- The paper finds that ablating a shared core in multilingual LLMs causes a drastic drop in neural predictivity and sentence-level linguistic competence.
- It employs gradient-guided lesioning on models like LLaMA2, Qwen2.5, and Mistral to isolate and measure the effects on representational geometry and fMRI alignment.
- Language-specific lesions reveal selective disruptions tied to typological similarities, indicating graded representational overlaps across English, Chinese, and French.
Causal Evidence for Shared and Language-Specific Brain Alignment in Multilingual LLMs
Introduction
This paper ("Computational Lesions in Multilingual LLMs Separate Shared and Language-specific Brain Alignment" (2604.10627)) addresses the organization of multilingual processing in the human brain and establishes a causal framework using computational lesions in multilingual LLMs. Through precise ablation of core and language-specific parameter subsets, the authors dissect the impact of these manipulations on representational structure, linguistic competence, and, critically, the model's ability to account for native-language neural activity as measured by fMRI across English, Chinese, and French.
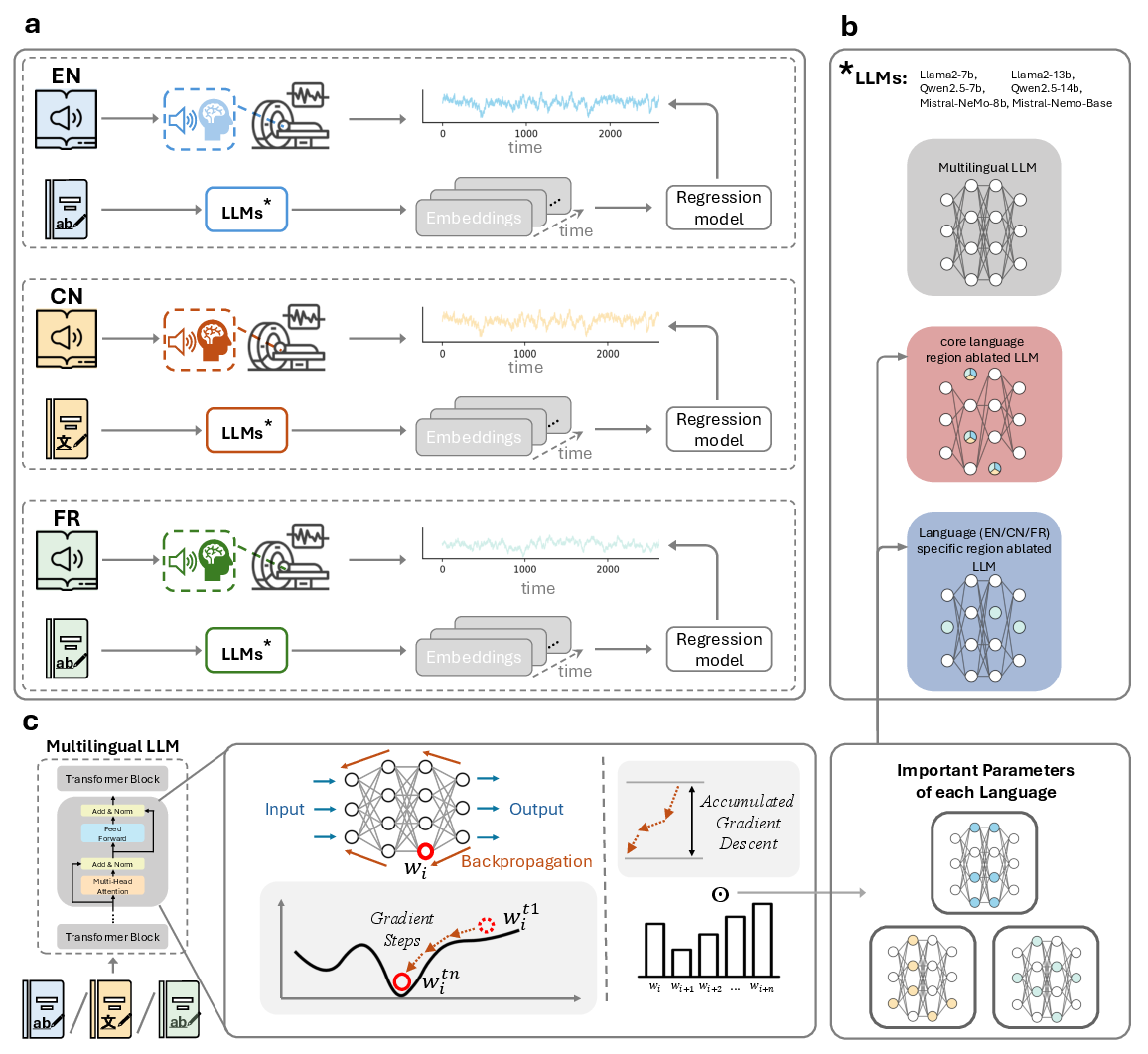
Figure 1: Overview of the multilingual neural encoding framework and the gradient-guided computational lesioning procedure for assessing language-specific and shared subcircuits.
