- The paper presents a component-centric methodology that identifies 16 unique multi-component attack techniques in MCP servers.
- It validates attack efficacy through rigorous experiments across industrial platforms, noting 100% success rate for direct code injection.
- It introduces Connor, a two-stage behavioral deviation detection framework achieving a 94.6% F1 score and minimal false alerts.
Understanding and Detecting Malicious MCP Servers: A Component-Centric Attack and Defense Paradigm
Introduction and Motivation
The proliferation of the Model Context Protocol (MCP) for external tool integration in LLM-powered systems introduces new, complex security risks that extend beyond classical supply chain attacks. The paper "From Component Manipulation to System Compromise: Understanding and Detecting Malicious MCP Servers" (2604.01905) exposes fundamental limitations in prevailing MCP security taxonomies and unveils novel multi-component attack primitives. To address both analytic and practical defense gaps, the authors develop a comprehensive component-centric attack methodology and instantiate Connor, a two-stage behavioral deviation detection framework for MCP servers.
Component-Centric Attack Surface Characterization
Prevailing approaches abstract attacks by observable effects rather than the mechanism of maliciousness propagation through MCP server architecture. This work pivots to a component-centric model, mapping explicit attack surfaces—tool descriptions, argument schemas, server configuration, tool/resource code, and post-execution responses.
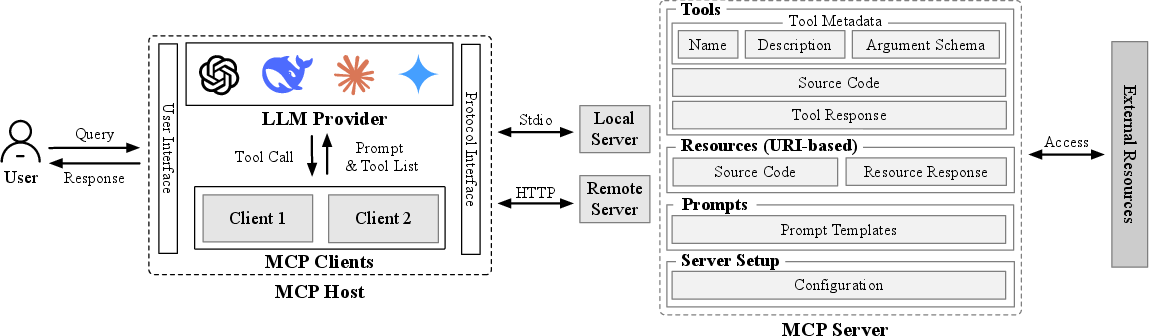
Figure 1: The MCP architecture, delineating attackable surfaces for malicious manipulation across servers, clients, and hosts.
The authors conduct a high-fidelity enumeration of feasible intra-server attack chains using a canonical signature encoding (mediation, stage, sink, and carrier type). This yields 26 distinct influence paths, systematically de-duplicated to 16 semantically unique mechanisms, and augmented to 19 for coverage validation. For each path, instantiations target established adversarial goals including data exfiltration, reverse shell, integrity violation, payload deployment, sabotage, and backdoor implantation. Their PoC dataset comprehensively saturates the attack technique space present in the literature, covering direct code injection, puppet attacks, control-flow hijacking, resource poisoning, shadowing, multi-tool coordination, and sandbox escape.
Empirical Analysis of Attack Efficacy
The practical exploitability of these attack mechanisms is validated across two industrial MCP host platforms and five state-of-the-art LLMs. The results highlight several fundamental findings:
This rigorous experimental protocol demonstrates the infeasibility of chain extension for practical attacks, empirically grounding the two-stage upper bound chosen for attack PoC design.
The Connor Defense Architecture: Behavioral Deviation Detection
To sidestep the signature overfitting and component-isolation limitations of existing MCP defenses, the authors introduce Connor—a detection pipeline leveraging step-wise behavioral deviation from function intent.
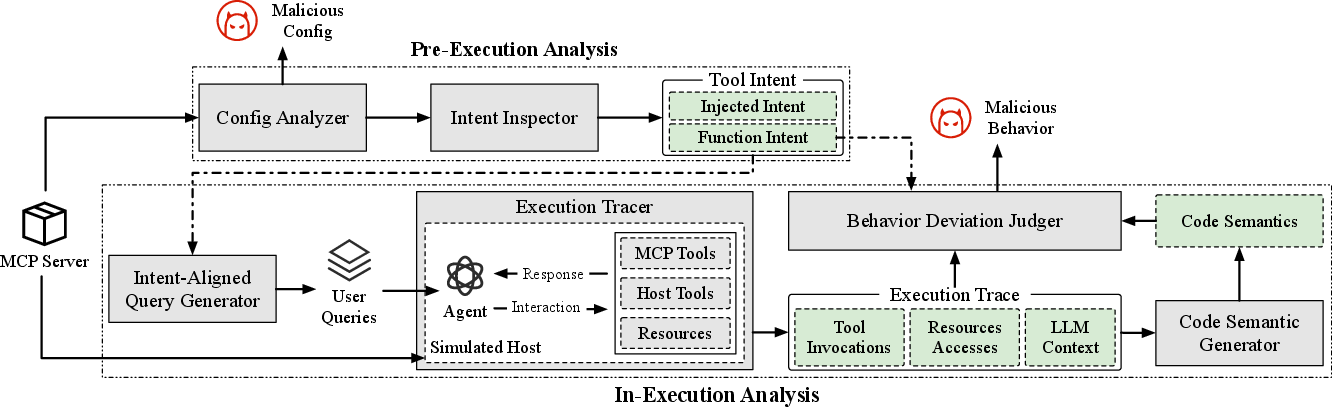
Figure 3: Schematic overview of the Connor framework: static intent/model analysis precedes live behavioral tracing with dynamic deviation detection.
