- The paper introduces a framework that leverages ML-generated proxies to partially identify econometric parameters by linking downstream and validation data via unconditional optimal transport.
- It employs sample splitting, cross-fitting, and Kantorovich duality in a convex program, ensuring effective inference even with nonclassical measurement errors.
- Empirical simulations demonstrate that stratification and increasing sample sizes in downstream and validation datasets yield tighter confidence bounds, enhancing practical reliability.
Econometric Inference with Machine-Learned Proxies: Partial Identification via Data Combination
Motivation and Framework
Empirical analyses in economics increasingly leverage ML algorithms to generate proxies for latent variables from complex, high-dimensional, or unstructured datasets. Standard practice involves an upstream ML prediction step—mapping X (e.g., text/images) to a proxy Z^ for unobserved targets Z—followed by downstream econometric inference on parameters θ0 in models such as E[q(W,Z;θ0)]=0. However, naive plug-in, treating Z^ as Z, fails to address measurement error and generated regressors, leading to biased estimation and invalid inference. The problem intensifies given: (i) the analytical intractability of modern ML methods (unknown rates, lack of consistency); (ii) nonclassical measurement error due to X potentially encoding information about W, resulting in Z−Z^ dependent on Z^0, correlated with Z^1, or even endogenous.
The paper proposes an econometric framework that exploits access to two datasets:
- The downstream sample with Z^2 using fixed ML rule Z^3.
- The auxiliary validation sample with Z^4, facilitating evaluation of Z^5.
Z^6 is reframed not as a noisy substitute, but as a linking variable bridging information between the samples, allowing recovery of Z^7 and yielding partial identification for Z^8 without restrictive structural or asymptotic assumptions. This approach is robust to proxy quality: informative proxies tighten the identified set, but validity persists even with crude proxies, reflecting the genuine informativeness of the proxy wrt Z^9.
Identification via Unconditional Optimal Transport
Sharp partial identification is achieved through an unconditional optimal transport (OT) characterization. Rather than solving a continuum of conditional OT problems (as in Fan, 2025), OT is formulated on the unconditional joint distributions: the method links Z0 from downstream and Z1 from validation without direct observation of Z2.
Given marginal distributions Z3 and Z4 for Z5 and Z6, the identified set is:
Z7
where Z8 is the Fréchet class of joint distributions with these marginals. The linking constraints (i.e., Z9, θ00) are enforced via moment conditions in an expanded OT formulation.
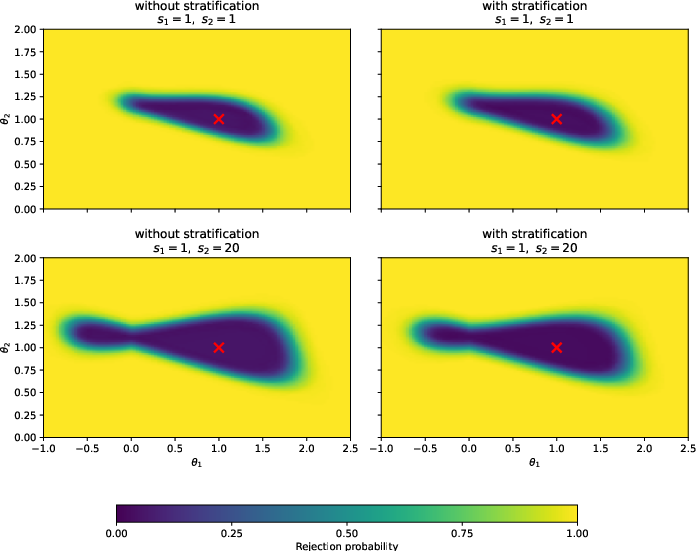
Figure 1: Effect of stratification on confidence sets; tighter bounds when stratifying on informative variables.
This reformulation eliminates the need for estimation of conditional distributions or solving transport problems for each θ01, enabling practical implementation even when θ02 is continuous or high-dimensional. The identified set remains sharp (cannot be further tightened under the data and assumptions).
Inference: Cross-Fitting and Kantorovich Duality
Inference is nonstandard due to non-classical asymptotic behavior in OT and the outer max-min over test functions. The procedure exploits the Kantorovich dual representation: inference is achievable via joint maximization over the sieve-approximated dual functions and test multipliers, transforming the criterion into a convex program. This enables computational tractability and scalability; the sieve approximation error diminishes as sieve complexity increases.
Methodologically, the inference deploys sample splitting and cross-fitting, with critical values from standard normal quantiles, obviating the need for resampling (bootstrap/subsampling). This delivers reliable asymptotic size control across varying predictive scenarios, as confirmed in Monte Carlo studies. The procedure maintains validity irrespective of proxy quality, sample size asymmetries, or continuous versus discrete proxies.
Empirical Implications and Practical Extensions
The framework has direct implications for applied empirical practice. It accommodates diverse ML output forms—binary labels, predicted probabilities, ranking vectors—and enables integration of proxies from multiple alternative ML procedures, treating the union of predictions as a low-dimensional linking summary. Stratification via θ03 (e.g., region, time, or text characteristics) further refines identification, tightening confidence sets when proxy accuracy heterogeneity exists across strata. This is evidenced in the simulations, where incorporation of stratification leads to marked improvements in informative bounds.
The unconditional OT mechanism generalizes classical data combination problems, offering computational tractability for scenarios where moment conditions span variables distributed across distinct datasets, a frequent circumstance in empirical economics (e.g., fairness analysis, intergenerational mobility, algorithmic impact studies).
Numerical Evidence
Monte Carlo simulations rigorously demonstrate:
- The proposed inference procedure exhibits reliable size control even under high measurement error or substantial sample-size asymmetry; plug-in estimators show pronounced over-rejection and invalid confidence sets.
- Stratification using observable features θ04 enhances informational content and generates substantially tighter bounds when prediction efficacy varies across strata (as shown in Figure 1).
- Continuous proxies admit more informative inference via sieves, outperforming binary proxies; sieve order incrementally decreases conservativeness, especially as sample size increases.
- Empirical confidence regions contract as either downstream or validation sample sizes grow, but the precision is governed by the minimum of the two.
Theoretical Contributions and Future Directions
The paper establishes a new identification result for moment models where generated regressors are ML proxies, and partial identification is optimal given marginal distributions and target population compatibility. The unconditional OT characterization complements existing literature by dispensing with structural assumptions and full validation samples required in prior approaches. The cross-fitted inference technique is robust and tractable, opening avenues for practical implementation in econometric analyses utilizing ML-generated measures.
From an ML perspective, the framework suggests that proxy quality should be assessed not merely by predictive accuracy, but by information preservation relative to economically relevant moment conditions. This may inspire design of ML procedures optimizing information linking rather than out-of-sample error minimization.
Potential future extensions include:
- Formal integration of reweighting for distributional shifts between validation and downstream samples.
- Refinement of subvector inference procedures for sharper, non-conservative bounds on individual parameters.
- Application to settings involving multiple overlapping proxies or operational surrogacy across observational datasets.
- Exploration of ML algorithm design tailored for maximized information preservation in downstream partial identification contexts.
Conclusion
This work provides a computationally viable, theoretically sharp framework for partial identification and inference in econometric models incorporating ML-generated proxies. By leveraging data combination and unconditional optimal transport, it permits valid inference with minimal requirements on the upstream ML process, facilitates practical application across a range of empirical settings, and motivates new directions in the interface of ML and econometric theory.

