- The paper demonstrates that finetuned ML models (BERT, SVC, BiLSTM) achieve perfect binary accuracy, markedly outperforming traditional YARA detection methods.
- The paper leverages a rigorous Design Science Methodology to develop and deploy a middleware that intercepts MCP tool executions in real time.
- The paper refines multiclass taxonomies using cosine similarity and back-translation techniques to enhance semantic discrimination and operational performance.
Machine Learning-Based Detection of MCP Attacks
Introduction
The proliferation of Model Context Protocol (MCP) technology, designed to extend pretrained LLM functionality via plug-in tools, has introduced a new attack vector: malicious tool injection. While analogous to threats encountered in email phishing and malware domains, defensive countermeasures for MCP tool-based attacks remain insufficiently explored. "Machine Learning-Based Detection of MCP Attacks" (2604.10534) systematically investigates this defensive gap by evaluating supervised ML and rule-based methodologies for automated detection of malicious MCP tool descriptions. The study compares traditional keyword-based YARA rules against BERT, BiLSTM, and SVC classifiers using robust experimental protocols, and demonstrates marked superiority of the ML-based approaches.
Project Structure and Workflow
The research leverages the Design Science Methodology (DSM) to ensure a rigorous, iterative process bridging academic and industrial imperatives. The initial phase comprises problem domain analysis, systematically identifying security defects specific to MCP tool adoption. Subsequent phases focus on artifact construction—encompassing data collection, model design, and middleware integration—culminating in artifact evaluation and deployment within a simulated live MCP ecosystem.
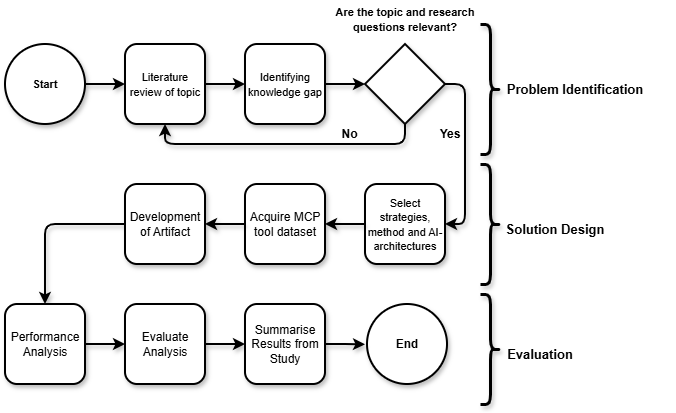
Figure 1: An overview of the DSM-based project structure guiding artifact development and evaluation.
A dedicated middleware, architected to interpose itself pre-MCP tool execution, operationalizes the ML-based detector as a gating mechanism for tool invocations. This enforces real-time threat detection without altering downstream LLM-agent workflows.
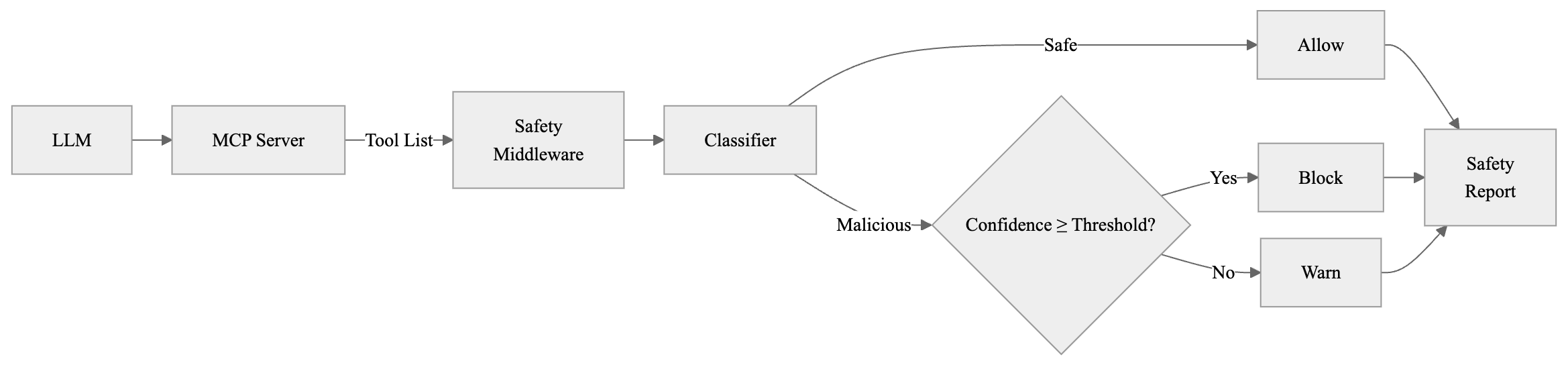
Figure 2: Flowchart illustrating middleware interception of MCP-tool calls with ML-based real-time classification.
Dataset Construction, Class Taxonomy, and Preprocessing
To enable robust supervised learning, a composite dataset is curated from two orthogonal sources: known malicious descriptions (sourced from MCPTox benchmark datasets), and benign tool documentation gathered via automated scraping and manual vetting of trusted MCP repositories.
The malicious class taxonomy, initially reflecting 11 attack types, is reduced to seven classes using cosine similarity-based agglomeration, mitigating semantic redundancy and class confusion.
