- The paper introduces a novel GEMM-compatible reformulation of the 3D Gaussian Splatting blending stage to fully utilize Tensor Cores.
- It details a CUDA-based, double-buffered kernel design that overlaps computation and memory access for enhanced throughput.
- Empirical results demonstrate speedups of up to 1.73× over vanilla 3DGS, enabling more efficient real-time neural rendering.
GEMM-GS: Enabling Tensor Core Acceleration for 3D Gaussian Splatting
Introduction
3D Gaussian Splatting (3DGS) has emerged as a leading explicit scene representation approach for neural rendering, addressing limitations of sampling-based Neural Radiance Fields (NeRF) by improving both rendering quality and throughput. Yet, while 3DGS significantly reduces practical rendering latency compared to NeRF, it remains insufficient for demanding real-time applications, especially as scene complexity and output resolutions scale. The predominant bottleneck in 3DGS is the pixel-wise blending phase, which remains ill-suited to fully exploit the matrix-multiplication-oriented Tensor Cores of contemporary GPUs.
GEMM-GS introduces a novel reformulation of the 3DGS blending pipeline, recasting blending as a GEMM-compatible operation. This architectural re-design enables direct scheduling of the most computationally expensive stage onto the high-throughput Tensor Cores, maximizing their utilization on modern hardware such as NVIDIA's Ampere and Hopper series. GEMM-GS further incorporates an optimized CUDA implementation featuring a three-stage, double-buffered kernel to efficiently overlap computation and memory access.
Background and Motivation
Neural Rendering Progression
NeRF established the paradigm of implicit scene representation, reconstructing high-fidelity 3D scenes and synthesizing novel views via point sampling and neural inference. However, coherent with prior benchmarks, NeRF's runtime is dominated by its extensive density/color queries, making it impractical for real-time tasks in AR/VR and interactive 3D systems.
3DGS shifts to an explicit point-based representation, modeling scenes with million-scale sets of 3D Gaussians fitted to the underlying geometry and appearance. The overall 3DGS pipeline entails four main stages: (1) preprocessing and projection of Gaussians; (2) duplication for parallelism; (3) sorting by depth within tiles; and (4) per-pixel blending for final image synthesis.
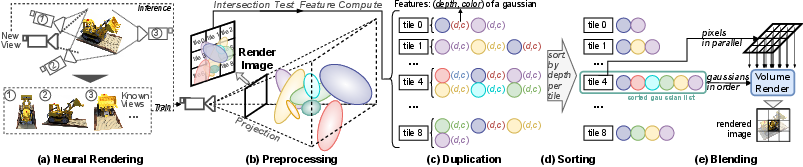
Figure 1: Neural rendering pipeline and process of 3D Gaussian Splatting, delineating the principal pipeline stages from Gaussian projection to parallel blending.
Despite streamlining preprocessing and leveraging explicitness, blending remains the dominant latency contributor within 3DGS, accounting for up to 70% of the total rendering time across diverse datasets and scenes.
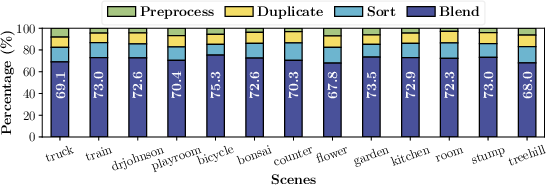
Figure 2: Rendering latency breakdown of 3DGS, highlighting the overwhelming cost of the blending stage across various datasets.
Underutilization of Tensor Cores
A significant yet underexploited resource in current GPU architectures is the Tensor Core subsystem, capable of performing dense GEMM operations at multi-teraflop rates. As shown in hardware profiling (Figure 3), Tensor Cores can deliver over 30× the raw compute throughput of scalar CUDA cores for compatible workloads. However, the legacy 3DGS pipeline does not expose GEMM operations in its pixel-wise blending computation, rendering the bulk of this hardware resource idle.
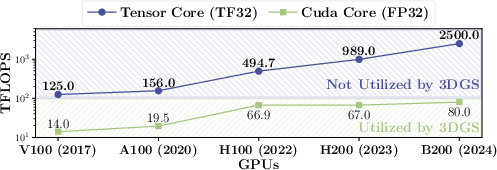
Figure 3: Computing power breakdown of modern GPUs with respect to kernel utilization in 3D Gaussian Splatting workflows.
The absence of matrix operations within standard 3DGS is therefore a key opportunity for redesign.
