- The paper introduces an adaptive spatial-spectral framework that integrates high-resolution multispectral details with low-resolution hyperspectral spectral fidelity.
- It employs a three-level pyramidal multi-scale generator with specialized SpaCAM and SpeCAM modules for dynamic feature extraction and fusion.
- Empirical results on standard benchmarks demonstrate improved PSNR, SSIM, and reduced spectral errors, highlighting the method’s robustness and efficiency.
CoFusion: Multispectral and Hyperspectral Image Fusion via Spectral Coordinate Attention
Introduction
CoFusion presents a unified spatial-spectral collaborative framework for Multispectral and Hyperspectral Image Fusion (MHIF), targeting the long-standing challenge of reconstructing high-resolution hyperspectral images (HRHSI) by effectively integrating the spectral richness of low-resolution HSI (LRHSI) with the spatial detail of high-resolution multispectral images (HRMSI). Traditional and even recent deep learning approaches are challenged by the scale discrepancy between modalities and struggle to balance spatial detail enhancement with spectral fidelity due to limited cross-scale and cross-modal feature interaction. CoFusion directly addresses these limitations by introducing explicit cross-scale and cross-modal coupling, an adaptive collaborative mechanism, and joint feature selection at multiple receptive fields.
CoFusion Architecture and Components
The proposed framework implements a three-level pyramidal multi-scale generator (MSG) pipeline precisely tuned for collaborative spatial-spectral reconstruction.
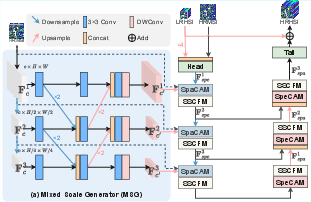
Figure 1: Overall architecture of CoFusion featuring a three-level MSG pipeline with dual-path coordinate-aware modules for collaborative spatial-spectral fusion.
Within each scale of the MSG, two specialized modules operate in parallel:
- SpaCAM (Spatial Coordinate-Aware Mixing) for spatial context extraction
- SpeCAM (Spectral Coordinate-Aware Mixing) for frequency-domain spectral processing
The outputs are subsequently fused using the Spatial-Spectral Cross-Fusion Module (SSCFM), enabling dynamic alignment and interaction of spatial and spectral representations.
Multi-Scale Generator (MSG)
MSG realizes hierarchical multi-scale representation, propagating both local and global context, and ensuring effective cross-scale alignment. Local spatial features are downsampled and encoded while global proxy features are upsampled and processed in parallel, facilitating lateral feature flow between HRMSI and LRHSI branches.
SpaCAM: Adaptive Spatial Detail Refinement
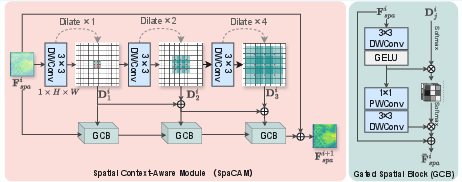
Figure 2: Structure of SpaCAM, showing depthwise separable convolutions with multi-rate dilation and the Gated Spatial Block mechanism for adaptive spatial context extraction.
SpaCAM is designed to support robust extraction and adaptation to spatial detail variations present in real HSI/RSI scenarios, especially for edge-dense or texture-rich regions. It employs cascaded, multi-dilated depthwise separable convolutions, supporting a wide effective receptive field without a proportional parameter increase. These outputs are then selectively filtered and amplified by a learnable gated mechanism (GSB), dynamically modulating feature emphasis based on regional content saliency, effectively reducing edge blurring and preventing local spatial over-smoothing.
SpeCAM: Frequency-Domain Spectral Modeling
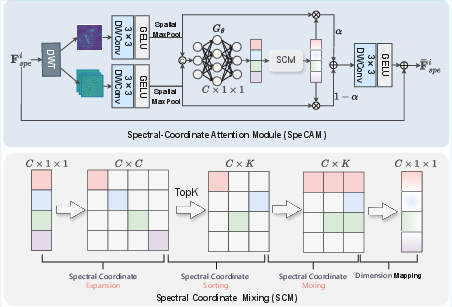
Figure 3: SpeCAM module, including frequency-domain decoupling and coordinate-based traversal for dynamic spectral correlation and innovation extraction.
SpeCAM is responsible for capturing inter-band and intra-band correlations at different frequency levels. It decomposes input spectral tensors using DWT into low- and high-frequency components. Channel saliency is extracted post-GELU nonlinear activation. The core Spectral Coordinate Mixing (SCM) mechanism constructs a dense C×C correlation space, applies a Top-K strategy to focus on informative coordinates, and updates each channel in a left-to-right traversal enforcing continuity except for locally detected innovations. The final spectral representation is composed via learned fusion weights, ensuring both physical continuity and selective enhancement of significant spectral features.
SSCFM: Dynamic Spatial-Spectral Fusion
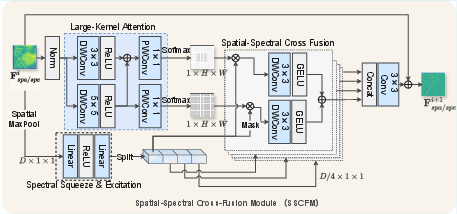
Figure 4: SSCFM architecture, integrating large-kernel spatial attention and spectral squeeze-excitation, supporting fine-grained cross-modal feature selection and residual refinement.
SSCFM employs spatial and spectral attention branches coupled via a channel-split cross-fusion operator. Large-kernel convolutions in the spatial path aggregate multiscale spatial cues, while the SSE branch excites and reweights channel-grouped spectral features. Spatial-spectral flows are split, interact at reduced scale for efficiency, and then reaggregated. A controlled dropout mechanism further regularizes the interaction against input corruption, ensuring robust fusion logic.
Experimental Analysis
The method is systematically evaluated over the Chikusei, CAVE, and PaviaU benchmarks at varying scale factors (×2, ×4, ×8), including settings with severe spatial degradation.
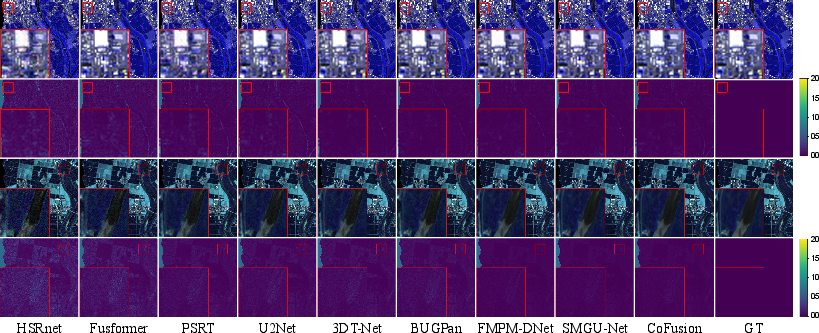
Figure 5: Chikusei dataset pseudo-color result and corresponding SAM error maps for ×4 fusion, comparing CoFusion to SOTA baselines.

