- The paper introduces a dedicated Polish tokenizer that reduces token fertility from 3.22 to 1.62, nearly doubling effective context utilization.
- It employs a multi-stage pretraining regimen using the FOCUS framework to transfer embeddings and mitigate catastrophic forgetting.
- The approach achieves improved inference speed and efficiency through structured pruning and knowledge distillation while preserving robust multilingual performance.
Optimizing Polish Language Modeling via Dedicated Tokenization in Bielik v3 7B and 11B
Introduction
The Bielik v3 PL model series introduces significant advances in language-specific adaptation of LLMs for Polish, focusing primarily on tokenizer redesign and efficient vocabulary adaptation. This work targets the inefficiencies that arise from employing universal multilingual tokenizers in morphologically rich languages. By developing and integrating a Polish-optimized tokenizer for the 7B and 11B parameter Bielik v3 models, the authors establish new standards for monolingual performance and token efficiency. The results substantiate the claim that high linguistic and reasoning capabilities in Polish can be obtained without sacrificing cross-lingual performance or resource constraints.
Model Architecture and Compression
Bielik v3 PL follows the Transformer backbone, inheriting modern architectural innovations from the Mistral 7B series. These include Grouped-Query Attention (GQA) for memory-efficient self-attention and Rotary Positional Embeddings (RoPE) for enhanced positional encodings at long context lengths (up to 32k tokens). The 11B variant leverages depth upscaling—from a 32 to a 50-layer Transformer—achieving increased representational capacity while maintaining deployment compatibility with 24 GB GPUs. The corresponding 7B "Minitron" variant is obtained through structured pruning and knowledge distillation from the 11B model, matching 90% of the original model's accuracy at 50% faster inference, illustrating optimal compression-to-performance tradeoffs.
Dedicated Polish Tokenizer: Motivation, Design, and Empirical Impact
The core contribution lies in replacing the universal Mistral-based tokenizer with a vocabulary tailored to Polish's morphological complexity. The redesigned tokenizer maintains a ~32,000-token vocabulary to decouple improvements from mere increases in embedding capacity. Token segmentation is calibrated for Polish, including refined treatment of diacritics and special characters. The empirical consequences are substantial: the Polish token-per-word (fertility ratio) is reduced from 3.22 (universal tokenizer) to 1.62, nearly doubling effective Polish context utilization and accelerating inference, while retaining non-Polish text coverage.
Embedding Initialization and Catastrophic Forgetting Mitigation
Transitioning a pretrained model to a new tokenizer induces catastrophic forgetting risk. The FOCUS framework was selected for embedding transfer, outperforming frequency-based vocabulary transfer, WECHSEL, model-aware approaches like MATT, OFA, and RAMEN on both short-term loss and downstream evaluation. FOCUS leverages semantically-aware sparse linear combinations to initialize target vocabulary embeddings, producing stability and alignment with prior representations in continued pretraining.
Curriculum: Multi-Stage Pretraining and Alignment
A two-stage pretraining regimen is deployed. The initial phase freezes all but the input/output embeddings and two transformer layers at each boundary, updating only 4 of 50 layers and the embeddings on 4B tokens. This boundary adaptation preserves model internals while enabling latent alignment with the new token segmentation. The second stage fully unfreezes the model for 16B tokens, permitting global adaptation.
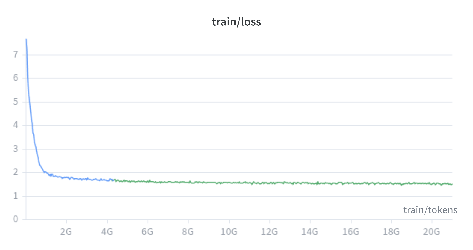
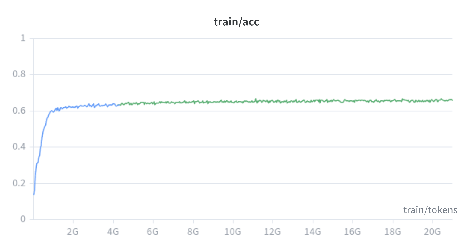
Figure 1: Training loss for Bielik 11B v3 PL over tokens during multi-stage adaptation validates successful embedding and vocabulary transfer.
Following pretraining, the post-training protocol is preserved from the original pipeline: supervised fine-tuning (SFT) on high-quality Polish and English instructions, direct preference optimization (DPO-P) for preference-aligned response calibration, and Group Relative Policy Optimization (GRPO) using verifiable reward signals in math and reasoning subdomains. This alignment stack ensures maintenance of conversational, factual, and reasoning skills.
Comprehensive Benchmark Evaluation
Evaluation spans Polish-centric and multilingual benchmarks:
- Open PL LLM Leaderboard: Bielik-PL-11B-v3.0-Instruct achieves a 5-shot average of 64.11, only 1.82 below the original tokenizer baseline, outperforming similarly-sized and larger models.
- Polish EQ-Bench: Bielik-PL-11B-v3.0-Instruct scores 71.15, essentially matching the original model (71.20), and exceeding several 70B+ parameter baselines.
- CPTUB: The PL variant surpasses the original (3.80 vs 3.73 overall), with particularly strong implicature and phraseology comprehension.
- Polish Medical Leaderboard: A domain-specific average of 48.42% places it above comparable instruction-tuned models at equivalent scale.
- Open LLM Leaderboard (English): At 71.49, PL tokenizer checkpoints demonstrate near-parity with original-tokenized equivalents.
- INCLUDE-base-44: Cross-European language performance remains robust, with Polish-specific scores exceeding 64 on the 11B PL variant.
- Belebele and FLORES: While there is a minor regression in multilingual scores, Polish language accuracy remains high (e.g., 81.22 on Belebele Polish subset, 17.58–18.07 BLEU on FLORES).
These outcomes empirically validate the central claim: dedicated tokenization provides substantial efficiency and competitive accuracy for the target language, while the overall model remains effective on English and related European languages.
Practical and Theoretical Implications
This work demonstrates a fully reproducible pipeline—FOCUS-based embedding transfer, multi-stage partial-to-global pretraining, and consistent alignment protocols—for efficient monolingual specialization of LLMs. Models optimized through this process can maximize effective context, accelerate inference, and reduce computational cost for language-specific applications, a crucial property for underrepresented linguistic communities and resource-constrained deployment.
From a theoretical standpoint, the results confirm that catastrophic forgetting during tokenizer transition can be both predicted and controlled with appropriately structured curricula and embedding initialization. Furthermore, strong cross-lingual robustness is preserved even in monolingual-optimized embeddings, arguing against the assumption that tokenization changes inevitably degrade multilingual capabilities.
Directions for Future Research
Further research could focus on dynamic vocabulary adaptation, task-adaptive tokenizer selection, and parameter-efficient adapter methods to enhance specialization with minimal retraining. Extending this pipeline to other under-resourced morphologically complex languages should empirically validate generality. Additionally, meta-learning approaches for automatic curriculum scheduling during tokenization transitions warrant exploration.
Conclusion
The Bielik v3 PL series delivers state-of-the-art performance in Polish language modeling by combining a dedicated tokenizer with an advanced embedding transfer and adaptation curriculum. Empirical results show only minimal trade-off in multilingual and English capabilities compared to substantial gains in token efficiency, supporting broad deployment and further research into adaptive tokenization for LLMs targeting morphologically rich, low-resource languages (2604.10799).

