- The paper introduces a novel framework that quantifies LLM inference's environmental impact by measuring energy, water, and carbon footprints.
- The methodology integrates performance metrics with region-specific factors like PUE, WUE, and CIF to estimate per-query energy use and emissions.
- Experimental evaluation reveals significant variability among models, emphasizing the critical role of infrastructure in sustainable AI deployment.
Introduction
The paper "How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference" presents a new framework to quantify the environmental footprint of LLMs during inference. As LLMs expand into various applications, their sustained environmental impact becomes a significant concern. While training LLMs has historically been the focus of sustainability discussions, inference—which occurs more frequently—presents a larger environmental burden. This paper addresses this gap by introducing a comprehensive benchmarking approach for evaluating the environmental costs of LLM inference across 30 models using empirical data and statistical analysis.
Methodology
The proposed framework for measuring the environmental impact of LLM inference integrates performance metrics like latency and throughput from public APIs with region-specific environmental multipliers such as Power Usage Effectiveness (PUE), Water Usage Effectiveness (WUE), and Carbon Intensity Factors (CIF). This infrastructure-aware approach advances the understanding of energy, water, and carbon implications for both open-source and proprietary models.
The methodology relies on several steps:
- Model Selection and Hardware Estimation: Thirty models were analyzed, categorized by deployment context and estimated hardware configurations based on observed performance metrics, such as Tokens Per Second (TPS).
- Per-Query Energy Consumption: Energy estimates were calculated using a formula incorporating model-specific performance data, region-specific PUE, and statistical models to account for infrastructure complexity, ensuring realistic modeling of disparate data centers.
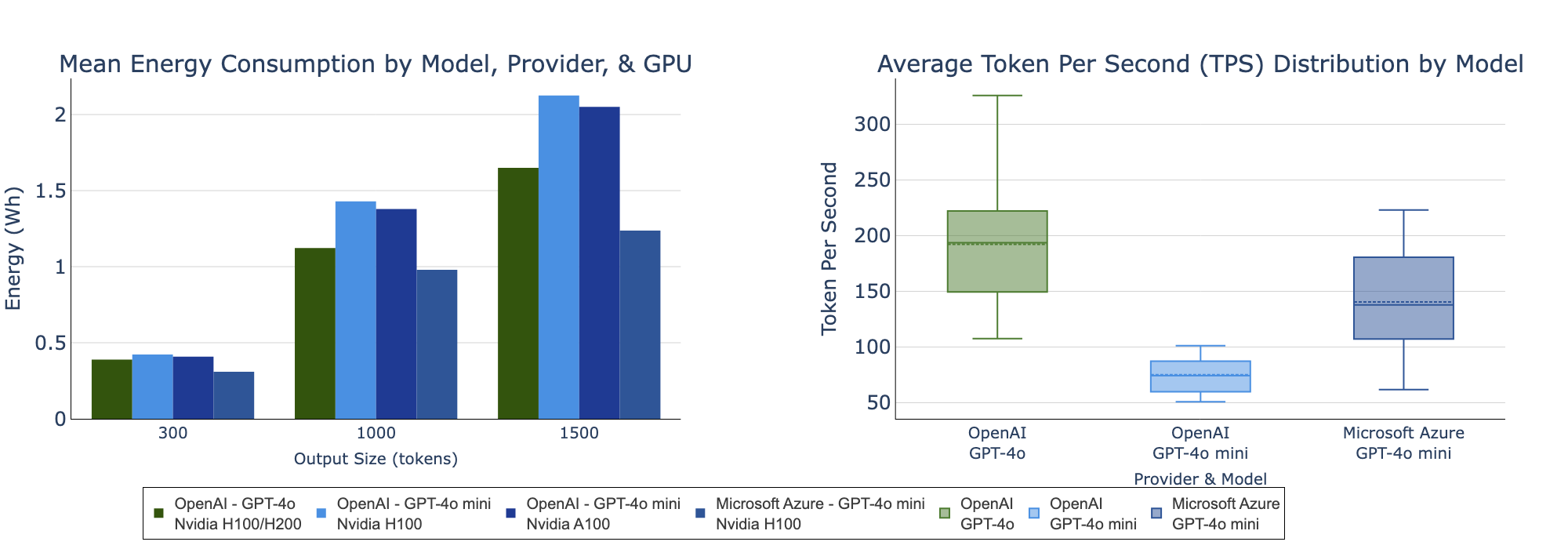
Figure 1: (Left) Mean energy consumption of GPT-4o and GPT-4o mini across providers and GPU types, measured by output size. (Right) Distribution of TPS (averaged across output sizes).
- Water and Carbon Emissions: Operational water consumption and carbon emissions were derived from energy usage metrics, while de-emphasizing Scope 3 impacts due to their variability and limited per-query attribution applicability.
