Long-Term Causal Inference with Many Noisy Proxies
Abstract: We propose a method for estimating long-term treatment effects with many short-term proxy outcomes: a central challenge when experimenting on digital platforms. We formalize this challenge as a latent variable problem where observed proxies are noisy measures of a low-dimensional set of unobserved surrogates that mediate treatment effects. Through theoretical analysis and simulations, we demonstrate that regularized regression methods substantially outperform naive proxy selection. We show in particular that the bias of Ridge regression decreases as more proxies are added, with closed-form expressions for the bias-variance tradeoff. We illustrate our method with an empirical application to the California GAIN experiment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper tackles a common problem for tech companies and researchers: how to figure out the long-term impact of a change (like a new app feature) when you can only measure lots of short-term signals right away (like clicks, time on page, or add-to-cart). The trick is that these short-term signals are “noisy” — they only partly reflect what you really care about, like future spending or coming back to the app months later.
The authors show how to combine many short-term signals in a smart way to estimate long-term effects more accurately. They use methods that carefully “shrink” or smooth the influence of each signal so the final estimate isn’t fooled by random noise.
What questions did the authors ask?
They set out to answer three simple questions:
- If our short-term signals are noisy, how far off will our long-term estimates be?
- Does having more short-term signals help reduce that error?
- What are the best practical methods to combine many signals to predict long-run effects?
How did they study it?
Think about trying to judge a person’s true mood (which you can’t directly see) using lots of clues: how much they smile, how often they text friends, how long they stay at an event, and so on. Each clue is a bit blurry and sometimes misleading, but together they tell a story. The paper builds a similar setup:
- The “treatment” is the change you make (like showing users a new recommendation algorithm).
- The “hidden state” is the thing you can’t directly see right away but really care about (like true engagement or satisfaction).
- The “proxies” are the many short-term signals you can see (clicks, views, session length), which are noisy reflections of the hidden state.
- The “long-term outcome” is what you ultimately care about (like spending in six months).
They use two kinds of data, just like many companies already have:
- An experiment that shows how the treatment changes the short-term signals (because the treatment is randomized, this part is trustworthy).
- A large observational dataset that shows how those short-term signals relate to the long-term outcome (even if there’s no experiment here, it’s still useful for learning the signal-to-outcome connection).
Then they combine these two pieces:
- Learn how the treatment shifts the short-term signals.
- Learn how those signals relate to the long-term outcome using a method called regularized regression.
