- The paper presents a novel multi-agent framework that simulates human actor reasoning for authentic speech role-playing.
- It introduces ActorMindBench, a hierarchical benchmark derived from 'Friends' Season 1, capturing utterance, scene, and role nuances.
- Empirical evaluations using RP-MOS show ActorMind significantly improves emotional fidelity and role consistency over baseline TTS and LLM methods.
ActorMind: Emulating Human Actor Reasoning for Speech Role-Playing
Introduction and Motivation
Despite notable advances in role-playing via LLMs and the emergence of strong multimodal models, current work in computational RP remains largely text-centric. Speech, as a primary modality for emotional and attitudinal expression, is essential for authentic RP but relatively underexplored. Addressing the limitations in existing approaches, "ActorMind: Emulating Human Actor Reasoning for Speech Role-Playing" (2604.11103) introduces speech role-playing as a formal setting. The paper proposes two key contributions: ActorMindBench, a hierarchical benchmark facilitating the study of speech RP, and ActorMind, a multi-agent chain-of-thought (CoT) framework modeled after the cognitive processes of professional actors.
ActorMindBench: Hierarchical Speech Role-Playing Benchmark
ActorMindBench is designed to capture the nuance and complexity of authentic role-based speech, structuring the data at three granularity levels: utterance, scene, and role.
ActorMindBench is constructed from Friends Season 1, ensuring persona and dialogue consistency directly from a human-written, domain-stable source. The dataset comprises 7,653 utterances (over 5 hours of labeled audio), 313 scenes, and textual profiles for six main characters, thus providing a rigorous resource for benchmarking models on authentic, scene-aware, and role-conditioned speech RP tasks.
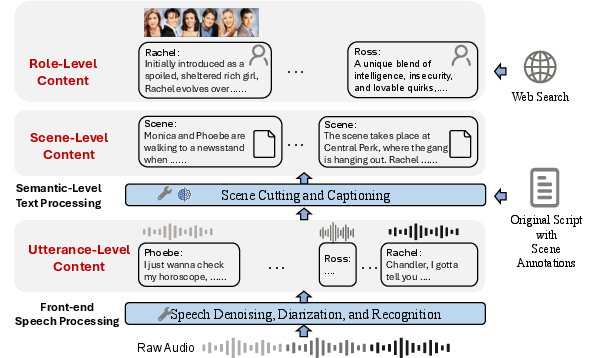
Figure 1: Overview of ActorMindBench with utterance, scene, and role levels, enabling context-rich and hierarchical analysis of speech role-playing.
ActorMind: Multi-Agent Chain-of-Thought Reasoning Architecture
The ActorMind framework operationalizes the process by which human actors parse scripts, perceive emotional context, inject persona, and deliver lines. ActorMind consists of four specialist agents:
- Eye Agent: Reads and memorizes role profiles and scene descriptions.
- Ear Agent: Processes historical spoken dialogue to extract emotional cues using SECAP (Speech Emotion Captioning).
- Brain Agent: Employs LLM-based reasoning to infer the appropriate emotional state for the next utterance, given context seen and heard.
- Mouth Agent: Generates speech for the next line using RAG (retrieval-augmented generation), prompting a TTS system with role- and scene-matched emotional groundings.
The framework is modular and does not require finetuning, leveraging off-the-shelf ASR, SECAP, LLM (Llama 3), and in-context speech synthesis (e.g., IndexTTS) for its implementation.
