Published 12 Apr 2026 in cs.LG, cs.AI, cs.DS, math.ST, and stat.ML | (2604.10857v1)
Abstract: Diffusion models generate samples by iteratively querying learned score estimates. A rapidly growing literature focuses on accelerating sampling by minimizing the number of score evaluations, yet the information-theoretic limits of such acceleration remain unclear. In this work, we establish the first score query lower bounds for diffusion sampling. We prove that for $d$-dimensional distributions, given access to score estimates with polynomial accuracy $\varepsilon=d{-O(1)}$ (in any $Lp$ sense), any sampling algorithm requires $\widetildeΩ(\sqrt{d})$ adaptive score queries. In particular, our proof shows that any sampler must search over $\widetildeΩ(\sqrt{d})$ distinct noise levels, providing a formal explanation for why multiscale noise schedules are necessary in practice.
The paper establishes a formal lower bound of Ω(√d) on query complexity for diffusion sampling under polynomially accurate score oracles.
It uses a hypothesis testing framework and synthetic experiments to show how the informative smoothing window scales as 1/√d.
The study highlights an intrinsic computational barrier in high-dimensional score-based modeling, justifying the necessity of multiscale noise schedules.
Query Lower Bounds for Diffusion Sampling
Introduction and Context
The paper "Query Lower Bounds for Diffusion Sampling" (2604.10857) addresses a foundational question in the theory of score-based generative modeling: what are the intrinsic limits on sampling efficiency in high-dimensional diffusion models when only given oracle access to polynomially accurate smoothed score estimates? Most advances in diffusion models have focused on accelerating sampling—reducing the number of neural network calls required for high-quality sample generation. While upper bounds exist for the query complexity of specific algorithms, a comprehensive information-theoretic lower bound applicable to all possible algorithms was missing. This work closes that gap by formally establishing dimension-dependent lower bounds that apply under standard oracle and regularity assumptions.
Main Theoretical Results
Under the assumption that the sampler can only interact with the target distribution via adaptive queries to an oracle that provides Lp-accurate estimates of the Gaussian-smoothed score function, the authors prove a lower bound of Ω(d) on the number of adaptive queries required to generate a non-trivial (constant TV-error) sample in d-dimensional space. This holds even with favorable conditions: the existence of bounded targets with added noise and oracles with accuracy guarantees matching those used in practice. Notably, this lower bound remains far from the existing upper bounds of O(d) iterations for standard discretizations (e.g., DDPM, DDIM), but rules out the possibility of constant or polylogarithmic query complexity in the worst case.
The formal statement of the main theorem is that, under standard bounded-support-plus-noise and Lp-oracle assumptions, any diffusion sampler achieving TV error below $0.99$ must make Ω(d) queries (where Ω hides logarithmic factors). Thus, for high-dimensional generative sampling, computational cost must scale at least sublinearly in the dimension.
Additionally, the lower bound extends (albeit weakened) to stronger tail assumptions: with subexponential error tails in oracle responses, at least Ω(d1/4) queries remain necessary.
Proof Overview and Hard Instance Construction
The proof reduces lower bounding query complexity to a hypothesis testing problem: the authors design a 'hard family' of target distributions consisting of mixtures of numerous well-separated modes ("codebooks"), each convolved with a small Gaussian. Oracle queries at a fixed noise level are informative only if the smoothing matches a narrow band where the information about the hidden multimodal structure is not obscured by the convolution. Outside this band, the answer can be essentially the same as for a null distribution and remain within the error guarantee.
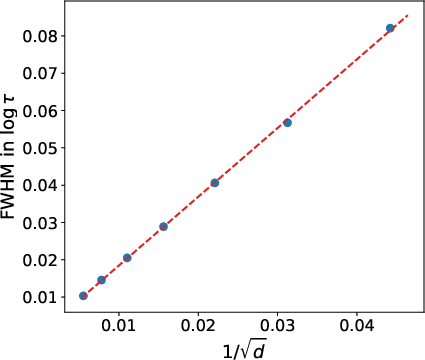
Crucially, the informative window—the set of noise parameters where queries are useful—shrinks as dimension increases. The width of this window is predicted (and verified by synthetic experiments) to scale as 1/d, requiring the sampler to scan through Ω(d)0 distinct smoothing levels before reliably producing a sample that is not close to null. This geometric mechanism directly yields the dimension-scaling of the lower bound.
