provides a full-scale LCA of GenAI research, revealing that only 4% of GPU time is spent on final training while 96% is dedicated to experimentation and diagnostics.
- It quantifies energy, GHG, water, and resource impacts for the Moshi model, with figures comparable to annual footprints of cities or mass consumer electronics production.
- The study recommends strategies such as reducing redundant evaluations, off-production debugging, and full reporting of compute budgets to enhance research sustainability.
Comprehensive Life Cycle Assessment of GenAI Research: The Case of the Moshi Foundation Model
Introduction
The paper "Environmental Footprint of GenAI Research: Insights from the Moshi Foundation Model" (2604.11154) presents a granular, end-to-end analysis of the compute and environmental footprint underlying the development of Moshi, an industry-scale 7B-parameter real-time speech-text foundation model. Unlike prior work which predominantly reports only the operational carbon footprint of final model training, the study provides a full-spectrum audit including early R&D, failed experiments, hyperparameter search, rigorous ablation studies, and hardware manufacturing impacts. Leveraging exhaustive internal logs from Kyutai, the authors quantify the energy, greenhouse gas (GHG), water, and mineral resource costs of each research phase and module, ultimately producing actionable guidance to reduce the environmental overhead of GenAI research.
Moshi System Architecture and Research Workflow
The Moshi system integrates several heterogeneous modules: a custom LLM backbone (Helium), the Mimi audio tokenizer (neural codec), a main transformer operating directly on speech tokens, and a data generator (TTS). The complete workflow—spanning experimentation, pre-training, post-training, and fine-tuning—was explicitly tracked and parsed across 3,534 individual training runs, supporting a granular attribution of compute to modules and phases.
The function and workflow of each module are schematized in the following illustration, which also shows information routing and data transformation during model operation:
Figure 2: Moshi module interconnections, depicting data flow from sound input through the tokenizer and main model, with initialization from the Helium LLM and dataset generation via TTS.
This architectural decomposition enabled the authors to isolate compute/hardware impacts not only by module but also by process novelty, revealing that innovative, less-stable research directions (speech-to-speech modeling) entailed much larger multiplicative overhead than established LLM pipelines.
Compute Cost Attribution: From Experimentation to Deployment
The computational audit reveals that the dominant share of energy and resource expenditure occurs outside final model training. Specifically, only 4% of total GPU-time is devoted to final runs; architecture exploration, hyperparameter search, failed/bugged experiments, validation/evaluation, and ablation studies compose the overwhelming remainder. Early-stage experimentation and tuning consumed as much as 75% of compute in the main, less standardized modules, while design and exploration for established architectures (Helium LLM) incurred much smaller overhead.
A temporal and intensity breakdown of GPU allocation underscores two key findings: early phases require many short, low-GPU experiments, but >89% of cumulative compute is concentrated in only 13% of long/hard runs, mostly in pre-training.
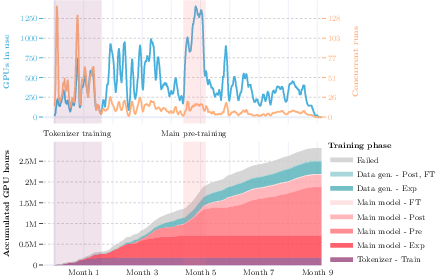
Figure 1: Timeline of active GPUs, concurrent jobs, and aggregate compute, stratified by work phase and module, emphasizing the heavy tail in compute intensity.
Crucially, failed and bugged runs contributed over 11% of total compute despite individually being of lower intensity, due to their sheer number (42% of all runs).
Full Life Cycle Assessment: Energy, GHG, Water, and Abiotic Impacts
Moving beyond operational electricity consumption from training, the paper pursues a complete first-order LCA, quantifying both operational (datacenter and computation) and embodied impacts (hardware manufacturing, transport, node assembly), focusing on:
- Primary energy extraction (MJ)
- GWP (kgCO2eq)
- Water consumption (L)
- Abiotic resource depletion (kgSbeq)
The holistic R&D effort underlying Moshi consumed 5 GWh of electricity, responsible for 319 tons of CO2eq (comparable to the annual footprint of 39 French citizens or 132 Paris-San Francisco flights), 19 million liters of water, and resource depletion equivalent to the production of 6,500 smartphones. The dissection by hardware component revealed GPUs as the primary driver for all impacts except mineral depletion, where RAM and power supplies are also significant, highlighting the non-negligible contribution of peripheral server infrastructure seldom tallied in previous studies.
Geographic analysis demonstrated substantial location-dependence of operational GWP and water costs, depending on grid energy mix (fossil/nuclear/hydroelectric), with no monotonic relation between water and CO2 impacts.
Contradictions with Prior Art and Implications for Sustainable Research
A major output of this analysis is the quantitative contradiction of the common industry narrative that final training is the costliest piece; in Moshi, final training accounts for at most 4% of total research compute for innovative modules, versus 15% for mature LLM backbones—contrasting sharply with reports from BLOOM (>31%) and OLMo-LMs (50%). This is attributed to the novelty of open-ended, less optimized research directions, and calls into question the representativeness of GHG estimates centered on deployment-only training for ongoing GenAI innovation.
The findings also contradict standard modeling of research workflows: most environmental impact arises from iterative, failing, or diagnostic experimentation rather than hyperparameter sweeps or final scaling. Ablation studies and safety analyses—crucial for publication in peer-reviewed venues—consume a non-trivial fraction (8%) of the full environmental budget.
Recommendations and Future Directions
The authors propose several strategies for reducing the environmental cost of GenAI research and suggest concrete practices for the field:
- Restrict compute-heavy experiments: Prioritize detailed monitoring, and background checks on large jobs (above GPU-month), and improve diagnostic tools to minimize failed expensive runs.
- Debug and evaluate off-production: Use low-power or downscaled infrastructure for early diagnostics and debugging.
- Reduce redundant evaluation/validation: Lower evaluation frequency and minimize the sample size for human or automated assessment benchmarks.
- Critical review of ablation practices: Conduct model ablations and comparative studies on proxy models or datasets rather than full-scale final architectures.
- Include complete budget reporting: Make hardware, compute, and full research-phase energy/CO2 metrics a standard component of model reporting, following emerging best practices (e.g., CodeCarbon, Boavizta).
- Hardware lifetime extension: Since GPUs and RAM (by total quantity) dominate embodied impacts, research into low-memory architectures and efficient reuse/repurposing of accelerators is essential.
On a theoretical level, the paper suggests that future studies of "AI sustainability" must avoid equating deployment optimization with sustainable AI unless full R&D and embodied impacts are carved out. For less-mature application domains, where iteration cycles dominate, the compute estimate envelope becomes much broader.
Conclusion
This work establishes a new reference framework for environmental accounting in GenAI R&D pipelines, especially for novel tasks without mature scaling laws or transfer learning protocols. The reported 25×–40× multipliers over final compute for innovative modules emphasize the urgency for end-to-end life cycle analyses in AI system science. Adoption of the methodological guidelines and transparency practices proposed here will be necessary to align AI research with ecological constraints, enable meaningful benchmarking of sustainability claims, and promote responsible growth in compute-intensive deep learning paradigms.