- The paper demonstrates that warm-starting RL with a supervised pose estimator accelerates convergence and enhances registration accuracy in liver surgery.
- It employs a Siamese actor–critic architecture with discrete SE(3) control and auxiliary heads for adaptive step-size and termination in registration tasks.
- Results show significant reductions in target registration error and inference time compared to traditional optimization methods under clinical and synthetic conditions.
Warm-Started Reinforcement Learning for Iterative 3D/2D Liver Registration: Technical Assessment
Introduction
This paper presents a discrete-action reinforcement learning (RL) framework for rigid registration of preoperative CT to intraoperative laparoscopic video in the context of augmented reality (AR) guidance for minimally invasive liver surgery (2604.10245). The method leverages a Siamese actor–critic architecture, warm-started from a supervised pose estimator, and introduces an environment with GPU-accelerated on-the-fly rendering for closed-loop control. The approach is designed to be patient-specific, emphasizing rapid adaptation and inference efficiency, and is validated against both synthetic and clinical datasets.
Methodology
The proposed pipeline formulates the registration as a sequential decision-making process. The RL agent receives concatenated six-channel inputs encoding both the rendered CT image and the target intraoperative image, including semantic anatomical masks and normalized depth. The control space is discrete, operating over 12 rigid body actions parameterized as SE(3) increments (translation and rotation, positive/negative direction), and the agent predicts not only the action, but also the step granularity (coarse/fine) and termination probability.
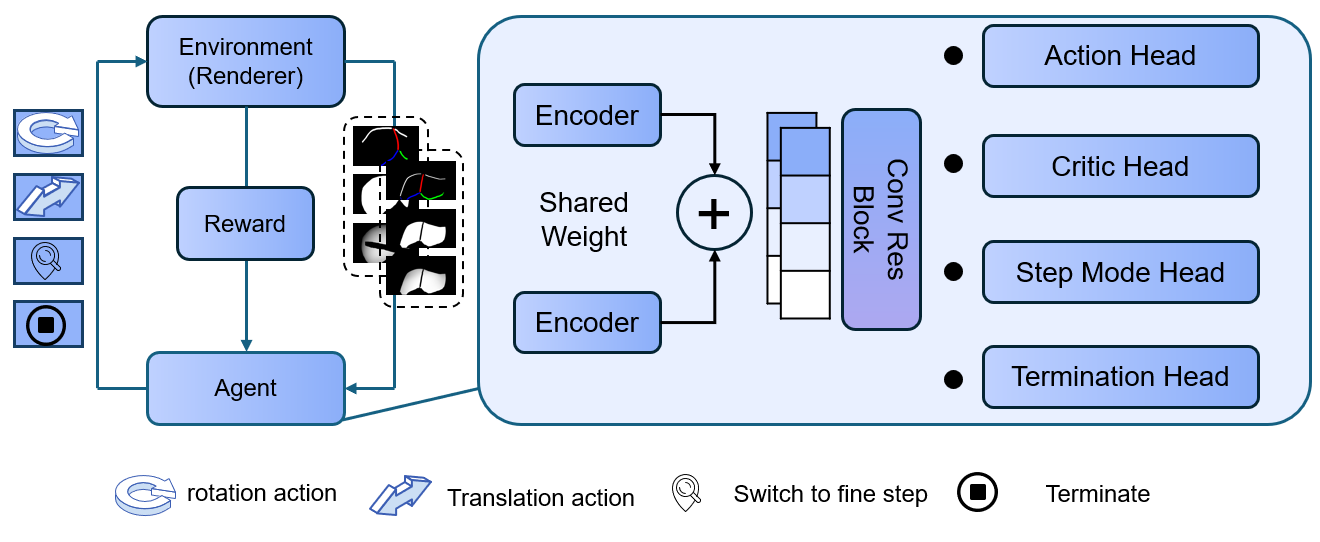
Figure 1: Overview of the RL framework integrating Siamese encoding, residual blocks, and four policy heads for action, step granularity, and episode termination.
Key architectural choices include:
- Warm-Started Feature Encoder: The RefineNet backbone, pretrained with supervised regression, accelerates RL convergence and provides robust geometric representations.
- Action Space: Using an SE(3) exponential map for camera poses ensures stable and manifold-consistent updates.
- Auxiliary Policy Heads: Supplementary outputs for step-size control and policy-based termination allow the agent to adjust trajectory adaptively.
- Reward Shaping: The internal reward relies on MSE of mesh vertices transformed by the relative pose, penalizing non-improving steps to discourage dithering.
- Curriculum Scheduling: The pose error threshold for "success" is progressively tightened, facilitating stable learning from coarse to fine registration stages.
Training is conducted via PPO with frozen encoder weights, four optimization epochs per rollout, and explicit entropy annealing. During inference, iterative updates are applied until the termination confidence exceeds a threshold or a maximum step limit is reached.
