- The paper demonstrates that engineering students favor chat and code generation features, achieving mean usage scores above 3.9 on a 5-point scale.
- The paper reveals that demographic variables and prior AI familiarity significantly modulate feature adoption and trust in GitHub Copilot.
- The study suggests targeted curricular and tool design interventions to foster equitable and effective AI-assisted programming education.
An Empirical Analysis of Engineering Students' Usage and Perceptions of GitHub Copilot in Open-Source Projects
Study Overview and Methodology
The investigation examines the utilization and perceptions of GitHub Copilot among engineering students contributing to an open-source codebase as part of a software engineering course. The study adopts a quasi-experimental, survey-based methodology involving 179 students at a major US public university. After a controlled introduction to Copilot's features within Visual Studio Code, students completed a substantial programming task on the JSON Crack project, focusing on adding node editing functionality to an unfamiliar codebase. Upon completing the assignment, participants reported on their usage and perceived utility of six key Copilot features—code autofill, code generation, Copilot chat, code explanation, error fixing, and documentation generation—using Likert-scale-based instruments.
The methodology is rigorously structured to isolate the impact of both demographic variables (notably gender) and prior experience (including AI familiarity and programming proficiency) on feature usage and trust constructs (reliability, technical competence, understandability, faith, and personal attachment, following Madsen-Gregor scales).
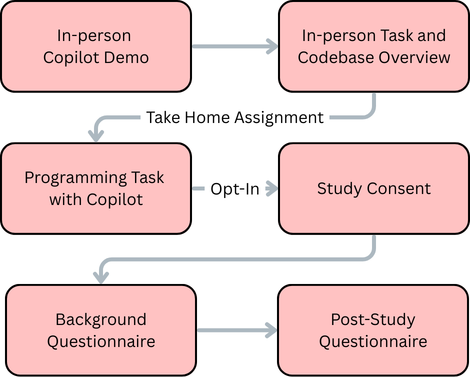
Figure 1: Study workflow detailing introduction, task, and post-task survey for GitHub Copilot feature usage and perception measurement.
Patterns of Feature Usage and Perceived Usefulness
Quantitative analysis reveals a non-uniform distribution of feature adoption, with Copilot chat and code generation features exhibiting the highest mean usage scores (4.02 and 3.92, respectively, on a 1–5 scale). Code explanation and code autofill demonstrated moderate uptake, while documentation and error fixing functions saw minimal engagement.
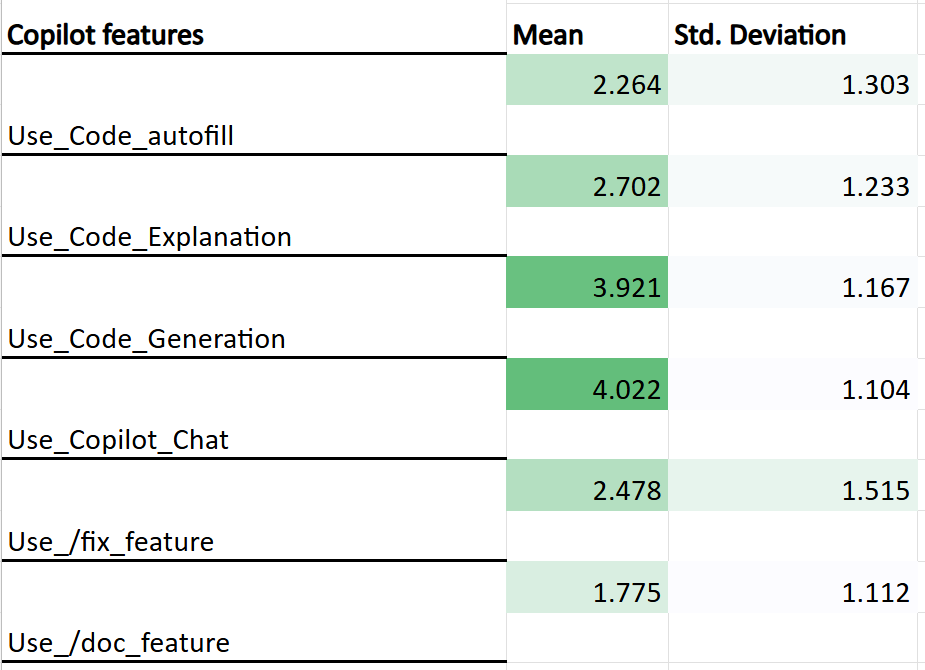
Figure 2: Mean and standard deviation of GitHub Copilot feature usage on the open-source project.