Methods and Lesion Paradigm
The authors utilize six decoder-only transformer-based LLMs spanning LLaMA2, Qwen2.5, and Mistral families at two parameter scales each (7B to 14B). Core and language-specific subnetworks are identified via full-parameter fine-tuning on naturalistic, typologically diverse corpora. Gradient-weight saliency is accumulated separately for each language, and parameters in the top 1% of importance (for either the core or for each language-specific profile) are ablated across model layers and computational components.
Lesioned and intact LLMs provide contextualized final-layer embeddings for audiobook narratives (The Little Prince) in each native language, which serve as features for voxel-wise encoding models predicting BOLD fMRI responses. Performance is quantified by cross-validated Pearson correlation between predicted and observed neural time series. The causal effect of each ablation is assessed through direct comparison to the intact model.
Cross-Linguistic Predictivity and Shared Cortical Substrates
All evaluated multilingual LLMs, despite architectural and training divergences, yield high encoding accuracy within established language-selective neural circuits, especially left-hemispheric temporal cortex. Region-wise analysis reveals reliable cortical alignment for LLM-derived embeddings across English, Chinese, and French native listeners, implicating a universal computational substrate for narrative comprehension and cross-linguistic generalizability.
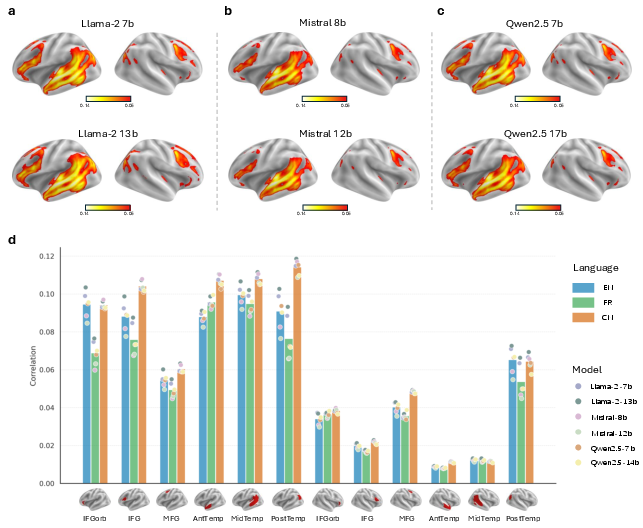
Figure 2: Cortical maps and ROI encoding analyses demonstrate robust, left-lateralized model-brain alignment across languages and LLM families.
Core Lesions: Catastrophic Loss of Representational and Neural Alignment
Ablation of the compact, gradient-defined core parameter subset (top 1% across all languages) induces a marked collapse of internal representational geometry. Uniform Manifold Approximation and Projection (UMAP) projections show that language-specific embedding clusters compress and partially overlap, quantitatively measured by a precipitous drop in Silhouette Coefficient (Δ=0.3683).
Critically, there is a mean 60.32% reduction in whole-brain encoding correlation following core ablation—a profound loss of neural predictivity that is highly localized to canonical language areas (bilateral superior temporal and inferior frontal cortex). Sentence-level linguistic competence is also severely diminished on multilingual structural probing tasks, implicating these parameters in both hierarchical structure formation and syntactic/semantic abstraction.
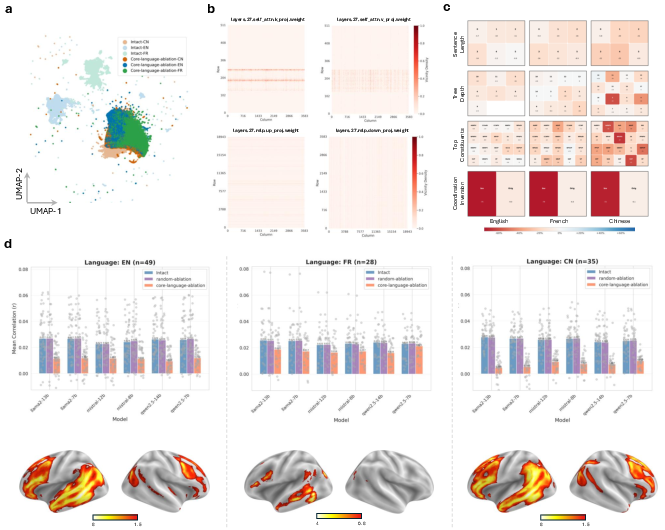
Figure 3: Disruption of the core subnetwork leads to collapse in representational geometry, widespread impairment in language probing tasks, and dramatic reduction in fMRI predictivity localized to established language-selective cortex.
Language-Specific Lesions: Selective and Graded Effects
Removal of language-specific parameter subsets (top 1% for each language, with mutually exclusive selection) produces a contrasting pattern. Embedding space maintains separation across languages; however, only the lesioned language manifold is reorganized. In encoding models, these lesions elicit selective reductions in neural predictivity tightly matched to the ablated language, particularly within native-language participants’ canonical language regions.
