- The paper presents an accelerator that achieves Full HD 129FPS 3D Gaussian Splatting rendering through a co-design of model compression and hardware optimization.
- It leverages iterative Gaussian pruning, progressive Spherical Harmonics reduction, and vector quantization to reduce model size by 51.6× with minimal quality loss.
- Hardware optimizations such as near-plane culling and comparison-free sorting significantly cut computations and energy use, enabling real-time performance on AR/VR devices.
A Real-Time, Energy-Efficient Accelerator for 3D Gaussian Splatting Rendering
Introduction
This work addresses the problem of efficient real-time rendering of 3D Gaussian Splatting (3DGS) on resource-constrained platforms, such as AR/VR devices. While 3DGS is effective for novel view synthesis and high-quality radiance field rendering, its substantial computational and storage demands have hampered deployment in edge scenarios. The paper presents a comprehensive co-design of memory-efficient model compression and hardware acceleration, enabling full-HD 1080p rendering at 129 frames per second (FPS) within a strict power and area budget.
Algorithmic Contributions: Compression-Oriented 3DGS
The paper identifies memory footprint, redundant computation, heavy sorting, and workload variability as core barriers to hardware-efficient 3DGS. The proposed pipeline integrates several strategies to reduce both Gaussian count and per-Gaussian storage, tightly coupling these with hardware requirements.
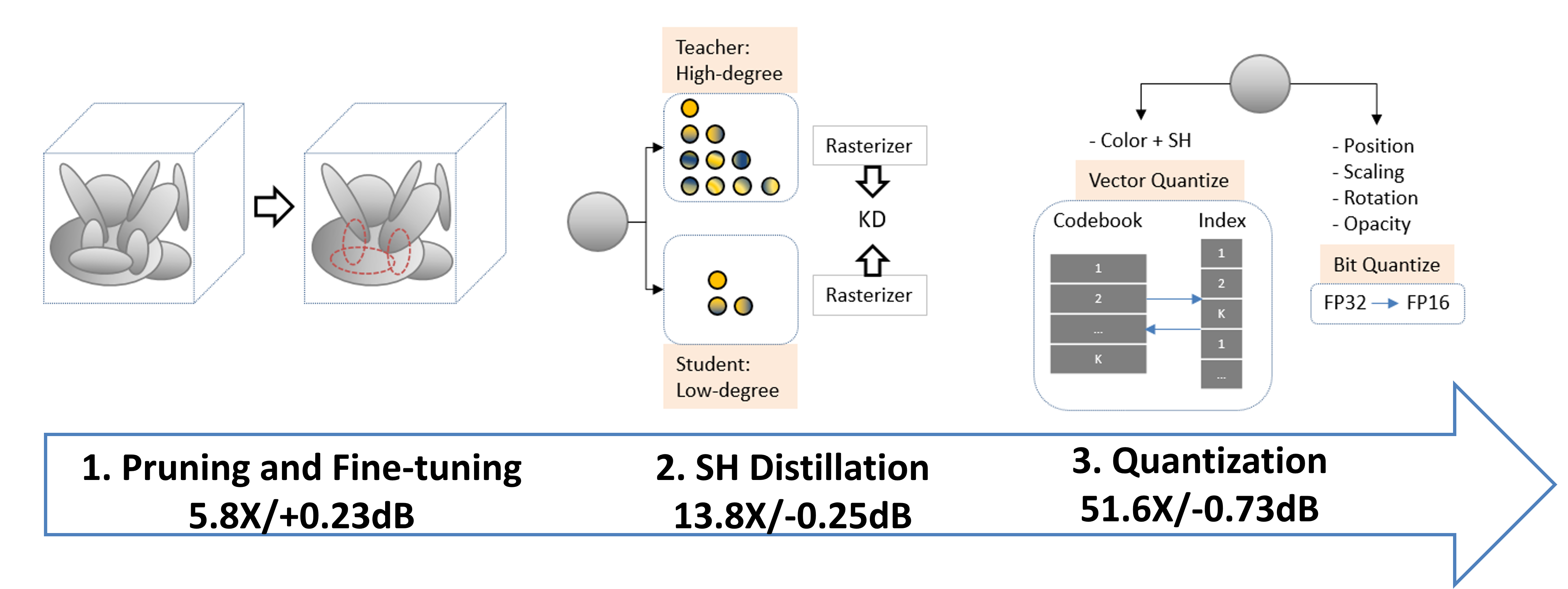
Figure 1: Overview of the proposed model compression pipeline, incorporating pruning, progressive SH degree reduction, and VQ.