Perceived usefulness was concordant with usage patterns, with the Copilot chat and code generation features again obtaining the highest mean ratings (3.80 and 3.83, respectively). Code explanation received moderate usefulness scores; documentation and error fixing were consistently rated near or below the scale midpoint.
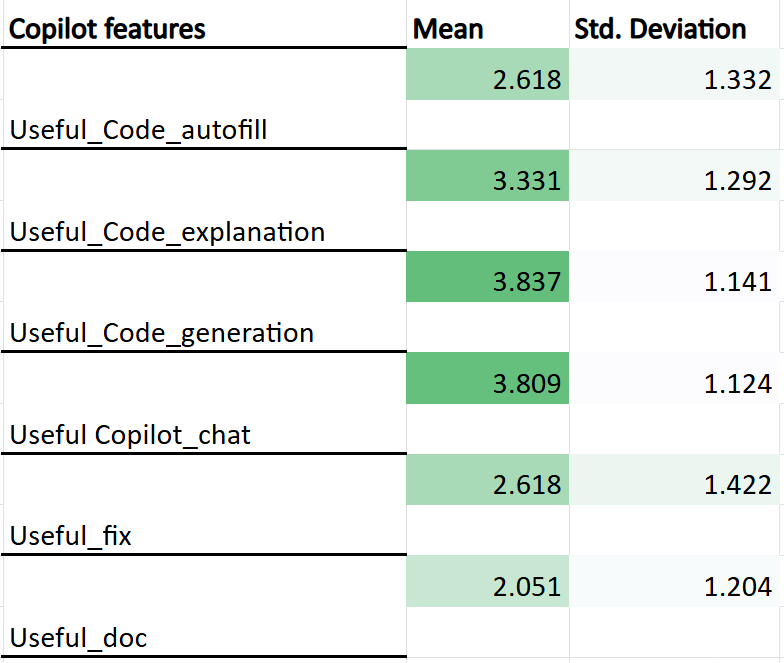
Figure 3: Participants' perceived usefulness ratings for Copilot features on a 1–5 scale.
These findings indicate that open-ended, context-driven assistance modalities—exemplified by chat-based interaction and prompt-driven code synthesis—are prioritized by students navigating ill-structured, authentic programming assignments. This suggests a pronounced preference for features that support high-level ideation and iterative problem-solving in contrast to those facilitating documentation or code hygiene.
Demographic and Experiential Modulation of Usage and Trust
Detailed gender-based analysis documents significant heterogeneity in both feature engagement and perception:
- Code autofill and code explanation: Female students reported statistically higher use and greater perceived utility relative to males.