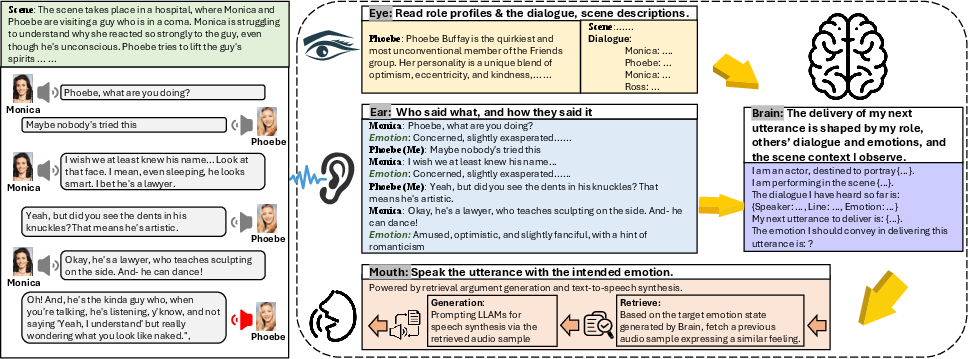
Figure 2: ActorMind system diagram showing the sequential "Eye–Ear–Brain–Mouth" agent pipeline, each emulating components of human actor reasoning in theatrical script delivery.
Evaluation, Results, and Empirical Insights
Evaluation on ActorMindBench employs RP-MOS, an adapted MOS for RP, focusing on exact character delivery and emotional fidelity. Six baseline methods are compared: one LLAM (Qwen_Omni) and five TTS models (CosyVoice, SparkTTS, IndexTTS, YourTTS, F5-TTS).
Key numerical results:
- ActorMind achieves an average RP-MOS of 3.56, exceeding IndexTTS (3.05), F5-TTS (2.87), and all other baselines.
- LLAM baseline (Qwen_Omni) scored consistently at 1.00, unable to align voices with any intended role or deliver expressive, context-aware speech, underscoring the necessity of task-specific frameworks.
- The largest performance drop in ablation studies occurred when role profiles were removed, reaffirming that persona conditioning is critical for speech RP.
- Application of ActorMind as a universal reasoning layer consistently improved TTS model performance on role-playing tasks, with mean qualitative improvement scores exceeding 0.5 across almost all pairings.
Qualitative analyses of generated spectrograms reveal that while TTS baselines generate acoustically valid speech, their prosody and emotional alignment with scene and role are poor compared to ActorMind outputs, which closely match ground truth prosody and role consistency.
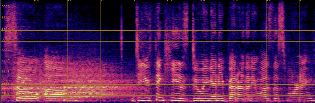
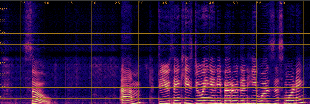
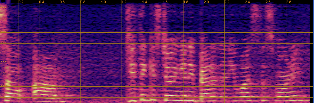
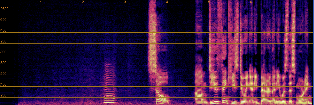
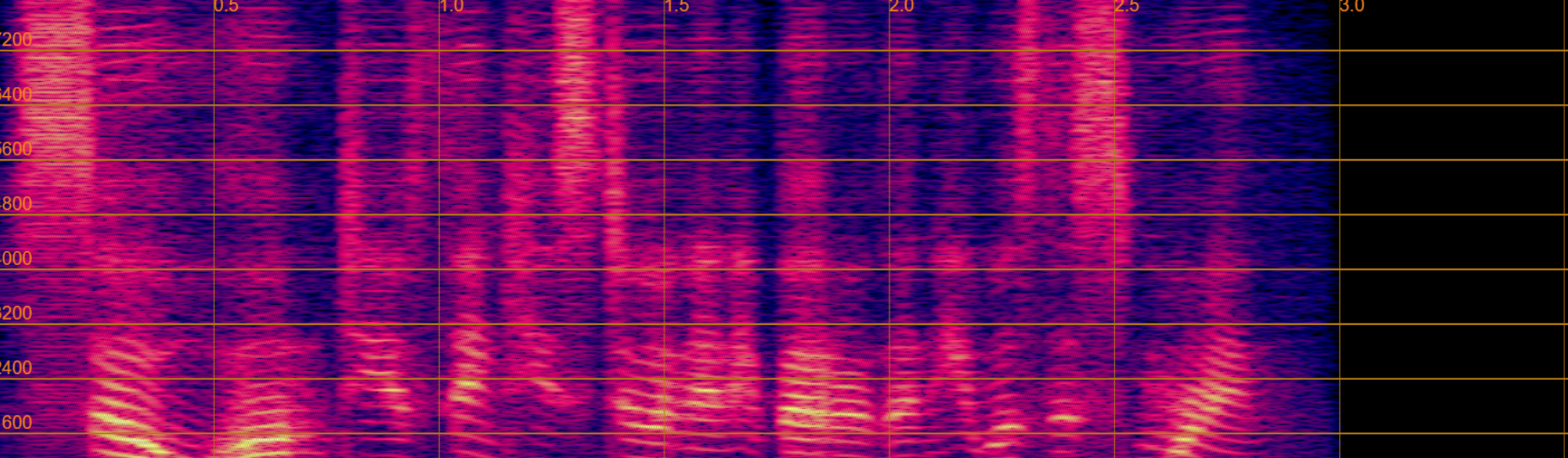
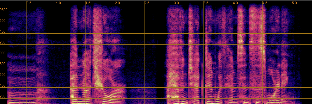
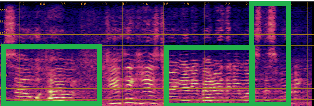
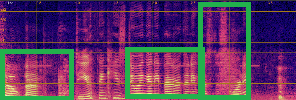
Figure 3: Example CosyVoice baseline spectrogram—shows valid speech generation but suboptimal alignment to target emotional state.
Construction Pipeline and Component Contributions
ActorMindBench's construction involves:
- Speech denoising (Resemble-Enhance), diarization (pyannote-audio), and ASR (Whisper) for utterance segmentation and labeling.
- Automated scene boundary detection and caption generation via Llama 3 for high-quality context summarization.
- Automatic extraction of role profiles from Wikipedia, summarized via Llama 3.
