- The paper introduces a trajectory-matching identification method that uses gradient-based optimization in differentiable simulation to align simulated and real actuator trajectories.
- It demonstrates significant reduction in joint position errors and enhances sim-to-real reinforcement learning by accurately fitting both parametric and neural actuator models.
- Experimental results show that improved actuator identification halves the MAE compared to traditional test-stand baselines, leading to robust real-world performance.
Trajectory-Based Actuator Identification via Differentiable Simulation: A Technical Analysis
Introduction and Context
Effective system identification of robotic actuators is fundamental to accurate physics simulation for control and reinforcement learning. Traditional approaches often rely on either simplified actuator abstractions or detailed hardware-based test-stand characterization, but each exhibits deficiencies for sim-to-real transfer. The discussed work introduces a trajectory-matching identification methodology using differentiable simulation. This framework poses identification as a parameter optimization task, leveraging gradient-based techniques to align simulated and real-world trajectories, and operates without requiring direct torque or current sensing. The method is validated on high-gear-ratio actuators with embedded PD control and further evaluated for its impact on downstream RL locomotion performance.
Methodological Framework
The trajectory-based actuator identification is formulated as follows. A parameterized simulator Φz generates predicted state trajectories si′ for a given sequence of control inputs ai from initial states s0. The unknown actuator and simulation parameters z∗ are estimated by minimizing the cumulative trajectory discrepancy between real and simulated rollouts:
Lbatch(z)=MN1j=0∑M−1i=1∑N∥W(si,j′−si,j)∥22
where W is a diagonal weighting matrix penalizing discrepancies in joint positions and velocities. The optimization employs gradient-based solvers enabled by differentiable simulators (specifically MJX, a JAX-based MuJoCo variant), making the approach compatible with both compact parametric actuator models and high-capacity neural mappings.
The sensor data requirements are minimized: only encoder-based joint positions and velocities, along with control commands, are necessary. The framework supports actuator parameterizations ranging from structured PD/armature modeling to expressive neural network torque maps and even per-timestep free torque "oracle" sequences to upper bound achievable trajectory fit.
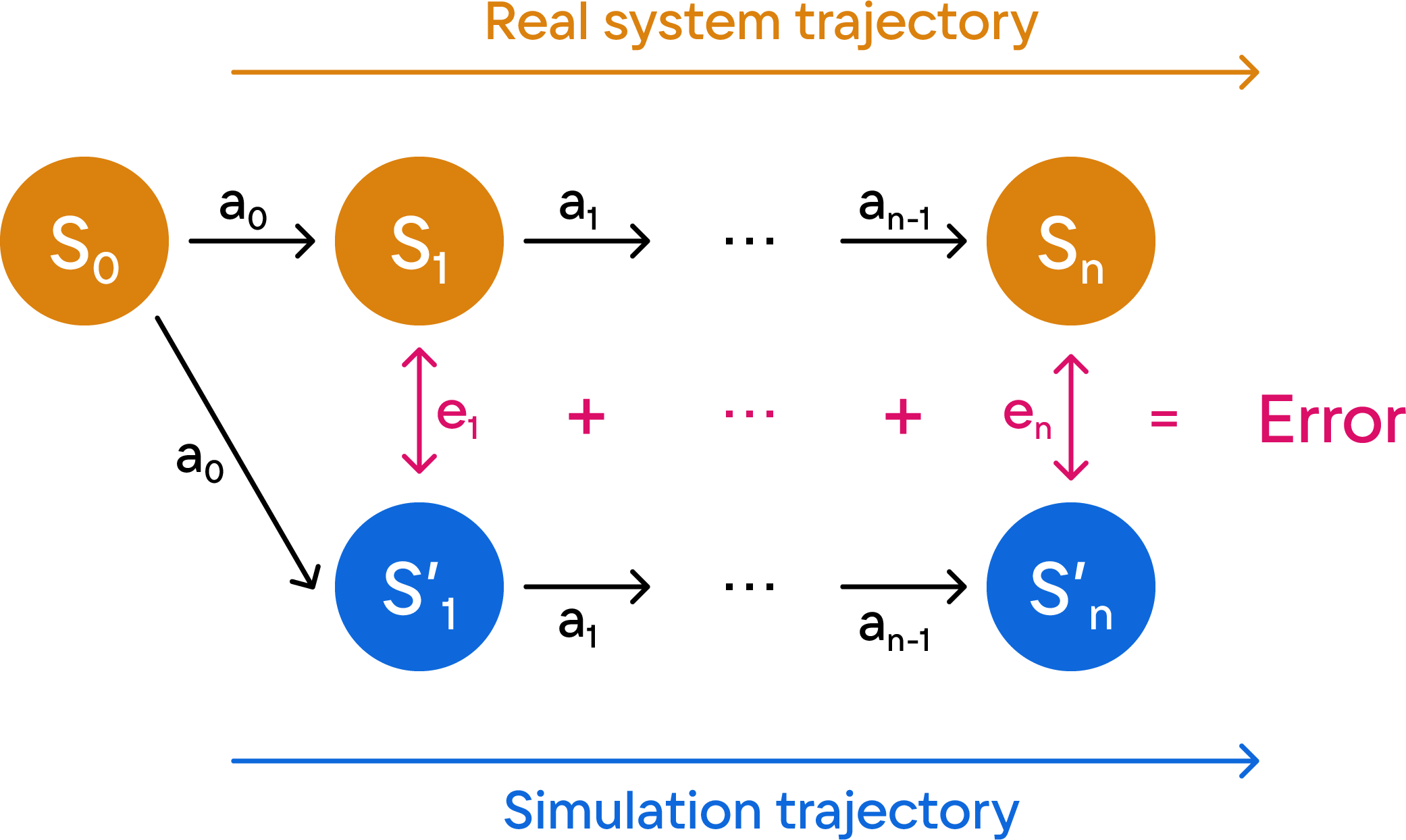