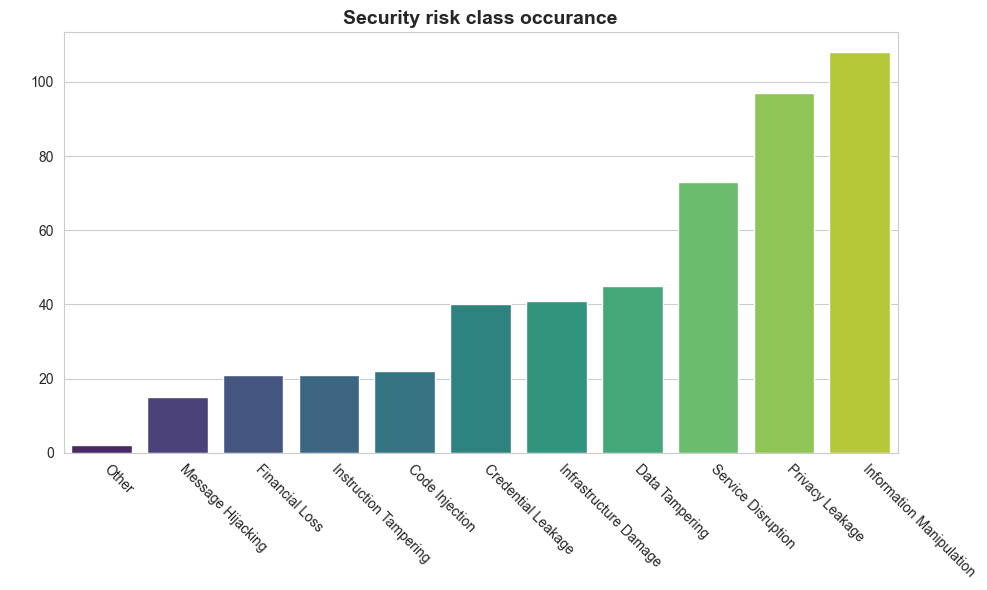
Figure 3: The class distribution visualizing skew towards certain MCP-tox attack types among malicious samples.
Inter-class similarity analysis using cosine metrics validates the high context overlap across several attack types, supporting the decision to form a coarser-grained class grouping.
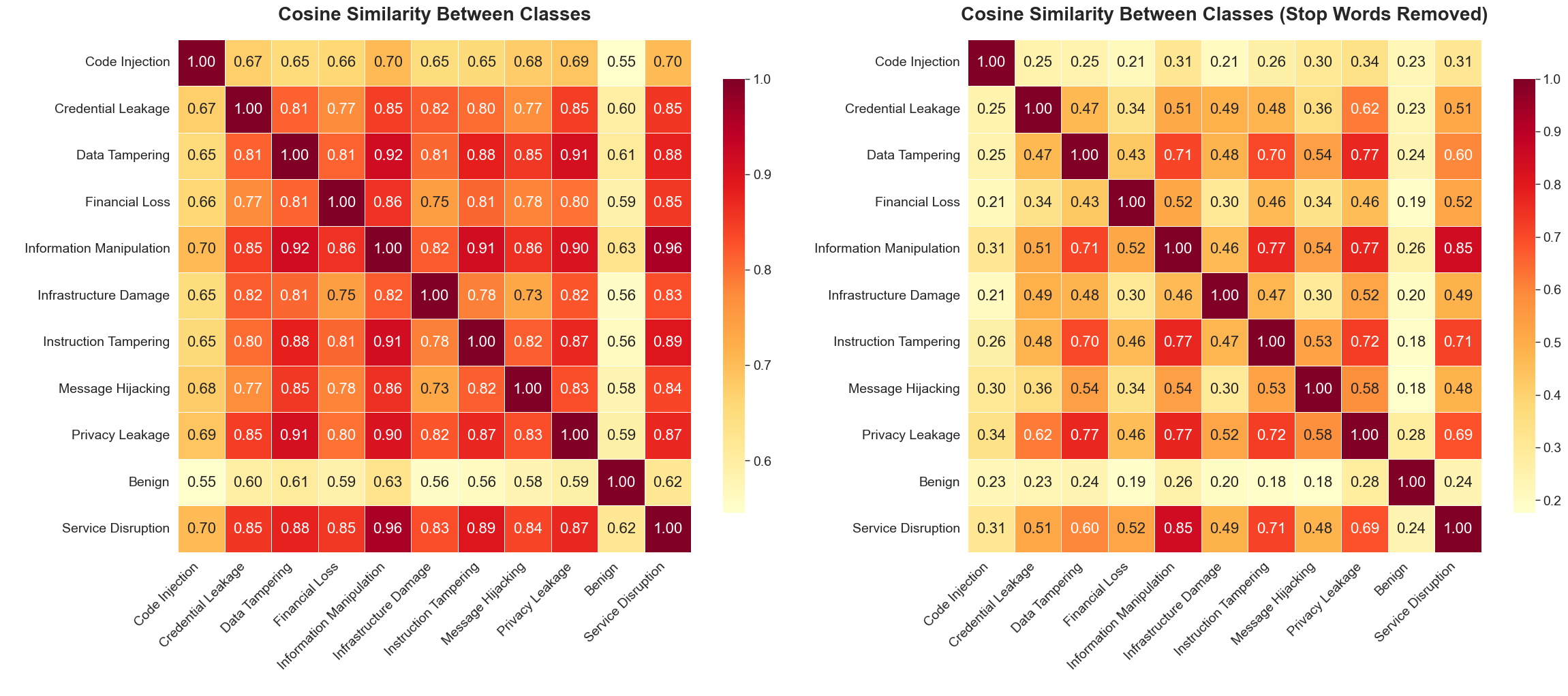
Figure 4: Cosine similarity distances across original malicious classes, highlighting areas of high confusion.
The refined multiclass task exhibits lower cross-class similarity, post-concatenation, as confirmed by the similarity matrix.
