- The paper demonstrates that iterative self-repair consistently improves code generation accuracy across diverse LLM architectures, with gains up to +30.0 percentage points.
- It quantifies error repair rates by category, revealing that assertion errors are less fixable (~45%) than name errors (~77%), thereby outlining key model limitations.
- The study shows that most improvements occur in the first two repair rounds, emphasizing efficiency gains and the added benefits of chain-of-thought prompts in larger models.
Iterative Self-Repair in LLM Code Generation: Scaling, Error Analysis, and Prompting
Introduction and Motivation
This paper presents an exhaustive empirical study of iterative self-repair for LLM code generation across diverse architectures, parameter scales, and benchmarks (2604.10508). The central focus is the effectiveness and characteristics of self-repair—where a model, upon producing a faulty code sample, is prompted to correct itself using execution error feedback and its prior attempt. Evaluation covers seven models from Meta, Alibaba, and Google, including both dense and Mixture-of-Experts (MoE) configurations, on HumanEval and MBPP.
Single-pass pass@1 benchmarks are standard, but they ignore the iterative, error-driven workflow that dominates human programming. This work systematically quantifies (1) how much accuracy can be recovered via iterative self-repair, (2) how efficiency and gains change with model family and scale, and (3) which error types define the practical limits of LLM self-correction.
Experimental Design
Seven models ranging from Llama 3.1 8B through Gemini 2.5 Pro are compared, with key axes including parameter scale, dense vs. MoE architectures, and open-weight vs. proprietary family. HumanEval (n=164) and MBPP Sanitized (n=257) serve as benchmarks, with each sample going through up to five attempts—initial plus four repair rounds.
All models employ greedy decoding for determinism. Error messages, code outputs, and previous attempts are composed into prompts fed to the model for self-repair. Error types are categorized (assertion, syntax, name, type/value, index/key, timeout) to analyze which failures are most/least self-correctable. A prompt ablation investigates the impact of minimal, explain-then-fix, and chain-of-thought (CoT) prompting.
Iterative self-repair yields universal gains for all models, regardless of scale and architecture. On HumanEval, self-repair improvements (Δ) range from +4.9 to +17.1 percentage points (pp), with Gemini 2.5 Flash achieving the highest final pass@1 (96.3%).
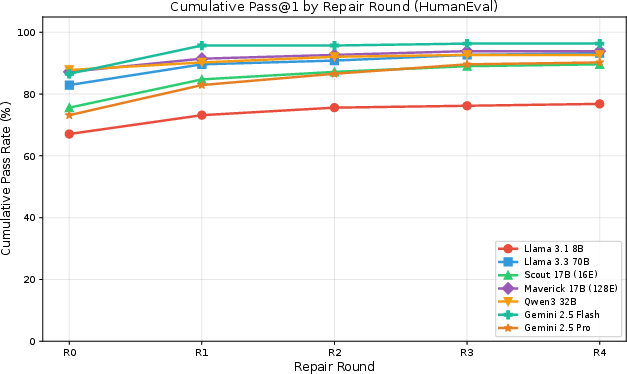
Figure 1: Cumulative pass@1 rate on HumanEval across repair rounds for all seven models, with Gemini 2.5 Flash reaching 96.3%; most gains are realized within the first two rounds.
MBPP sees even larger repair gains (up to +30.0 pp for Gemini 2.5 Flash), reflecting more headroom and the impact of error type.
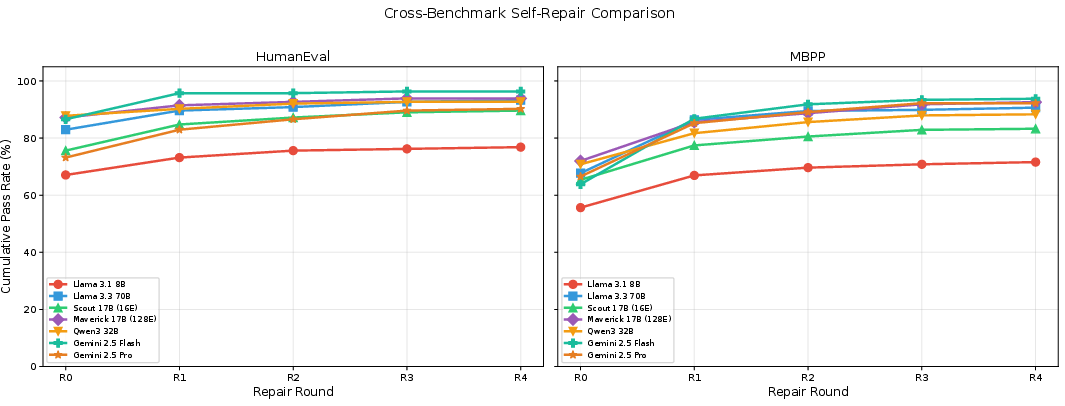
Figure 2: Self-repair gains are consistently larger for MBPP than HumanEval, with Gemini 2.5 Flash outperforming all other models (+30.0 pp on MBPP).
