- The paper introduces a hybrid framework that combines knowledge graphs and large language models to generate high-quality multiple-choice questions with interpretable difficulty signals.
- It employs controlled subgraph sampling and LLM prompting to create contextually enriched question stems and distractors from structured textual data.
- Empirical results using XGBoost and SHAP analyses confirm robust alignment between predicted difficulty scores and human performance.
Generating Multiple-Choice Knowledge Questions with Interpretable Difficulty Estimation via KGs and LLMs
Introduction
This paper, "Generating Multiple-Choice Knowledge Questions with Interpretable Difficulty Estimation using Knowledge Graphs and LLMs" (2604.10748), presents an end-to-end framework for the generation of high-quality multiple-choice questions (MCQs) from unstructured text, unifying the strengths of knowledge graphs (KGs) and LLMs. Unlike prior systems that rely exclusively on template-driven generation or treat LLMs as black-box MCQ generators, this approach leverages a hybrid pipeline: 1) constructing a KG as a structured intermediate representation, 2) systematically generating MCQs through controlled sampling of KG subgraphs and targeted prompting of an LLM, and 3) providing interpretable, empirically aligned difficulty estimation using a suite of nine technical signals. The framework's originality lies in its seamless integration of structured KG topology, LLM-driven contextualization, and human-in-the-loop difficulty calibration.
Framework Overview
The system initiates by transforming an input corpus (here, Wikipedia’s 100 most-viewed articles) into a KG using automated LLM-based factual triple extraction. The KG encodes entities, their semantic types, and relational edges, naturally supporting reasoning over both direct (single-hop) and complex (multi-hop) knowledge paths. High-centrality nodes are selected as MCQ keys due to their broad relevance and semantic connectivity.
An MCQ is generated by: 1) Sampling a subgraph—either a triple (for direct, “single-hop” fact questions) or quintuple (for “double-hop” reasoning); 2) Optionally augmenting the context with an additional triple to increase informational complexity; 3) Prompting GPT-4o to formulate a question stem informed by the sampled subgraph; 4) Constructing distractors via breadth-first search to enforce type and topical coherence; and 5) Validating the MCQ using LLM-based answer disambiguation.
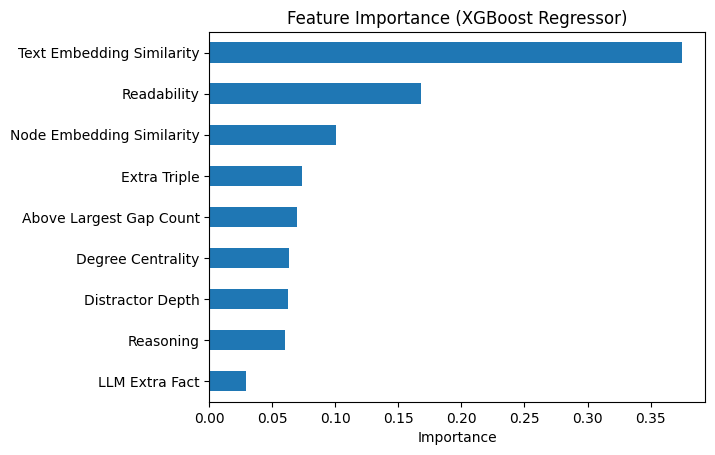
Figure 2: Schematic of the KG-to-MCQ pipeline integrating entity-centric subgraph selection, LLM-based question generation, and difficulty annotation.
This method explicitly disentangles graph structure, question semantics, and distractor plausibility, providing a controlled setting for investigating difficulty and interpretability.
Interpretable Difficulty Estimation
A principal contribution is the introduction of nine normalized, interpretable signals spanning graph analytics, embedding-based semantic similarity, and linguistic complexity. These include:
- Reasoning: Binary indicator for single-hop vs. double-hop construction.
- Extra Triple: Contextual enrichment flag.
- Distractor Depth: Mean graph-theoretic distance between the key and distractors.
- Node Embedding and Text Embedding Similarity: Averaged cosine similarities quantifying semantic proximity in latent spaces.