GEMM-GS: Methodology and Kernel Design
The central contribution in GEMM-GS is the derivation of a mathematically equivalent formulation of Gaussian opacity computation, restructuring it to fit the dot-product and batched-matrix-multiplication archetype required for Tensor Core execution. Rather than computing per-pixel, per-Gaussian quadratic expressions directly, GEMM-GS leverages intra-tile relative coordinates and parameter grouping to encode the opacities as six-dimensional inner products:
powerij=vgi⊤vpj
Here, vgi encodes the Gaussian's parameters and position relative to a reference tile pixel, and vpj encodes per-pixel positional terms. These vpj vectors are invariant across tiles and amenable to offline precomputation.
This enables the batch processing of all Gaussian–pixel pairs in a tile as a single GEMM operation, mapping precisely to Tensor Core primitives for maximal throughput.
GPU Kernel Implementation
GEMM-GS's CUDA kernel employs a three-stage double-buffered pipeline:
- Loading: Gaussian indices required for the current tile batch are fetched asynchronously into shared memory buffers.
- Matrix Construction: Each thread computes a row of the Mg Gaussian parameter matrix.
- Matrix Multiplication and Rendering: GEMM is invoked (16×8 mini-batching due to shared memory constraints) via PTX warp-level mma instructions, producing the power matrix Mpower. These powers are exponentiated and incorporated in the volumetric blending, exactly matching the original 3DGS rendering semantics but at substantially higher arithmetic intensity.
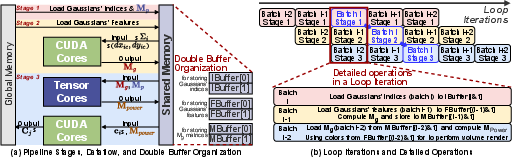
Figure 4: High-performance GPU kernel pipeline of GEMM-GS, detailing the three-stage design and timing of overlapped memory and compute stages.
Double-buffering allows asynchronous data fetch and matrix construction in parallel with ongoing GEMM computation, eliminating global barriers and minimizing memory stalls.
Experimental Results
Throughput Comparison
Empirical evaluation of GEMM-GS, both stand-alone and integrated with prior state-of-the-art 3DGS acceleration methods, demonstrates robust and consistent throughput improvements:
Resolution and Batch Size Scalability
GEMM-GS preserves and amplifies its advantages as scene resolution increases. When evaluated at 2× and 3× image resolutions, speedups remain stable (~1.73×), confirming high arithmetic intensity scaling and suitability for large-scale or VR rendering.

Figure 6: Latency scaling of GEMM-GS vs. vanilla 3DGS under increasing image resolution.
For tile batch sizes below 256, latency climbs due to underutilization of available GPU threads, but GEMM-GS maintains a lead in all regimes.
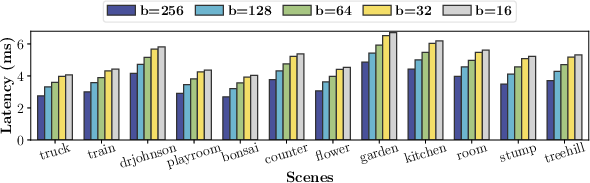
Figure 7: Latency scaling with variable batch sizes, demonstrating GEMM-GS efficiency in parallel workloads.
Practical and Theoretical Implications
GEMM-GS's formulation is orthogonal to both preprocessing and compression strategies, making it compatible as an incremental improvement for any current or future 3DGS variant. Its fully software-based pipeline ensures immediate deployability on commodity GPUs without hardware or model retraining requirements. This directly benefits real-time AR/VR, digital twin visualization, and cloud rendering pipelines, simultaneously maximizing hardware investment via rapid Tensor Core saturation.
Theoretically, GEMM-GS exemplifies how canonical volume rendering and point splatting operations, long assumed incompatible with dense linear algebra acceleration, can be reformulated for modern hardware. This methodology invites similar reinterpretations for other non-GEMM-centric computer graphics operations, particularly as hardware trends continue to favor large-scale matrix multiplication.
As scene complexity and model density further increase, the importance of hardware-congruent algorithm design will only rise. Extensions of this approach to foveated rendering, dynamic scene updates, or generalized point-based rendering may prove particularly fruitful.
Conclusion
GEMM-GS presents an explicit and architecture-aware strategy for accelerating 3D Gaussian Splatting by harnessing the underutilized Tensor Cores of modern GPUs, reformulating the bottleneck blending operation as a matrix multiplication for maximal hardware efficiency. Demonstrated by strong speedups across multiple datasets, model types, and hardware generations, GEMM-GS stands as a robust and generalizable improvement to the 3DGS rendering pipeline. Its broad compatibility and software-first design position it as a practical solution for large-scale neural rendering deployments and a template for further hardware-monolithic redesigns in computational graphics and AI-driven rendering.