Across models, the reduction from language-specific lesions is less than that from core ablation and is spatially more fragmented. Notably, cross-language effects reflect typological kinship: English- and French-specific lesions show greater mutual impact than either does with Chinese, evidencing graded representational overlap and transfer consistent with genealogical and structural linguistic similarity. These results are corroborated by the Language Processing Index (LPI), which quantifies relative sensitivity of cortical voxels to language-specific vs. core lesions.
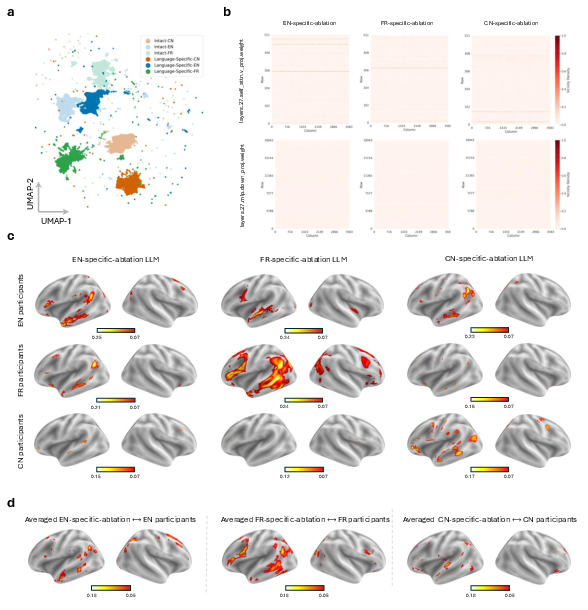
Figure 4: Language-specific lesions reorganize the lesioned language’s embedding manifold and induce spatially confined, language-matched degradations in cortical alignment.
Convergent Effects Across Models and Participants
Lesion effects are robust across LLM architectures and model sizes, supporting that the hybrid—core-and-specialization—organization is not an artifact of idiosyncratic properties. Whole-brain t-map projections indicate spatial convergence of lesion effects across participants and languages, emphasizing distributed but functionally critical circuits for shared and language-specific processing.
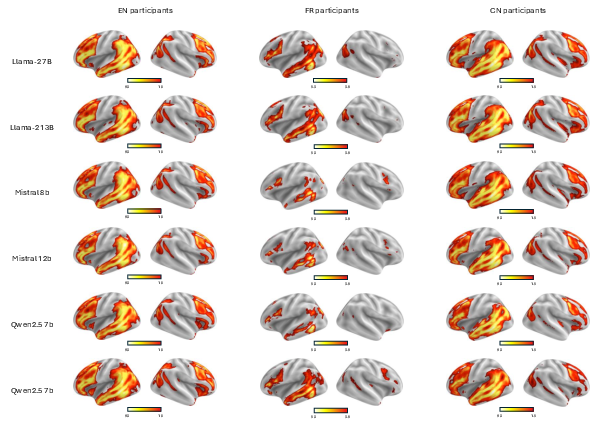
Figure 5: Group-level t-maps for core ablation demonstrate widespread and convergent loss of encoding strength across participant groups and LLMs, emphasizing the universal function of the shared core.
Theoretical and Practical Implications
The findings enforce a hybrid account of multilingual cortical computation: a compact and distributed core backbone underlies both model and neural representations across languages, with embedded, partial specializations imparting language-specific tuning. The use of gradient-guided lesions provides causal evidence for the necessary contribution of these parameter sets to brain-model alignment, shifting analyses from correlational to mechanistic paradigm.
This sparsity principle suggests that only a limited subset of weights—distributed across transformer layers and components—is critical for brain-like computation. Such concentration of function has strong implications for interpretability, modularity, and network pruning strategies in scaling LLMs. The language-specific circuit mapping enables future testing of typological similarity, L2 effects, or pathological dissociation in bilinguals/multilinguals, with possible extension to a large language typology and fine-grained lesion mapping (e.g., attention heads vs. MLP subcircuits).
Limitations
The study’s interpretation is constrained by potential confounds inherent to ablation-induced global degradation, stimulus properties, and recording site differences. However, within-group comparative methodology, inclusion of random ablation controls, and robust cross-architectural replication mitigate the nonspecific effect hypothesis. Further work is needed to extend stimulus and language typology, implement dose-response lesioning, or integrate temporally resolved neural recordings for dynamic mapping.
Conclusion
This work demonstrates that computational lesioning in state-of-the-art multilingual LLMs supports a hybrid model of brain-language alignment, jointly revealing distributed shared computational backbones and embedded, graded specializations. Core ablation yields catastrophic representational and neural impairment; language-specific lesions effect targeted, language-matched reduction. These results deliver mechanistic constraints on the intersection of artificial multilingual computation and the cortical language network, providing tools and frameworks for future causal dissection of brain-model alignment.