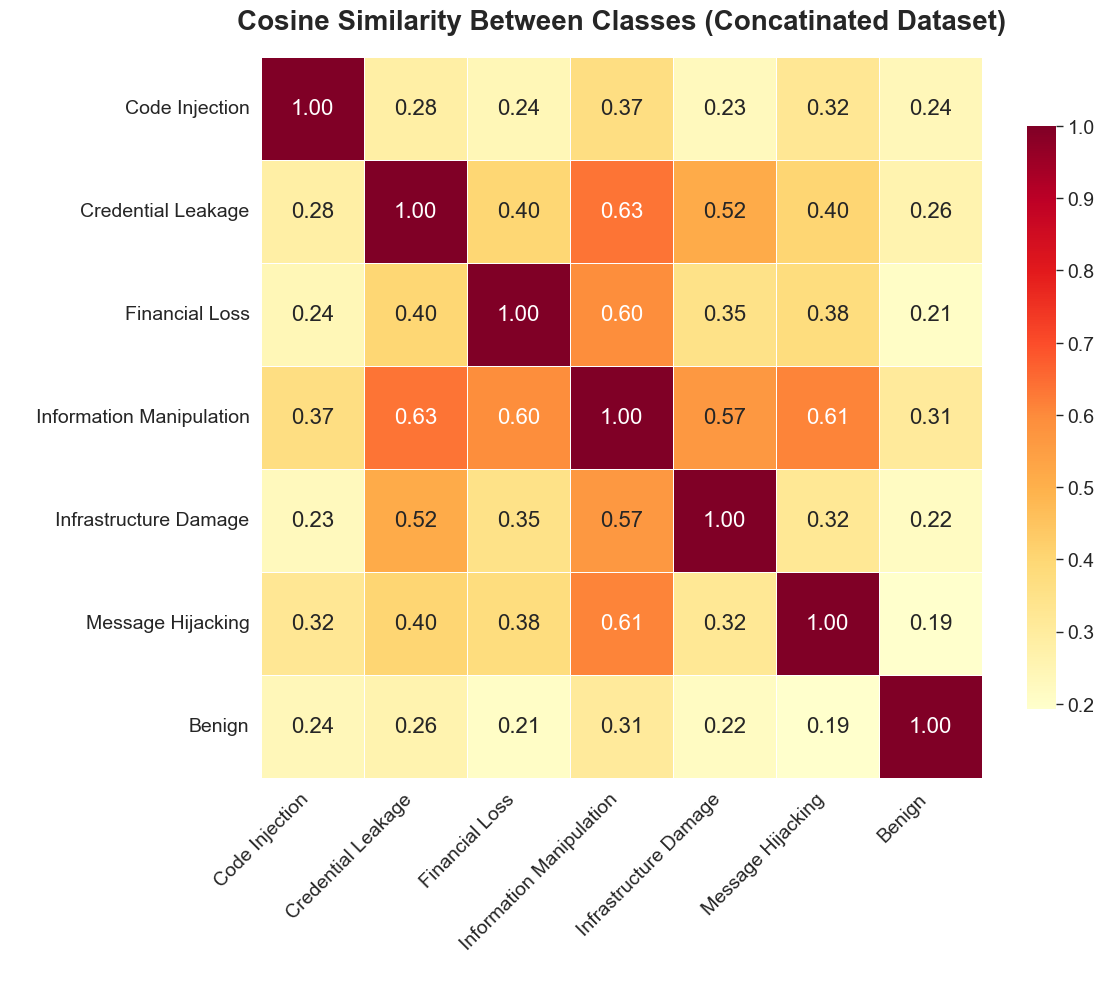
Figure 5: Cosine similarity matrix after merging highly similar classes, indicating improved class separability.
Data augmentation is accomplished via back-translation using linguistically distant languages (Arabic, Chinese, Japanese, Korean), aiding generalization and paraphrase robustness. Minimal text preprocessing is applied to preserve domain-specific linguistic cues essential for contextual ML discrimination.
Baseline: Rule-Based Detection (YARA)
YARA rule-based detection operates on a binary classifier paradigm, benchmarking the pragmatic efficiency of static keyword and pattern matching for MCP docstring descriptions.
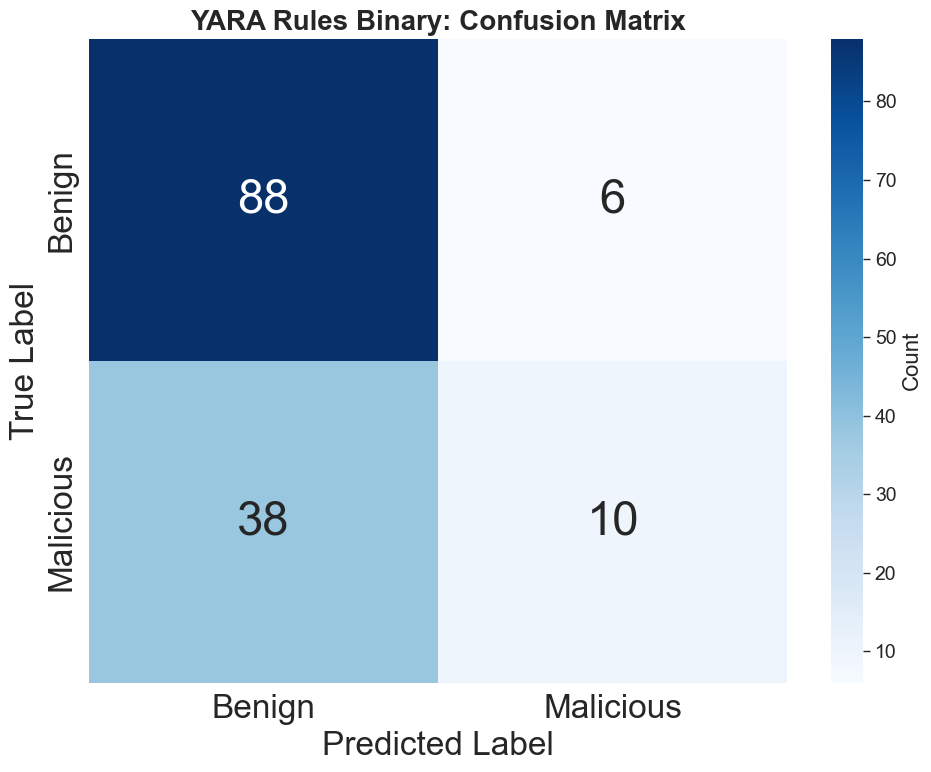
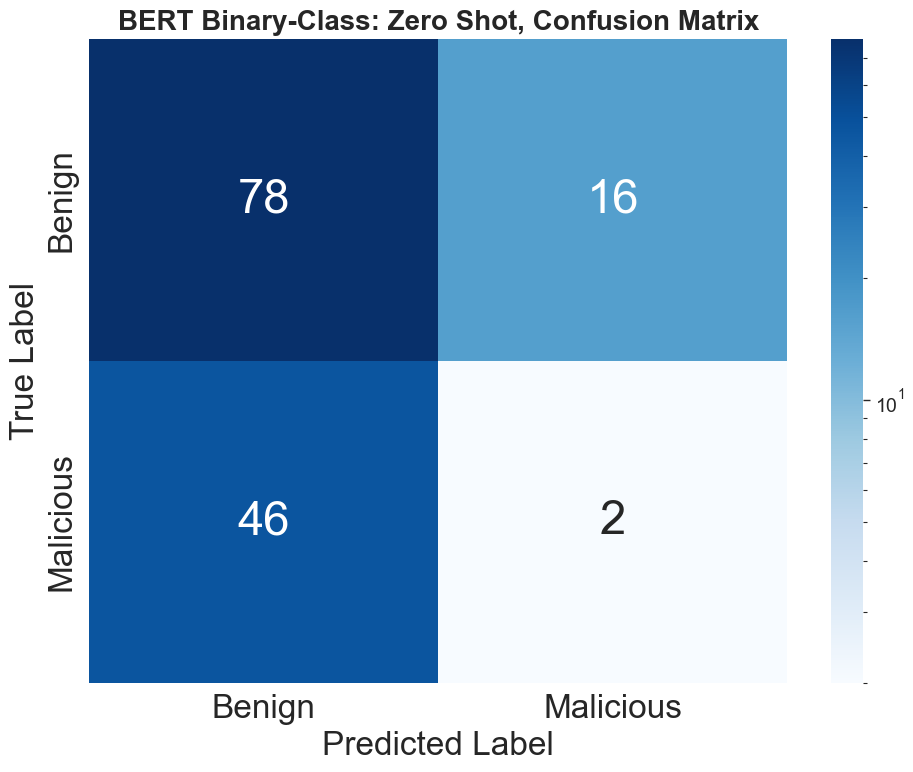
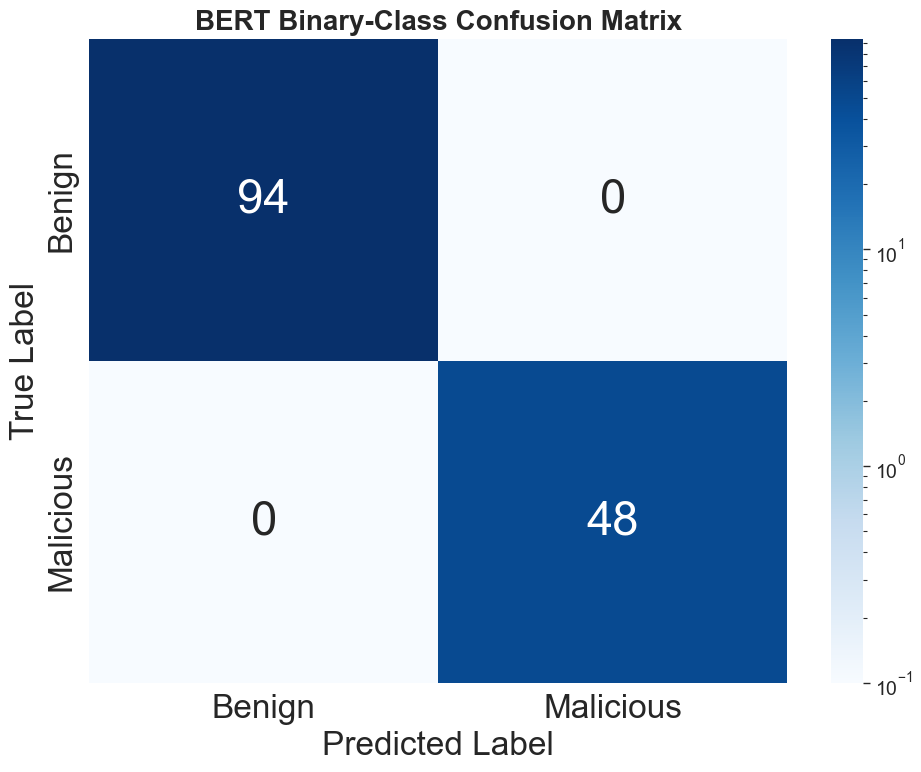
