- The paper shows that RL on preference-labeled critic data unifies critic and policy functions, yielding a +5.7% performance boost over base models on 26 benchmarks.
- It introduces a novel RL training method using a weighted sum of preference and format rewards via GRPO, surpassing traditional SFT approaches.
- The study demonstrates that test-time self-critique with recursive candidate comparison improves reasoning tasks by +13.8%, highlighting the synergy between evaluation and generation.
LLaVA-Critic-R1: Unifying Critic and Policy Capabilities in Multimodal Vision-LLMs
Introduction and Motivation
The paper "LLaVA-Critic-R1: Your Critic Model is Secretly a Strong Policy Model" (2509.00676) challenges the entrenched separation between critic and policy models in vision-language modeling (VLM). Traditionally, critic models are trained to evaluate outputs—assigning scalar scores or pairwise preferences—while policy models are optimized to generate responses. This work demonstrates that reinforcement learning (RL) on preference-labeled critic data can yield a single model that excels both as a critic and as a policy, with strong empirical results across a wide range of visual reasoning and understanding benchmarks.
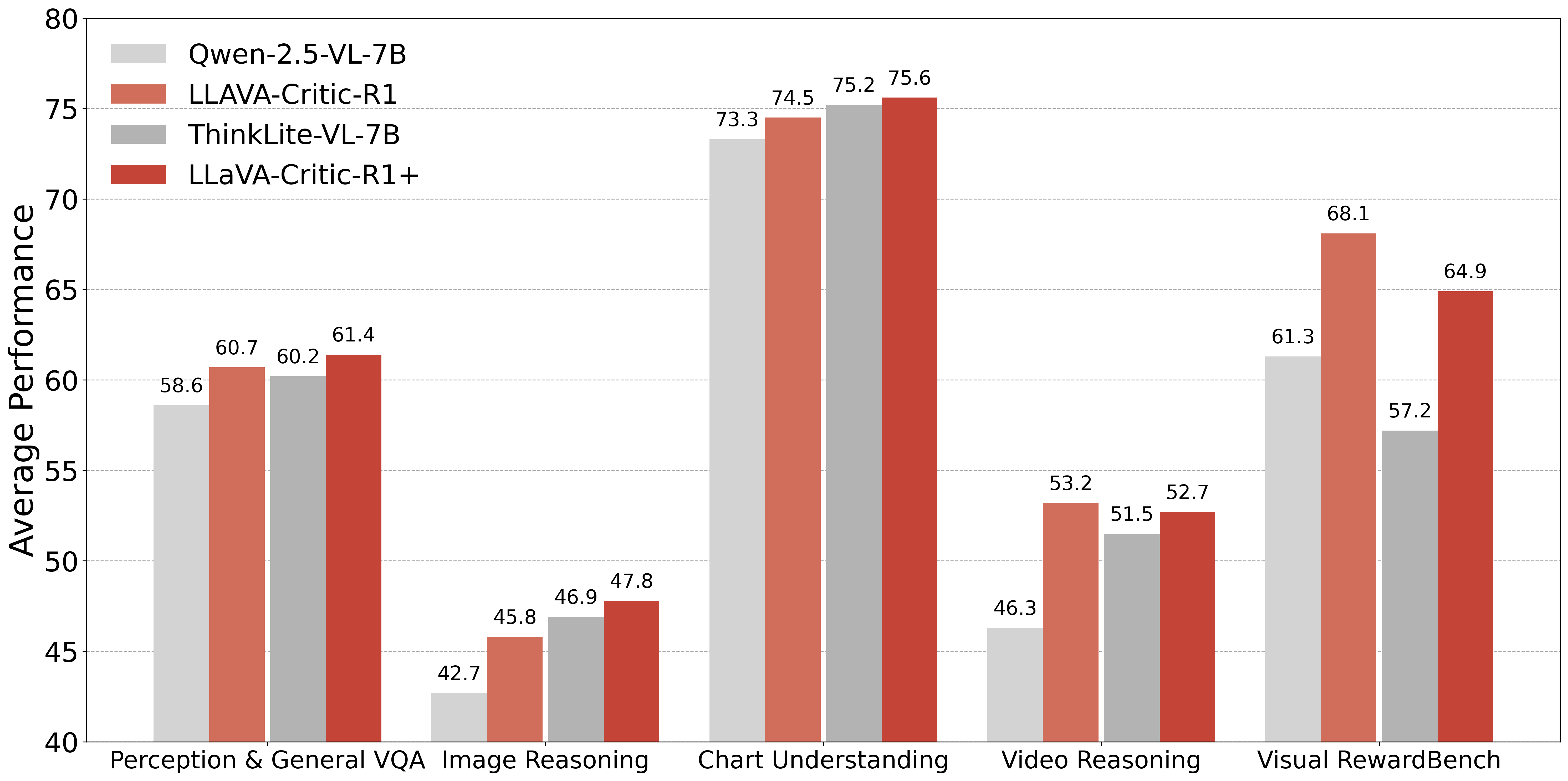
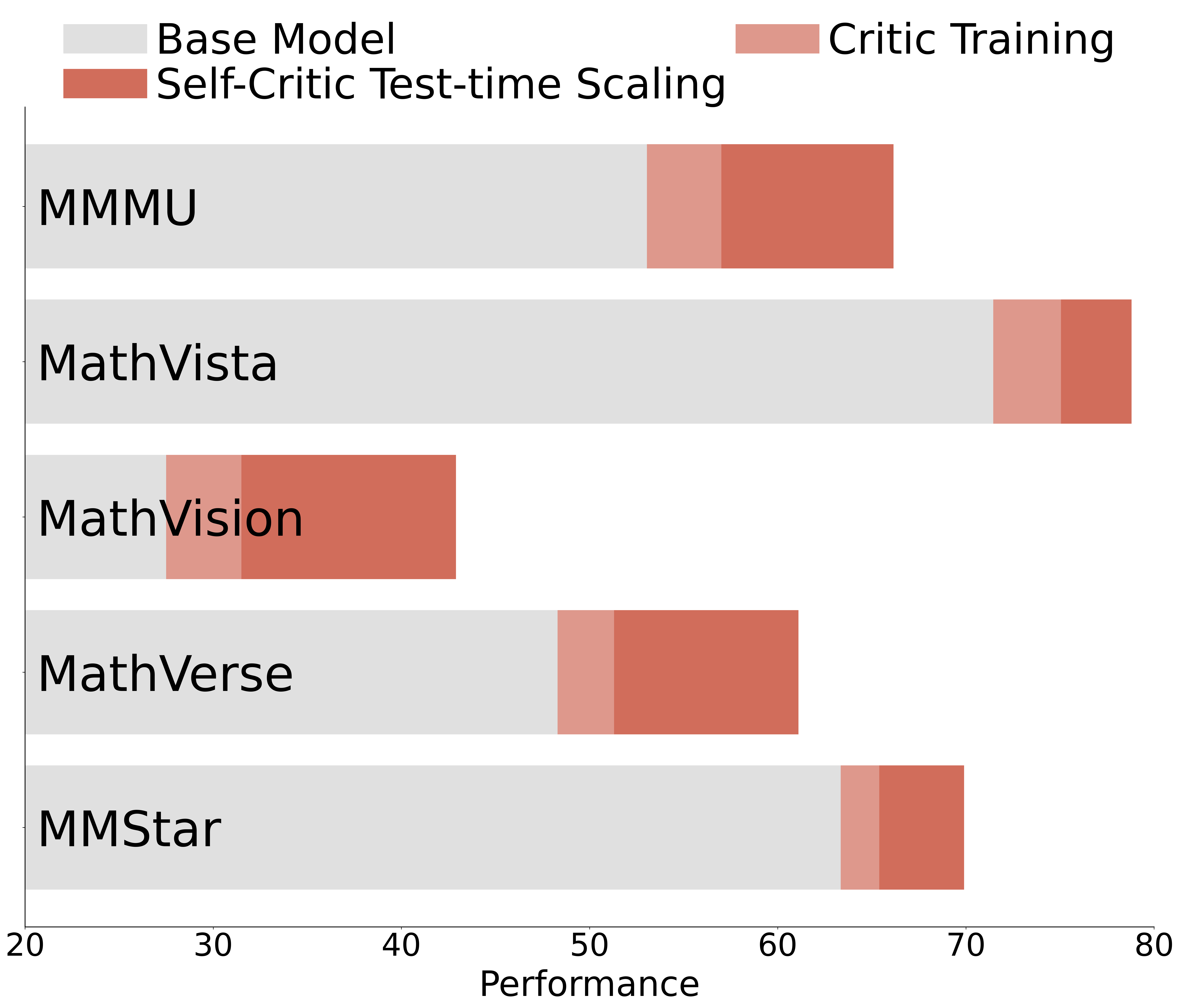
Figure 1: LLaVA-Critic-R1 is trained on top of the base model Qwen-2.5-VL-7B. Building upon a stronger reasoning VLM, ThinkLite-VL-7B, we further develop LLaVA-Critic-R1+ by applying the same RL critic training procedure.