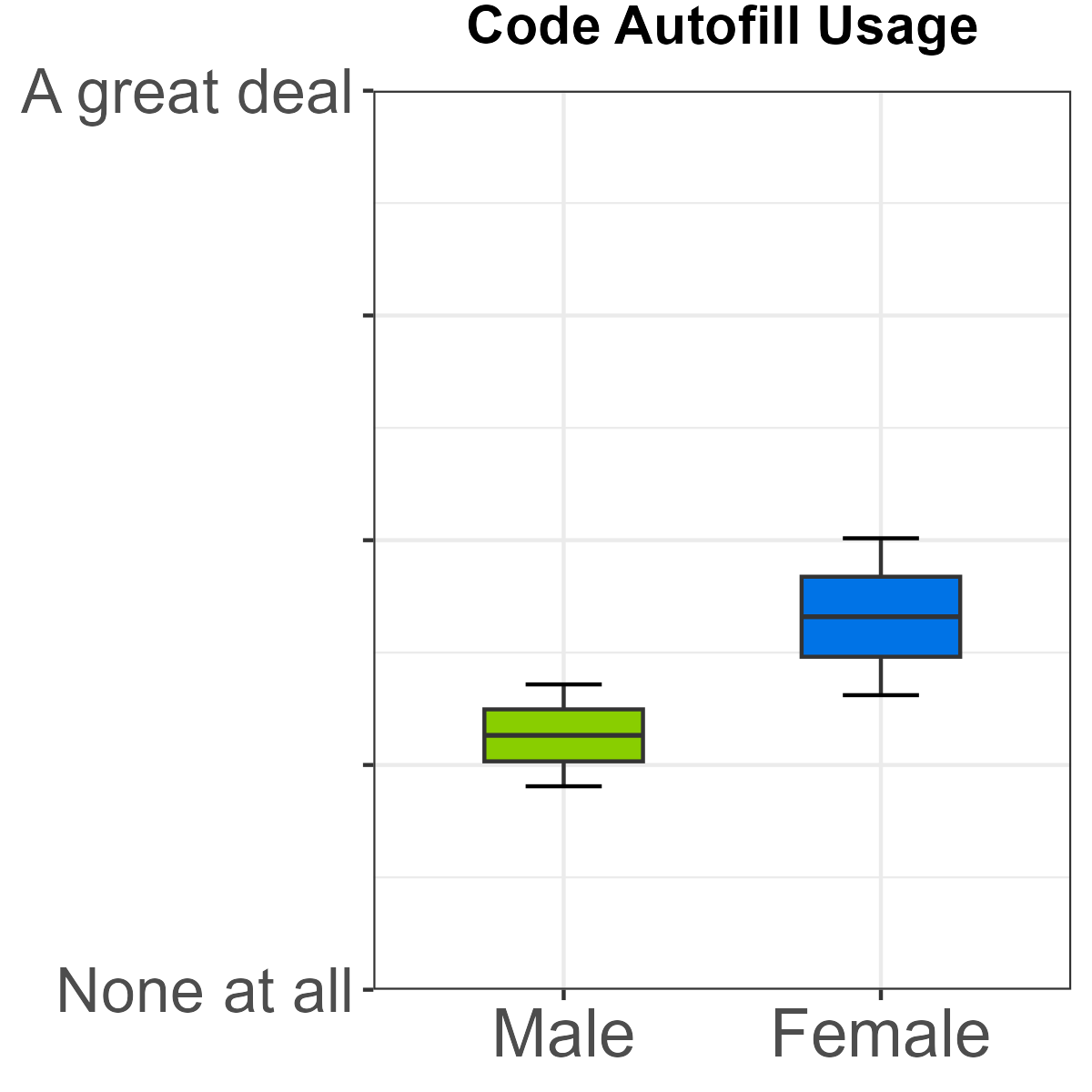
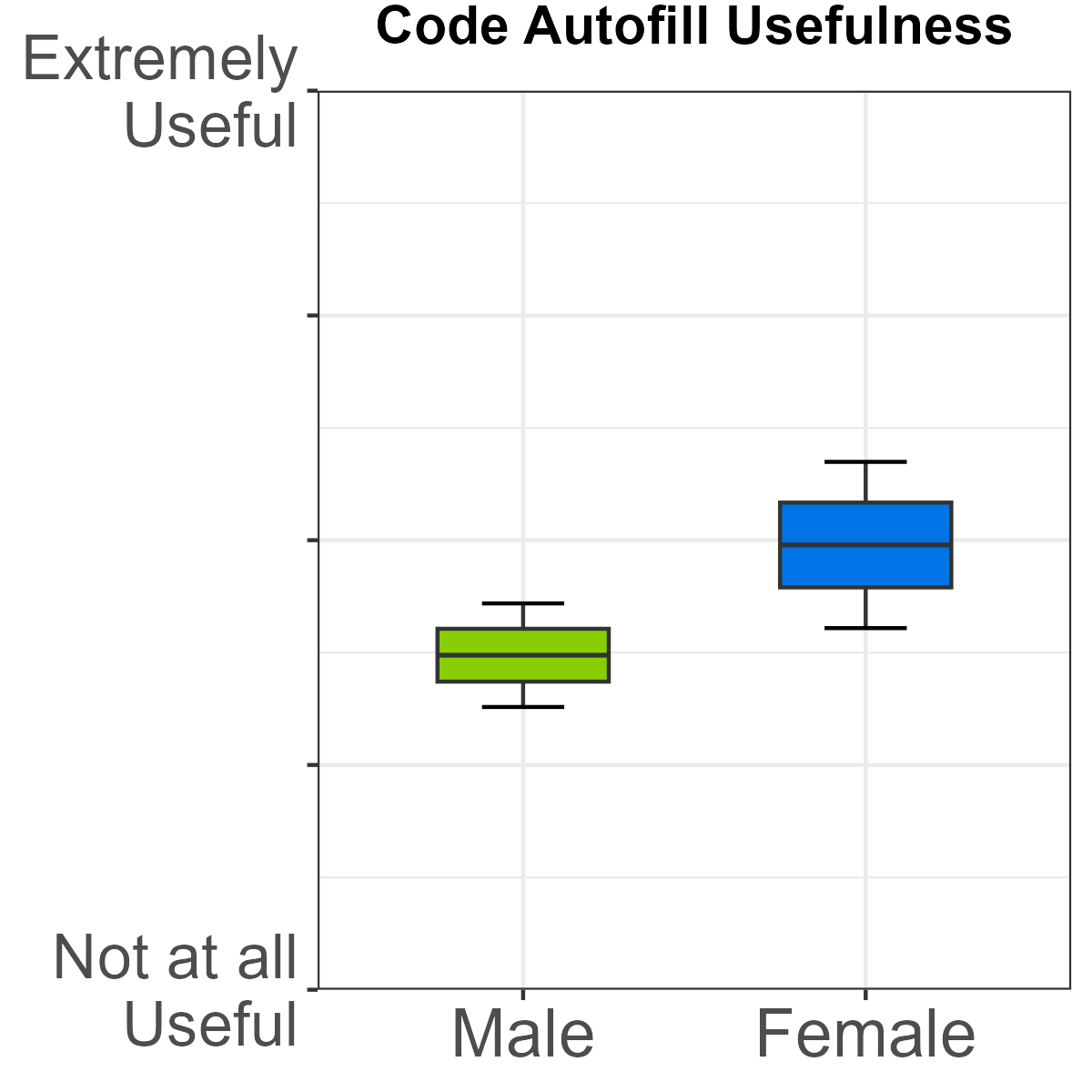
Figure 4: Difference in usage and usefulness