- The paper presents RDVQ, a novel approach that integrates a differentiable soft assignment for codebook indices to enable end-to-end gradient-based rate–distortion optimization.
- It leverages an autoregressive masked Transformer for entropy modeling, yielding improved perceptual fidelity and coding efficiency across standard benchmarks.
- RDVQ supports flexible test-time bitrate control and maintains high structural fidelity even at ultra-low bitrates, outperforming traditional VQ methods.
Differentiable Vector Quantization for Rate-Distortion Optimization of Generative Image Compression
Introduction and Motivation
This paper addresses the lack of end-to-end rate–distortion (RD) optimization in Vector Quantization (VQ)-based generative image compression. Conventional VQ approaches in learned compression frameworks suffer from non-differentiable index assignments, impeding gradient flow from the rate objective to the encoder. Consequently, the encoder-induced prior over codebook indices remains fixed or uniform, and entropy modeling operates passively, strongly decoupling representation learning from entropy minimization.
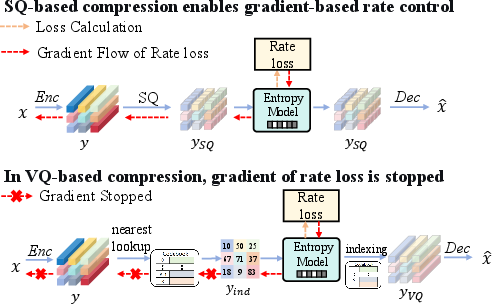
Figure 1: Gradient-based rate control in VQ compression is challenging due to non-differentiable indices.
The proposed solution, RDVQ, introduces a differentiable surrogate for the codebook index distribution. By relaxing the hard assignment to a distance-aware soft assignment, gradients from the rate objective can backpropagate to the encoder, aligning latent representations with entropy constraints and enabling effective joint RD optimization. This paradigm shift allows VQ-based compression models to match or surpass the perceptual efficiency of state-of-the-art alternatives, while supporting flexible test-time bitrate control.
Methodology
Unified Rate–Distortion Optimization with Differentiable VQ
RDVQ achieves end-to-end RD optimization by decoupling the reconstruction/coding path (hard VQ) from the rate-estimation path (differentiable soft assignment). In the forward pass, the encoder output is mapped onto a learned multi-scale codebook via standard nearest-neighbor assignments for reconstruction and entropy coding. The core novelty is the branch in which, for the purpose of rate estimation, the probability over codebook entries is replaced by a temperature-controlled softmax over negative squared distances, replacing the standard argmin discrete operation with a smooth, differentiable approximation.
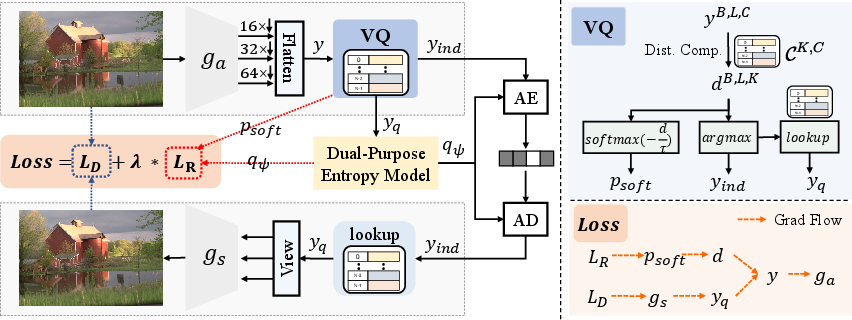
Figure 2: Overview of RDVQ. The analysis transform ga extracts and flattens features, the VQ module computes hard and relaxed representations, and gradients from the rate term flow through the soft branch to the encoder.
The rate loss is then the cross-entropy between the softened codebook distribution and a masked-transformer-based entropy model, which provides a tight and differentiable estimate of coding cost for RD training. At deployment, the model performs conventional hard VQ and entropy coding, so there is no impact on inference efficiency or pipeline structure.