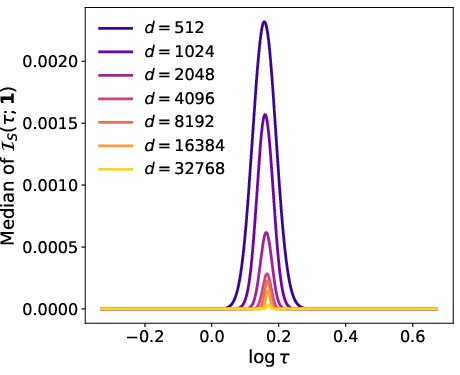
Figure 1: Median of the shell-resolved proxy for Ω(d)1 shows the informative smoothing window narrows proportionally to Ω(d)2, confirming the theoretical prediction.
Connection to Practical Algorithms and Model Classes
The oracle model analyzed in the paper abstractly but accurately captures the information structure available during inference for standard diffusion samplers. The result applies to both SDE/ODE-based solvers (DDPM, DDIM, PNDM, DPM-Solver, DEIS, UniPC, EDM, etc.) and to flow-matching and rectified flow approaches under linear Gaussian interpolation, because all such methods reduce, via reparameterization, to repeated evaluation of a score-like vector field at chosen Ω(d)3.
Notably, the lower bound applies regardless of solver order, discretization, or adaptive schedule, as long as the only access to the target at inference is via these oracle queries. The information-theoretic barrier therefore explains why multiscale noise schedules—in which scores are queried at a progressively finer sequence of noise levels—are empirically observed and necessary.
Implications, Contradictions, and Tightness
This work's lower bound provides a formal theoretical explanation for the necessity of nontrivial iteration counts in practical diffusion samplers. The implication is that, independent of improvements in discretization order or step-size selection, there exists an inescapable informational bottleneck caused by the geometric nature of high-dimensional smoothing. Any algorithm seeking to leverage only the information provided by score queries must confront this.
However, there remains a notable gap between this lower bound (Ω(d)4) and the best upper bounds (Ω(d)5). The theoretical challenge is then two-fold: (1) determine whether one can push the lower bound further (for example, obtaining linear dependence), or (2) construct algorithms that break the current upper bounds, perhaps by exploiting further regularity or structure not captured by the worst-case ensemble.
Empirically, some datasets permit high-quality generation in far fewer iterations, hinting that real-world distributions may possess additional low-dimensional (or otherwise tractable) structure. Future research may focus on identifying and exploiting such structure to bridge between worst-case and typical-case behavior.
Synthetic Experimentation and Verification
The paper supports its theoretical claims via carefully designed synthetic experiments. For the prototypical 'hard family', Figure 1 visualizes the shrinking of the informative scale window for the Fisher signal as Ω(d)6 grows. The experiments corroborate the theoretical analysis, showing the informative window's width in Ω(d)7 space decreases as Ω(d)8, which operationally translates to the need for many distinct queries to locate the right scale as dimension increases.
Theoretical and Practical Consequences
Practically, the result signals that any computationally efficient score-based model, unless fundamentally altering the inference primitive or tapping into more global knowledge than can be expressed in local score queries, will not asymptotically evade this sublinear-in-Ω(d)9 complexity. This result thereby undercuts hopes for truly constant-iteration or "single-step" samplers in the general (worst-case) setting.
Theoretically, the work suggests interesting directions: closing the dependence gap, extending to different oracle models (other smoothing or coupling strategies), or quantifying when the underlying structure of real datasets allows for dramatically faster generation.
Conclusion
This paper provides the first information-theoretic lower bound on the query complexity of diffusion sampling, showing that dimensionality imposes a genuine computational barrier: any sampler relying solely on repeated, polynomially accurate smoothed score queries must use at least d0 distinct noise levels to reliably sample from worst-case smooth high-dimensional distributions. This fundamentally explains and justifies, at the oracle model level, the empirically essential role of multiscale noise schedules, and sets an explicit target for both lower- and upper-bound improvements in future research. The result thus constitutes an essential step in formalizing the limitations of generative diffusion models in high dimensions.
Figure 1: Median of the shell-resolved proxy for d1 across varying d2 demonstrates concentration narrowing, with width scaling as d3, thereby confirming the theoretical lower bound on informative smoothing windows.