of code autofill by gender.
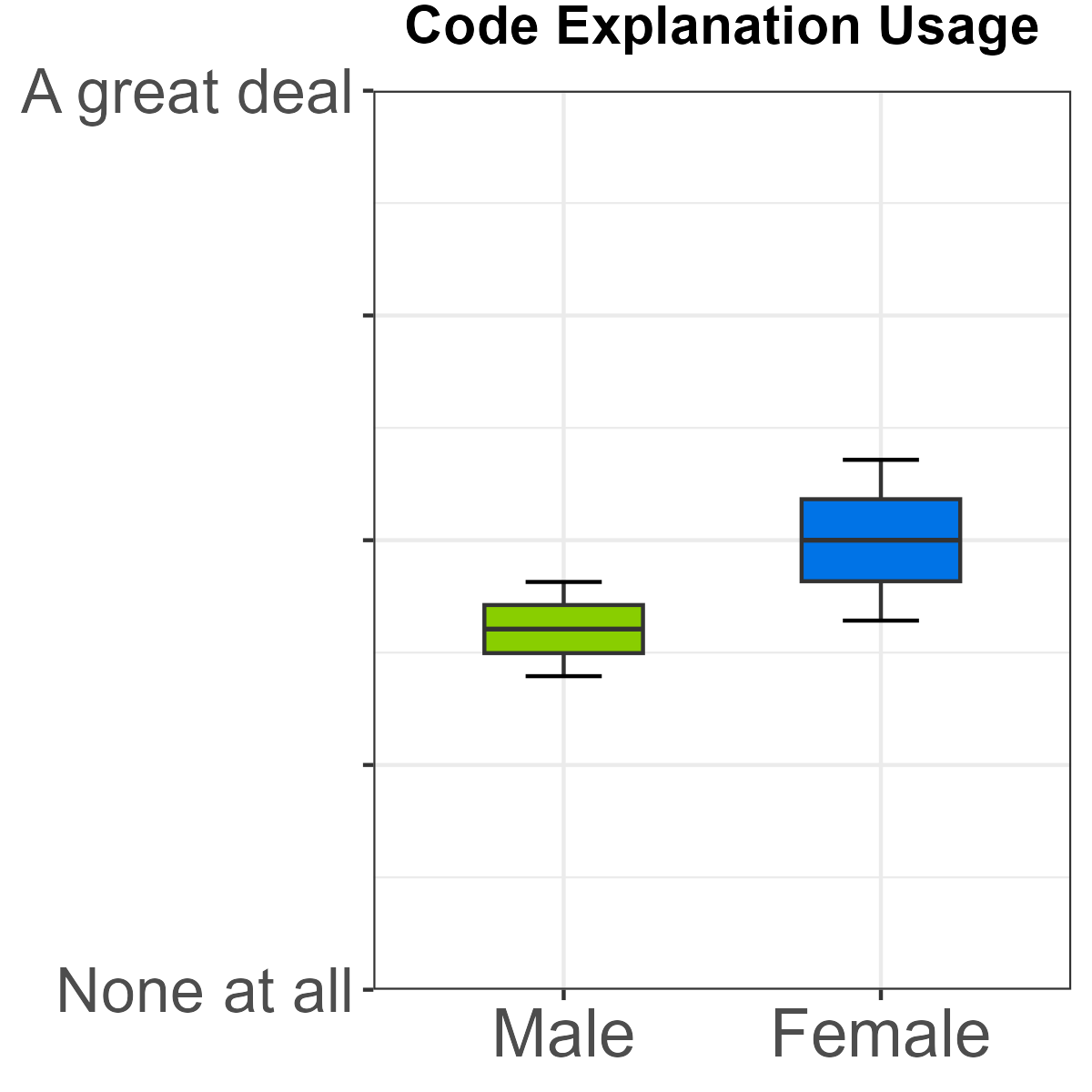
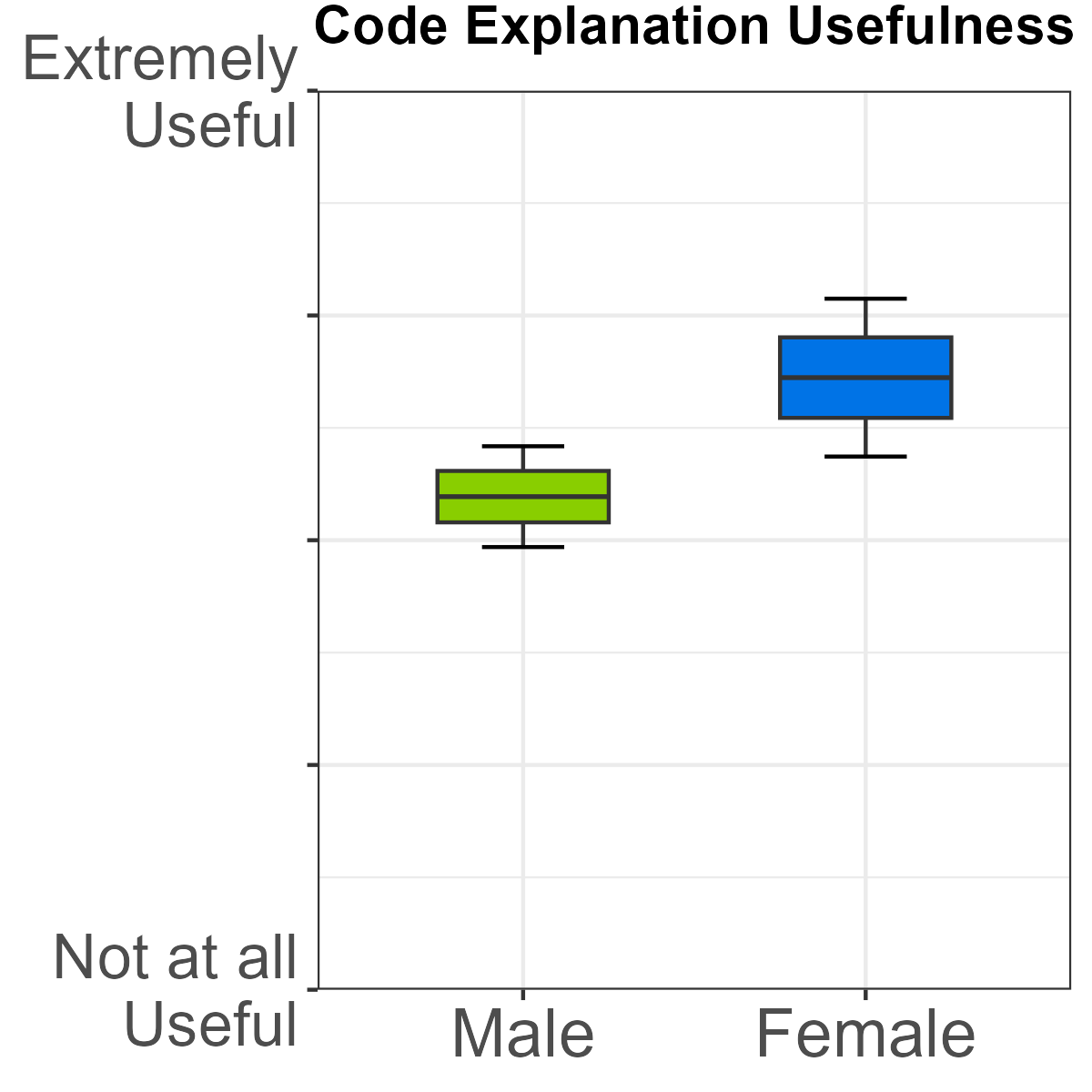