Autoregressive Entropy Modeling in Multi-Scale Structure
The entropy modeling is implemented as an autoregressive masked Transformer operating over a dependency-aware ordering of the codebook indices. This design captures both spatial and hierarchical (multi-scale) dependencies, and the casual masking ensures that each token attends only to its valid predecessors, crucial for accurate conditional entropy estimation.
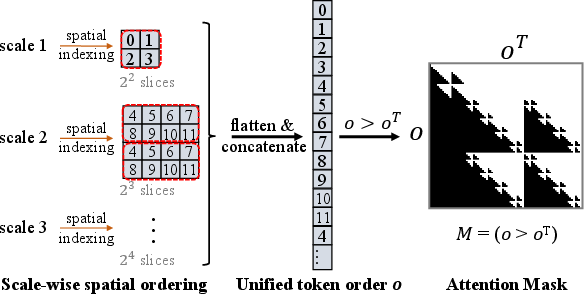
Figure 3: Dependency-aware ordering for autoregressive entropy modeling—spatially and hierarchically sorted index ordering enables structured attention masking.
This unified entropy model is reused for both rate estimation during training and entropy coding at test time, and can operate in generative mode for index completion, which is the basis for variable-bitrate transmission via prefix techniques.
Experimental Results
Across standard benchmarks (Kodak, DIV2K-val, CLIC2020-test), RDVQ demonstrates strong improvements, especially at ultra-low bitrates. Compared to previous VQ-based (e.g., K-means VQ, OSCAR) and hybrid or diffusion/dictionary-based approaches (e.g., DLF, RDEIC), RDVQ achieves higher structural fidelity (as measured by DISTS), better perceptual similarity (LPIPS), and FID, while using a substantially smaller backbone—often less than 20% of the parameter count required by competitors.