- Degree Centrality: Mean node importance over the associated subgraph.
- Readability: Flesch reading-ease score.
- Above Largest Gap Count: Ordinal count reflecting semantic gaps among distractors.
- LLM Extra Fact: Indicator for hallucinated information in the generated stem.
The signals are input to regression models (both linear and non-linear: XGBoost, Random Forest, Gradient Boosting) trained on empirically derived difficulty scores, defined as the proportion of incorrect human responses per MCQ.
Dataset Construction and Empirical Calibration
A dataset comprising 156 validated MCQs, each anchored to a KG subgraph and augmented with approximately 38 human-annotated difficulty responses per question, was constructed for evaluation. The incorrect response rate from this annotation serves as the gold standard for difficulty. This explicit calibration ensures that estimated difficulty is behaviorally meaningful rather than heuristic, i.e., grounded in observed cognitive challenge rather than solely structural proxies.
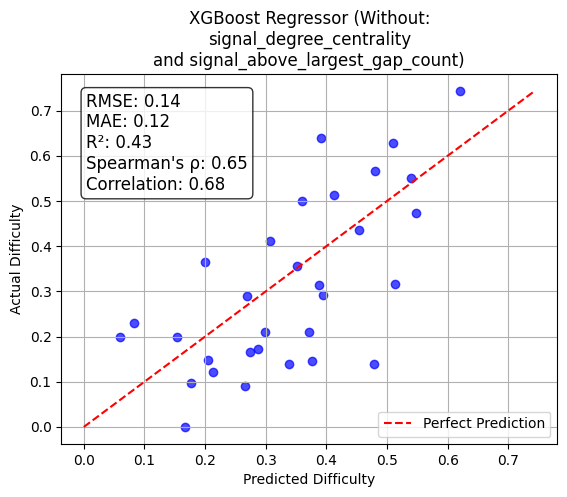
Figure 4: Histogram of MCQ incorrect answer rates, empirically characterizing the spectrum of question difficulty.