Key Compression Techniques
- Iterative Gaussian Pruning and Fine-Tuning: Rather than one-shot aggressive pruning (which harms fidelity), multiple pruning stages with intermediate fine-tuning are executed to maintain quality while reducing count.
- Progressive Spherical Harmonics (SH) Degree Reduction: SH coefficients are distilled in stages, providing gradual reduction in representation size and computational cost with bounded quality degradation.
- Vector Quantization (VQ): VQ is applied to all SH coefficients and colors, not merely low-salience subsets, achieving maximal storage savings.
The result is a 51.6× model-size reduction at a mean PSNR loss of only 0.743 dB, making the technique highly effective for hardware deployment.
Hardware Architecture and Dataflow Optimizations
The hardware is a four-stage pipelined accelerator with explicit design for minimizing unnecessary computations and maximizing power/resource efficiency.
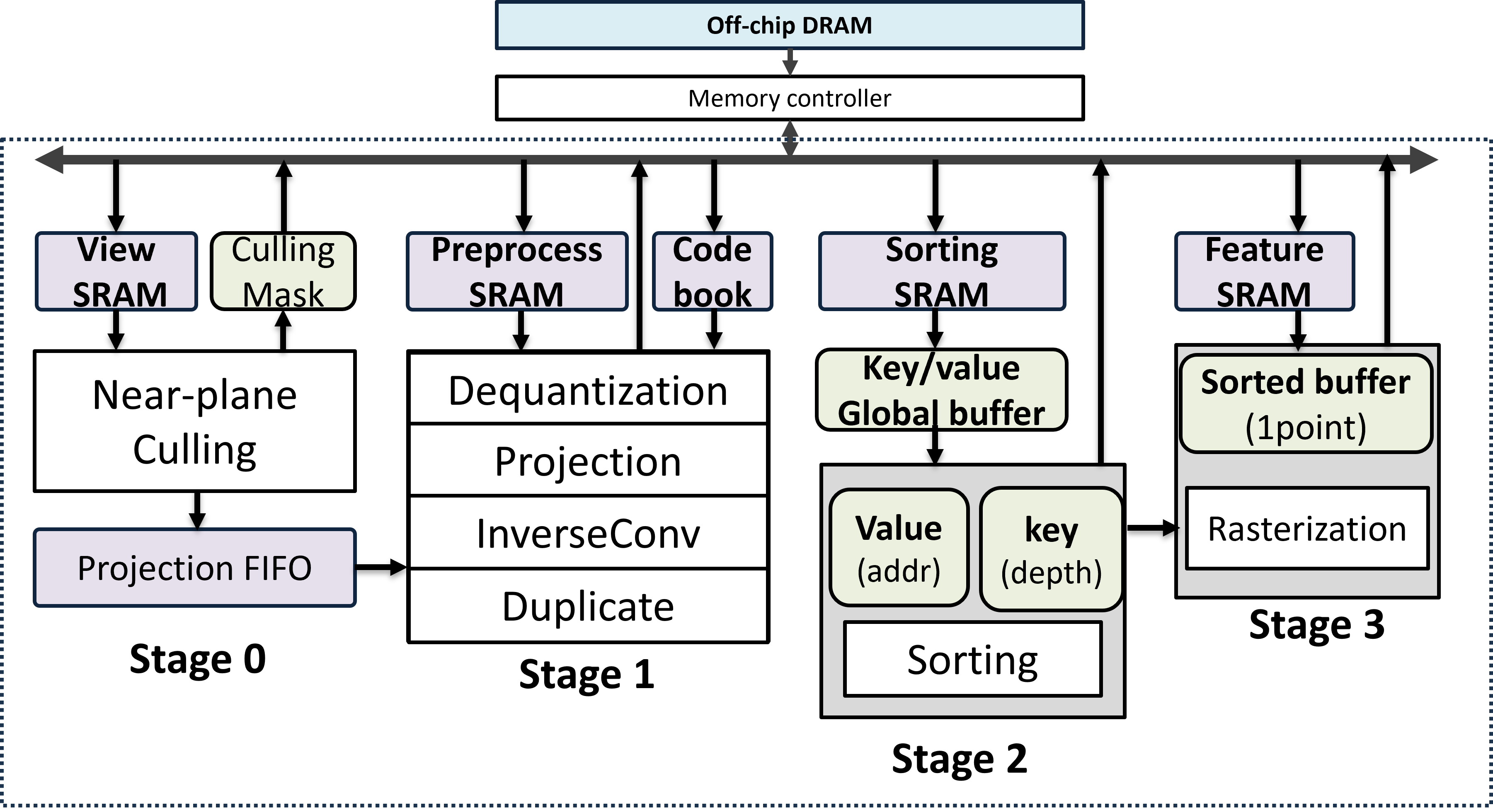
Figure 3: Proposed system architecture integrates preprocessing (culling, projection) with rendering (sorting, rasterization) in a frame-level pipeline.