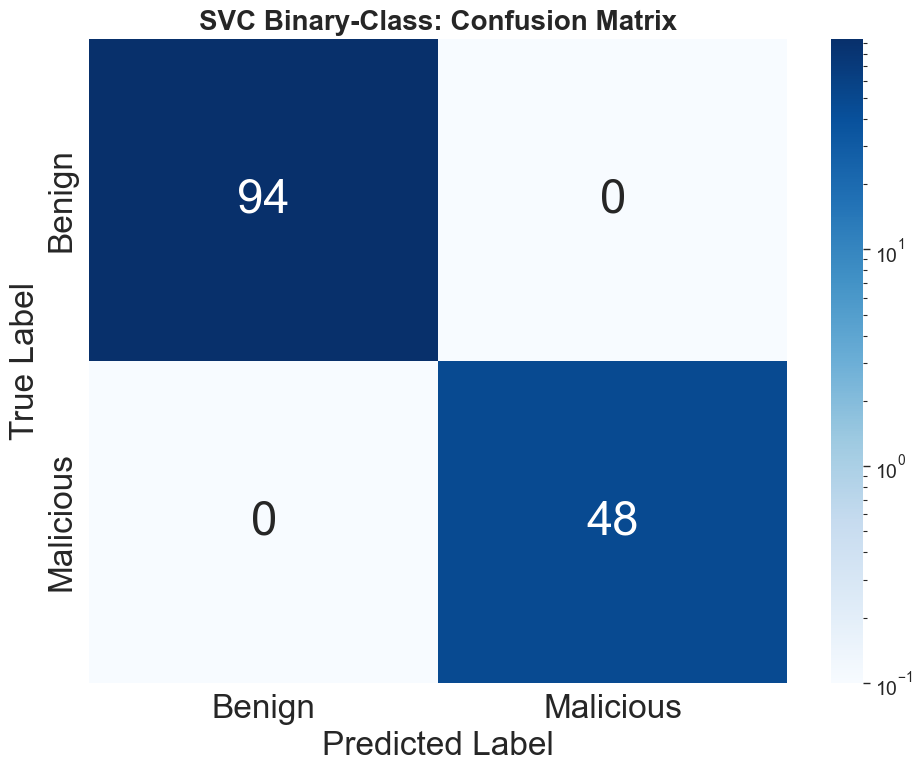
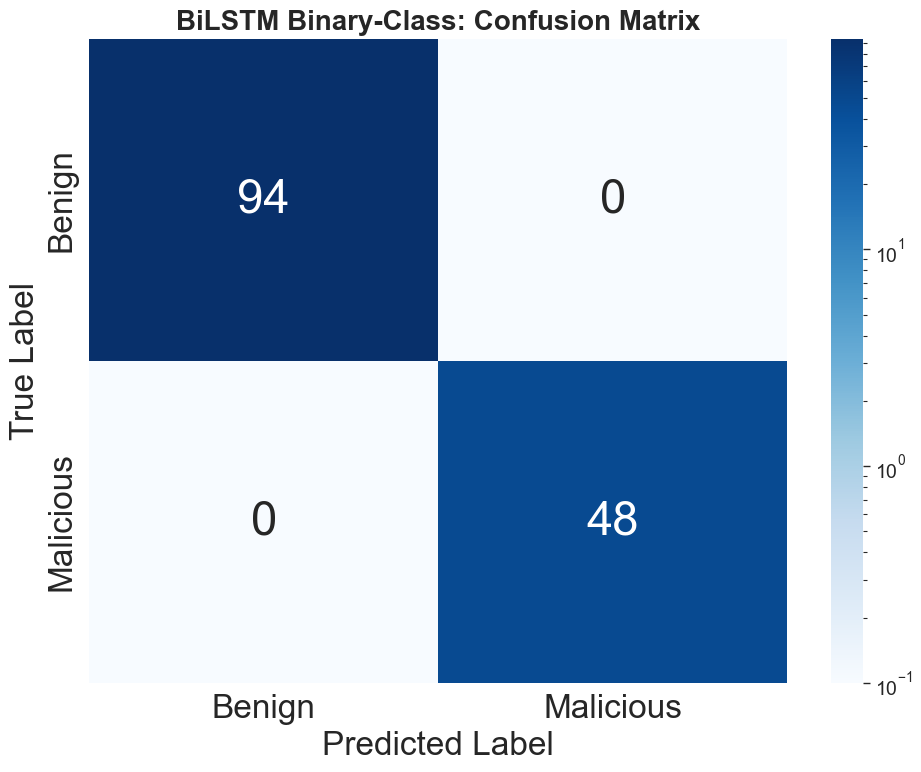
Figure 6: YARA rule-based pipeline performance on the MCP attack dataset.
While historically effective for static, signature-based malware, results indicate substantial precision–recall trade-offs and a tendency towards bias in imbalanced datasets. Manual upkeep and poor generalization to novel tool obfuscations further limit their application.
Supervised Machine Learning Architectures
BERT
A finetuned BERT (bert-base-uncased) serves as the flagship architecture. Endowed with contextual self-attention, BERT is augmented by a lightweight classification head and finetuned on the MCP dataset using few-shot paradigms. Both untuned (pretrained only) and finetuned variants are compared for ablation control.
