- The paper presents a novel STGV architecture that decouples static background and dynamic motion using dual spatio-temporal hash encoding.
- It employs a Key Frame Canonical Initialization strategy to maintain spatial coherence and enhance Gaussian-based video reconstruction.
- Experimental results demonstrate state-of-the-art performance with improved PSNR, robust compression, and effective inpainting and super-resolution.
Spatio-Temporal Hash Encoding for Gaussian-Based Video Representation
Introduction
The paper "STGV: Spatio-Temporal Hash Encoding for Gaussian-based Video Representation" (2604.10910) addresses crucial limitations in current explicit video representation paradigms based on 2D Gaussian Splatting (2DGS). State-of-the-art 2DGS methods for video generally fail to disentangle static background cues from dynamic content, often resulting in misrepresentation of motion patterns, blurred background, and reduced detail fidelity. The authors propose a novel Spatio-Temporal Gaussian Video (STGV) architecture, which explicitly decomposes video volume information using learnable 2D spatial and 3D temporal hash encodings. This approach aims to decouple static and dynamic content, thereby enabling accurate frame-wise deformation estimation and improved video reconstruction quality.
Methodology
2D Gaussian Splatting and Video Representation Pipeline
STGV leverages 2DGS, representing each frame as a set of 2D Gaussian primitives parameterized by spatial location, color, and a covariance matrix. The pipeline operates on short Groups of Pictures (GoPs), and for each GoP, a two-stage training regime is applied: first, a canonical representation is constructed via coarse initialization; then, Gaussian attributes are deformed per-frame via a learned deformation field.
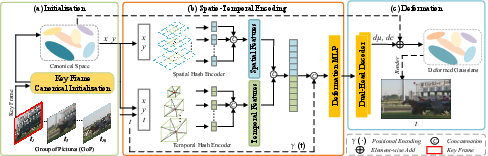
Figure 1: Overview of STGV, including key frame canonical initialization, spatio-temporal hash encoding, and frame-specific Gaussian attribute deformation and rendering.
Spatio-Temporal Hash Encoding
To address the entanglement of static and dynamic information, STGV introduces a dual-branch hash encoding scheme. The static path employs a multi-resolution 2D spatial hash encoder to preserve background detail invariant over time. The dynamic path uses a 3D temporal hash encoder to learn time-varying motion patterns. Both branches extract disentangled features, which are subsequently concatenated and processed via a dual-head MLP decoder predicting both geometric and appearance deformations for the Gaussian primitives.
This factorized encoding directly mitigates spatio-temporal feature collisions that occur in plane-based approaches, which tend to interleave features of static and moving regions.
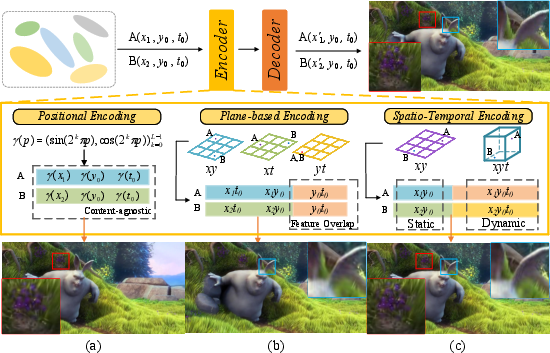
Figure 2: Comparison of different deformation field parameterizations. The proposed spatio-temporal hash encoding better captures both motion and background structure versus implicit and plane-based alternatives.
Key Frame Canonical Initialization
Standard approaches initialize canonical Gaussian space from multiple frames, which induces spatial incoherence due to misaligned dynamic motion and camera movement, leading to blending artifacts and degraded geometry. STGV introduces a Key Frame Canonical Initialization (KFCI) strategy, employing the first frame of each GoP as the canonical anchor for Gaussian primitives. This eliminates the averaging effect and provides a spatially consistent and detailed foundation, facilitating subsequent deformation modeling.