Preprocessing: Culling and Projection
Near-plane culling removes extraneous Gaussians early, yielding a 56% reduction in required downstream processing for compressed models (see also Figure 3).
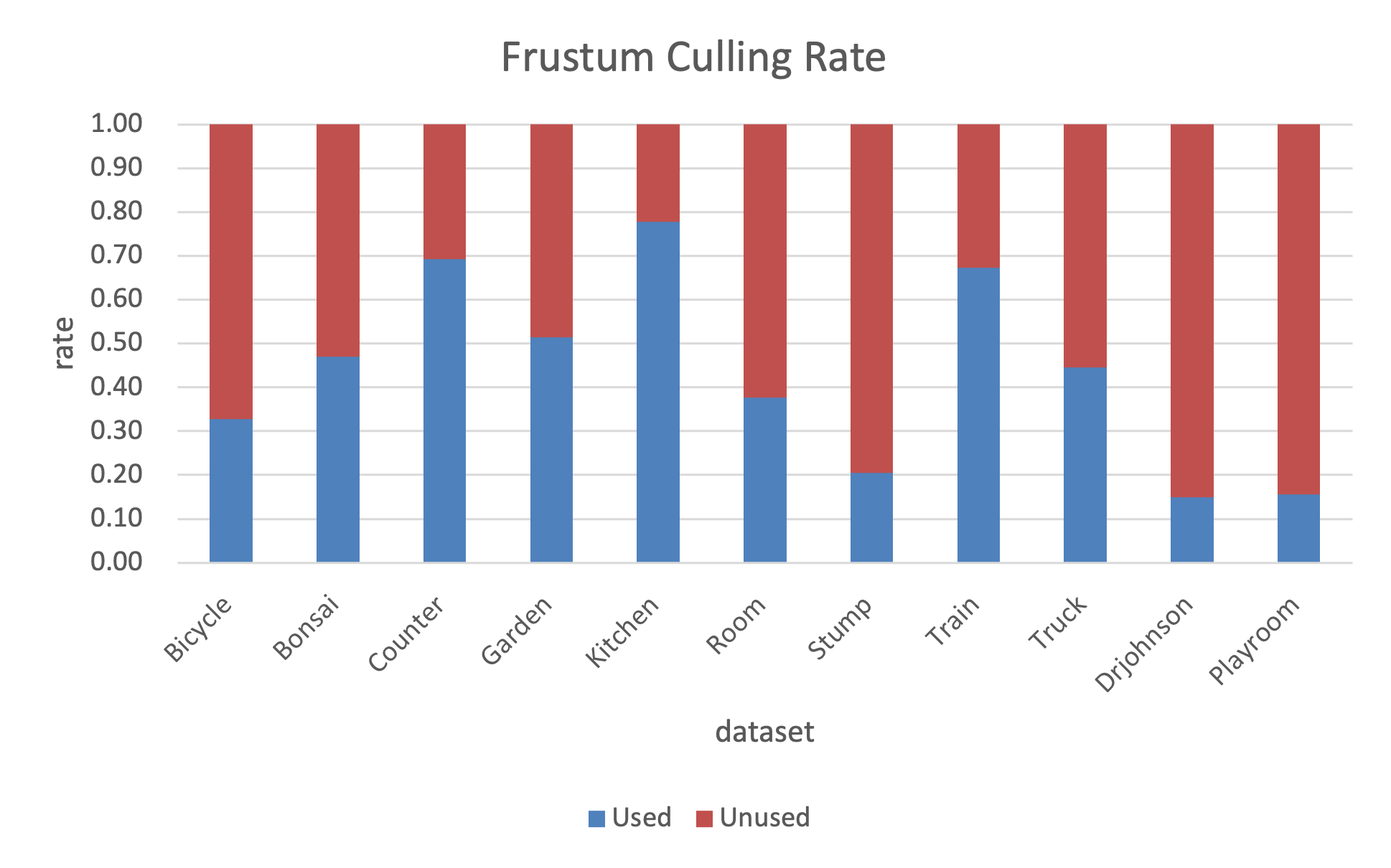
Figure 4: Near-plane culling achieves a 56% reduction in workload for compressed models.