SVC
TF-IDF-based vectorization precedes linear-kernel SVC deployment. SVC's capacity to find optimal hyperplanes in sparse, high-dimensional feature spaces is well suited for natural language anomaly detection inherent in tool injection attacks.
BiLSTM
A BiLSTM, leveraging bidirectional context propagation, is trained using embedding features for comparative benchmarking, given its established utility in phishing and spam detection tasks.
Evaluation Protocols and Metrics
All models are assessed under two configurations:
- Binary: Malicious vs. benign.
- Multiclass: Recognition of up to 11 (or reduced 7) attack classes plus benign.
The evaluation leverages stratified train–test splits and standard classification metrics (accuracy, precision, recall, F1-score), supplemented by confusion matrix visualizations to highlight error modalities in the context of class imbalance.
Results
Binary Classification
The untuned BERT and YARA are robust only in classifying majority benign samples, achieving F1-scores of 6.06% and 31.25% respectively. In stark contrast, all fine-tuned ML models (BERT, SVC, BiLSTM) attain perfect separation: 100% accuracy, F1, precision, and recall, with zero false positives/negatives, demonstrating complete discrimination of malicious from benign tool descriptions.
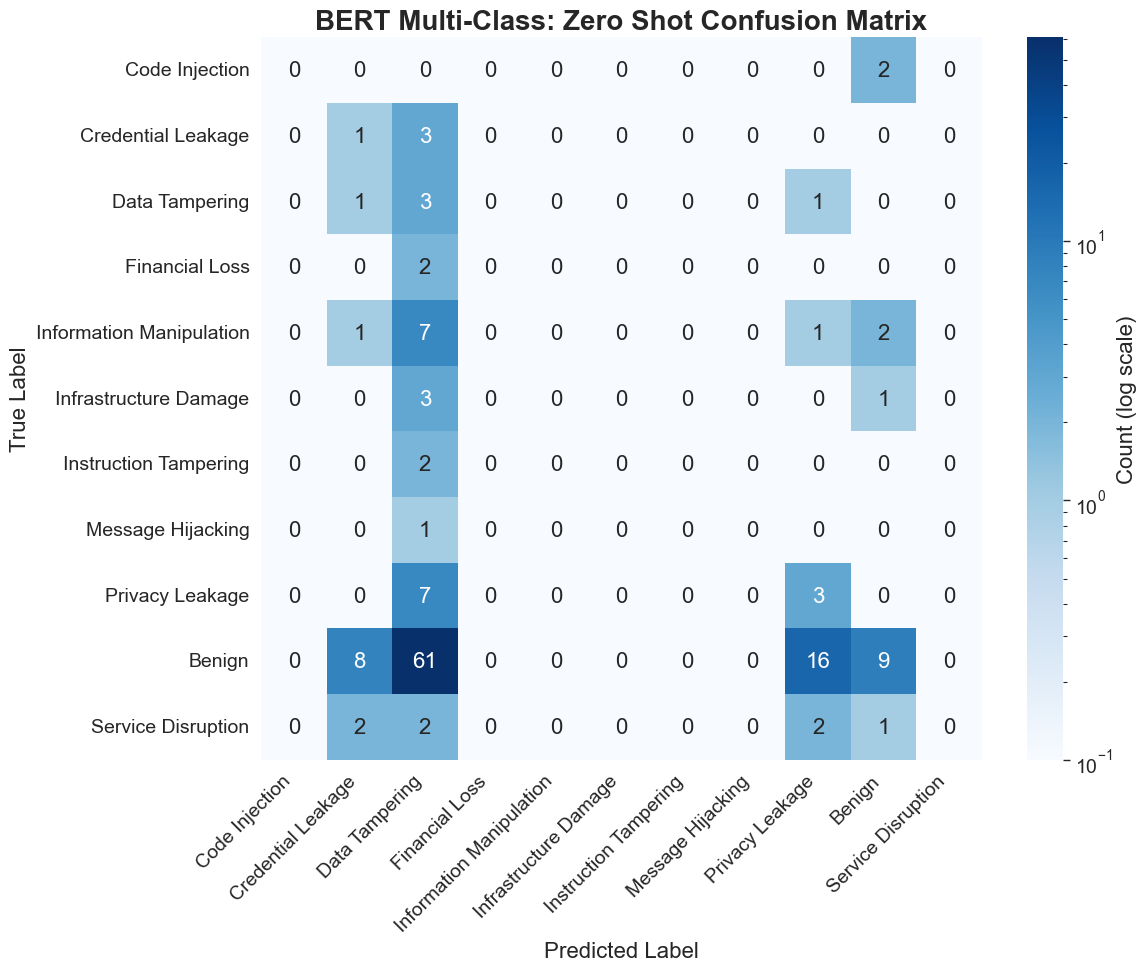
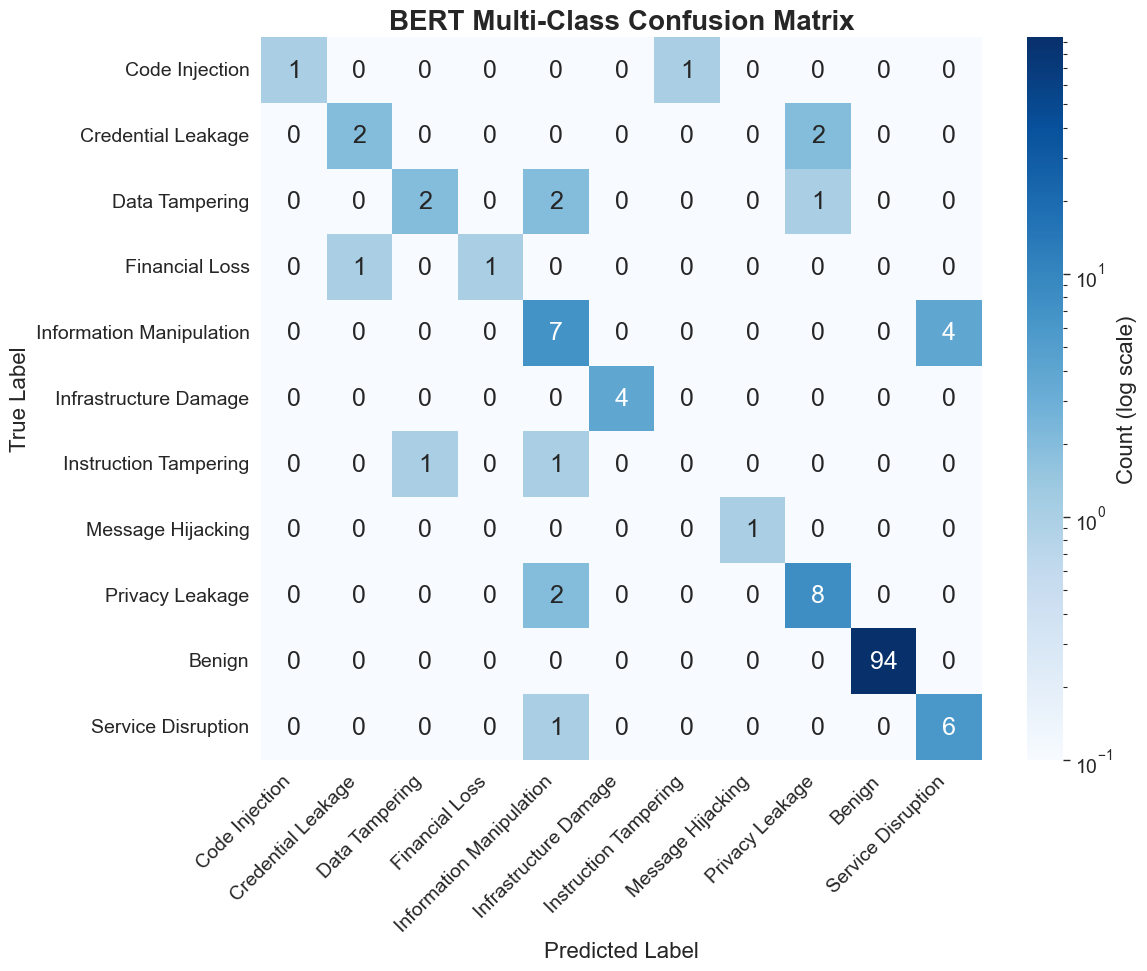
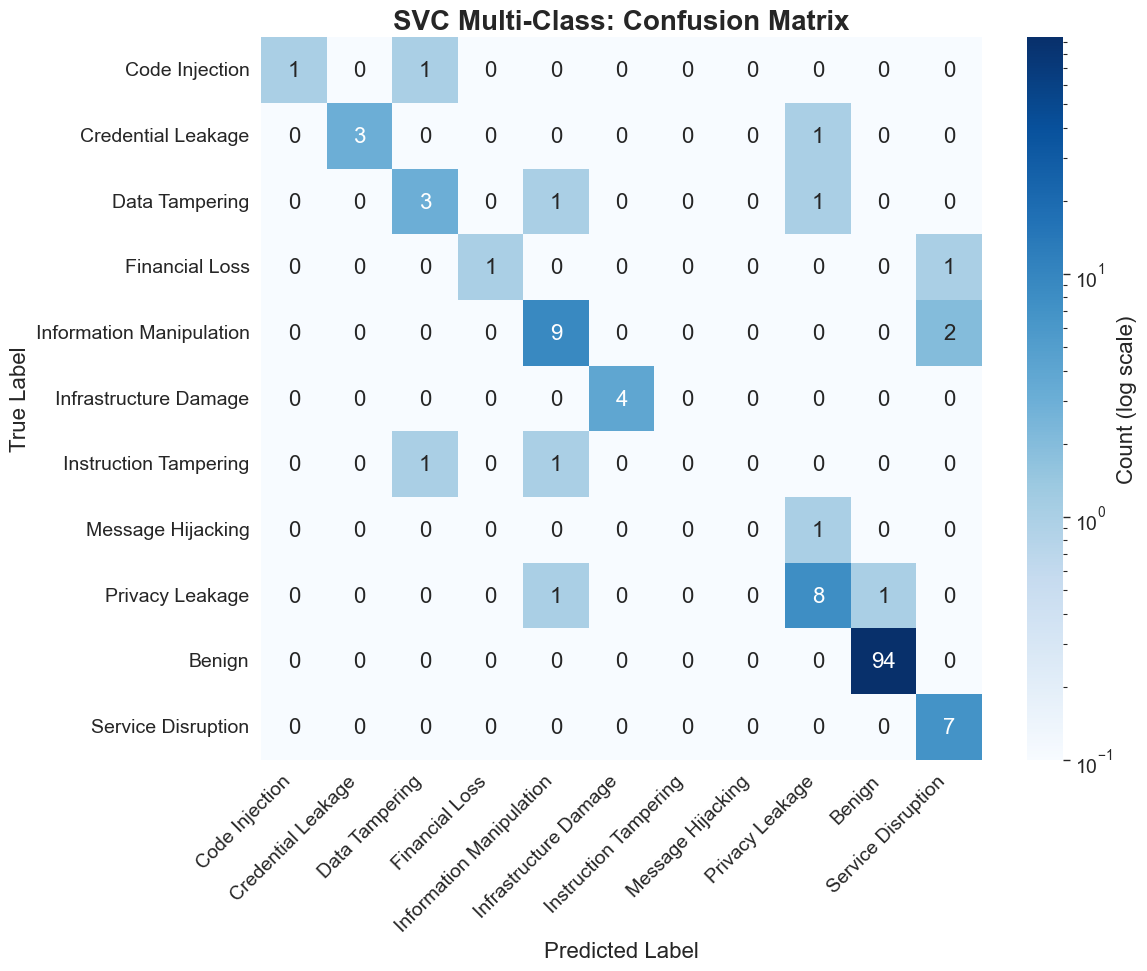
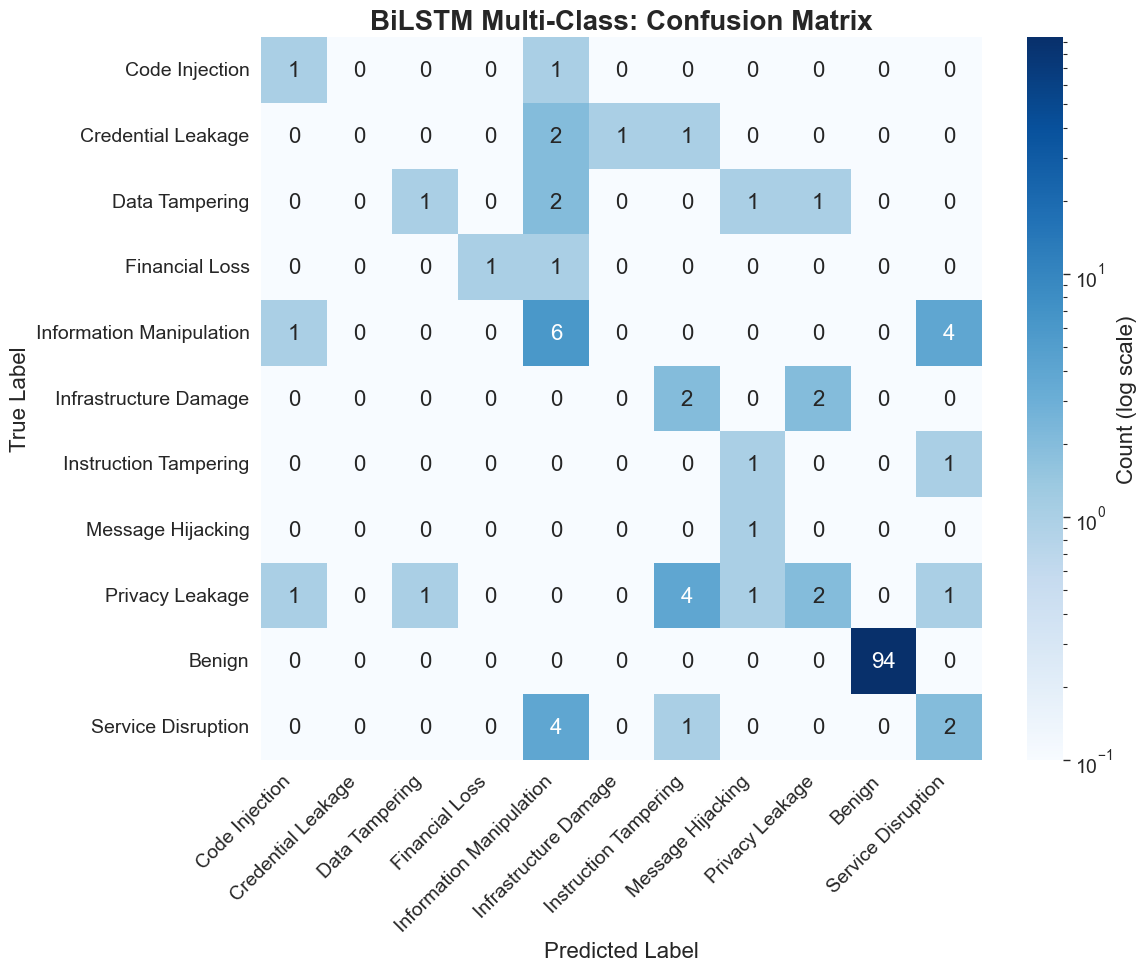
Figure 7: Zero-shot BERT confusion matrix illustrating mode collapse to dominant classes.
Multiclass Classification
For the full 11-class taxonomy, SVC achieves the highest F1 at 90.56%, followed by BERT at 88.33%. The BiLSTM achieves 75.62%. On the reduced 7-class task, BERT's F1 increases to 97.66% and SVC to 95.25%. Notably, only SVC misclassifies a single "privacy leakage" instance as benign, while BERT maintains perfect binary partitioning within the multiclass frame. Untuned BERT's multiclass F1 lags substantially at 12–14%, underscoring the necessity of task-specific finetuning.
Token importance analysis via integrated gradients corroborates that the BERT model does not primarily rely on explicit "malicious" keywords but instead encodes prescriptive/instructional discourse structures as risk signals (e.g., "must", "should", "will").