What is regularized regression? Imagine you have lots of noisy thermometers to measure a room’s temperature. If you just pick the “best-looking” thermometer, you might get fooled by one that’s off by chance. Regularized methods (like Ridge, Lasso, or Partial Least Squares) pool information from all thermometers but keep each one’s weight modest, so random errors average out. In short:
- Ridge spreads small weights across many signals.
- Lasso picks a smaller set of the strongest signals.
- Partial Least Squares builds a few “summary signals” that are most helpful for prediction.
These methods reduce overconfidence in any one noisy signal and make the final estimate more stable.
What did they find?
There are four big takeaways:
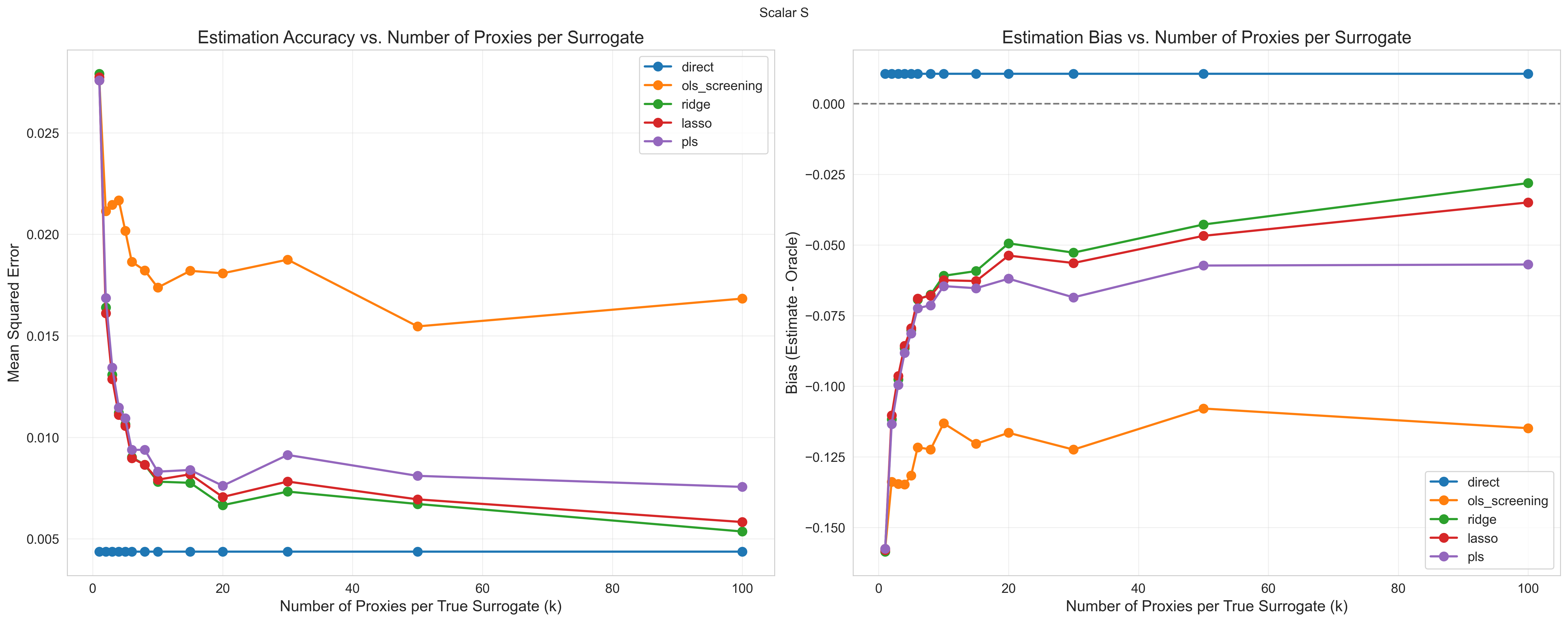
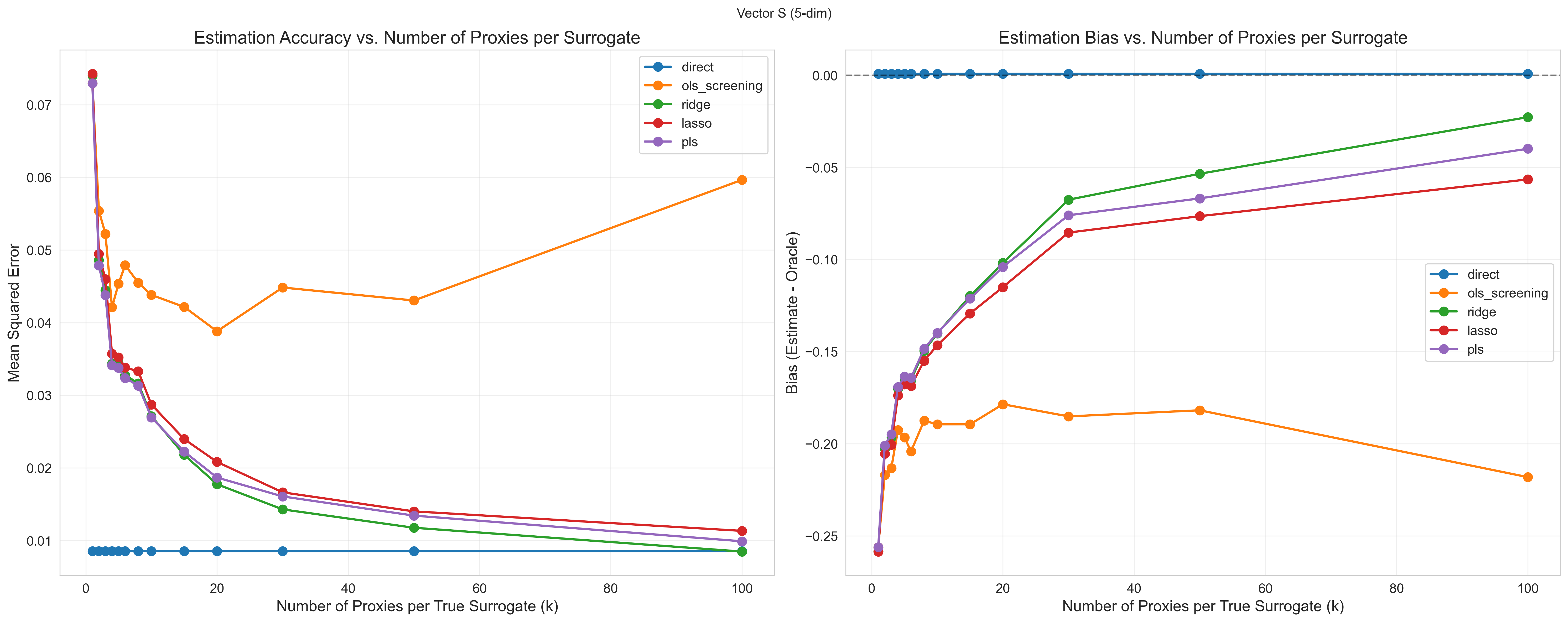
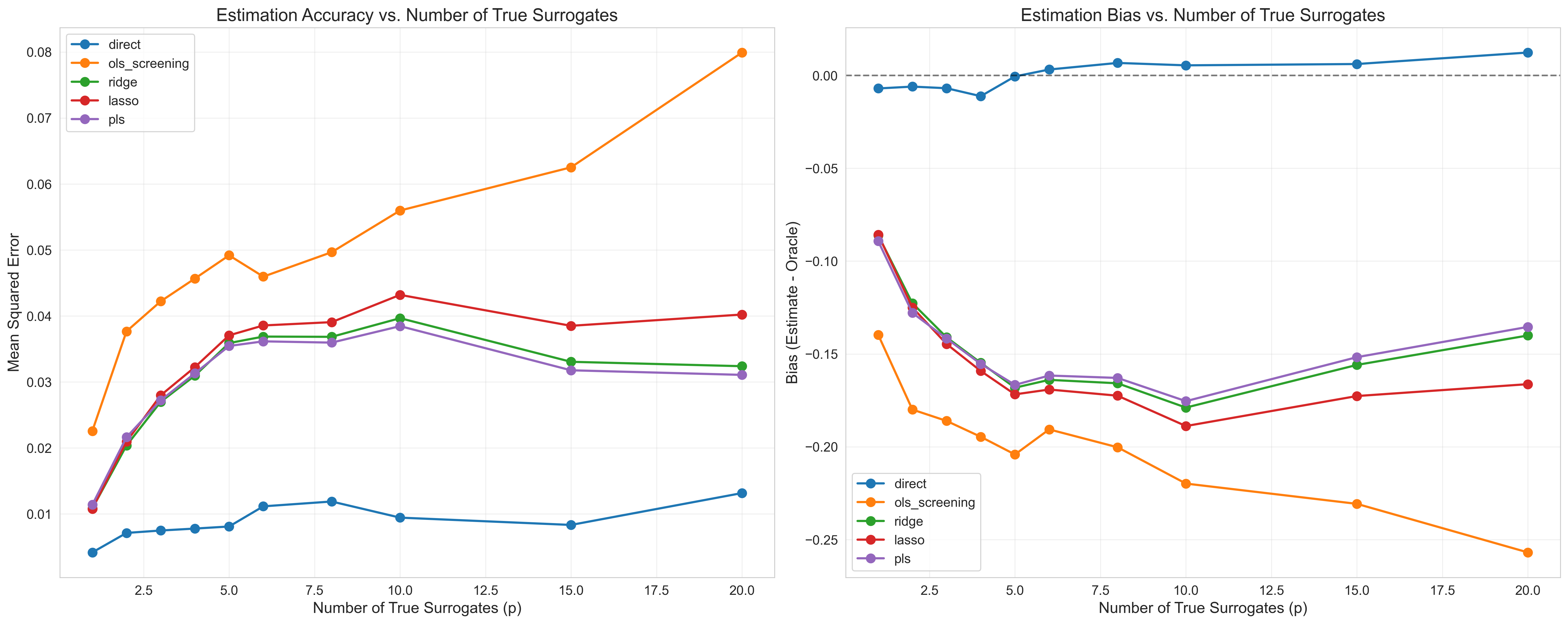
- Many noisy signals are better than a few. If each signal is a blurry picture of the hidden state, averaging lots of them helps cancel out the blur. The authors show that, under realistic assumptions, the bias (systematic underestimation) gets smaller as you add more good-quality proxies. A helpful mental model: averaging many noisy thermometers gets you closer to the true temperature.
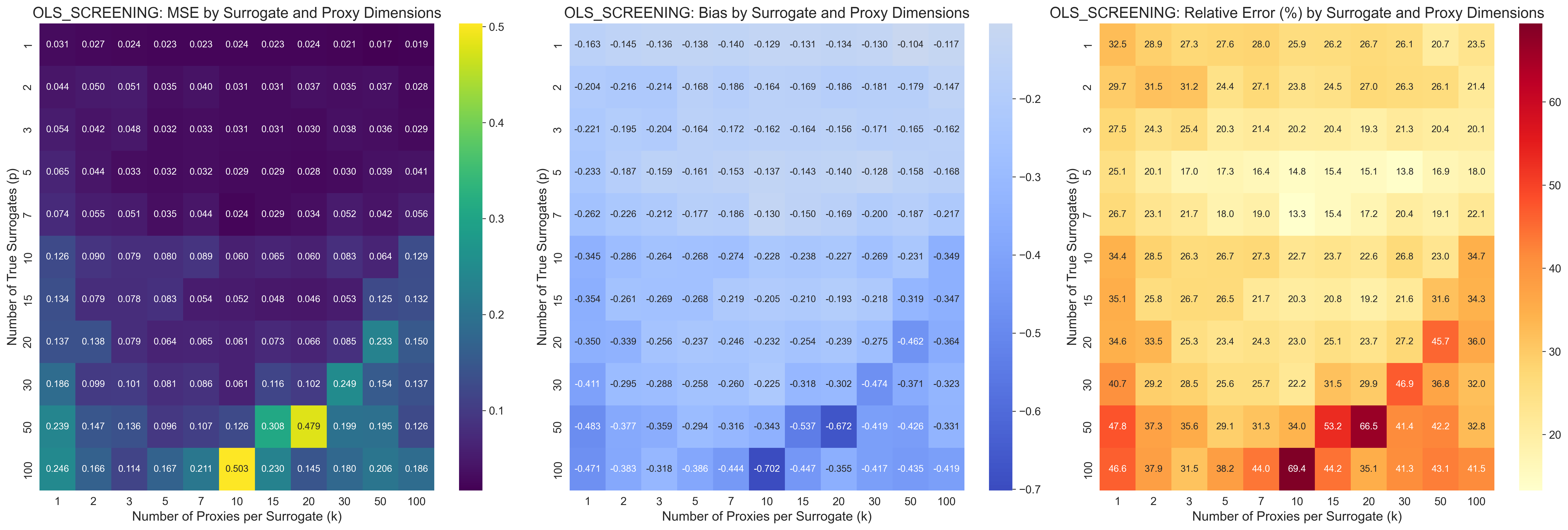
- Regularization beats “pick the top signals.” A common shortcut is to choose the handful of short-term measures most correlated with the outcome and ignore the rest. The paper shows this is risky: those “top” picks can be lucky flukes caused by noise. Regularized methods (Ridge, Lasso, PLS) consistently perform better, especially when you have lots of signals.