Experimental Setup and Evaluation
- Data Source: The Rabbani et al. multi-patient dataset provides real intraoperative video with tumor landmarks for quantitative evaluation.
- Synthetic Perturbations: Extensive synthetic pose sampling avoids overfitting, with data augmentations simulating occlusions and mask perturbations.
- Patient-Specific Models: Training and validation are conducted for each patient case independently, allowing focused assessment under realistic clinical conditions.
Evaluation metrics include mean squared error (MSE) on synthetic renderings and target registration error (TRE) in mm on real data, specifically measuring tumor landmark alignment. Both mean and variance of TRE are reported across initialization perturbations.
Results
Synthetic Data and Termination Policy
Violin plots show that increasing the termination probability threshold consistently lowers final MSE at the expense of increased computational steps.
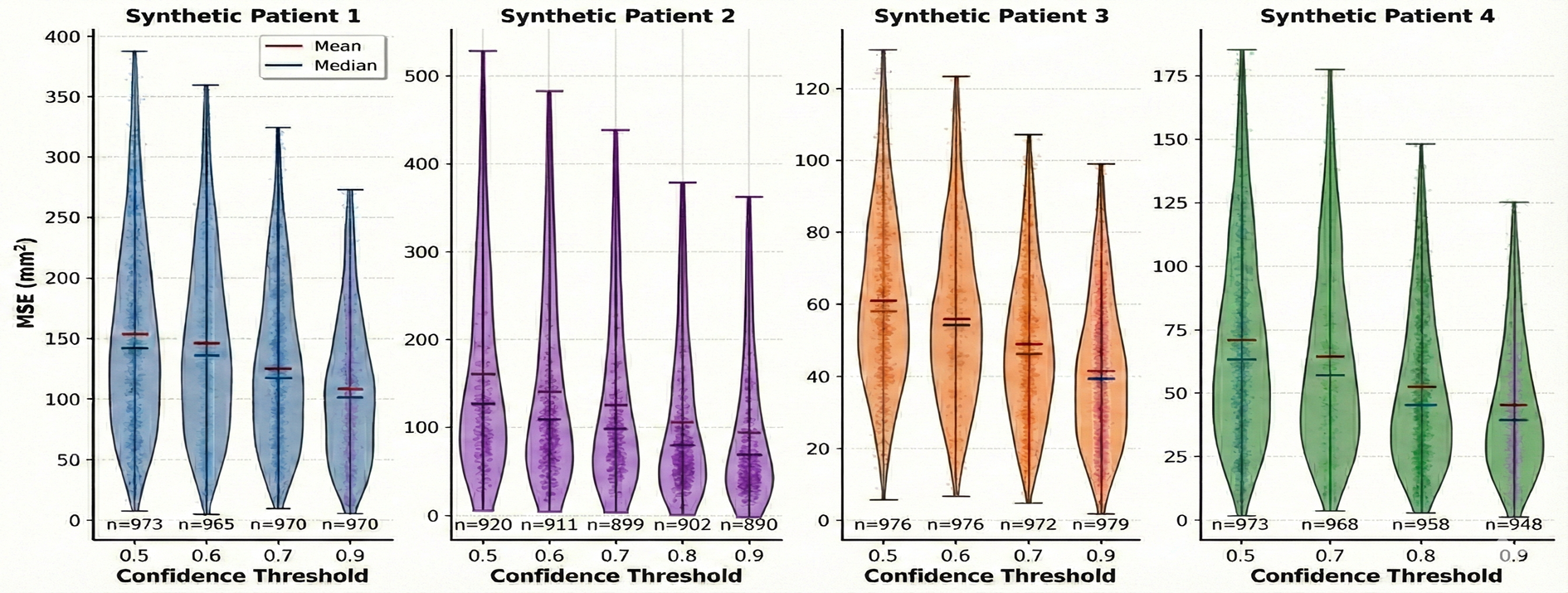
Figure 2: MSE distribution for four synthetic patients; stricter thresholds lower MSE, but increase inference time.
Successful convergence to low MSE is robust for most patients except for the known challenging outlier (Patient 2), where even manual or optimization-based methods struggle due to strong non-rigid deformation.
Clinical Evaluation
On real data, the RL-based pipeline achieves mean TRE comparable to or lower than state-of-the-art baseline methods, especially on challenging patient cases. Step-size switching is shown to improve accuracy. Notably, even when noise is injected into manual segmentations, accuracy is largely preserved.