Figure 5: Difference in usage and usefulness of code explanation by gender.
- Code generation: Male students reported both higher usage and higher perceived usefulness compared to female peers.
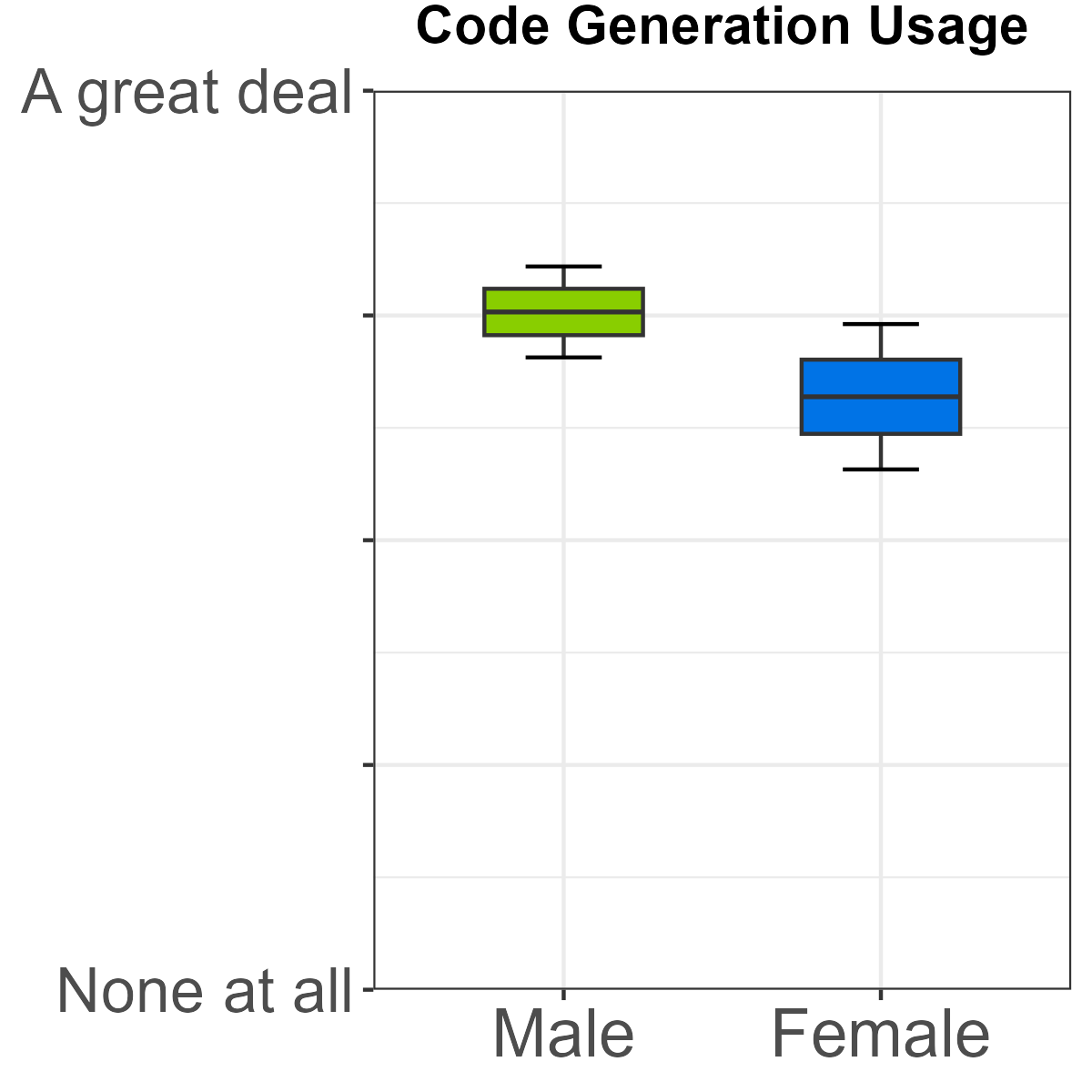