Notably, distractor and key selection is constrained so that options are of the same entity type and derived from neighboring subgraphs, mitigating selection bias and maximizing question realism.
Experimental Results and Quantitative Insights
Among regression models, XGBoost achieves the best prediction performance (RMSE=0.12, MAE=0.10, R2=0.58, Spearman ρ=66%). Predicted scores track human-measured difficulty robustly, and ablation studies further isolate key features.
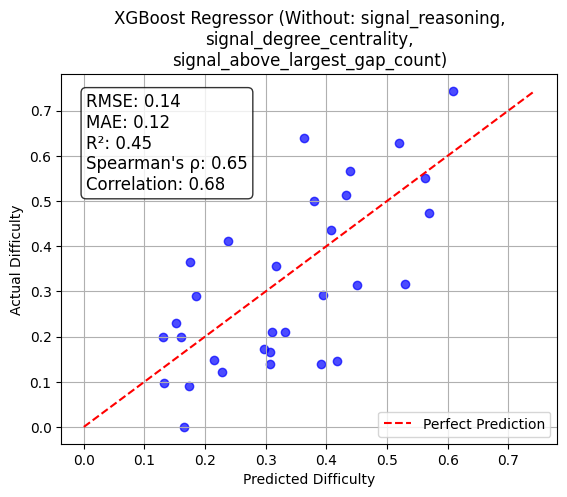
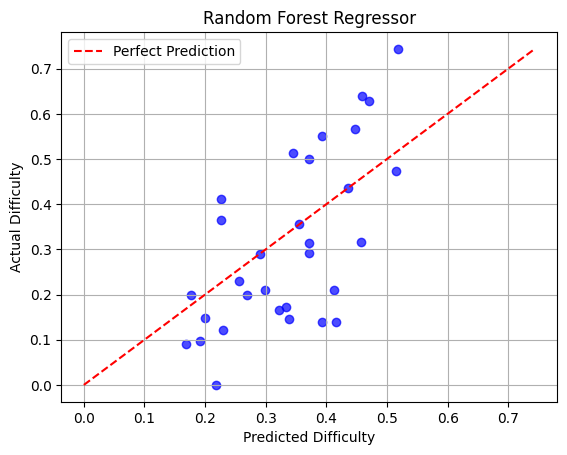
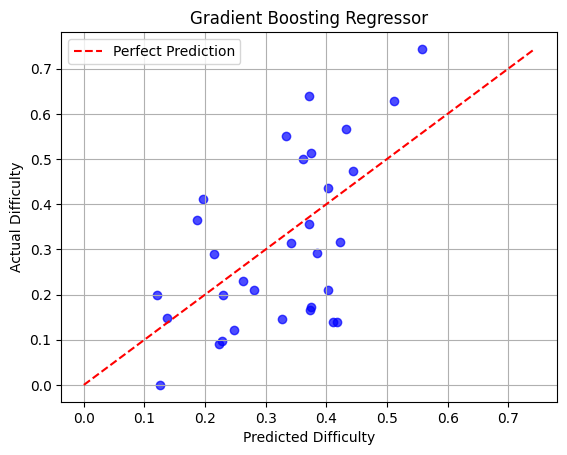
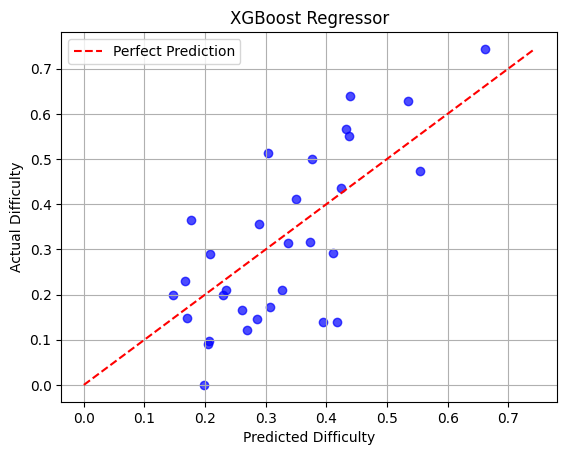
Figure 1: Alignment of predicted vs. actual difficulty scores for XGBoost regression, demonstrating high fidelity to empirical response patterns.
Feature importance and SHAP analyses reveal that text-based semantic similarity signals, particularly those measuring alignment between stem and distractors, dominate in predictive power. The Flesch readability score is also a key contributor, while explicit KG-topological signals such as degree centrality and reasoning type contribute less, particularly in the presence of strong semantic features.
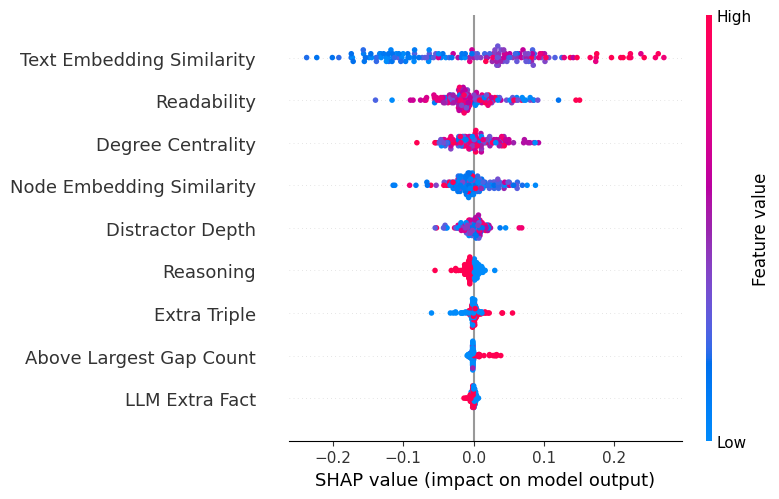
Figure 7: SHAP value-based analysis indicates that text embedding similarity and readability are the most influential predictors of difficulty.