The projection stage exploits the analytical sparsity of the Jacobian, skipping multiplications by zero and resulting in a 53% reduction in computational operations and 63% reduction in processing elements versus naive implementations.
Rendering: Efficient Sorting and Rasterization
The sorting stage implements a parallel, comparison-free, tile-based sorter—eschewing global radix sort and favoring deterministic, area-efficient operation. Sorting and rasterization are tightly coupled, using a fixed per-output latency design to suit α-blending.
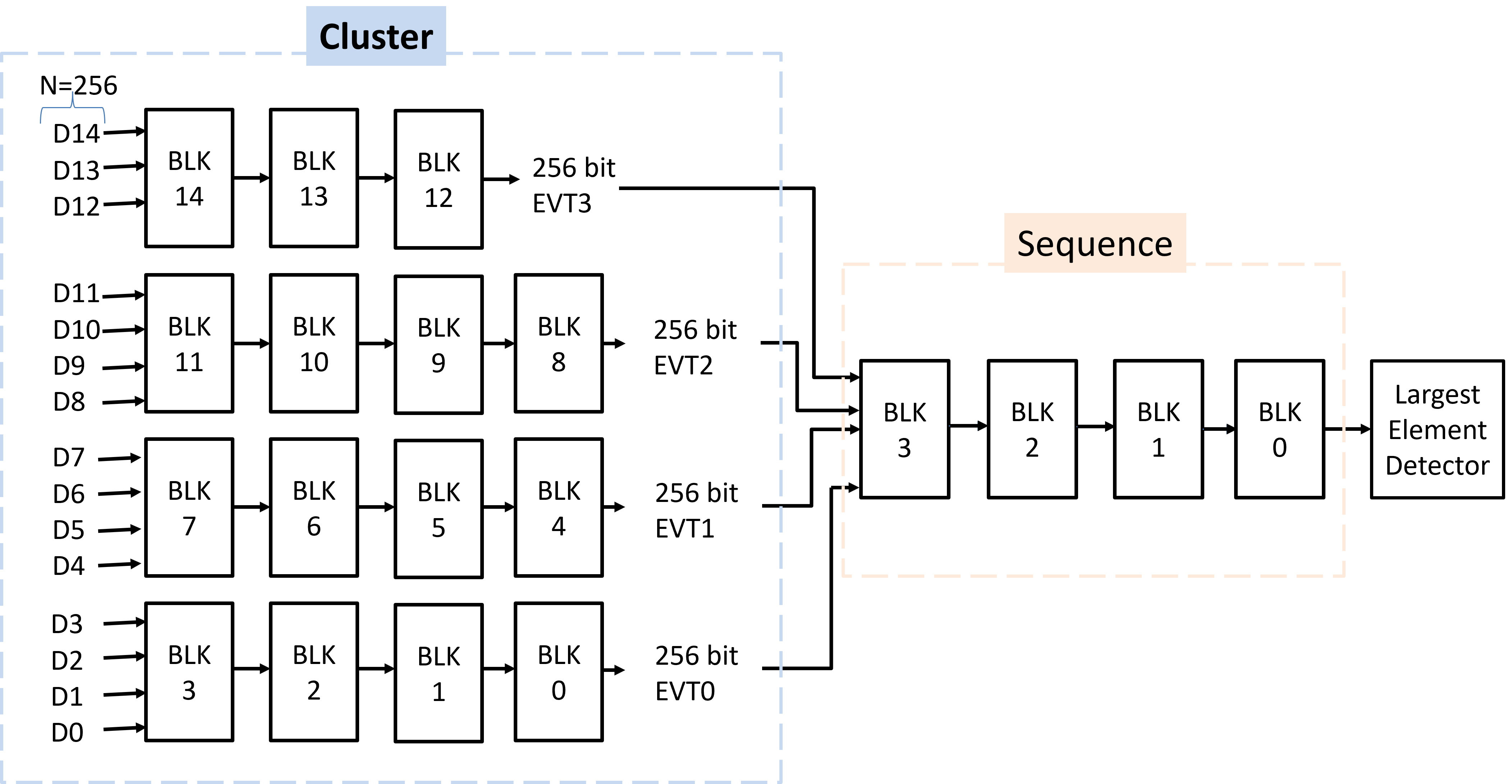
Figure 2: Proposed Gaussian sorting unit uses parallel, comparison-free sorting for low-latency, hardware-friendly operation.