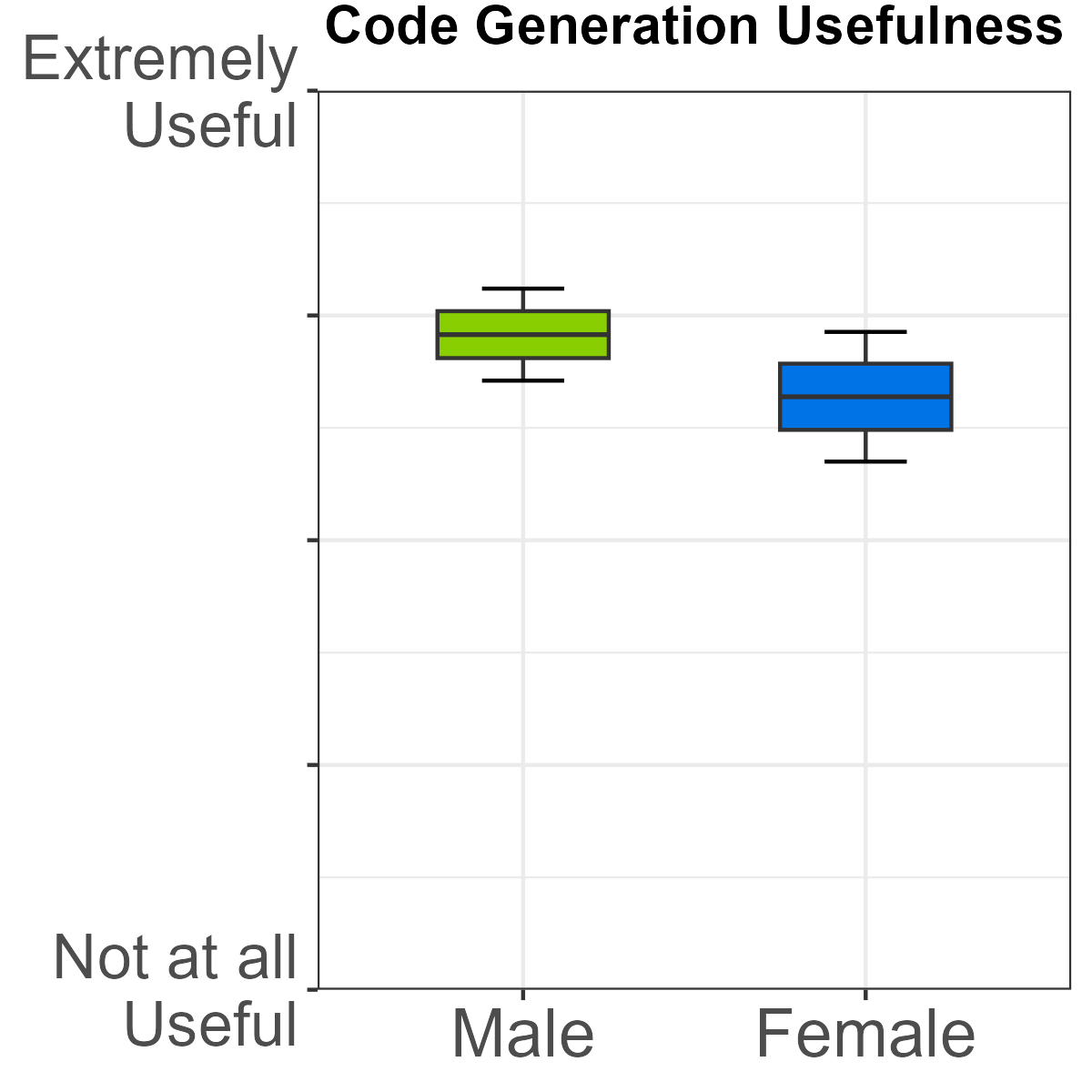
Figure 6: Male students exhibit significantly higher usage and perceived utility for code generation.
