Multi-modal, multi-scale representation learning for satellite imagery analysis just needs a good ALiBi
Published 11 Apr 2026 in cs.CV | (2604.10347v1)
Abstract: Vision foundation models have been shown to be effective at processing satellite imagery into representations fit for downstream tasks, however, creating models which operate over multiple spatial resolutions and modes is challenging. This paper presents Scale-ALiBi, a linear bias transformer attention mechanism with a spatial encoding bias to relationships between image patches at different ground sample distance scales. We provide an implementation of Scale-ALiBi over a dataset of aligned high- and low-resolution optical and low-resolution SAR satellite imagery data using a triple-contrastive and reconstructive architecture, show an improvement on the GEO-Bench benchmark, and release the newly curated dataset publicly.
The paper introduces Scale-ALiBi, integrating a GSD-aware transformer attention mechanism for effective multi-modal, multi-scale satellite imagery analysis.
It employs a novel training framework with triple-contrastive and reconstruction losses to align SAR, low-res, and high-res optical data using a curated dataset.
Experimental results on GEO-Bench demonstrate competitive performance, highlighting improved multi-scale grounding and robustness for diverse remote sensing tasks.
Multi-Modal, Multi-Scale Representation Learning with Scale-ALiBi Attention for Satellite Imagery
Introduction and Motivation
Representation learning for satellite imagery presents critical challenges due to the wide spectrum of spatial resolutions (GSDs) and sensing modalities (e.g., optical, SAR). Existing models have primarily focused on individual axes of variation—resolution, modality, or temporal sequence—often neglecting the compositional richness that contemporaneous, co-registered multimodal, and multi-scale views can provide. The paper "Multi-modal, multi-scale representation learning for satellite imagery analysis just needs a good ALiBi" (2604.10347) introduces Scale-ALiBi, a transformer-based attention mechanism systematically incorporating both scale (via GSD) and modality-awareness into the representation learning process. The approach is validated using a novel, curated dataset of aligned high-res and low-res optical, and low-res SAR images, and is benchmarked on GEO-Bench, demonstrating competitive quantitative results, alongside public dataset and code release.
Scale-ALiBi Attention Mechanism
At the core of Scale-ALiBi is an extension of the ALiBi (Attention with Linear Biases) attention paradigm, previously generalized to 2D-ALiBi/X-ALiBi for encoding spatial Euclidean distances between patches. Scale-ALiBi advances this formulation by introducing a GSD-dependent term in the attention bias, enabling the transformer to compare tokens not just by their patchwise spatial proximity but also by their absolute physical ground distances across varying resolutions. The attention logits are adjusted before the softmax via:
ahij=d⋅qhi⋅khj−g(i,j)⋅m(h)
where g(i,j)=distance(i,j)⋅GSD embeds the spatial-geodesic relationship scaled by ground sample distance. This architecture supports simultaneous processing of images with differing spatial resolutions and varying numbers of patches while maintaining semantic alignment in physical space.
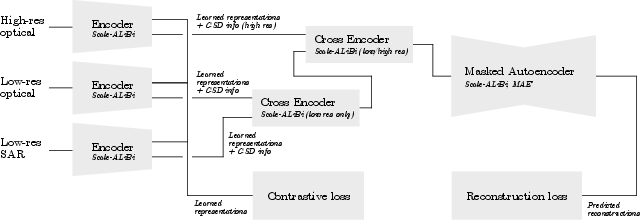
Figure 1: A block diagram of the full Scale-ALiBi model.
A direct implication is robust multi-scale grounding and improved extrapolation to longer (larger) image sequences—critically important in satellite imagery, which can be arbitrarily large in coverage.
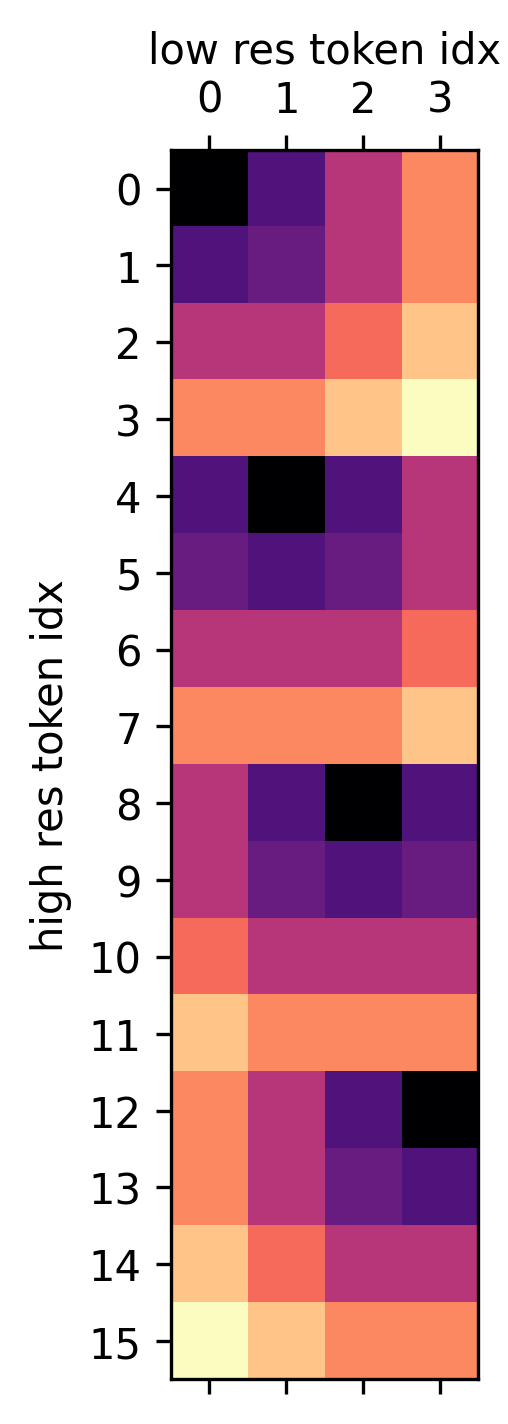
Figure 2: Example Scale-ALiBi attention matrix between patches from different sized images, encoding both spatial and GSD relationships for precise cross-resolution comparison.