- There’s a clear trade-off between bias and variance. If you regularize more, you become cautious and avoid wild swings (lower variance), but you may slightly underestimate the true effect (higher bias). If you regularize less, you risk noisy, unstable estimates. The authors derive simple formulas showing this trade-off and explain how to choose the amount of regularization with standard tools like cross‑validation.
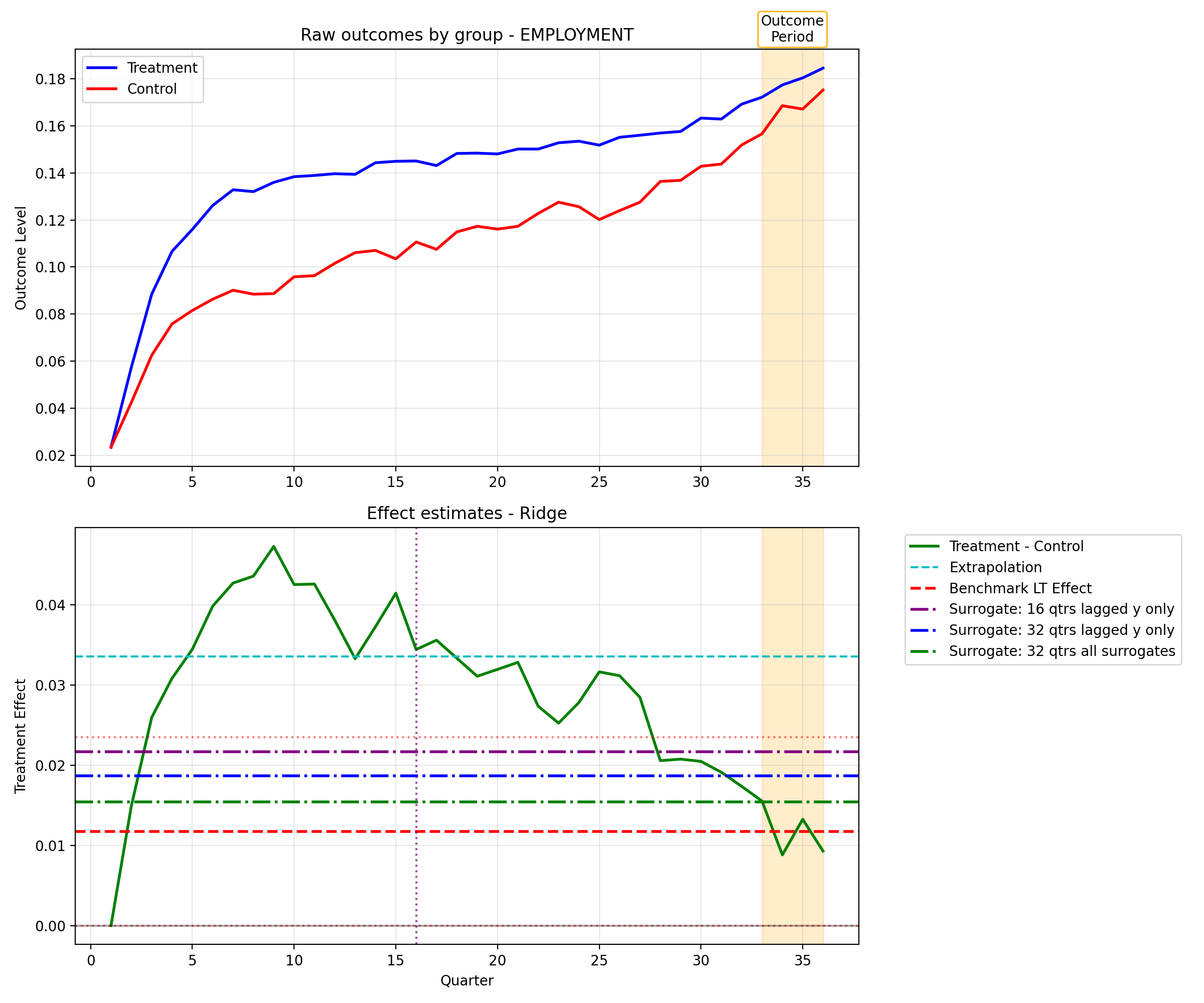
- Real and simulated tests confirm the theory. In computer simulations, regularized methods consistently outperformed naïve screening, particularly when there were many signals and only a few true underlying factors. In a real-world example (the California GAIN job program), Ridge improved as more short-term measures were added, while ordinary methods that just picked signals didn’t improve much.
Why this matters:
- Companies and researchers can get closer to the true long-term impact without waiting months or years.
- Using more signals isn’t enough — you must combine them carefully to avoid being misled by noise.
Why does this matter and what could it change?
- Better product decisions, faster: Firms can run short experiments, collect many quick measures, and still estimate long-term outcomes more reliably. This helps decide which features, prices, or ads to roll out.
- Smarter measurement strategy: Rather than hunting for one “perfect” short-term metric, it’s often better to gather many okay metrics and combine them with regularization.