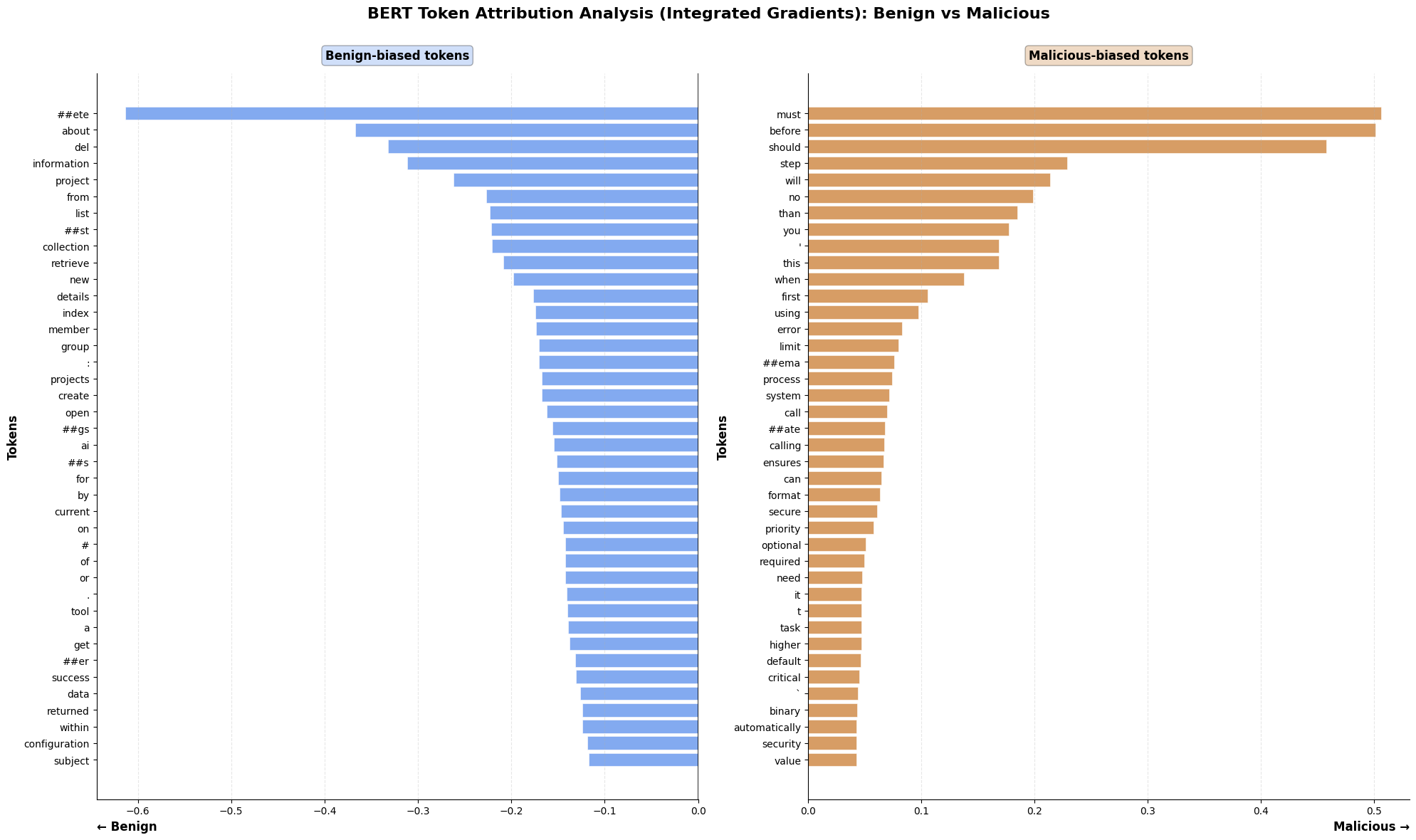
Figure 8: Visualization of top token contributions to BERT model predictions on benign vs. malicious MCP tool descriptions.
Discussion
This manuscript demonstrates that context-aware, modern NLP classifiers—particularly BERT and SVC—are highly effective for MCP attack detection, substantially outperforming both untuned transformer baselines and legacy rule-based (YARA) detectors. Exceptionally high binary accuracy indicates that malicious tool descriptions are semantically distinct from benign ones, and ML models can reliably operationalize this for real-time threat mitigation.
In multiclass scenarios, while fine-grained attack categorization is more challenging, the models maintain strong overall discriminative power. The results show that judicious class refinement (via agglomeration based on cosine similarity metrics) eliminates confusion and further boosts accuracy. The analysis exposes major shortcomings in current industrial rule-based deployments, such as inflexibility, high maintenance cost, and poor recall in the face of paraphrased or contextually obfuscated attacks.
Token-level analysis for BERT models elucidates the depth of semantic generalization achievable with current transformers—a critical advantage when classifying adversarial or subtly crafted tool docstrings that evade keyword-based detection.
Implications and Future Outlook
Practically, this study delivers an ML-driven middleware deployable atop existing MCP frameworks for dynamic pre-execution screening of tool invocations. The results suggest that industry should immediately transition from legacy YARA-based mechanisms to transformer-classifier or SVC-based deployments for improved security guarantees.
Theoretically, the success of context-driven, model-based detectors in MCP attack domains portends expanding application to adjacent LLM-integrated agentic protocol domains, including newly introduced frameworks like Claude Skills. Designing robust, generalizable detectors for increasingly heterogeneous, multi-lingual agent tool ecosystems will require adaptation of current methodology and transfer learning across evolving threat landscapes.
Further research is required on transferability to non-English tool descriptions, large-scale adversarial robustness, and adaptive continual learning as attackers develop mechanisms to mimic benign tool contexts more closely.
Conclusion
The study establishes the primacy of finetuned machine learning architectures, particularly BERT and SVC, for MCP attack detection, both in binary and multiclass scenarios. These models decisively outperform rule-based approaches (YARA), obviating the need for hybrid neuro-symbolic strategies under current threat taxonomies. Deployment of such systems within middleware enforcement layers provides a practical line of defense for organizations embracing LLM-based automation with MCP extensions. Future work will expand on multilingualism, cross-domain generalization, and adversarial robustness to ensure sustainable, adaptive MCP ecosystem security.