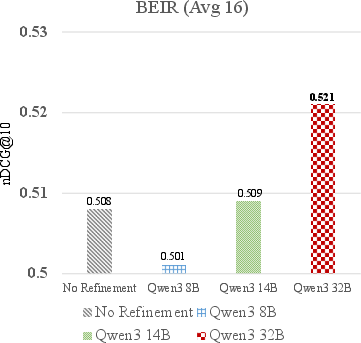
- The paper introduces ARHN, which redefines hard-negative mining by extracting answer snippets to relabel or filter negatives for cleaner supervision.
- It employs a two-stage pipeline that first extracts answer evidence with an open-source LLM and then reranks snippets to optimize label refinement.
- Empirical results demonstrate improved nDCG@10 and OOD generalization across multiple datasets using scalable LLM-driven methods.
Answer-Centric Relabeling of Hard Negatives with Open-Source LLMs for Dense Retrieval
Motivation and Problem Setting
Training neural text retrievers for IR, RAG, and QA tasks typically employs contrastive learning with large triplet collections: a query, a positive passage, and multiple hard negative passages. While hard negatives (difficult non-relevant candidates) are intended to maximize discriminative signal, standard mining techniques frequently yield label contamination—passages annotated as negatives despite actually being relevant or partially answer-supporting. Such false negatives distort the representation geometry, degrade generalization, and are especially problematic for zero-shot and OOD retrieval due to compromised supervision.
The paper proposes ARHN (Answer-centric Relabeling of Hard Negatives), a systematic approach to mining- and label-noise correction that leverages open-source LLMs for answer-aware negative relabeling. ARHN operationalizes two answer-centric interventions: (1) relabeling answer-containing negatives as additional positives and (2) removing ambiguously relevant negatives to construct a cleaner supervision set.
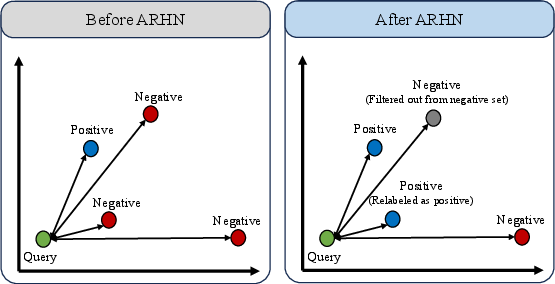
Figure 1: Schematic motivation for ARHN—standard hard-negative mining introduces answer-bearing false negatives which ARHN either relabels as positives or removes as ambiguous negatives.
ARHN Methodology
The ARHN pipeline is two-stage and LLM-driven:
- Stage 1—Answer Snippet Extraction: For each (query, passage) pair, an open-source LLM is prompted to identify a contiguous answer-supporting span as a verbatim snippet, or output
NO_ANSWER if the passage lacks such evidence. This ensures that relabeling is grounded in explicit, document-derived support, reducing LLM hallucinations and focusing solely on extractive evidence.
- Stage 2—Answer-Centric Listwise Reranking: All extracted answer snippets for a given query (including those from positives and hard negatives) are listwise reranked by the LLM according to directness and sufficiency of answer support. Negatives ranked above the original positive's answer are promoted to positives; those ranked below but still containing a snippet are filtered out as ambiguous. Only negatives with
NO_ANSWER are retained as true denials.
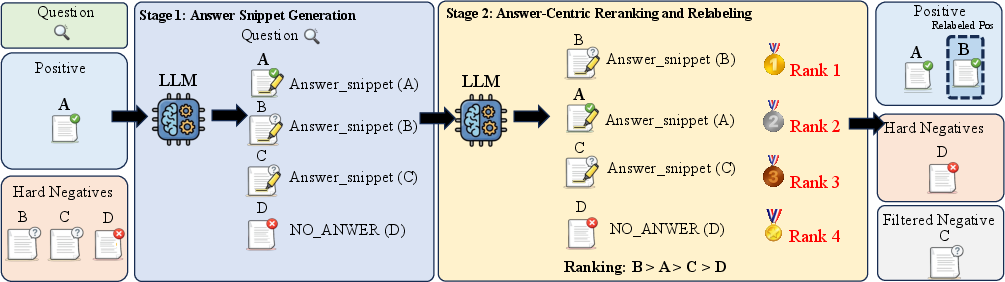
Figure 2: End-to-end ARHN workflow—LLMs extract answer snippets or NO_ANSWER (Stage 1), after which snippets are listwise reranked and labels reconstructed (Stage 2).
This snippet-centric operationalization contrasts with prior passage-level relabeling (which is confounded by shared background and verbose context), yielding more focused and less ambiguous supervision correction.
