Ruling Out to Rule In: Contrastive Hypothesis Retrieval for Medical Question Answering
Published 6 Apr 2026 in cs.IR, cs.AI, and cs.CL | (2604.04593v1)
Abstract: Retrieval-augmented generation (RAG) grounds LLMs in external medical knowledge, yet standard retrievers frequently surface hard negatives that are semantically close to the query but describe clinically distinct conditions. While existing query-expansion methods improve query representation to mitigate ambiguity, they typically focus on enriching target-relevant semantics without an explicit mechanism to selectively suppress specific, clinically plausible hard negatives. This leaves the system prone to retrieving plausible mimics that overshadow the actual diagnosis, particularly when such mimics are dominant within the corpus. We propose Contrastive Hypothesis Retrieval (CHR), a framework inspired by the process of clinical differential diagnosis. CHR generates a target hypothesis $H+$ for the likely correct answer and a mimic hypothesis $H-$ for the most plausible incorrect alternative, then scores documents by promoting $H+$-aligned evidence while penalizing $H-$-aligned content. Across three medical QA benchmarks and three answer generators, CHR outperforms all five baselines in every configuration, with improvements of up to 10.4 percentage points over the next-best method. On the $n=587$ pooled cases where CHR answers correctly while embedded hypothetical-document query expansion does not, 85.2\% have no shared documents between the top-5 retrieval lists of CHR and of that baseline, consistent with substantive retrieval redirection rather than light re-ranking of the same candidates. By explicitly modeling what to avoid alongside what to find, CHR bridges clinical reasoning with retrieval mechanism design and offers a practical path to reducing hard-negative contamination in medical RAG systems.
The paper’s main contribution is the introduction of a dual-hypothesis modeling technique that explicitly suppresses hard negatives in medical question answering.
It leverages cosine similarity scoring between target and mimic hypotheses, demonstrating up to a 10.4% improvement in retrieval accuracy across benchmarks.
The method reduces LLM calls and token use, making it a cost-efficient solution for enhancing clinical decision support systems.
Contrastive Hypothesis Retrieval for Medical Question Answering
Motivation and Problem Statement
Hard-negative contamination is a principal bottleneck for retrieval-augmented generation (RAG) in medical QA. Dense retrievers frequently surface documents that are superficially relevant but clinically distinct, jeopardizing downstream LLM answer fidelity. Conventional query-expansion methods, such as hypothetical document generation (HyDE), corpus-steered expansion (CSQE), and iterative feedback-driven reforms (ThinkQE), improve recall and coverage but do not actively suppress misleading retrievals. As a result, medically plausible mimics remain a persistent source of error, fundamentally limiting gains from RAG in high-stakes clinical contexts.
Contrastive Hypothesis Retrieval: Mechanism and Workflow
Contrastive Hypothesis Retrieval (CHR) leverages dual-hypothesis modeling, formally introducing an explicit negative constraint during query construction.