- Practical guidance: Use Ridge, Lasso, or PLS (with cross‑validation) to build a surrogate index from many proxies, then combine it with the experimental effect on those proxies to estimate the long-term effect.
- Limits to keep in mind: This works best when many signals reflect a small number of underlying “hidden factors.” If the hidden world is very complex and you don’t have enough informative signals per factor, it’s harder to recover the long-term effect perfectly.
In short, the paper shows a reliable, practical way to turn lots of short-term, imperfect signals into trustworthy estimates of long-term impact — a big win for data-driven decision making.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains uncertain or unexplored, highlighting actionable directions for future research.
- Validity under partial surrogacy: The analysis assumes complete mediation (). Develop sensitivity analyses, identification bounds, or robust estimators when there are direct effects or omitted mediators that violate surrogacy.
- Nonlinear structural relationships: Theoretical results hinge on linearity for , , and . Extend the framework to nonlinear mappings (e.g., generalized linear models for binary , interactions among surrogate dimensions, non-additive measurement models) and characterize resulting bias/variance.
- Correlated and heteroskedastic proxy noise: Key bias formulas use homoskedastic, independent errors (). Derive bias/variance characterizations and consistency conditions under general correlated, heteroskedastic (including time-series dependence and cluster structure).
- General loading structures beyond “balanced loadings”: The clean bias formula relies on . Provide results that quantify how bias decreases with under realistic, unbalanced, cross-loading structures (e.g., sparse, low-rank, or factor-model loadings), and determine when adding proxies actually improves the smallest singular values of .
- Debiasing to target with finite : The estimator targets the ridge estimand , not the causal estimand . Design practical bias-correction strategies (e.g., SIMEX-style measurement-error correction, deconvolution, IV-based approaches, or supervised factor models) to recover consistency for when proxies are noisy.
- Tuning for treatment-effect AMSE: is selected via prediction-oriented cross-validation, while the optimal for minimizing depends on unknown causal quantities. Develop tuning schemes and estimators that directly target the AMSE of the treatment-effect estimator rather than the predictive loss of .
- Inference with tuned hyperparameters: The variance estimator treats as fixed. Incorporate the extra uncertainty from data-driven hyperparameter selection (e.g., nested CV or bootstrap that resamples both stages and tuning), and establish its asymptotic validity.
- Two-sample transport and dataset shift: The approach assumes and are i.i.d. from the same population. Investigate robustness and corrections under covariate shift, temporal drift, or sample selection differences between the experimental proxy data and the observational outcome data (e.g., reweighting or domain adaptation).
- High-dimensional first-stage estimation: The first stage uses difference-in-means for each proxy. Analyze and develop shrinkage or regularized first-stage estimators for when is large and is modest (e.g., ridge/Lasso across proxies, hierarchical shrinkage), and quantify the impact on the final AMSE.
- Theory for Lasso and PLS: While simulations include Lasso and PLS, the theory focuses on ridge. Derive spectral bias/variance decompositions for Lasso (including selection mistakes) and PLS (including component estimation error), and characterize regimes where they dominate ridge.
- Dynamic surrogate processes: Proxies often arrive as time series (lags, panels). Extend the model to dynamic latent states (state-space models) and derive identification and bias properties when proxies are measured over time and is a long-horizon outcome.
- Heterogeneous treatment effects: The framework targets an average effect . Study subgroup-specific or conditional treatment effects (heterogeneity across user segments), including how proxy composition and measurement error interact with heterogeneity.
- Binary and bounded outcomes: The method treats as continuous, yet empirical outcomes (e.g., employment, retention) are often binary or bounded. Characterize bias/variance for generalized outcome models (logit/probit) with noisy proxies and propose feasible estimators.
- Regimes with and finite-sample guarantees: Provide nonasymptotic risk bounds and inference procedures when the observational sample is small relative to the number of proxies, including double-descent phenomena and regularization path behaviors.
- Learning the latent dimension : The number of surrogates is assumed rather than estimated. Develop data-driven procedures to infer (e.g., supervised factor analysis, information criteria, cross-validated rank selection) and quantify downstream impacts on .
- Proxy design guidance: Offer principled measurement-design strategies to maximize information about (e.g., increasing the smallest singular values of ), including how many proxies to collect per surrogate, which behaviors are most informative, and cost–benefit tradeoffs.
- Missing or non-overlapping proxies across datasets: Real deployments may have different or partially overlapping proxy sets in and . Create alignment methods (e.g., imputation, mapping via learned latent factors) and analyze identification implications.
- Robustness to dependence and interference: The setup ignores interference (spillovers) and network dependence. Examine how proxy-based surrogates behave under interference and propose corrections or experimental designs to mitigate spillover bias.
- Overlap of units across samples: Inference notes added covariance when and overlap but does not fully develop estimators. Provide practical procedures for overlap-aware variance estimation (e.g., sample splitting, cross-fitting with overlap-adjusted covariance).
- Practical guidance on required signal-to-noise: Translate theory into actionable thresholds (minimum per , required SNR, sample sizes and ) to achieve target bias or MSE, aiding practitioners in planning experiments and measurement.