To deal with high tile-to-tile variability, the architecture leverages shared global buffers, ensuring high utilization without artificial upper limits that could manifest as visual artifacts.
The rasterization stage incorporates α-pruning and early termination, omitting further computations for pixels where color/transmittance is saturated. In compressed models, early termination still saves ~24% of computation (Figure 4).
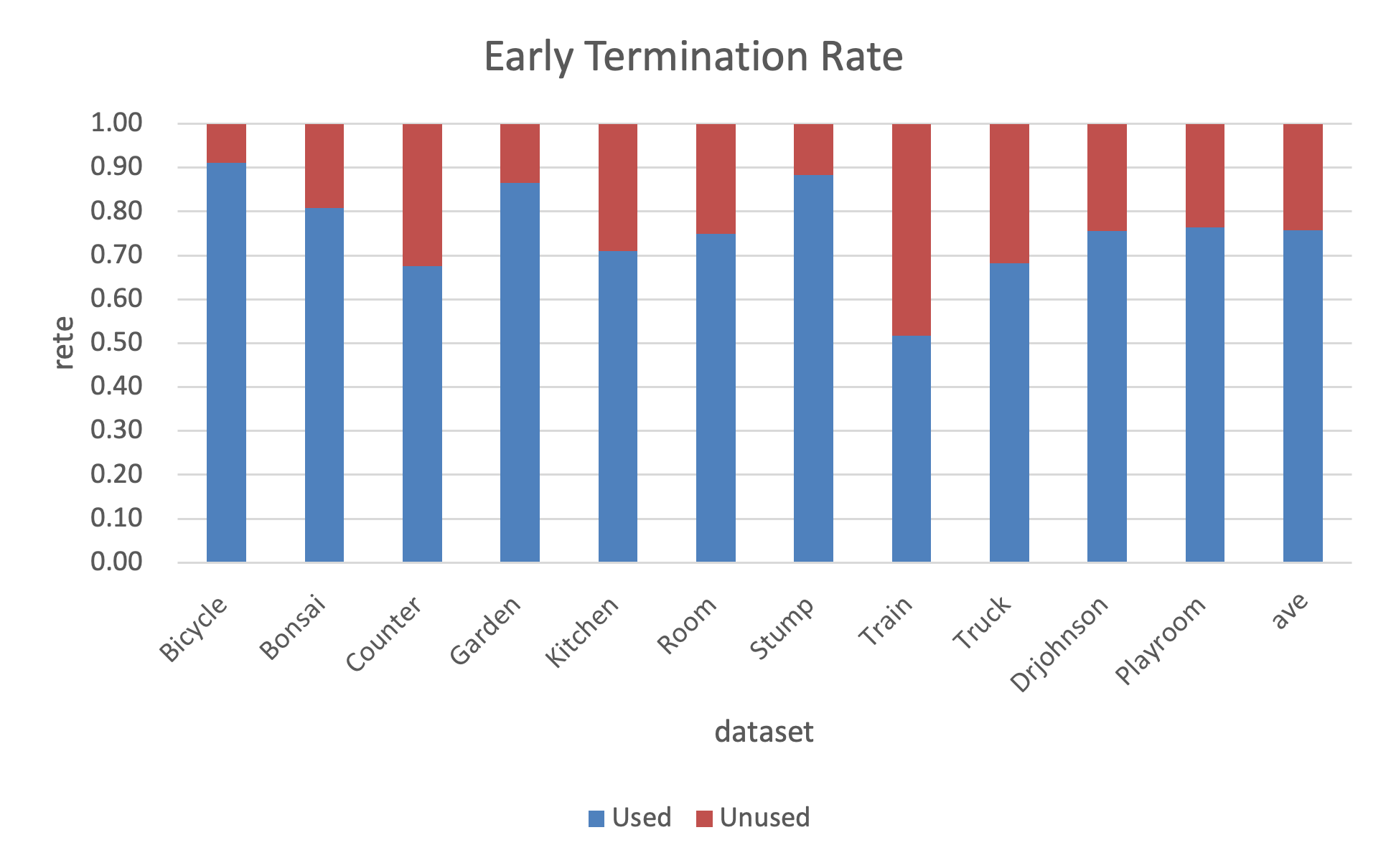
Figure 6: Early termination rate analysis post-compression shows further compute savings.