Triple-Contrastive and Reconstructive Training
The representation learning framework relies on three modality-specific Vision Transformer (ViT) encoders: low-res SAR (Sentinel-1), low-res optical (Sentinel-2), and high-res optical (NAIP), each generating token streams corresponding to their input resolution. A pair of cross-encoders fuses these representations first across low-res modalities and then integrates the high-res stream.
The learning objective is a combination of (i) triple-contrastive InfoNCE loss, which aligns representations of SAR, low-res optical, and high-res optical from the same location, and (ii) a reconstruction loss via a masked autoencoder, enforcing the ability to recover all original modalities from the multi-modal representation. This dual objective intentionally enforces both modality-invariance and reconstructibility, facilitating adaptation to downstream supervised and unsupervised tasks.
High-quality training of Scale-ALiBi necessitates precisely aligned diverse resolution and modality samples. To this end, the paper introduces a new dataset covering the continental United States and Puerto Rico, leveraging Sentinel-1, Sentinel-2, and NAIP, with careful tiling and pairing of 256×256 and 512×512 image patches at consistent geospatial coordinates. The compositional structure of the dataset (Figure 3) is a strong resource for the wider remote sensing community, mitigating a major bottleneck for cross-modal and multi-resolution representation learning.
Figure 3: A selection of samples from the Scale-ALiBi dataset; rightmost column highlights double-resolution high-res optical samples aligned with lower resolution modalities.
Experimental Results and Comparative Evaluation
Scale-ALiBi is evaluated on the GEO-Bench benchmark, which comprises multiple classification and segmentation tasks over both SAR and optical data streams. The new model is compared against CROMA (which lacks high-resolution modality input and GSD-aware attention) using identical hardware and training protocols for parity.
Strong numerical results are reported: on neural network-based classification, Scale-ALiBi achieves up to 87.8% on certain tasks and records similar or better scores in k-means/k-NN clustering compared to CROMA. Notably, the neural linear classifier accuracy for the "m-pv4ger" task is 87.77% for Scale-ALiBi (low-res encoder) versus 88.53% for CROMA, reflecting near-tail parity. Some k-means clustering and k-means+UMAP settings show Scale-ALiBi marginally outperforming the baseline, especially with high-res encoders. The results indicate Scale-ALiBi maintains or sometimes surpasses state-of-the-art performance, with the expectation that further scaling of training (especially with larger, longer training runs) will lead to consistent improvement over previous baselines.
Practical and Theoretical Implications
The learned, GSD-aware, multimodal representations in Scale-ALiBi improve model generalization over heterogeneous remote sensing data and enable direct fusion of variable resolution imagery—a previously challenging setting for deep learning in earth observation. Models based on this paradigm can natively support applications such as land use monitoring, change detection, and multi-temporal analysis where the revisit frequency and quality of data differ sharply between modalities and sensors.
Theoretically, Scale-ALiBi underscores the flexibility of transformer attention mechanisms amenable to explicit inductive bias engineering—here, embedding prior knowledge about physical scale and modality structure directly into the attention computation—offering pathways for future research in multi-source geospatial fusion, temporal modeling, and cross-domain adaptation.
Future Directions
Potential developments include:
Expansion to global datasets: Scaling Scale-ALiBi with worldwide high-res/SAR/optical pairing.
Temporal modeling: Integrating time into Attention biases for robust change detection and sequence modeling.
Downstream transfer: Applying the learned representations to novel remote sensing tasks (e.g., disaster mapping, precision agriculture).
Scale-ALiBi introduces a principled attention bias catering directly to the needs of multi-modal, multi-scale satellite imagery representation learning, validated both by architectural innovation and competitive benchmarks on the GEO-Bench suite (2604.10347). The release of code and data assets not only facilitates reproducibility but establishes a new foundation for joint resolution and modality-aware earth observation models.