Gemini 2.5 Flash consistently establishes a new ceiling for open-weight and proprietary models, outpacing even larger dense and deeper MoE models. Notably, self-repair works robustly with only prompt-based error feedback at the 8B scale, contrary to prior work that required fine-tuning to enable self-repair for weaker models.
Error Taxonomy and Self-Repair Limits
A critical, novel contribution is the breakdown of error repairability by category. Across all models, assertion errors are the predominant failure mode and are the hardest to repair: only ∼45% are fixed through iterative self-repair. In contrast, name errors (undefined variables etc.) are repaired at rates ∼77%.
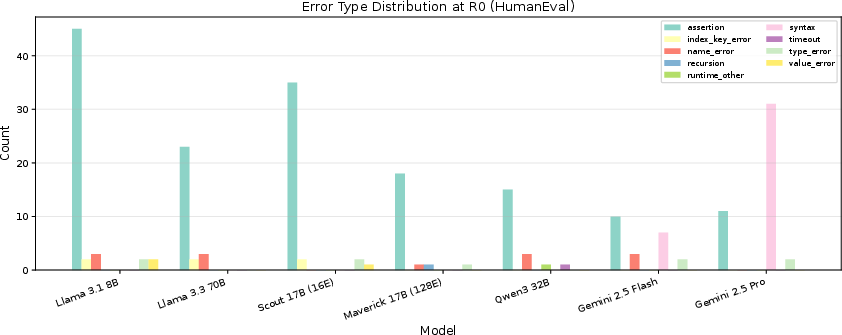
Figure 3: Distribution of error types at the initial attempt (R₀) on HumanEval for each model.
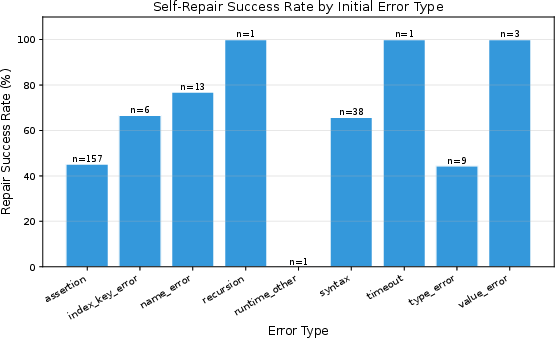
Figure 4: Repair success rate by error type; assertion errors demonstrate marked resistance to self-repair compared to name and syntax errors.
This suggests fundamental limitations: while LLMs reliably fix syntactic or superficial bugs via error feedback, “silent” logical mistakes that yield assertion errors remain challenging due to insufficient specificity in error signals.
Repair Dynamics and Marginal Returns
The incremental benefit of each repair round exhibits rapidly diminishing returns.
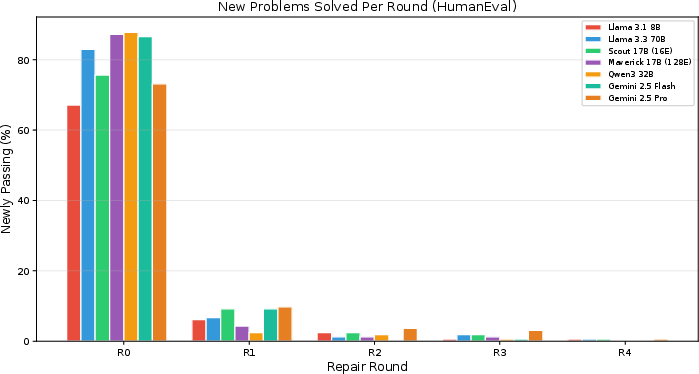
Figure 5: The first repair round always provides the largest marginal gain; additional rounds have sharply diminishing returns across all models.
Across all benchmarks and models, the majority of repairable failures are fixed in the first two rounds (76–95% of total possible gain). For deployment, this implies that allocating budget for two repair iterations captures almost all practical benefit from self-repair.
Prompt Design and Repair Efficacy
Prompt ablation reveals that more sophisticated error feedback strategies—specifically chain-of-thought (CoT)—yield notable additive gains for stronger models. The CoT strategy provides up to +5.5 pp additional self-repair gain on the 70B model relative to a minimal prompt. This effect scales positively with model capacity.