Timing and Pipeline
The datapath is organized as a frame-level pipeline: preprocessing (culling, projection) operates point-wise, while rendering is tile-wise. This matches statistical workload characteristics and removes unnecessary synchronization.
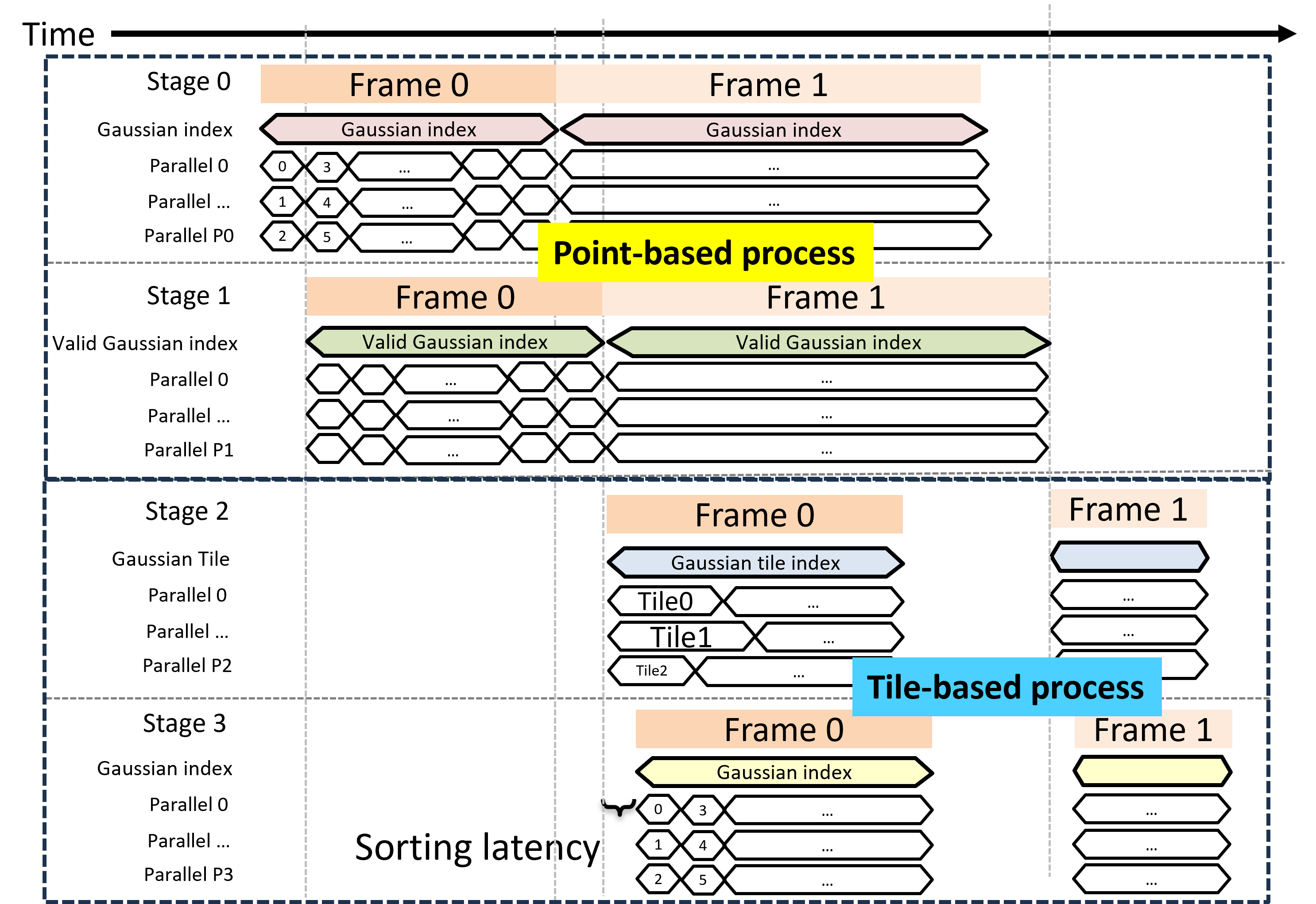
Figure 7: Timing diagram of the proposed pipeline: point-based preprocessing followed by tile-parallel rendering.