- Structured regularization: Explore group, hierarchical, or multitask regularization that leverages domain knowledge (e.g., grouping proxies by product category), and quantify improvements over plain ridge/Lasso.
- Broader empirical validation: Validate across multiple digital-platform datasets with diverse proxy sets and outcomes, including ablation studies that vary , SNR, , and loading structures to stress-test the method.
- Open-source reproducibility and diagnostics: Provide replicable code, diagnostics to detect proxy redundancy and harmful multicollinearity, and tools to visualize the learned surrogate index and its stability across resamples.
Practical Applications
Overview
The paper introduces a practical, two-sample surrogate-index approach for estimating long-term treatment effects when randomized experiments can only observe short-term outcomes. It shows why and how regularized regression methods (especially Ridge, but also Lasso and PLS) can aggregate many noisy proxies of latent surrogates to yield less biased and more stable long-term effect estimates than naïve proxy selection. The theory clarifies the bias-variance trade-off, provides variance estimation for inference, and demonstrates strong empirical performance (including a policy application to the California GAIN experiment).
Below are actionable applications derived from the paper’s findings, organized by time-to-deployment.
Immediate Applications
The following applications can be implemented with current tooling (e.g., Python/R Ridge/Lasso/PLS, standard A/B testing platforms, and the paper’s variance estimator). Each item includes sector links, potential tools/workflows, and key assumptions/dependencies.
- E-commerce and digital platforms: accelerate long-term decision-making in A/B tests (e.g., recommender changes, UI tweaks, search ranking) using short-term proxies such as clicks, add-to-cart, session duration, early purchases
- Sector: software, retail, ad tech
- Tools/Workflow: two-sample pipeline (train surrogate index on historical proxies-to-long-term outcome via Ridge/Lasso/PLS; run RCT to estimate treatment effects on proxies; combine via τ̂ = τ̂P′ α̂λ; compute standard errors using the paper’s plug-in variance estimator); cross-validation for λ; dashboard integration
- Assumptions/Dependencies: randomized treatment; surrogacy (treatment affects long-term outcomes only via latent surrogates); stability of proxy–outcome mapping between observational and experimental data; sufficient number and coverage of proxies
- Subscription businesses and streaming/gaming: early read on retention/LTV from short-term engagement metrics (e.g., first-week sessions, watch time, gameplay intensity)
- Sector: software, media/entertainment, gaming
- Tools/Workflow: regularized surrogate index trained on historical cohorts; automated gating rules for feature rollouts based on τ̂ and confidence intervals; monitoring for proxy–outcome drift
- Assumptions/Dependencies: stationarity of engagement-to-retention relationship; adequate sample sizes; independence of datasets or use of sample splitting if overlapping
- Marketing and growth: predict long-run revenue or retention from short-term campaign metrics (opens, clicks, sign-ups, early purchase)
- Sector: marketing tech, e-commerce, SaaS
- Tools/Workflow: campaign-level two-sample estimator; lift in proxies from experimental arms paired with surrogate index from CRM/analytics data; variance-based decision thresholds
- Assumptions/Dependencies: proxies cover key latent drivers; consistent measurement across campaigns; surrogacy plausibility
- Pricing and promotion experiments: infer long-term effects on customer value from immediate behavior changes (coupon redemption, basket composition, price comparisons)
- Sector: retail, e-commerce, finance (payments)
- Tools/Workflow: Ridge surrogate index trained on historical transaction data; experiment reads using τ̂P′ α̂λ; sensitivity analysis across proxy sets
- Assumptions/Dependencies: linear approximation reasonable; proxies capture price sensitivity and purchase intent; minimal policy-induced confounding
- Policy evaluation under administrative data: earlier assessment of long-run outcomes (employment, earnings, welfare use) using short-run administrative proxies (as in the California GAIN example)
- Sector: public policy, labor, social programs
- Tools/Workflow: build surrogate index with Ridge/Lasso/PLS from prior cohorts; apply to ongoing RCT proxy effects; report τ̂ and CIs alongside naïve extrapolations; use the paper’s inference recipe
- Assumptions/Dependencies: random assignment; consistency of proxy–outcome mapping; sufficient proxy diversity; ethical/legal data use
- Education technology and learning analytics: forecast longer-run learning outcomes (course completion, certification, skill retention) from early proxies (assignment scores, logins, time-on-task)
- Sector: education, edtech
- Tools/Workflow: surrogate index from historical course data; experiment-level proxy lifts; use variance estimator for CI; integrate into instructional A/B platforms
- Assumptions/Dependencies: surrogate validity (early engagement mediates long-run learning); proxy coverage of latent learning states; stability across cohorts
- Fintech product changes: estimate long-run value or risk from early usage proxies (onboarding completion, feature adoption, repayment cadence)
- Sector: finance, fintech
- Tools/Workflow: regularized surrogate index; two-stage estimator; monitoring for regulatory constraints; internal model risk governance (document bias-variance trade-offs)
- Assumptions/Dependencies: model stability; data privacy; surrogacy plausibility given compliance needs
- Experimentation platform enhancement: add “surrogate index” modules to internal A/B testing tooling
- Sector: software tooling, data science platforms
- Tools/Workflow: packaged pipelines (fit α̂_λ via Ridge/Lasso/PLS; estimate τ̂_P from RCT; compute τ̂ and SE); CV for λ; sample splitting to address overlap; visualization of bias-variance trade-off
- Assumptions/Dependencies: adequate historical data; well-defined proxy sets; governance and monitoring to detect drift
- Measurement and proxy design: re-instrument products to add/standardize proxies, increasing coverage of latent surrogates to reduce attenuation bias
- Sector: product analytics, instrumentation
- Tools/Workflow: proxy auditing against loadings; add diverse proxies to boost smallest singular values (coverage); track SNR; data quality checks
- Assumptions/Dependencies: engineering capacity; data collection policies; careful avoidance of redundant proxies that don’t improve coverage
- Rapid prototyping and training: use the paper’s interactive app (https://linearsurrogateindex.streamlit.app/) to explore surrogate index behavior and tune workflows
- Sector: data science, academia
- Tools/Workflow: app-driven scenario exploration; synthetic simulations; sensitivity analysis
- Assumptions/Dependencies: educational/demo context; alignment with production data realities
Long-Term Applications
These applications require further research, scaling, validation, or development beyond off-the-shelf regularized regression.