CHR proceeds as follows:
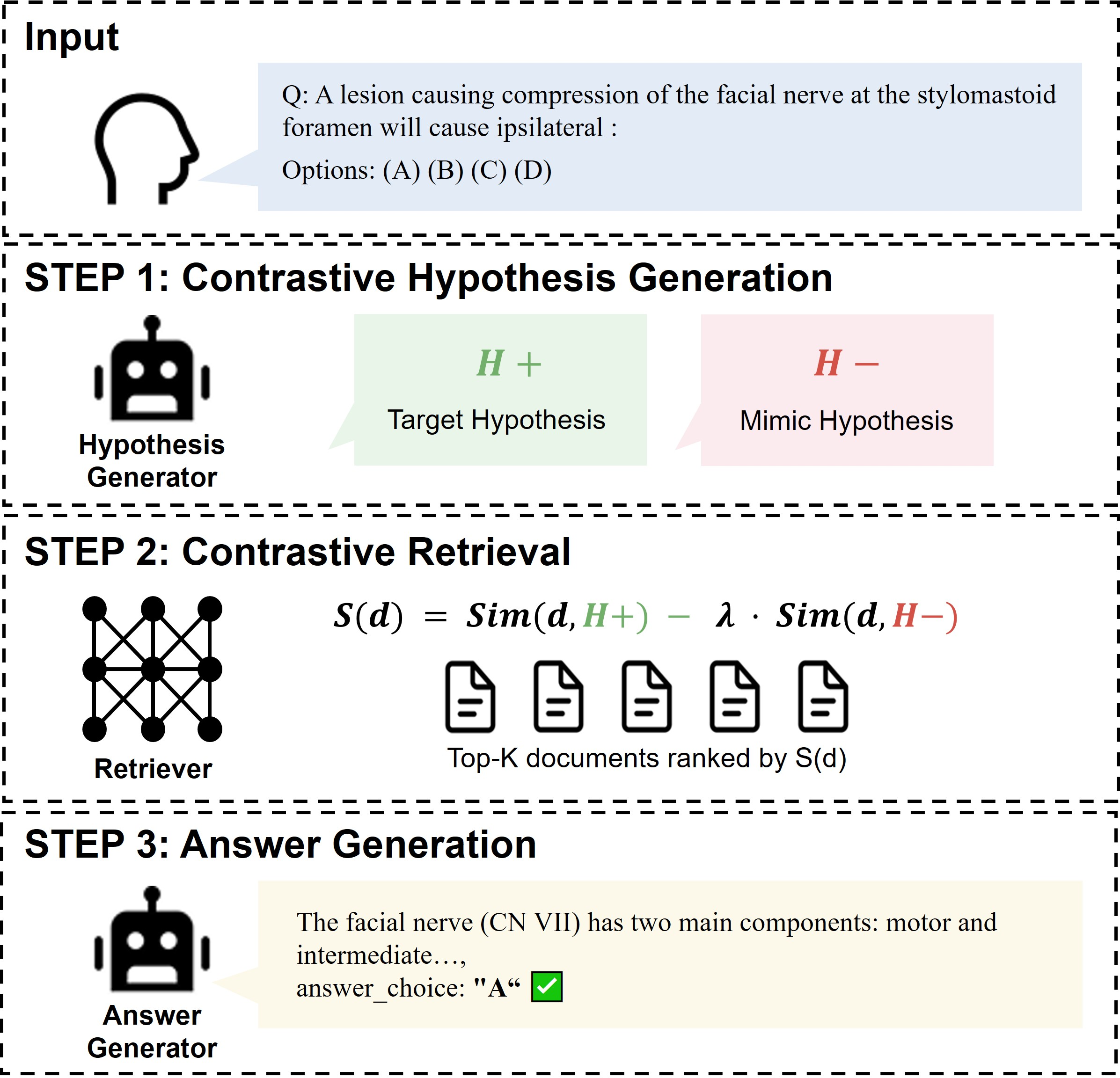
Contrastive Hypothesis Generation: For each clinical multiple-choice question, a LLM is prompted to produce both a target hypothesis (H+), capturing the pathophysiology and distinctive features of the correct answer, and a mimic hypothesis (H−), representing the most plausible confounder or hard negative. Both are synthesized in a single, structured JSON output.
Contrastive Document Scoring: Each candidate document d is scored as S(d)=Sim(d,H+)−λ⋅Sim(d,H−), where cosine similarity measures are computed in the retrieval embedding space and λ is a tunable weight (empirically set to 1.0). The highest scoring documents are passed forward.
Answer Generation: The original question, options, and the retrieved evidence are sent to a downstream answer generator LLM.
Figure 1: The CHR pipeline: structured dual-hypothesis generation, contrastive scoring, and evidence-driven LLM answer synthesis.
This structure directly operationalizes differential diagnosis reasoning: clinicians aim not only to "rule in" but to rigorously "rule out" plausible mimics. The contrastive vector (H+−λH−) geometrically shifts the query away from the semantic basin of the most dangerous hard negative, countering bias toward frequent misleading narratives in the corpus.