Figure 1: Illustration of trajectory-matching optimization: the real system follows trajectory {si} under control inputs {ai}; the simulator, parameterized by z, generates predicted states si′0, and the error at each step is minimized.
Experimental Validation and Baseline Comparisons
Validation of the framework targets closed-loop fidelity for a high-gear-ratio actuator (210:1) with nontrivial embedded control. The identification pipeline is benchmarked against multiple baselines:
- Bench-Sup: An MLP-based supervised model trained on torque-labeled test-stand data.
- Param-ES: A gradient-free evolution strategy optimizer (sMAES) for parametric actuator parameters.
- Residual-RL: A neural residual policy in the spirit of ASAP-style sim-to-real correction.
- TrajID-Param/TrajID-NN: Differentiable simulation-based parameter/numerical network regressors (proposed).
- Torque-Oracle: An unconstrained per-timestep torque sequence upper bound.
Quantitative assessment is performed by aligning models with measured hardware rollouts under identical control inputs, and MAE in joint position is reported.
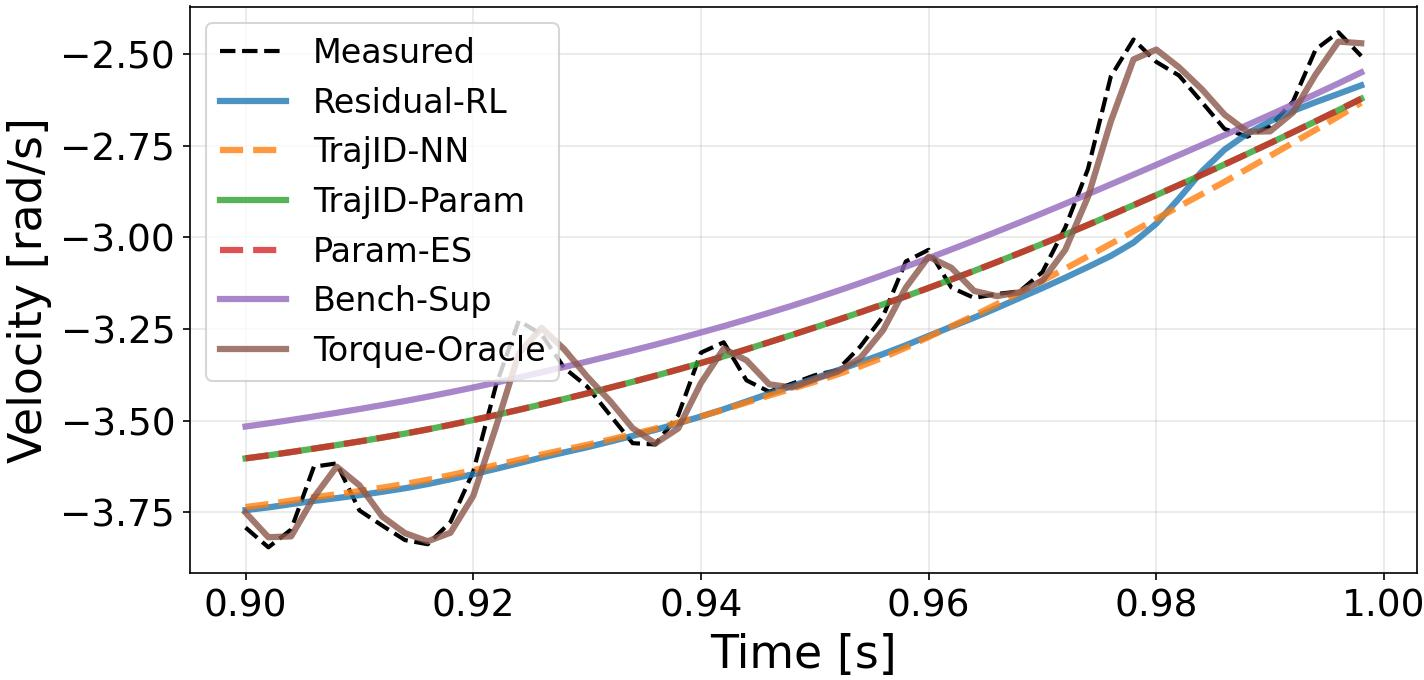
Figure 2: Measured (black dashed) versus simulated (colored) motor velocities under identical control inputs, for each actuator model.
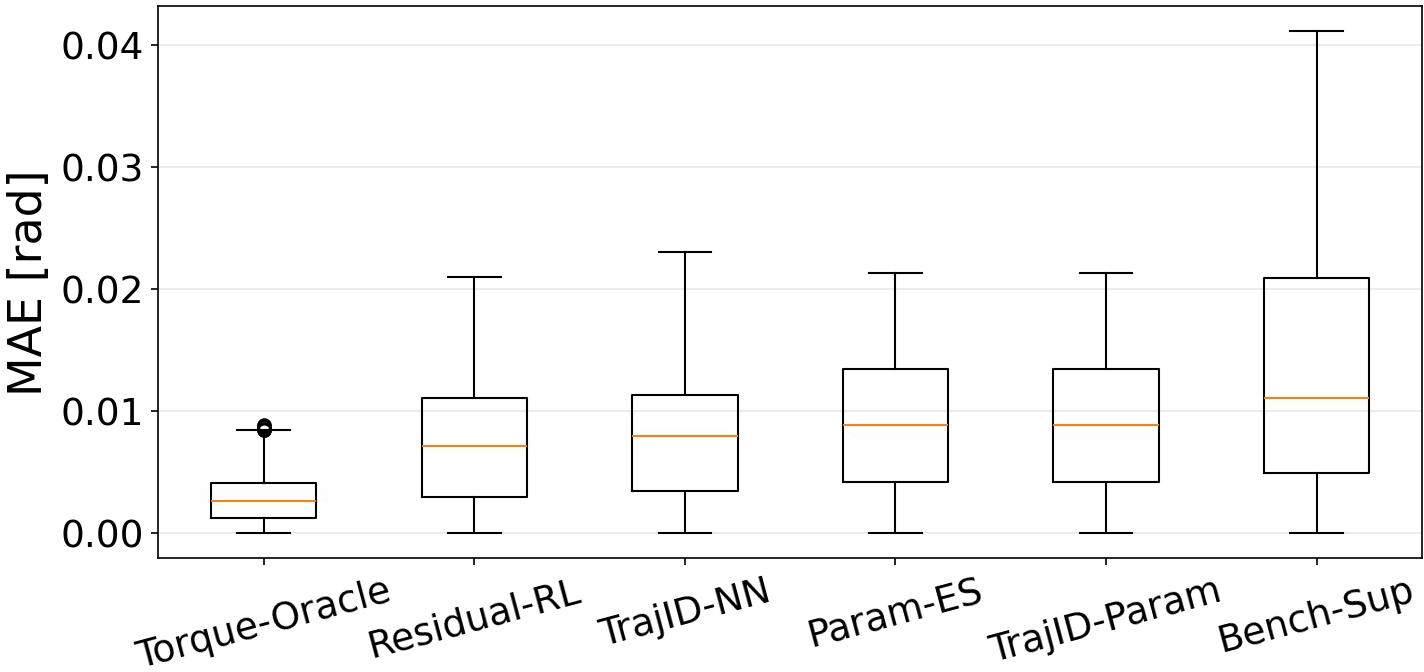
Figure 3: Position MAE for each actuator model, revealing substantial gains for trajectory-matching methods over test-stand baselines.