- Clinical trials and biomedical research: multi-biomarker surrogate indices for long-term clinical endpoints
- Sector: healthcare
- Tools/Workflow: Ridge/PLS surrogate indices built on rich biomarker panels; early interim decisions; potential regulatory pathways for surrogate endpoint acceptance
- Assumptions/Dependencies: strong surrogacy evidence; external validation; regulatory approval; careful handling of nonlinearity and heterogeneity
- Policy frameworks for early decision-making: institutionalize surrogate-index-based interim analyses for social programs (education, labor, public health)
- Sector: public policy
- Tools/Workflow: standardized protocols (two-sample estimators, inference, drift monitoring); guidelines for proxy selection; transparency and audit trails
- Assumptions/Dependencies: legal/ethical governance; stakeholder buy-in; robust validation across contexts/time
- Integrated A/B platforms with automated surrogate reads and gating: real-time adoption in large-scale experimentation with confidence-bound decision rules
- Sector: software tooling, experimentation infrastructure
- Tools/Workflow: automated pipelines (training, estimation, inference, alerting); guardrails (detect non-stationarity, proxy drift); bandit integration with long-term reward proxies
- Assumptions/Dependencies: MLOps maturity; scalability; robust drift detection; organizational acceptance
- Causal representation learning for surrogates: use deep latent models to relax linearity and capture richer proxy–surrogate relationships
- Sector: software, AI/ML
- Tools/Workflow: deep encoders with causal regularization; two-stage estimators in learned latent space; robustness evaluation
- Assumptions/Dependencies: data volume; identifiability; domain-shift handling; ML governance
- Dynamic and sequential decision-making: adapt surrogate indices to time-varying, path-dependent outcomes (reinforcement learning, long-horizon bandits)
- Sector: software, robotics, operations
- Tools/Workflow: sequential surrogates; online updating; policy-gradient or off-policy evaluation with proxy-informed long-term rewards
- Assumptions/Dependencies: temporal surrogacy; Markovian structures or controlled relaxation; stability under policy changes
- Proxy set optimization and information design: select/engineer proxies to maximize coverage (increase minimal singular values) and SNR
- Sector: analytics, instrumentation
- Tools/Workflow: experimental design for proxies; active measurement; information-theoretic criteria for proxy choice; cost–benefit analysis
- Assumptions/Dependencies: clear mapping from proxy design to latent coverage; measurement budgets; diminishing returns analysis
- Robustness to violations of surrogacy and linearity: sensitivity analyses, partial mediation models, and nonparametric extensions
- Sector: academia, applied econometrics
- Tools/Workflow: diagnostic tests; bounds when surrogacy is imperfect; semiparametric or nonparametric surrogate indices; heterogeneous treatment effect modeling
- Assumptions/Dependencies: additional identification assumptions; larger samples; method development
- Cross-domain generalization and fairness: ensure surrogate indices perform equitably across subpopulations and remain valid across markets/products
- Sector: software, policy, compliance
- Tools/Workflow: subgroup validation; fairness metrics; domain adaptation; recalibration pipelines
- Assumptions/Dependencies: representativeness; detection and correction of proxy bias; governance and auditing
- Energy and sustainability programs: estimate long-run savings/reliability from short-run operational proxies (smart meter data, demand response signals)
- Sector: energy
- Tools/Workflow: two-sample surrogate indices from historical utility data; program-level early reads; integration with grid planning tools
- Assumptions/Dependencies: stable proxy–outcome mapping; seasonal/behavioral adjustments; regulatory acceptance
- Standardization and auditing of surrogate-based inference: develop best practices, benchmarks, and open-source libraries implementing the paper’s estimator and inference
- Sector: academia, industry consortia
- Tools/Workflow: reference implementations (R/Python), benchmarking suites, documentation of assumptions and variance estimation; educational materials
- Assumptions/Dependencies: community adoption; ongoing maintenance; empirical validation across sectors
Notes on Feasibility and Key Assumptions
- Surrogacy (complete mediation): the core assumption is that treatment affects long-run outcomes only through latent surrogates captured by proxies; violations can bias estimates.
- Stability and transportability: the proxy–outcome mapping estimated in observational data must apply to the experimental context; monitor for dataset shift and temporal drift.