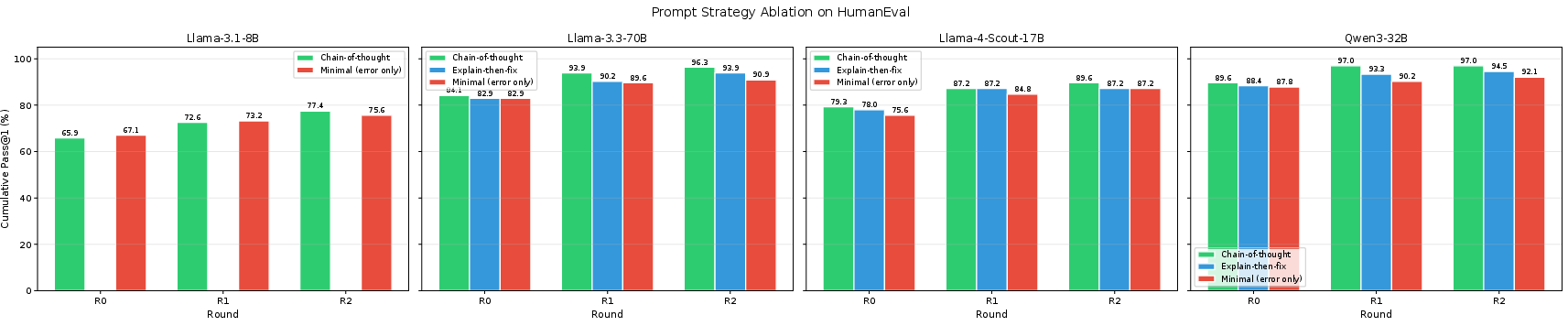
Figure 6: Chain-of-thought repair prompts consistently generate the highest pass rates; the benefit over minimal prompting increases with model capability.
Self-Repair vs. Independent Resampling
The study contrasts self-repair with multiple independent resampling (e.g., pass@5 with stochastic sampling). For models ≥70B, self-repair is consistently more token-efficient and either matches or exceeds the best-of-five pass rate. For smaller models, resampling can provide slightly higher coverage, highlighting a nuanced trade-off.
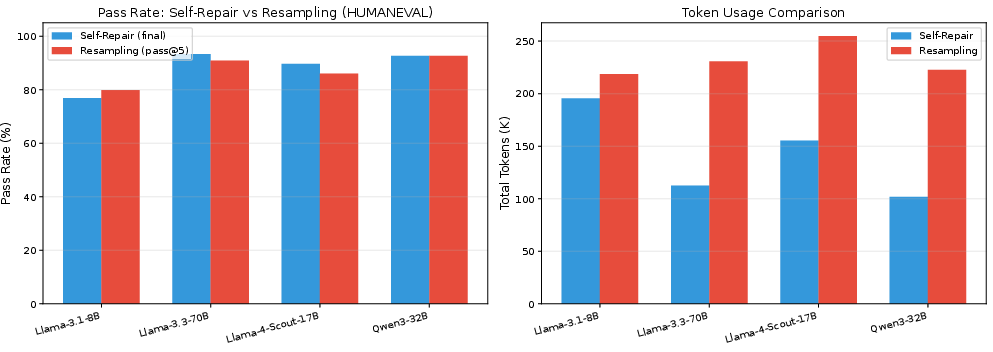
Figure 7: Self-repair is more token-efficient and matches/exceeds resampling for all capable models; only the 8B model falls behind resampling in final pass rate.
Implications for LLM Code Generation
- Self-repair is now a universally valid, training-free mechanism for model improvement. Even 8B-scale, instruction-tuned models achieve reliable gains with only prompt-based feedback.
- Practical systems should allocate at least one but likely not more than two repair rounds, trading off computation against sharply diminishing marginal returns.
- Prompt strategy matters non-trivially for high-end models; CoT strategies further close gaps.
- Error-type analysis provides actionable cues: for failures dominated by assertion errors, alternative approaches (like program synthesis or diversified resampling) may be necessary.
- Dense and MoE architectures exhibit distinct gains and plateau points; however, sufficiently large dense models are competitive with or surpass MoE alternatives in self-repair efficiency.
Theoretical and Practical Considerations
The observed ceiling on assertion error repair suggests a disconnect between error feedback granularity and the required logical revision, aligning with limitations found in general LLM self-correction. Theoretical work is needed to better characterize when error signals can effectively inform semantic correction, and how to bridge the “reasoning gap” for assertion-type failures.
From a deployment standpoint, models like Gemini 2.5 Flash exemplify architectures and training paradigms that maximize both first-pass accuracy and repair capability. This has implications for the design of developer-facing LLM tools, continuous integration bots, and real-time or iterative code synthesis environments.
Conclusion
This paper establishes prompt-based iterative self-repair as a highly effective method for improving the functional correctness of code generated by modern LLMs. Gains are robust across parameter scales, architectures, and benchmark domains, and extend to small models that previously required fine-tuning for self-repair. The marginal utility of each repair iteration and error-type sensitivity are quantified in detail, providing deployment guidelines and identifying future research directions for tool-augmented reasoning and richer error feedback mechanisms.