Notable numerical results:
- Bench-Sup: si′1 mrad MAE.
- TrajID-NN: si′2 mrad MAE.
- Residual-RL: si′3 mrad MAE.
- TrajID-Param: si′4 mrad MAE.
- Torque-Oracle: si′5 mrad MAE.
Trajectory-matching methods halve the position MAE versus test-stand-trained baselines. Notably, gradient-based optimization scales efficiently to high-dimensional actuator models, whereas gradient-free methods are only tractable for small parameter sets.
Optimization Stability, Sensitivity, and Design Choices
The proposed identification shows strong repeatability. In 25 independent runs, estimated PD and armature parameters have negligible variance, with consistently stable convergence.
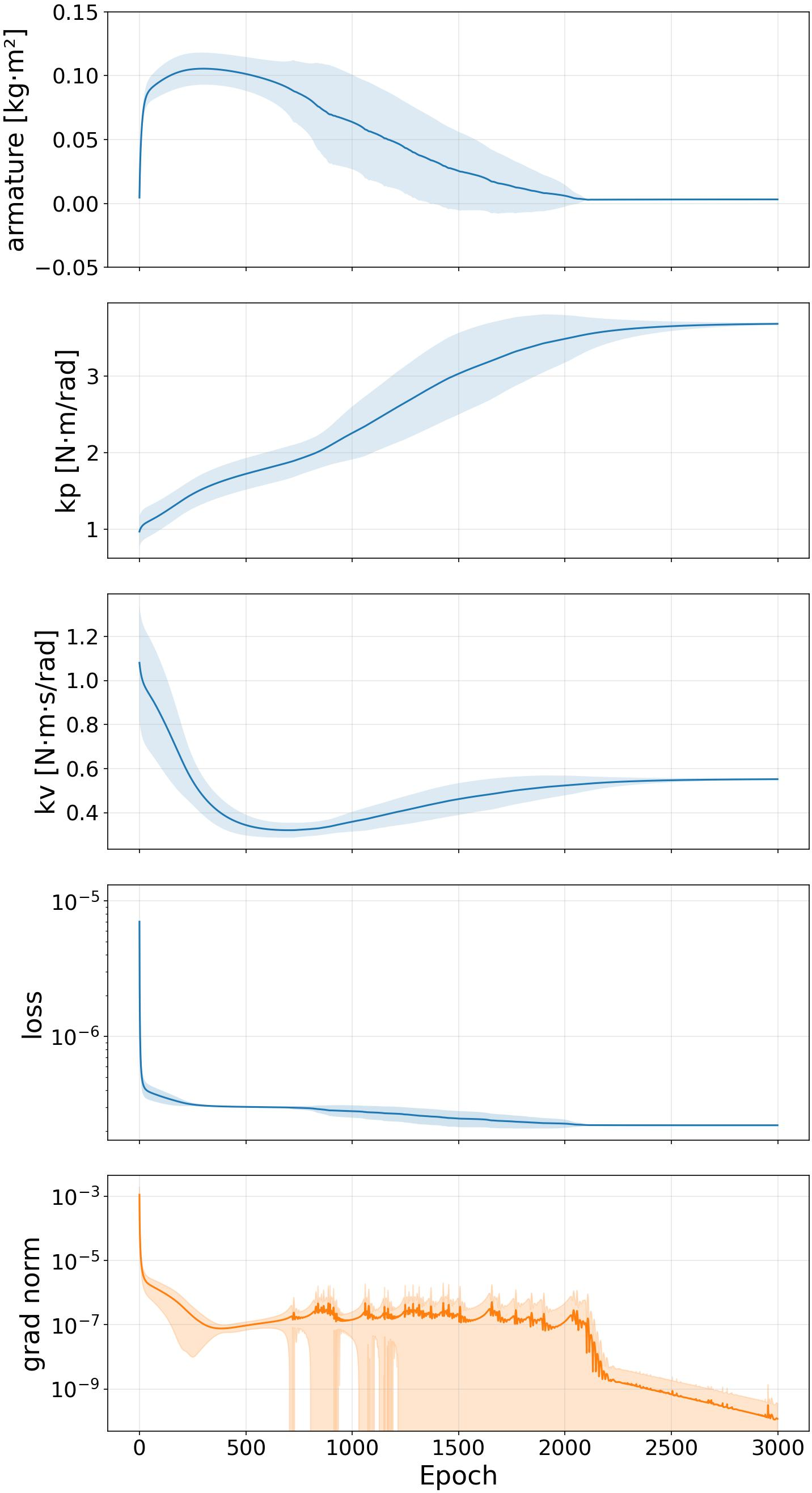
Figure 4: Parameter, loss, and gradient norm convergence for TrajID-Param over 25 runs, indicating high repeatability.
Objective sensitivity analyses demonstrate that the compact parametric models are robust to loss weighting and prediction horizon choices. In contrast, flexible neural models are more susceptible to overfitting on noisy velocity data and can accumulate integration errors over longer horizons.
Figure 5: Validation MAE versus the position/velocity weighting in the loss for different model architectures.
Figure 6: Validation MAE versus prediction horizon, illustrating horizon-robustness of parametric models and more variable neural/horizon-dependent behavior for flexible models.
Downstream Robotics Application: RL Policy Transfer
To assess practical implications, the refined actuator models are deployed in a sim-to-real RL workflow for quadrupedal locomotion (miniPi robot). Policies trained with default versus identified actuator parameters are transferred to hardware and evaluated for forward travel distance and rotational alignment.
Figure 7: Real-robot trajectory comparisons for baseline and refined policies; refined model leads to increased distance and improved alignment.
Mean outcomes over 10 trials:
| Metric |
Baseline |
TrajID Model |
| Rotation (deg) |
si′6 |
si′7 |
| Distance (m) |
si′8 |
si′9 |