The core methodological innovation is the reformulation of standard pairwise critic datasets into verifiable RL tasks. Each data point consists of an image, a question, two candidate responses, and a preference label. Unlike prior SFT-based approaches that leverage chain-of-thought (CoT) rationales generated by large models (e.g., GPT), this work discards external rationales to avoid knowledge distillation bias and to encourage autonomous reasoning.
The RL objective is defined as a weighted sum of a preference reward (matching the ground-truth preference) and a format reward (adherence to a "think-then-answer" output structure). The model is trained using Group Relative Policy Optimization (GRPO), with the reward function:
r=α⋅rpref+(1−α)⋅rformat
where rpref is 1 if the model's preference matches the ground truth, and rformat is 1 if the output format is correct. This design enforces both verifiable decision-making and structured reasoning.
Empirical Results: Dual Critic and Policy Gains
LLaVA-Critic-R1, trained on Qwen-2.5-VL-7B with 40k critic data, achieves an average gain of +5.7% over its base model across 26 visual reasoning and understanding benchmarks. When the same RL critic training is applied to a stronger reasoning VLM (ThinkLite-VL-7B), the resulting LLaVA-Critic-R1+ achieves state-of-the-art (SoTA) performance, notably 71.9 on MMMU at the 7B scale.
The model demonstrates robust improvements not only in critic benchmarks (e.g., VLRewardBench, MM-RLHF) but also in general policy tasks, including perception, chart understanding, and video reasoning. Notably, policy training alone degrades critic ability, while critic RL training enhances both roles simultaneously—a contradictory finding to standard practice.