Empirical Evaluation
CHR is benchmarked across three medical QA datasets (MMLU-Med, MedQA, BioASQ Y/N) and three generator architectures (Llama-3-8B, Qwen2.5-7B, Gemma-2-9B). All retrieval models utilize MedCPT over the MedCorp biomedical corpus, with fixed LLMs (Qwen2.5-72B) handling query expansion for all baselines to isolate retrieval dynamics.
Key results:
CHR achieves the highest accuracy in all 18 (dataset × generator) head-to-head evaluations.
Maximum observed improvement: +10.4% (BioASQ, Qwen2.5-7B) over next-best baseline.
For MedQA, CHR with Llama-3-8B reaches 51.5%, at least +5% over all alternatives.
Robustness: Baselines such as HyDE occasionally underperform Standard RAG due to the lack of hard negative suppression; CHR uniformly outperforms all.
Importantly, retrieval shift analysis (cases where CHR answers correctly and HyDE fails) shows that in 85.2% of these 587 instances, CHR's top-5 retrieved documents have zero overlap with HyDE—strong evidence that CHR accesses distinct, target-aligned evidence rather than trivial reranking.
Efficiency and Practicality
CHR is markedly efficient. It requires only one LLM call per query to generate both hypotheses, reducing token consumption by nearly an order of magnitude compared to HyDE and by several-fold compared to other expansion baselines. This confers substantial inference cost advantages, essential for large-scale deployment in clinical environments.
Mimic Hypothesis Quality and Retrieval Dynamics
Physician-mediated annotation of H− shows a positive correlation between the clinical plausibility of the mimic and system accuracy: when H− zeroes in on the key confounder, performance peaks (66.7% with "Excellent" mimics vs. 37.5% for "Poor" cases). Poor performance arises primarily when the mimic hypothesis is semantically parallel or paraphrastic to the target, resulting in insufficient contrastive signal and retrieval collapse.
Case studies further illustrate the discriminative utility of CHR. In an MMLU-Med scenario involving amantadine (an antiviral repurposed for parkinsonism), traditional retrieval is confounded by literature on antiviral-induced parkinsonian symptoms. CHR’s mimic hypothesis successfully suppresses misleading antiviral→side effect narratives, elevating the correct evidence for amantadine's clinical use.
Limitations
CHR’s principal vulnerability is the semantic co-occurrence collapse: when corpus realities dictate that H+ and H− are heavily entangled (e.g., Th2 cytokines IL-4 and IL-13), contrastive subtraction may indiscriminately penalize target-relevant passages. Error analysis attributes 23% of system failures to this issue. Dynamic adjustment of H−0 based on the cosine similarity of hypotheses, or pre-emptive mimic filtering, are promising mitigations.
Implications and Future Prospects
CHR demonstrably elevates the reliability of RAG-based clinical QA by encoding explicit negative constraints, a concept that generalizes to any high-ambiguity, expert-critical retrieval regime. Its efficiency and plug-and-play generative interface (fixed retrievers, black-box generators) facilitate straightforward integration with emerging LLM architectures and expanding biomedical corpora.
Long-term, deployment of contrastive query expansion frameworks like CHR will be instrumental for trustworthy AI decision support, especially as LLM-centric workflows transition to real-world healthcare delivery. Downtuning of mimic suppression and extension to open-ended generative tasks are natural next steps. Results also suggest broader utility for legal, scientific, or other specialized RAG contexts where surface-level overlap is a potent source of retrieval error.
Conclusion
CHR combines clinical reasoning with neural retrieval, operationalizing explicit mimic suppression to eliminate hard negatives from medical QA. This leads to consistent, robust gains over the state of the art in both accuracy and efficiency, fundamentally redirecting evidence selection within RAG systems. Further investigation into adaptive contrastive control and cross-domain applications is warranted to realize the full potential of this approach.