Extended ablation shows that the joint exclusion of "Reasoning" and "Above Largest Gap Count" yields marginal improvement, suggesting redundancy or low additive signal among these features. The system delivers both interpretability and predictive accuracy, enabling diagnostic insights into which MCQ properties drive respondent challenge.
Qualitative Signal Analyses
The paper provides detailed visual illustrations of how MCQs differ structurally as a function of subgraph choice (triple vs. quintuple), extra-triple augmentation, and distractor sampling depth, illuminating criteria for single- vs. multi-hop reasoning.
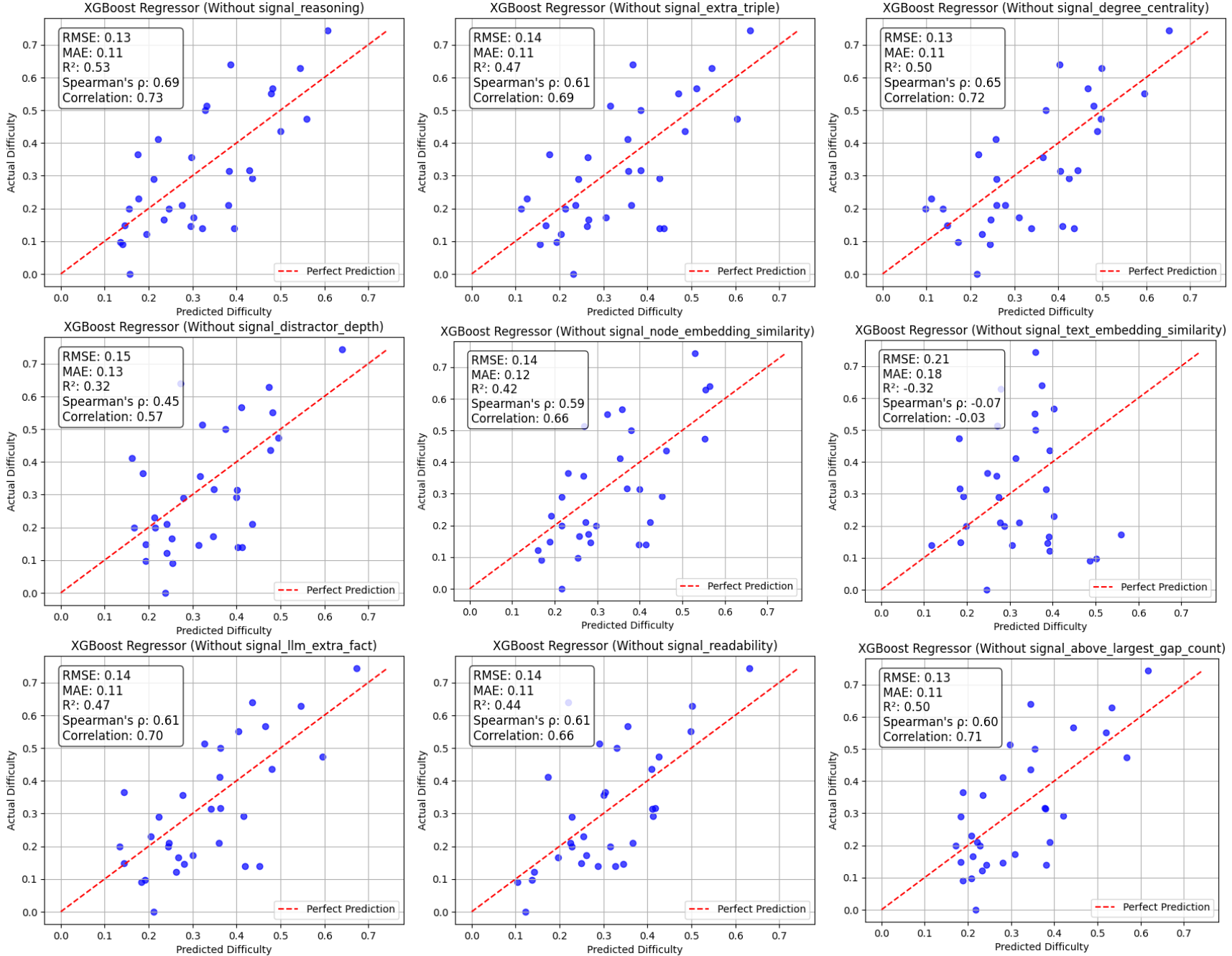
Figure 9: Illustration of single-hop and double-hop reasoning MCQs using KG subgraphs.