- Proxy coverage and quantity: bias shrinks with more and better proxies per latent dimension; collect diverse proxies that increase coverage rather than redundant ones.
- Regularization and tuning: use cross-validation to select λ; recognize bias–variance trade-offs (Ridge bias increases with λ but variance decreases).
- Independence and inference: when experimental and observational datasets overlap, use sample splitting or adjust for overlap covariance per the paper’s variance decomposition.
- Linearity and normality: theory uses linear models and normality for tractability; in practice, check model diagnostics and consider robust or nonlinear extensions when needed.
- Data governance: ensure privacy, compliance, and ethical use, especially for administrative or sensitive domains.
Glossary
- AMSE (Asymptotic Mean Squared Error): The large-sample mean of squared estimation error, combining squared bias and variance. "Asymptotic Mean Squared Error (AMSE)"
- Asymptotic bias: The limiting bias of an estimator as sample size grows. "Asymptotic Bias"
- Asymptotic variance: The variance of an estimator in the large-sample limit. "By deriving the asymptotic variance and combining it with the squared bias"
- Attenuation bias: Bias toward zero arising from measurement error or shrinkage. "showing that attenuation bias shrinks as more proxies are added."
- Balanced loadings: An assumption that proxy loadings are orthogonal and equally scaled, simplifying analysis. "balanced loadings ()"
- Bias-variance tradeoff: The tension between reducing bias (fit) and reducing variance (stability) in estimation. "closed-form expressions for the bias-variance tradeoff."
- Causal graph: A directed representation of causal relationships among variables. "Our data generating process is based on the causal graph in figure \ref{fig:dag_prox}."
- Compound symmetry: A covariance structure with equal variances and equal covariances among variables. "compound symmetry:"
- Cross-validation: A data-driven method to choose tuning parameters by splitting data into training and validation sets. "cross-validated ridge regression (L2)"
- Delta method: A technique to approximate the variance of a function of estimators. "Delta-method decomposition."
- Difference-in-means: An estimator comparing average outcomes between treated and control groups. "In the simplest difference-in-means implementation"
- Eicker--Huber--White: A heteroskedasticity-robust variance estimator for regression coefficients. "A heteroskedasticity-robust (Eicker--Huber--White) variance estimator"
- Errors-in-variables: Regression with measurement error in predictors, causing bias in estimated coefficients. "errors-in-variables model with measurement error in the regressors"
- Heteroskedasticity: Non-constant variance of errors across observations. "A heteroskedasticity-robust (Eicker--Huber--White) variance estimator"
- High-dimensional: Settings where the number of variables is large relative to sample size. "particularly in the challenging high-dimensional settings"
- Homoskedasticity: Constant variance of errors across observations. "Under homoskedasticity, one may replace with "
- i.i.d. (independent and identically distributed): Observations drawn independently from the same distribution. "observations drawn i.i.d. from the common model:"
- Latent surrogate: An unobserved variable mediating treatment effects on outcomes. "latent surrogates"
- Loading matrix: The matrix mapping latent variables to observed proxies. "L \in R{k\times p} is a non-random loading matrix"
- Lasso: An L1-regularized regression method that induces sparsity in coefficients. "Lasso/L1 Regression: We regress the long-term outcome on all proxies with cross-validated LASSO regression (L1)"
- Moore–Penrose pseudoinverse: A generalized inverse used for potentially non-full-rank matrices. "Here denotes the Moore-Penrose pseudoinverse of "
- Ordinary Least Squares (OLS): The standard linear regression estimator minimizing squared residuals. "OLS Screening/L0 Regression"
- Partial Least Squares (PLS): A dimensionality-reduction method constructing components to maximize covariance with the outcome. "Partial Least Squares (PLS): This method reduces the dimensionality of the proxies P"
- Quasi-linear utility: A utility specification linear in one argument, often simplifying demand modeling. "under quasi-linear utility with linear demand"
- Random utility framework: A model where choices arise from utility with random components. "random utility framework \parencite{mcfadden1974conditional}."
- Ridge regression: An L2-regularized regression method that shrinks coefficients to stabilize estimates. "ridge regression with regularized coefficient vector:"
- Sherman–Morrison formula: A matrix identity for inverting rank-one updates. "Using the Sherman-Morrison formula, the inverse of this matrix is:"
- Singular Value Decomposition (SVD): A matrix factorization into orthogonal singular vectors and singular values. "Let be the SVD with singular values ."
- Spectral bias decomposition: A bias analysis expressed along singular directions of a loading matrix. "Spectral Bias Decomposition"
- Surrogacy criterion: The assumption that treatment affects outcomes only through surrogates. "maintaining the ``surrogacy criterion'' of complete mediation"
- Surrogate index: A linear combination of surrogates or proxies used to predict long-term outcomes. "the ``true surrogate index,'' "
- Toeplitz covariance: A structured covariance matrix with constant diagonals, often modeling time-series dependence. "random Toeplitz covariance "
- Wald interval: A confidence interval constructed from an estimator and its standard error under asymptotic normality. "A Wald interval is $\hat\tau_\lambda \pm z_{1-\alpha/2}\hat{\text{SE}(\hat\tau_\lambda)$."
Collections
Sign up for free to add this paper to one or more collections.