Test-Time Self-Critic Scaling
The unified critic-policy capability enables effective test-time scaling via self-critique. At inference, the model generates n candidate responses and recursively selects the best via pairwise self-comparison, leveraging its critic head. This "Best-of-128" self-critic approach yields an average +13.8% improvement on five representative reasoning tasks, outperforming majority vote and base model critic baselines.
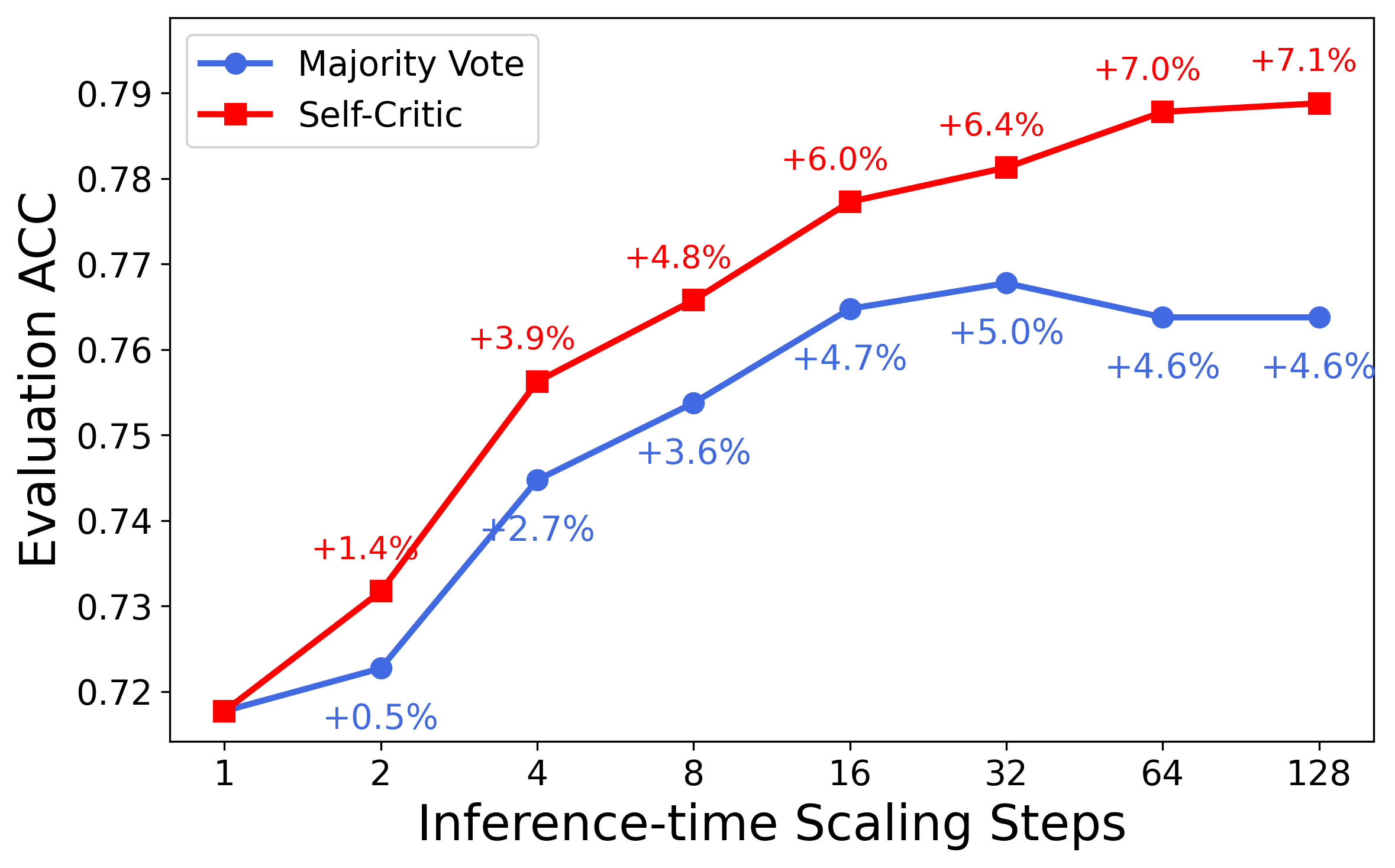
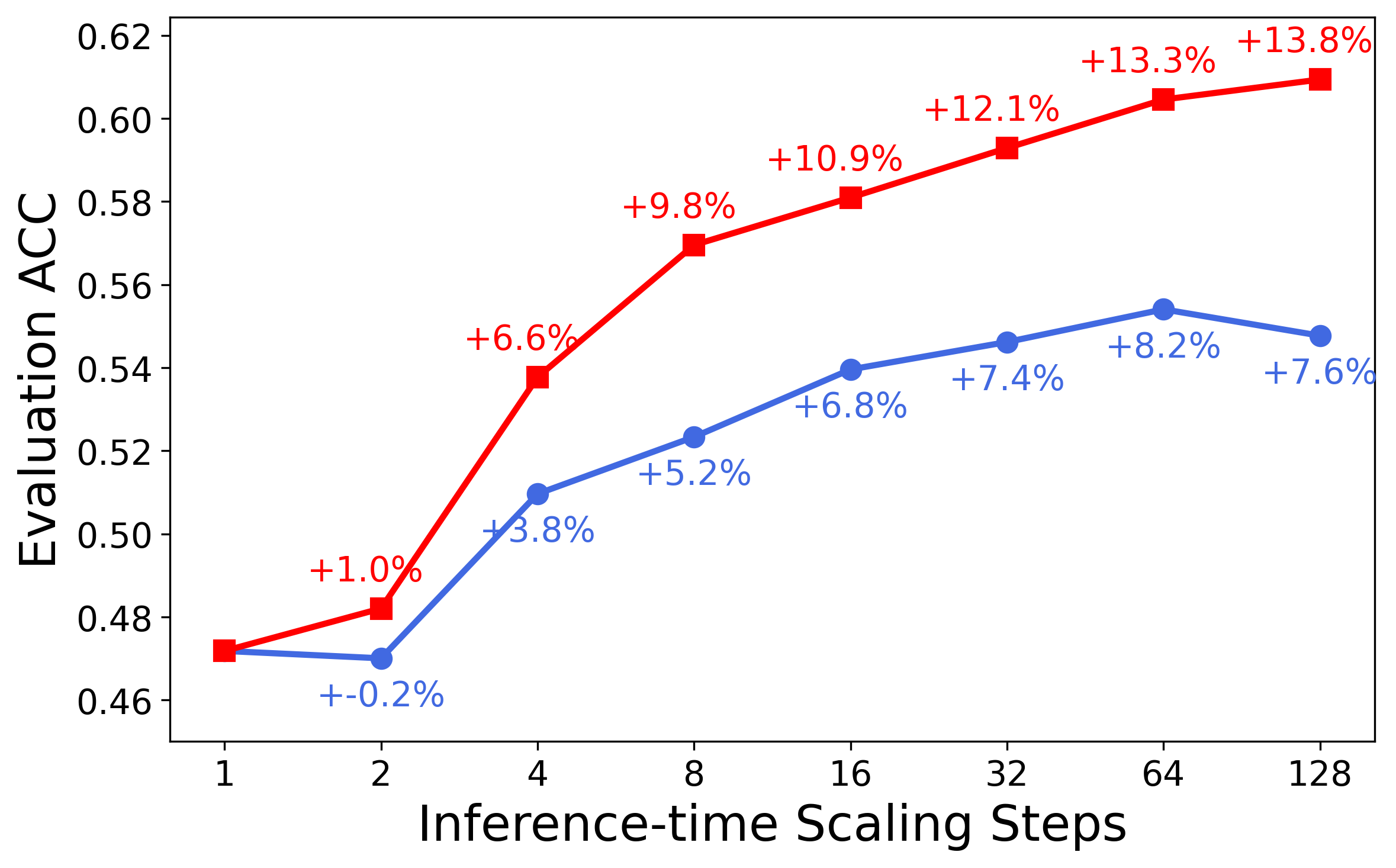
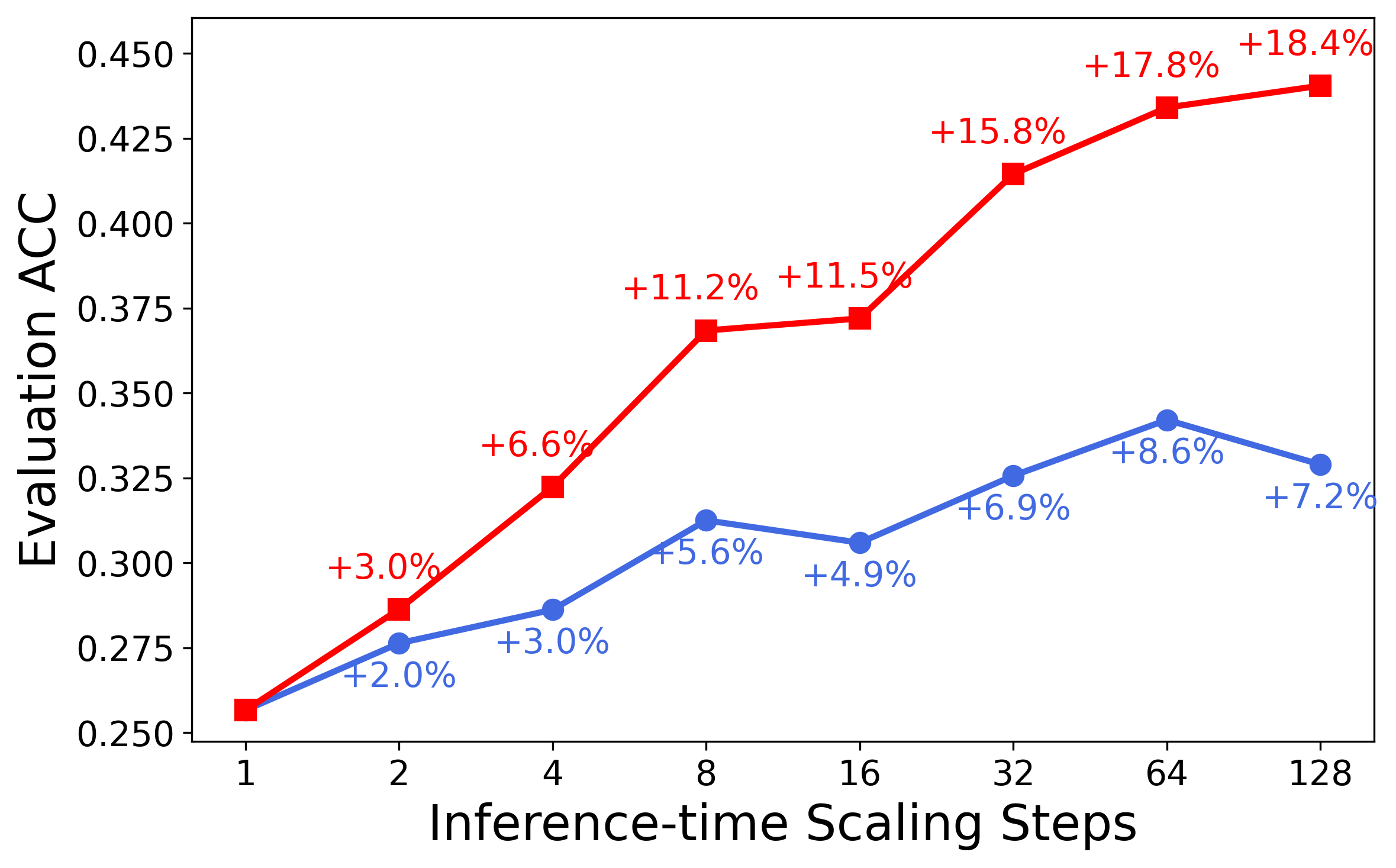
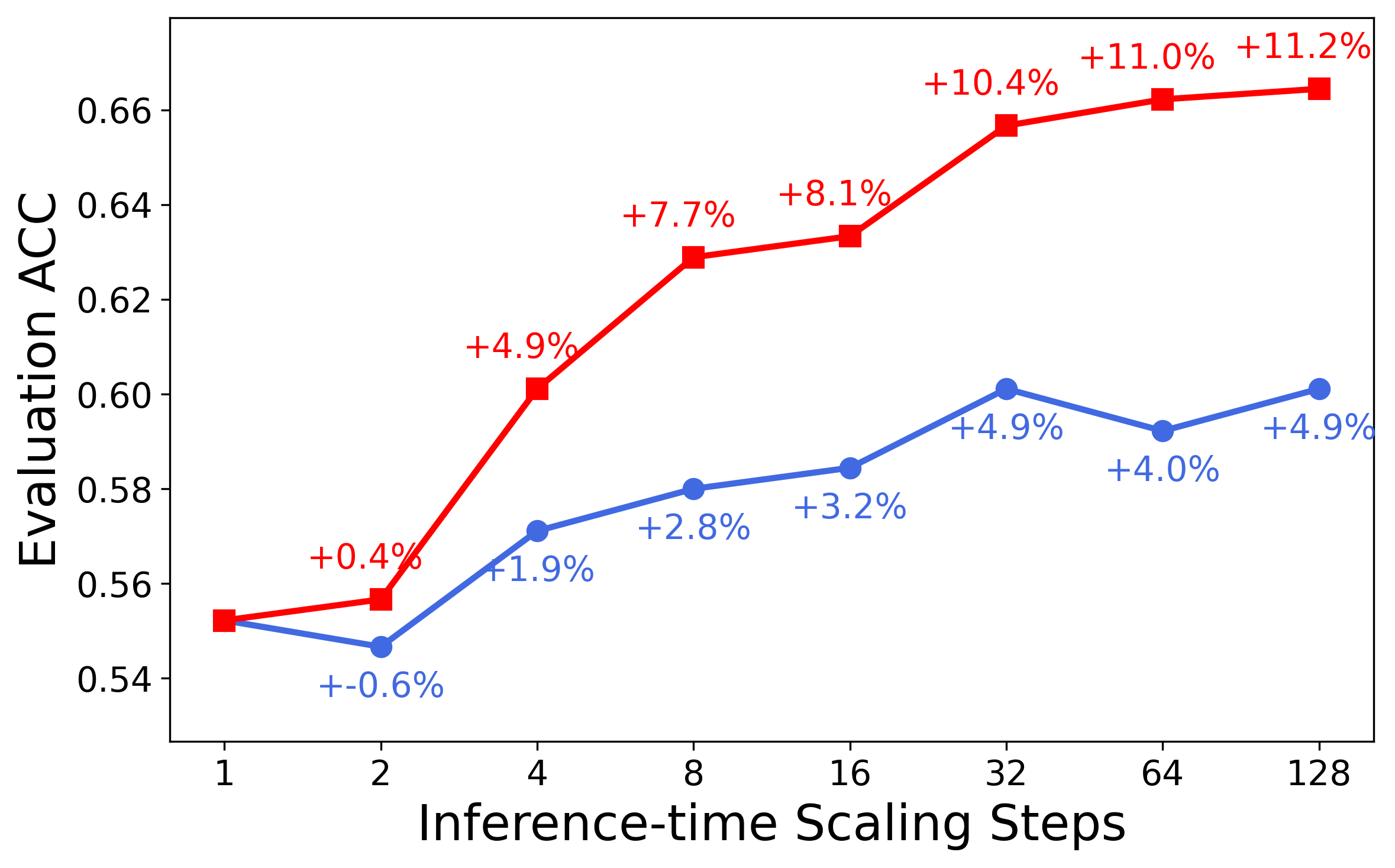
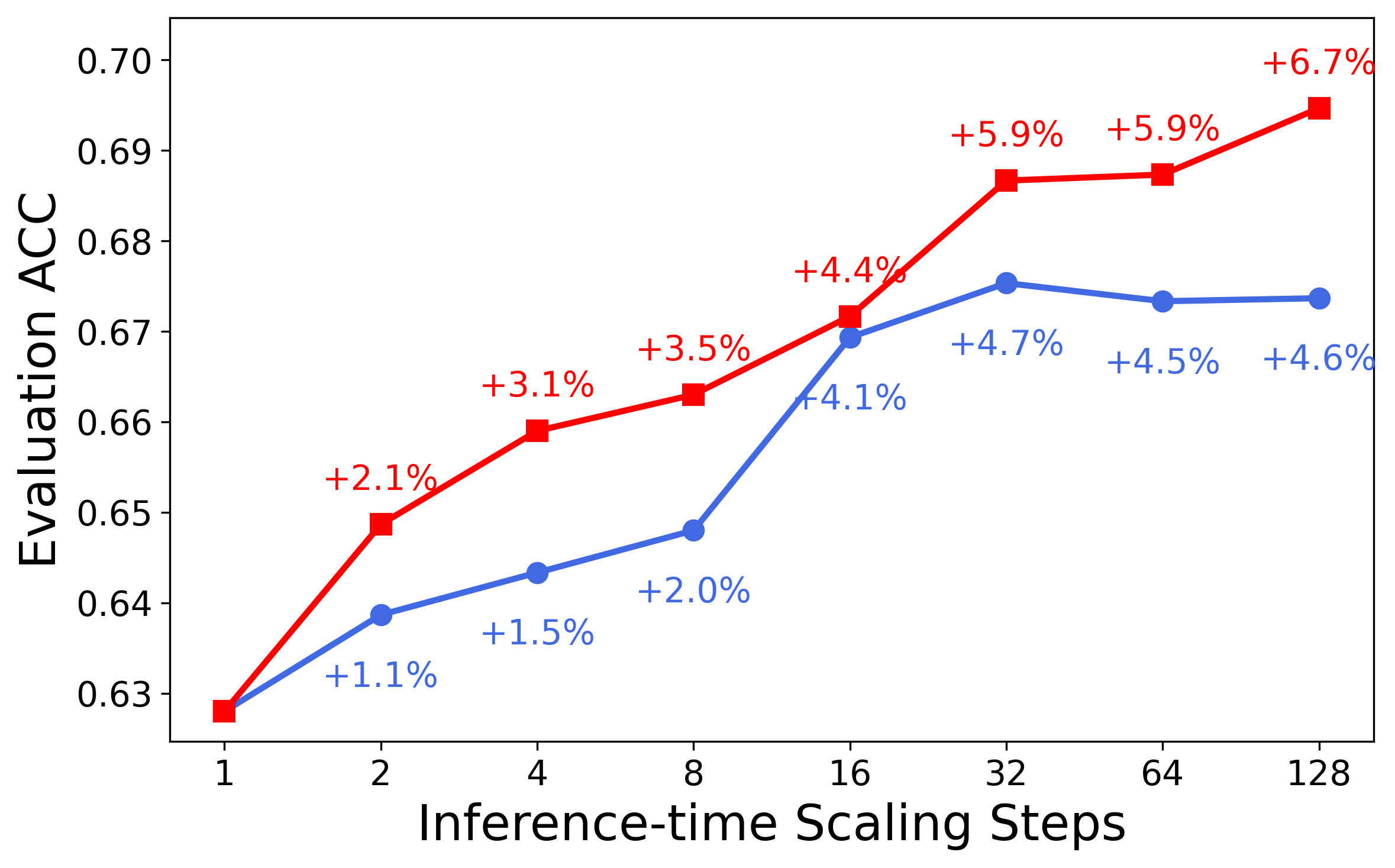
Figure 2: MathVista—one of the challenging benchmarks where LLaVA-Critic-R1 demonstrates strong reasoning performance.