- Eco-efficiency Analysis: Utilizing cross-efficiency Data Envelopment Analysis (DEA), the paper evaluates each model's ability to convert environmental resources into intelligence, offering a nuanced view of eco-efficiency across models.
Experimental Evaluation
Energy Consumption
The results highlight the disparity in energy consumption across models based on architecture and deployment infrastructure. For example, while GPT-4.1 nano requires only 0.454 Wh for long prompts, o3 consumes over 39 Wh, showcasing a wide variability in energy efficiency. These findings suggest that model architecture alone doesn't determine real-world energy use; instead, the deployment infrastructure significantly impacts energy requirements.
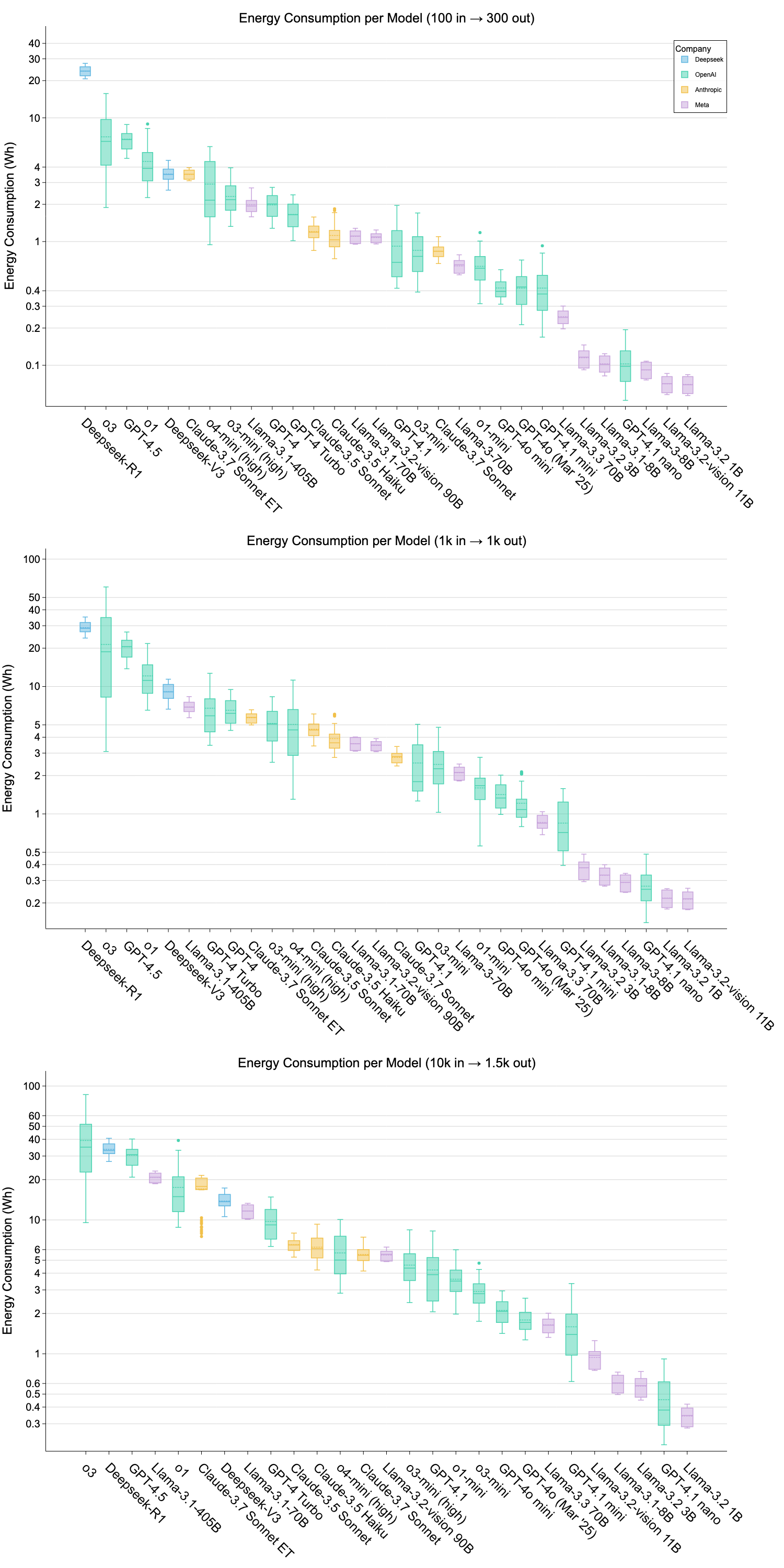
Figure 2: Energy consumption per model across three prompt sizes (Wh, logâscale).
Water and Carbon Emissions
The evaluation reveals substantial variations in water usage and carbon emissions among models, emphasizing the broader environmental implications of AI deployment. Notably, some models, like DeepSeek-R1, demonstrate exceptionally high environmental costs due to deployment inefficiencies.