Policy trained with the trajectory-identified actuator achieved 46% greater travel and 75% lower rotational drift under identical deployment conditions.
Practical and Theoretical Implications
This approach systematically closes the actuation gap in sim-to-real transfer workflows without additional instrumentation. By fitting actuator dynamics at the trajectory level, including transients, the method avoids pitfalls of steady-state-only test-stand calibration and circumvents the need for torque/current sensor access. Its compatibility with both interpretable parametric and high-capacity neural models enables flexible trade-offs between physical insight and representational power.
Limitations include imperfect coverage of unmodeled actuator nonlinearities (e.g., temperature effects, supply sag, hysteresis), dependence on excitation richness in identification data, and challenges for generalization beyond the tested actuator class. Yet, the demonstrated simulation fidelity gains and real-robot RL transfer improvements confirm clear downstream value.
Future Directions
Several avenues remain for broadening applicability and enhancing robustness:
- Extension to multi-joint, contact-rich platforms and new actuation modalities.
- Integration of recurrent and temporal architectures to capture hysteresis, delay, and long-term dependencies.
- Formal robustness and identifiability analyses, with expanded validation across excitation and task regimes.
- Incorporation of regularization strategies and meta-learning to further improve generalization and reduce overfitting risks.
Conclusion
The trajectory-based differentiable simulation identification method delivers quantifiable improvements over both test-stand and residual RL baselines for actuator modeling, yielding superior sim-to-real transfer performance in practical legged robotics tasks. The presented results highlight the relevance of full trajectory-level calibration for high-fidelity simulation and robust control pipeline deployment. The approach provides a scalable foundation for future system identification research and sim-to-real RL applications in robotic systems with restricted measurement access.