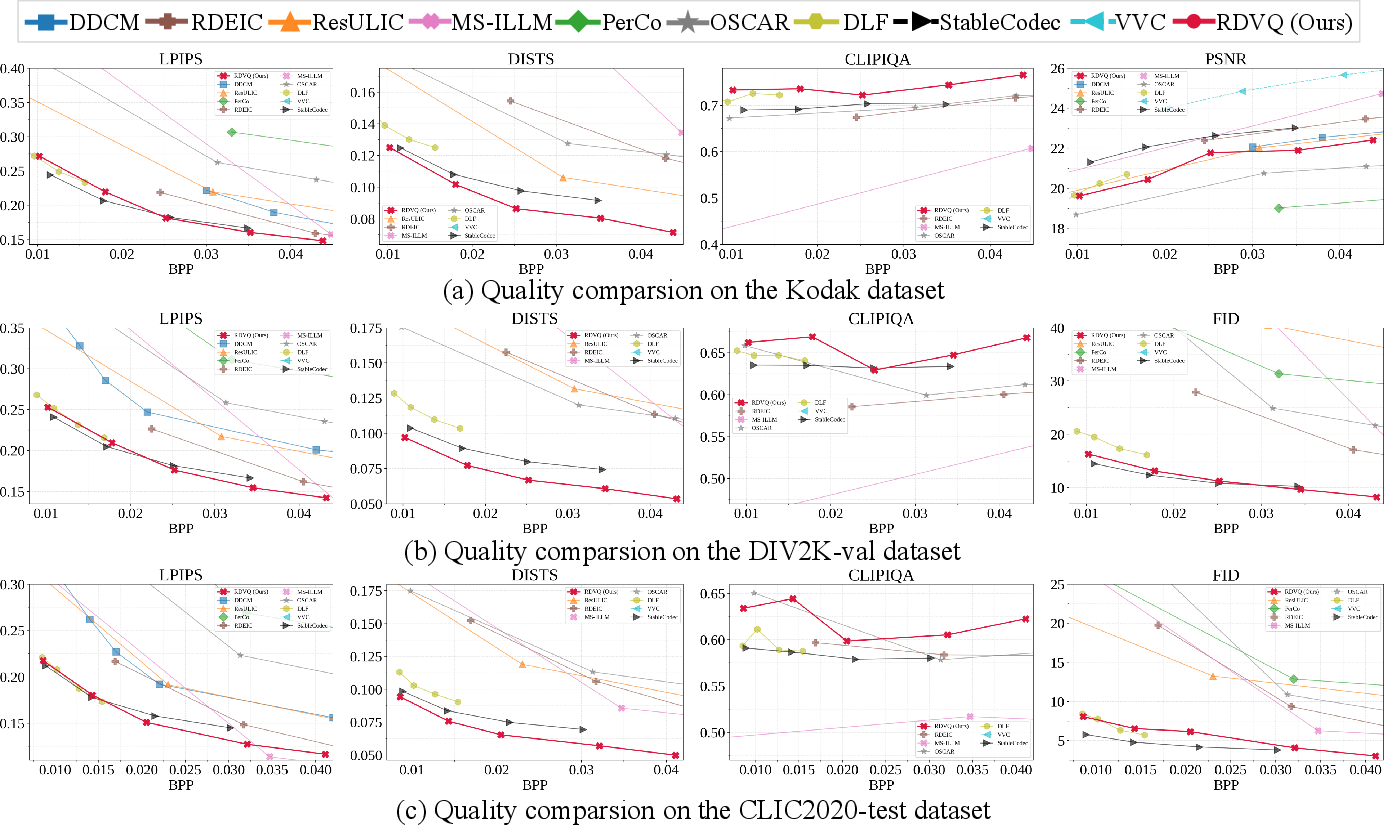
Figure 4: Rate-distortion curves on the Kodak, DIV2K-val, and CLIC2020-test datasets reveal RDVQ's superior perceptual quality and coding efficiency across rate regimes.
Model efficiency analysis further reveals that RDVQ obtains the best BD-DISTS-parameter trade-off, maintaining high performance in lightweight (251.9M-parameter) settings.
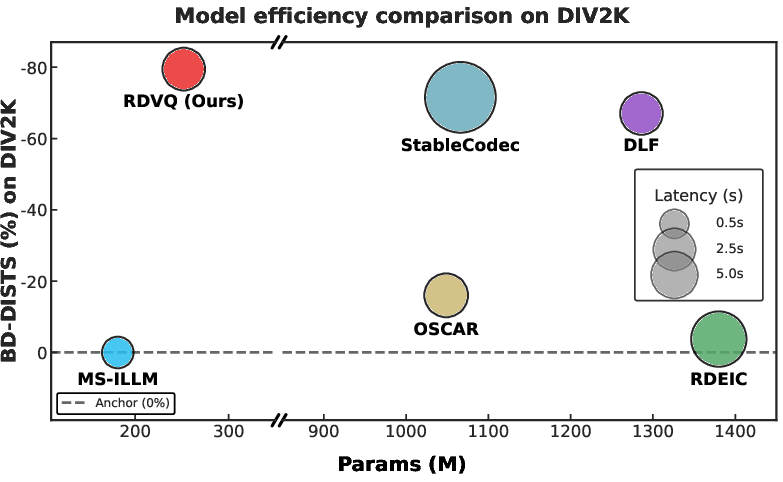
Figure 5: Model efficiency comparison on DIV2K—RDVQ achieves lower BD-DISTS with fewer parameters than competitors.
Ablation studies indicate that omitting the differentiable relaxation (i.e., eliminating direct rate-to-encoder gradients) leads to severe performance degradation, and that codebook-size-based rate control (as in K-means VQ) achieves the same bitrate but considerably worse perceptual metrics.
Qualitative and Perceptual Analysis
Visualization of reconstructions on challenging datasets shows that at bitrates as low as 0.01–0.04 bpp, RDVQ preserves both global structure and fine textures, with fewer artifacts than both diffusion-based codecs and hand-crafted baselines.

Figure 6: Visual examples on the CLIC2020 test set demonstrate RDVQ's consistency in preserving content under aggressive rate constraints.

Figure 7: Visual examples on the Kodak dataset showing structural fidelity at extremely low bitrates.