Prompts for scene and role generation and LLM-based emotional reasoning are systematically designed for reproducibility and extensibility.
Ablation findings:
- The Eye Agent (role and scene context) is indispensable for persona conditioning.
- Ear Agent (emotional context extraction) significantly impacts expressive quality.
- Brain Agent (LLM-based emotion reasoning) is central—omission degrades performance substantially and disables RAG-driven expressive synthesis via the Mouth Agent.
Practical and Theoretical Implications
The ActorMind approach provides a scalable methodology for situation-aware, expressively conditioned speech RP, moving beyond static and persona-invariant speech generation. ActorMind establishes a holistic, agent-based abstraction for emulating complex human cognitive strategies in AI-driven multimodal communication.
Practical implications include application in digital assistants, virtual actors, and sociological RP simulations, especially where spontaneous, emotionally-dynamic, and role-adaptive speech is required. ActorMindBench, by utilizing authentic, copyright-safe annotation pipelines, sets a standard for future multimodal RP datasets.

Figure 4: Example from ActorMindBench illustrating the rich, labeled utterance, scene, and role structures extracted from actual sitcom scripts.
Limitations and Directions for Future Research
ActorMindBench content is currently constrained to the sitcom domain ("Friends" Season 1, six main roles), necessitating diversification for broader generalization. The RAG-powered Mouth Agent and LLM-based Brain Agent may further benefit from RL-augmented or fine-tuned emotion control. Extensions should address diverse genres, emotional spectra, and open-domain settings. Integration with more flexible or context-adaptive TTS models could further bridge the personification gap.
Conclusion
ActorMind establishes a principled, human-inspired, multi-agent framework for speech role-playing, directly addressing gaps in spontaneous, persona-consistent, and emotionally driven speech within multimodal AI. ActorMindBench provides a rigorous, hierarchical dataset for systematic evaluation. Empirical evidence on RP-MOS and qualitative metrics demonstrates that ActorMind significantly outperforms LLAM and TTS baselines on authentic RP. This work forms a concrete foundation for scalable, expressive, and generalizable speech role-playing systems in both research and deployable AI contexts.