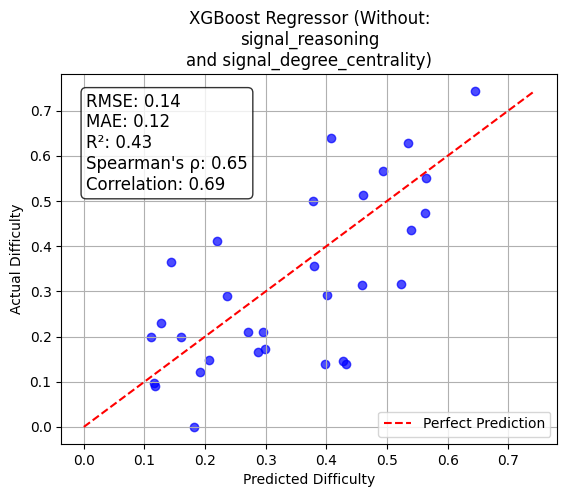
Figure 11: Visualization of MCQ generation with and without supplementary context via extra KG triples.
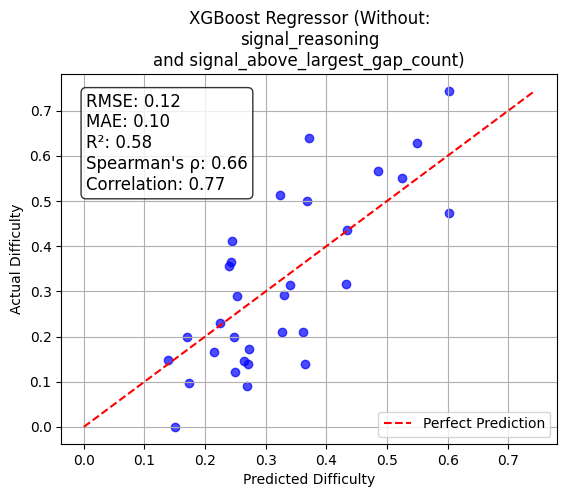
Figure 8: Distractor depth mapping shows the relation between key nodes and distractor sampling in the KG.
These controlled manipulations enable targeted evaluation of question complexity and facilitate further research on parameterized or difficulty-controlled MCQ generation.
Implications, Limitations, and Future Directions
By providing interpretable, empirically validated difficulty estimation, the framework has immediate applications in adaptive education (e.g., personalized assessment, curriculum diagnosis), cognitive scaffolding for tutoring systems, and automated exam construction. The KG-centric approach ensures traceability and the opportunity for post hoc analysis of question provenance—critical for both explainability and iterative refinement of assessment instruments.
Nevertheless, dataset size currently restricts the application of deep learning or more data-hungry modeling schemes. Expansion to specialized domains and personalized difficulty modeling, as discussed, constitutes a natural next stage. Further, cross-model MCQ validation and deeper adversarial distractor modeling could reduce occasional validation failures.
Conclusion
This research establishes a comprehensive pipeline for MCQ generation from textual corpora via LLM-driven KG construction, systematic subgraph sampling, LLM-based stem generation, graph-based distractor selection, and interpretable, empirically calibrated difficulty estimation. The approach effectively bridges structured knowledge representations and natural language generation, offering high-quality, explainable, and human-aligned MCQs with rigorously quantified difficulty. As LLM and KG integration deepens, the framework provides the technical substrate for principled advances in automatic educational assessment and AI-augmented learning.
Reference:
"Generating Multiple-Choice Knowledge Questions with Interpretable Difficulty Estimation using Knowledge Graphs and LLMs" (2604.10748)