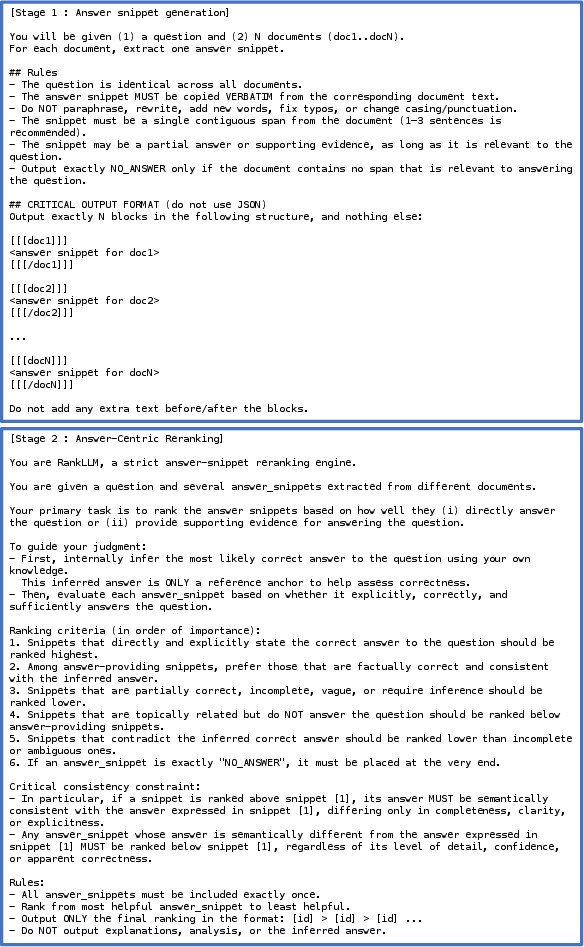
Figure 3: LLM prompt design for snippet extraction and snippet-centric listwise reranking, facilitating interpretable answers and transparent passage assessment.
Empirical Evaluation
The authors benchmark ARHN on BEIR across 16 datasets, employing E5-base and LG-ANNA-Embedding (Mistral-7B) as retrievers. They compare three main variants:
- Relabeling only: promote only,
- Filtering only: remove ambiguous negatives,
- Combined (R+F): both relabel false negatives and filter ambiguous negatives.
Key empirical findings:
Cohen's κ for LLM/human agreement on 500 relabeling cases increases with LLM scale (from 0.31 to 0.37), underscoring the importance of LLM capacity for supervision reliability.
Comparative and Qualitative Analysis
The snippet-centric protocol (ARHN) consistently outperforms passage-centric relabeling (PRHN), especially for OOD datasets and in settings where background context or question ambiguity leads passage-level signals astray. Answer-centric signals are critical for separating partial/ambiguous negatives from true negatives. Qualitative error analysis highlights frequent instances of positive-negative label contamination, often with negatives containing near-identical or highly complementary answer spans to those labeled as positives. ARHN directly mitigates these errors by promoting all answer-supporting evidentiary content to usable supervision and excising misleading negatives.
Practical and Theoretical Implications
Practically, ARHN synthesizes the advantages of answer grounding (extractive answer snippets, not just passage similarity) with cost-effective open-source LLMs, eliminating reliance on black-box commercial APIs. The pipeline is reproducible, high-throughput, and adaptable to arbitrary training sets and retrieval architectures.
Theoretically, the answer-centric paradigm reframes noisy contrastive learning from a passive data selection task to an evidence-centric, listwise signal reconstruction problem, leveraging evolving LLMs as scalable semantic annotators. By dissecting the hierarchy of snippet granularity, ARHN exposes the multifaceted nature of 'relevance' and the brittleness of purely instance-level annotation, especially in low-data or adversarial generalization regimes.
Future Directions
- Open-source LLM scale remains a limiting factor. As open models continue to close the gap with commercial LLMs, further performance and consistency gains are expected.
- There's potential to extend ARHN to non-extractive QA, multi-hop reasoning, and domains where full supervision transfer is intractable.
- Integrating ARHN with dynamic data curation pipelines, continual learning, and in-deployment model monitoring can further tighten the data-model alignment loop.
Conclusion
ARHN delivers a robust framework for the correction of hard-negative label noise in dense text retrieval. By extracting answer snippets and leveraging listwise, answer-centric relabeling and filtering with open-source LLMs, it constructs higher-precision supervision signals, increases OOD generalization, and is largely backbone-agnostic. The results substantiate that principled answer-centric supervision—rather than heuristic instance-level mining—should form the foundation for future large-scale IR and RAG retrieval pipelines (2604.11092).