At the feature level, PCA of encoder outputs highlights a continuous suppression of high-frequency content as the bitrate decreases, illustrating adaptive encoder behavior under end-to-end rate pressure.

Figure 8: PCA visualization—encoder features become smoother at lower bitrates, emphasizing low-frequency, predictable structure.
As the rate constraint increases, codebook utilization becomes increasingly sparse and focused, indicating improved redundancy elimination compared to heuristically-constrained VQ approaches.
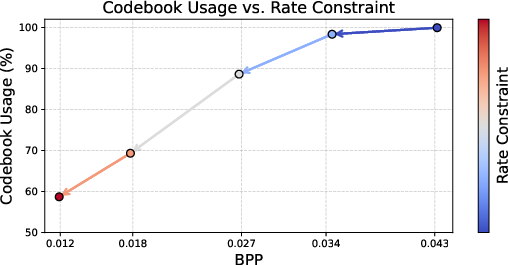
Figure 9: Codebook usage concentrates under stronger rate constraints—an indicator of more efficient and entropy-aligned latent representations.
Test-Time Bitrate Control
RDVQ supports on-the-fly bitrate control by means of prefix transmission with autoregressive completion of the remaining indices via the entropy model. Controlled experiments show that, within a usable bitrate range, the quality degrades gracefully as the prefix shortens, and the perceptual quality remains competitive. Competing approaches—such as AE-Entropy (no joint RD learning) and zero-padding—exhibit significantly larger quality drops and artifacts under the same protocol.
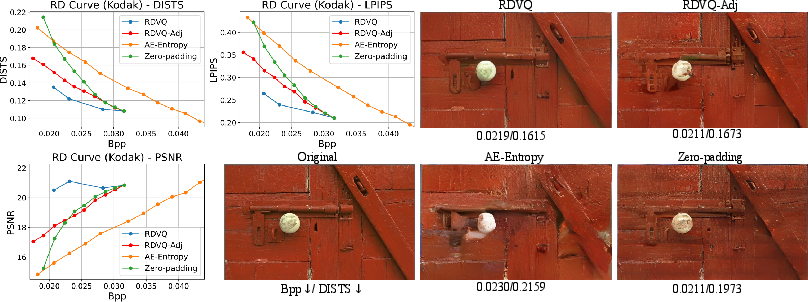
Figure 10: Test-time rate adjustment via prefix transmission—rate–distortion curves and visual comparisons show the effectiveness of RDVQ's autoregressive completion relative to baselines.
Implications, Theoretical Insights, and Future Directions
RDVQ presents a principled mechanism for integrating entropy minimization with high-level discrete representation learning in generative image compression. By restoring the gradient connection from the rate to the encoder, the approach enables learned priors that are structurally and semantically faithful, yet highly compressible. This entropy-constrained VQ formulation has implications beyond the compression domain: it suggests a potential unification of discriminative and generative modeling via discrete latent spaces amenable to entropy shaping.
Practically, RDVQ demonstrates that state-of-the-art perceptual quality is achievable—even at extreme compression factors—with lightweight architectures and without dependence on large pretrained backbones. The compatibility with autoregressive and prefix-based rate control points to versatility for interactive and streaming applications.
Theoretically, the differentiable surrogate for hard quantization could be extended to other discrete generative modeling tasks, or combined with diffusion or masked autoregressive decoding frameworks. Further, entropy-aware VQ tokenization may provide improved structural regularization for downstream visual-language or cross-modal generative tasks.
Conclusion
RDVQ establishes differentiable soft relaxation of codebook indices as a foundation for rate–distortion optimization in VQ-based image compression. The approach delivers strong perceptual fidelity and coding efficiency, robust test-time bitrate adjustment, and lightweight deployment. Theoretical analysis and experimental validation confirm that explicit entropy modeling is essential for bridging the gap between discrete representation learning and practical, controllable generative compression. This framework is expected to catalyze advances in both fundamental representation learning and adaptive communications systems.
For further details, see "Differentiable Vector Quantization for Rate-Distortion Optimization of Generative Image Compression" (2604.10546).