Analysis: Why Does Critic Training Improve Policy?
Ablation studies reveal two synergistic mechanisms:
- Enhanced Visual Perception: The critic dataset, constructed from diverse VLM outputs, forces the model to distinguish subtle differences and hallucinations, improving grounding and perception.
- Structured Reasoning: The enforced "think-then-answer" format, both at training and inference, strengthens stepwise reasoning, which is critical for complex visual tasks.
Experiments show that simply prompting the base model with the thinking template or training with format reward alone yields only marginal gains. In contrast, full critic RL training delivers substantial improvements in both perception and reasoning domains.
Critic-Policy Training Synergy and Data Utilization
The paper systematically explores training strategies combining critic and policy data. The optimal approach is policy-then-critic: first train a strong reasoning model, then apply critic RL training. This yields the best balance, recovering critic ability lost during policy training and further boosting policy performance.
Supervised fine-tuning (SFT) on CoT critic data, even with full-parameter updates, does not match the generalization or critic performance of RL-based training. RFT (reinforcement fine-tuning) from a strong policy checkpoint is most effective for unifying both capabilities.
A key empirical finding is the strong positive correlation between critic and policy performance during RL training. Improvements in critic ability (as measured on reward benchmarks) are directly linked to gains in policy performance on general tasks, up to the point where overfitting may cause divergence.