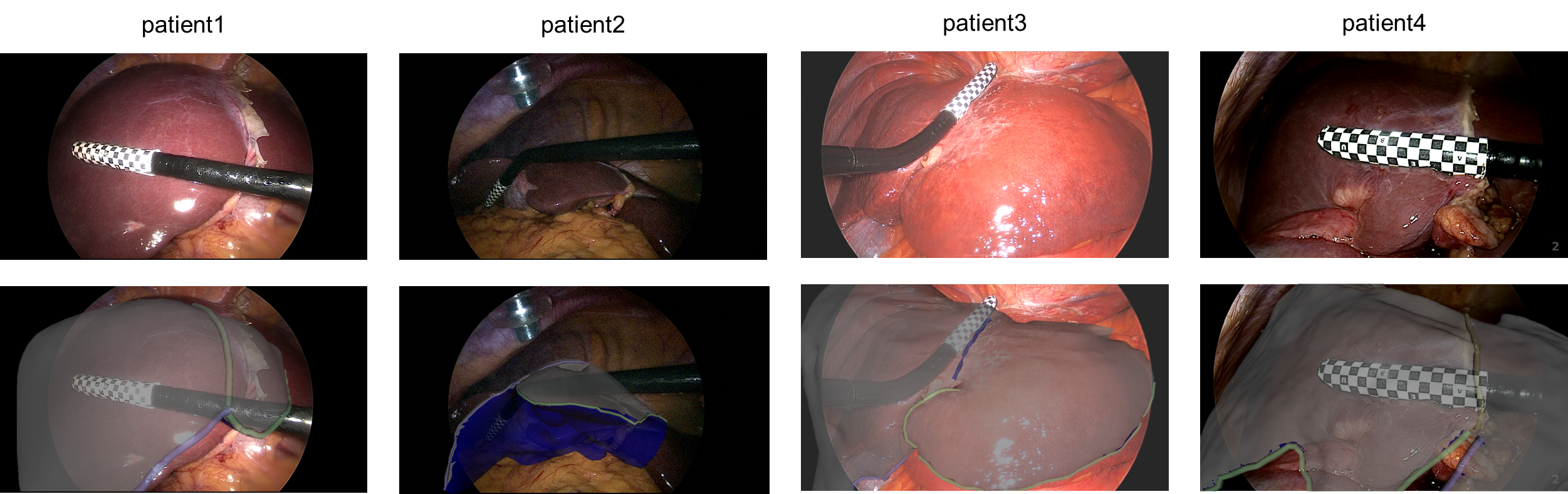
Figure 3: Visual results for four clinical cases; top: intraoperative video, bottom: AR overlays with registered 3D meshes.
Key findings from quantitative results:
- Patient 3/4: Median TREs below 12 mm, outperforming optimization and hybrid baselines.
- Patient 2: Substantial TRE reduction compared to prior methods (from ∼45–53 mm down to 27.4 mm), although visual alignment remains imperfect due to inherent deformation.
- Inference Efficiency: Registration typically terminates in 40–256 steps (∼1–5 s on modern GPUs), which is substantially faster than baselines relying on iterative optimization (30–60 s or more).
Strong numerical results underpin several claims:
- The RL-based method eliminates the need for manual step-size tuning and ad hoc stopping criteria while offering high accuracy.
- Warm-starting from supervised models is essential for convergence; training from scratch yields unstable or diverging RL policies.
Discussion
This work demonstrates that a discrete RL control policy with a warm-started encoder can efficiently automate 3D/2D rigid registration in laparoscopic AR setups. The approach tightly integrates domain knowledge (anatomical masks, depth cues) and geometric control (SE(3) exponential map) within an interactive RL environment.
Practical implications include:
- Inference time reduction compared to classical optimization or hybrid learning/optimization pipelines.
- End-to-end automation: Actions, step sizes, and stopping are jointly optimized, removing reliance on heuristics.
Limitations and future directions:
- Discrete action granularity: The discrete step space constrains the ultimate registration precision and may prolong convergence near optima. Transitioning to continuous action spaces could enable smoother, more adaptive trajectories but will require addressing policy optimization challenges in high-dimensional continuous control.
- Patient-Specific Training: While efficient for small data regimes, this approach does not scale to population-level deployment. A promising direction is to pre-register multiple datasets into a common anatomical space and train a generalized (foundation) policy for cross-patient adaptation.
- Domain Gap: Despite extensive augmentation, synthetic-to-real generalizability is not complete. Incorporating domain adaptation strategies could further decrease the performance gap.
Conclusion
This work establishes the feasibility of warm-started RL for closed-loop, policy-driven CT-to-laparoscopic video rigid registration. Key technical advances include a Siamese RL architecture with explicit geometric control and auxiliary step/termination heads, offering efficient convergence without manual hyperparameter adjustment and demonstrating strong quantitative and qualitative performance on clinical benchmarks. Future research should focus on extending to continuous actions, developing cross-patient foundation models, and systematically addressing domain adaptation to enable rapid deployment in diverse surgical environments.