Empirical Evaluation
Visualization and Perceptual Quality
Visual inspection confirms that, despite aggressive compression, the rendered results preserve global appearance and exhibit only minor degradation in local high-frequency structure.






Figure 9: Visual comparison—top to bottom: ground truth, standard 3DGS, compressed model. Global fidelity preserved, with tolerable local smoothing.
Numerical Results
Compression and Fidelity
| Model Variant |
Compression |
PSNR (dB) |
SSIM |
LPIPS |
| Baseline 3DGS |
1× |
26.9 |
0.832 |
0.214 |
| Pruned |
5.8× |
27.1 |
0.824 |
0.244 |
| SH+VQ |
51.6× |
26.2 |
0.810 |
0.259 |
Overall, the fully compressed model achieves substantial size reduction with only a minor tradeoff in PSNR and LPIPS.
| Design |
Area (mm²) |
FPS (1080p) |
Power (W) |
Throughput (Mpixels/s) |
Energy Eff. (Gpixels/W) |
| Proposed |
0.66 |
129 |
0.219 |
267.5 |
1.2 |
| GSCore [gscore] |
3.95 |
182 (@800×600) |
0.87 |
87 |
0.1 |
| GSNorm [gsnorm] |
2.48 |
94.6 |
0.284 |
45 |
0.159 |
The proposed solution is 5.98× smaller in area, ~6× higher in throughput, and 7.5× more efficient in energy than the previous state-of-the-art accelerators.
Ablation Studies
Sequential ablation shows throughput gains from culling, zero-skipping, and early termination, together responsible for a net increase from 20.4 FPS (baseline) to 129 FPS.
Justification for Aggressive Compression
An analysis demonstrates that without such aggressive compression, power consumption would easily exceed 0.8 W—problematic for intended low-power edge deployment. Thus, the compression pipeline is not optional but fundamental to the solution.
Implications and Future Directions
The demonstrated co-design approach addresses both theoretical and practical challenges of 3DGS deployment on edge devices. By linking the compression schedule to hardware-friendly forms, the paper effectively bridges model representation and accelerator constraints. The deterministic tile-based pipelines, comparison-free sorting, and global/local memory partitioning propose new architectural paradigms for structured, large-scale sparse point cloud rendering.
Practically, such techniques enable interactive applications—AR/VR, telepresence, and photorealistic scene streaming on mobile devices—where battery and silicon area are critical. The framework can guide future accelerators for other point-based or grid-based neural scene representations, and the memory-friendly compaction methodology can generalize to other radiance field approaches.
Theoretically, the results suggest that smart structural priors (e.g., compression-aware training, SH reduction, and culling policies) are pivotal for scalable neural rendering under strict hardware and power constraints.
Conclusion
The paper systematically tackles the deployment of 3D Gaussian Splatting for real-time, full-HD rendering on edge platforms by combining hardware-aware model compression with a low-power accelerator architecture. The approach achieves unprecedented compression (51.6×), minimal perceptual loss (~0.7 dB PSNR), and state-of-the-art energy and area metrics, supporting sustained 129 FPS at 1080p within 0.22 W and 0.66 mm². This enables, for the first time, practical integration of high-fidelity neural rendering in AR/VR-class devices, and marks a significant direction for further research in hardware-algorithm co-design for real-time graphics.