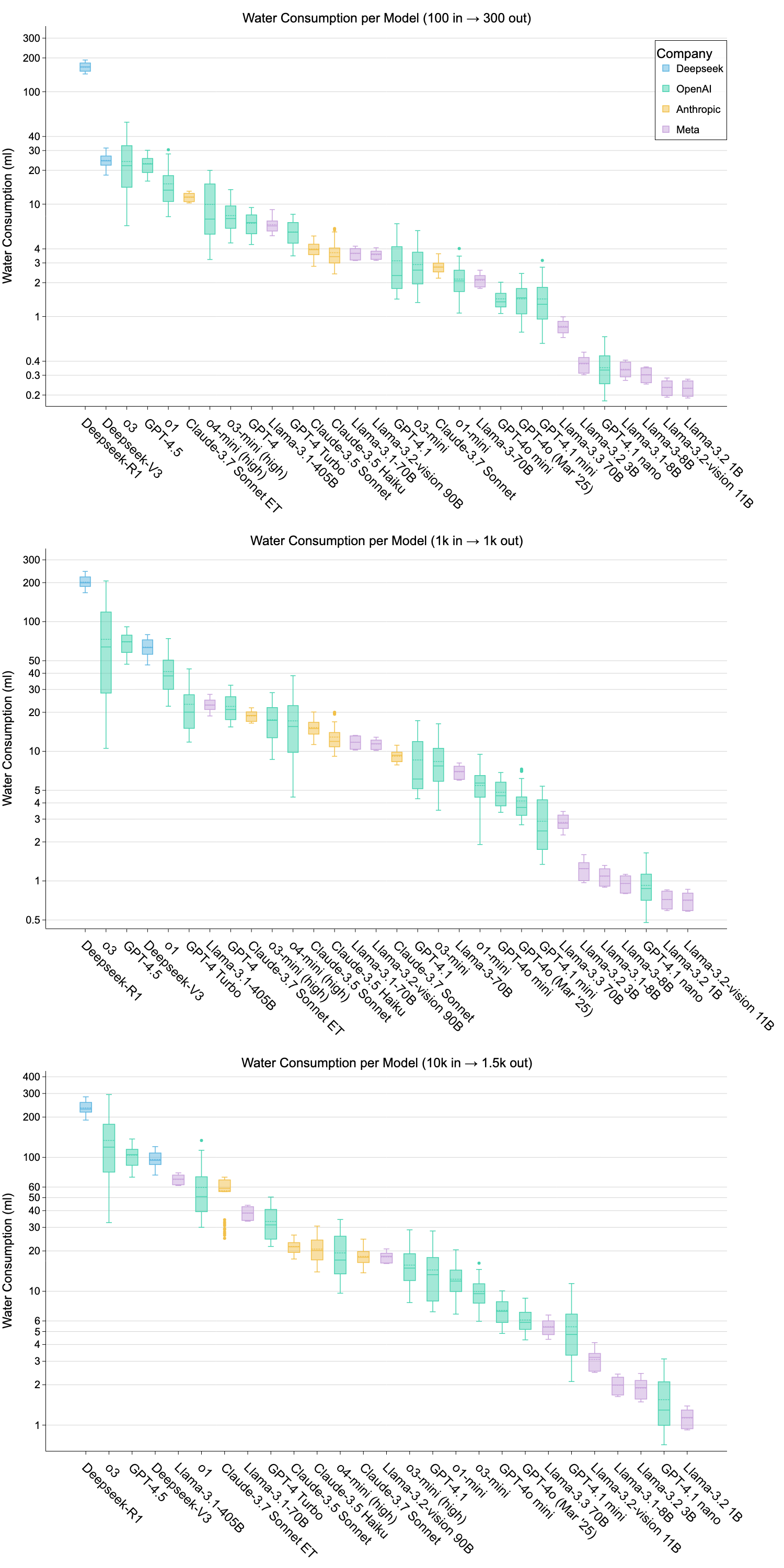
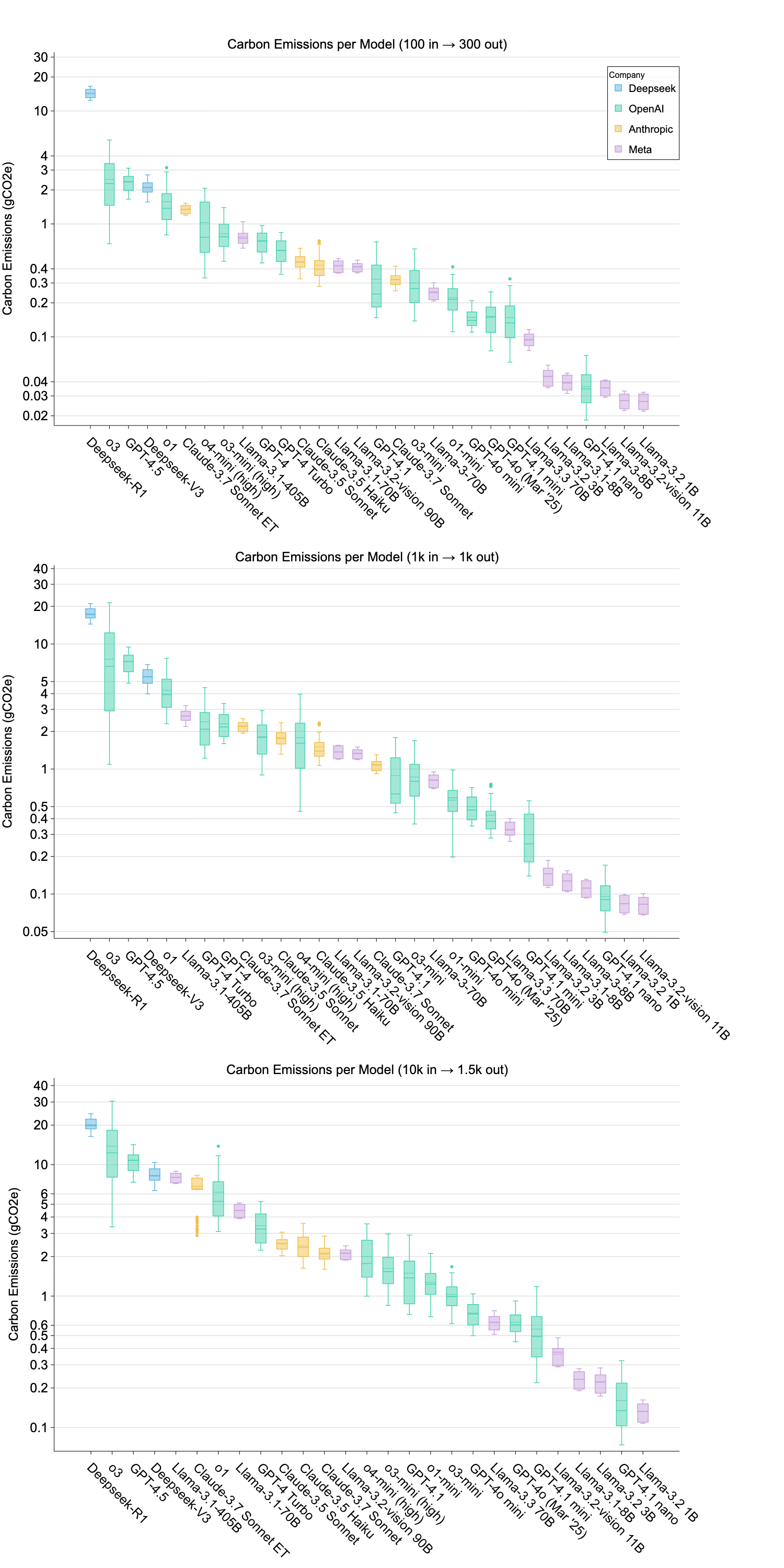
Figure 3: Water consumption per model across three prompt sizes (ml, log-scale).
GPT-4o Case Study
A focused analysis on GPT-4o underscores the cumulative environmental impact of LLM inference at scale. Despite modest per-query resource demands, the aggregated effect translates into significant energy consumption comparable to the annual use of thousands of households, highlighting the necessity for infrastructure-level optimizations.
Discussion
Infrastructure's Role in Sustainability
The paper establishes that infrastructure, including efficient hardware and renewable energy sourcing, profoundly influences AI sustainability. As evidenced, deployment settings can overshadow architectural optimizations, necessitating integrated sustainability strategies that encompass the entire AI lifecycle.
Rebound Effects
Efficiency gains are overshadowed by expanding AI adoption, analogous to the Jevons Paradox—wherein greater efficiency leads to increased resource consumption. This necessitates systemic approaches to balance growing usage with environmental responsibility.
Policy Implications
The study advocates for regulatory thresholds on the environmental footprint of AI models, promoting architectural and infrastructural innovations for sustainable deployments. The integration of transparent reporting mechanisms could bolster environmental accountability.
Conclusion
The paper introduces a robust benchmarking framework for assessing the environmental impact of LLM inference, combining thorough methodology with empirical validation. Although it offers comprehensive insights into AI sustainability, future work should expand into other AI modalities and further refine the attribution of environmental costs to the comprehensive AI lifecycle. As the adoption and complexity of AI systems increase, ensuring sustainable deployment practices is critical to mitigating the potential ecological and societal impacts associated with industrial-scale AI usage.