Connor operates in two phases:
- Pre-execution analysis: Shell command (config) analysis fuses structural parsing with LLM-based semantic interpretation for robust detection of complex, obfuscated malicious commands. Descriptions and schemas are parsed by a tuned LLM to split legitimate functional intent from injected adversarial intent.
- In-execution analysis: Under a simulated host environment mapping MCP builtins (mirroring real deployment), Connor drives agent execution via intent-aligned queries. All invoked MCP components (code and context) are instrumented, code semantics are extracted using Joern-based inter-procedural slicing and LLM summarization. Behavioral deviation is then judged on a trajectory (multi-step) basis against the extracted functional intent baseline, using hierarchical verdicts (allow/warn/block).
Crucially, this approach enables early and fine-grained detection of multi-stage and compositional attacks that single-step or purely static approaches systematically miss.
Evaluation and Comparative Results
- Detection effectiveness: On a curated 134-malware dataset, Connor achieves an F1 of 94.6%, a margin of +8.9–59.6% over open-source and industry baselines (MCP-Scan, AI-Infra-Guard, MCPScan). Its precision is 98.4%, with recall 91.1%; importantly, FNs are predominantly unreachable behaviors missed due to runtime non-exercise or attacks entirely out-of-scope (hardcoded test logic, integrity-only violations).
- Ablation: Disabling code semantic summarization catastrophically degrades recall and precision. Intent extraction and config analysis are significant but not pivotal. Replacing program slicing with full code summaries balloons LLM cost by 187.4% while achieving no accuracy gain, validating slicing necessity for practical deployment.
- Real-world applicability: When deployed across 1,672 marketplace MCP servers, Connor yields the lowest alert rate (0.54%) and uniquely discovers two confirmed, previously unknown malware servers, reducing analyst burden by up to 98.4% compared to baselines.
- Pipeline generality: Behavioral deviation detection based on functional intent—rather than chain signatures or path enumeration—demonstrates strong generalization: 91.7% detection on external PoCs with diverse attack goals and methodologies.
Practical and Theoretical Implications
Connor’s methodology enforces a shift from component-isolation and pattern-based alerting, towards holistic, function-intent-driven analysis. This enhances detection capacity against emergent, novel, cross-component adversarial strategies and minimizes the risk of zero-day escape via attack surface recombination.
For ecosystem developers, these results underline the critical need for robust MCP server vetting prior to deployment, regardless of host/LLM, and raise urgent requirements for standardized source code auditing pipelines. The data suggests LLM-side instruction filtering is insufficient in the face of compositional attacks manipulating MCP protocol surfaces.
Theoretically, this work introduces a framework for systematic attack enumeration and exhaustiveness in compositional tool ecosystems—immediately applicable to other modular AI-agent integration protocols.
Limitations and Future Work
The presented defense assumes availability of MCP server code and does not incorporate inter-server compositional attacks. Detection is limited to behaviors exercised at runtime; latent code paths may evade analysis absent adversarial triggering. Query generation aligns to intent—multi-tool attacks implicit in user-driven, non-canonical sequences may be missed in simulation but are detectable via proxying in real host deployments.
Future research should extend to support inter-server/cross-domain attack composition, integration with static advanced payload tracing, and zero-configuration analysis of parameterized, environment-dependent servers. Additionally, investigation into LLM-based code summarization reliability and defenses against adversarial summarization evasion warrants exploration.
Conclusion
This study establishes a systematic, component-centric methodology for analyzing risk in Model Context Protocol-powered LLM ecosystems and empirically demonstrates the superiority of behavioral deviation-based detection over prevailing MCP security tools. The Connor framework’s efficacy in uncovering both synthetic and real-world malware underscores its utility for practical defense at scale, while its analytic results provide a new foundation for supply chain and cross-component attack modeling in AI agent infrastructure.
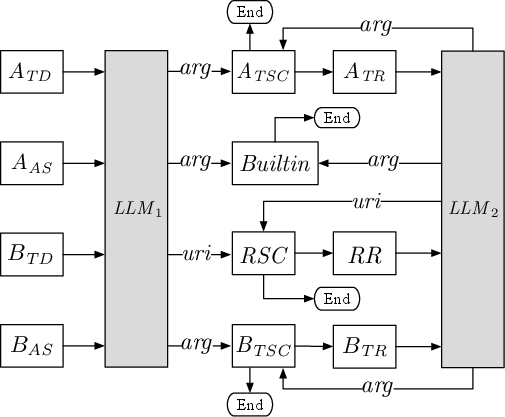
Figure 4: Dynamic interplay of LLM reasoning, MCP server manipulation, and host-provided builtin tool exploitation facilitating indirect system compromise.