Figure 3: Comparison between Key Frame Canonical and Multi-frame Initialization highlights sharper and more coherent geometry for the KFCI strategy.
Experimental Results
Quantitative and Visual Comparison
Extensive evaluation on UVG, DAVIS, and Bunny datasets demonstrates that STGV surpasses both INR-based (e.g., SIREN, NeRV, E-NeRV, HNeRV) and Gaussian-based baselines (e.g., D2GV, GaussianVideo, GSVR). The method achieves an average PSNR improvement of +0.98 dB relative to prior Gaussian-based approaches on UVG, with competitive MS-SSIM and rapid training and inference times (decoding up to 625 FPS).
Visual comparison exhibits consistently sharper foreground/background separation and crisper motion, with significantly reduced ghosting and texture blurring in regions of motion.

Figure 4: Visual comparison on "yachtride," "cows," and "boat" videos, where STGV with spatio-temporal hash encoding and KFCI outperforms other methods in detail and temporal coherence.
Auxiliary Tasks: Compression, Inpainting, and Super-Resolution
STGV delivers favorable rate-distortion tradeoffs for video compression by leveraging quantization-aware fine-tuning of the canonical Gaussians and deformation field parameters, outperforming competing explicit models.
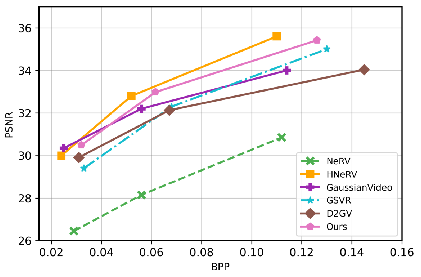
Figure 5: Compression results on the Bunny dataset confirm superior rate-distortion performance of the proposed methodology.
In video inpainting tasks, STGV accurately reconstructs masked regions without introducing artifacts, leveraging spatio-temporal encoding to exploit both spatial coherence and dynamic context.

Figure 6: Inpainting visualizations demonstrate artifact-free region restoration, outperforming competing architectures.
Furthermore, the explicit and continuous nature of 2DGS allows for effective spatial interpolation and direct rendering at higher resolutions, providing robust scaling without retraining.

Figure 7: Spatial interpolation results on Beauty and Honeybee videos, highlighting preservation of fine details.
Ablations and Hash Encoding Analysis
Ablation studies isolate the benefit of KFCI, static/dynamic hash encoding, and their combination. Full STGV achieves state-of-the-art reconstruction under all settings, whereas removing either hash path or KFCI causes quality degradation, underpinning the necessity of their combined use.

Figure 8: Static vs. dynamic hash encoding comparisons highlight that only the dual-branch approach simultaneously preserves static background and dynamic motion quality.
Assessment across Gaussian primitive count, denoising, and other attributes confirm STGV’s robustness, adaptability, and efficiency.
Theoretical and Practical Implications
The explicit disentanglement of static and dynamic cues in the video volume via hash encoding offers a principled solution to spatio-temporal mixing, which has broader implications for neural video representations. The acceleration in training and inference beyond what is achievable by conventional INRs and prior explicit models expands the practical feasibility of real-time video compression and streaming, high-fidelity synthesis, and video editing at scale.
On the theoretical front, the multiresolution hash encoding paradigm allows for compact, scalable storage, and direct indexing, which is naturally extensible to other image and video synthesis tasks—such as video super-resolution, view synthesis, or even generative modeling. However, the high-frequency bias of hash encodings may introduce overfitting risks in the presence of noise, suggesting future work on incorporating smoothness priors or noise-robust regularization.
Future Directions
Conclusion
STGV presents a principled, high-fidelity and efficient architectural framework for explicit video representation. Through spatio-temporal hash encoding and robust spatial initialization, it cleanly disentangles static and dynamic cues, resulting in improved fidelity for both reconstruction and auxiliary tasks. The approach opens new possibilities for scalable video generation, compression, and interactive editing, and sets a foundation for further research in neural visual representation with explicit, compositional priors.