In addition, gender differences emerged in broader familiarity with LLMs and AI assistants, aligning with previous literature documenting gender-based discrepancies in AI literacy and adoption [cachero2025gender, iddrisu2025gender]. Male participants were more likely to report familiarity—and assign high utility—to AI coding assistants, with small effect sizes.
Multivariate analyses controlling for programming proficiency and prior familiarity with AI tools reveal further distinctions:
- Students with greater AI assistant experience: Reported higher trust, understandability, and personal attachment toward Copilot, with medium effect sizes.
- Programming proficiency: Highly proficient students used the chat feature more, evidenced greater differentiated faith and reliability in Copilot, and displayed optimal trust calibration.
Collectively, these findings substantiate that both intrinsic familiarity with AI and advanced programming skills drive more nuanced and, arguably, more effective exploitation of generative coding support. Conversely, less-experienced or less-familiar students tend to underutilize advanced Copilot capabilities and fail to calibrate trust appropriately—raising concerns of overreliance or inadequate critical engagement [pitts2025students, vaithilingam2022expectation].
From an educational design perspective, the data illuminate three salient implications:
- Curricular Alignment: High engagement with chat and code generation features indicates that instructional interventions should prioritize not only feature awareness but nuanced, skill-calibrated strategies for prompting and prompt iteration.
- Equity and Inclusion: Gender-differentiated patterns in both familiarity and feature preference demand targeted measures to close AI literacy gaps, ensuring equitable access to the benefits of generative programming support.
- Trust Formation: The positive correlation between prior familiarity and calibrated trust suggests a need for early, guided exposure to AI assistants to scaffold students' development of appropriate mental models and reliance boundaries, mitigating risks associated with overtrust or misunderstanding.
At the tool design level, developers of AI coding platforms might consider adaptive interfaces that recommend features or surface tutorial content dynamically, contingent on detected usage patterns and self-reported proficiency.
Limitations and Future Research Directions
While the present study provides granular insight into real-world, unconstrained usage of GitHub Copilot among students, several limitations must be acknowledged:
- Self-report Bias: Findings are contingent on retrospective participant accounts rather than telemetry-validated interactions.
- Sample Imbalance: Disproportionate representation by gender and skill level circumscribes the generalizability of inference.
- Non-performance Outcomes: The absence of direct connection to assignment quality or skill acquisition precludes conclusions about long-term learning impacts.
Future investigations should integrate fine-grained, in-situ logging of tool interactions with longitudinal follow-up to connect feature usage with measurable programming outcomes. Additionally, studies should examine interventions to enhance AI literacy and calibrate trust, especially among underrepresented populations.
Conclusion
This study demonstrates that engineering students leverage GitHub Copilot in authentic open-source programming tasks with a marked preference for free-form interaction modalities such as chat and code generation. Both feature usage and perceived utility are modulated by gender, prior AI familiarity, and programming proficiency, emphasizing the role of demographic and experiential factors in shaping AI adoption. The findings advocate for deliberate pedagogical and tool-centric interventions to foster equitable, effective use of generative AI in programming education, and underscore the necessity for ongoing research exploring the interplay between AI support, learning processes, and trust formation.