Figure 6: CAVE dataset visual comparison with error maps for different fusion models.

Figure 7: PaviaU dataset pseudo-color and SAM error visualization for ×4 fusion.
Across all datasets and scales, CoFusion demonstrates consistently superior PSNR, SSIM, lower SAM, and ERGAS scores. Notably, on Chikusei, CoFusion maintains robustness at ×8 super-resolution, substantially reducing error accumulation in high-frequency and edge regions. In the CAVE dataset (dominated by smooth spectral continuity), CoFusion achieves lowest spectral errors, highlighting the efficacy of SpeCAM for capturing subtle spectral distinctions in low-noise environments.
Spectral Fidelity and Visual Consistency
Spectral fidelity is assessed both globally (SAM) and at selected pixels using spectral response curves.

Figure 8: Spectral response error curves at critical locations, with CoFusion (red) exhibiting minimal divergence from ground truth across bands for Chikusei, CAVE, and PaviaU.
Results underline that CoFusion preserves band-wise consistency and avoids spectral distortion even in regions of pronounced spatial transitions. Competing methods suffer increased error near boundaries, a failure not observed in CoFusion's spatial-spectral coupled optimization.
Model Efficiency
Model compactness and inference speed are key, especially for deployment on resource-limited hardware.
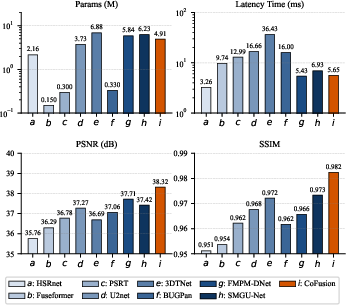
Figure 9: Parameter count and latency (log scale) for ×4 fusion on PaviaU; CoFusion achieves high accuracy at low resource cost.
CoFusion achieves SOTA performance with only 4.91M parameters and 5.65ms per inference, outperforming more complex architectures (e.g., U2Net, 3DTNet) both in efficiency and accuracy by leveraging lightweight spatial encoding and eliminating redundant cross-modal routines.
Ablation Study
Component ablations performed on CoFusion confirm the centrality of each module. Excluding SpaCAM causes the greatest drop in PSNR/SSIM, reflecting its foundational role in spatial detail preservation. Removing SpeCAM sacrifices spectral consistency, while the absence of SSCFM impairs multi-scale interaction and overall network robustness.
Implications and Future Directions
This work enforces that explicit and adaptive spatial-spectral interaction significantly enhances the ability to resolve the extreme ill-posedness of MHIF. The approach is modular and enables further extension:
- Multi-modal Generalization: The cross-scale, dual-branch, and collaborative fusion mechanisms are directly transferable to other paired remote sensing tasks (e.g., fusion with LiDAR, SAR).
- Spectral-Physical Constraints: Future integration with physics-constrained or uncertainty-aware modules may further stabilize performance under real-world sensor/distribution shifts.
- Hardware-Aware Design: The efficient architectural choices demonstrated by CoFusion suggest it can be adapted for real-time or embedded deployment in resource-limited platforms, such as onboard satellite or UAV processing.
Conclusion
CoFusion introduces a principled solution for the spatial-spectral collaborative fusion of multispectral and hyperspectral data, establishing new SOTA performance through explicit, modular, and efficient cross-scale/cross-modal alignment. Empirical results confirm both quantitative gains and practical deployment viability, while component analysis delineates the necessity of each design aspect. This work provides a robust foundation for next-generation MHIF architectures, emphasizing structured, dynamic feature coupling as a key direction for future research in high-dimensional image fusion.
Reference: "CoFusion: Multispectral and Hyperspectral Image Fusion via Spectral Coordinate Attention" (2604.10584)