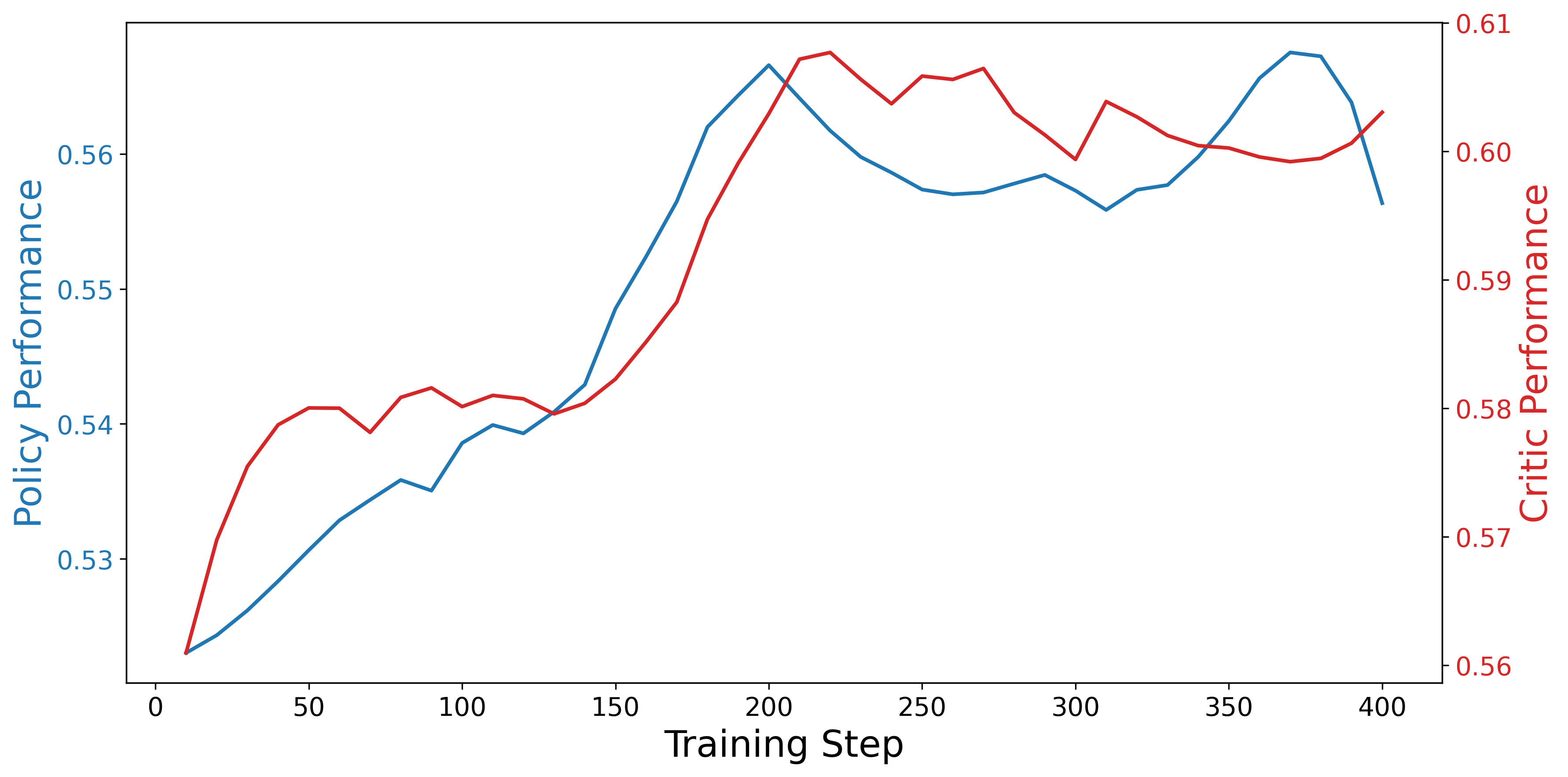
Figure 3: Correlation between LLaVA-Critic-R1's critic and policy performance during RL training, showing strong positive alignment between the two capabilities.
Implications and Future Directions
This work demonstrates that RL on preference-labeled critic data can produce a single VLM that is both a top-tier evaluator and a competitive generator. The approach is model-agnostic, yielding consistent gains when applied to different base architectures (e.g., MiMo-VL, LLaMA-3.2-Vision). The findings suggest that the traditional separation between critic and policy models is unnecessary and potentially suboptimal.
Practically, this enables scalable, self-improving multimodal systems that can generate, evaluate, and self-improve without reliance on external verifiers or retraining. The self-critic scaling paradigm offers a compute-efficient alternative to massive search or ensemble methods at inference.
Theoretically, the results motivate further investigation into the mutual reinforcement of evaluation and generation capabilities, the design of verifiable RL tasks for multimodal data, and the development of models with intrinsic judgment and self-improvement abilities.
Conclusion
LLaVA-Critic-R1 establishes that RL-based critic training is a simple yet effective path to unifying policy and critic capabilities in VLMs. The model achieves SoTA results across diverse benchmarks, with strong evidence that critic ability and policy performance are deeply intertwined. This paradigm shift has significant implications for the design of future multimodal AI systems, suggesting that self-improving, unified architectures are both feasible and advantageous.