- The paper introduces a traversal-free, GPU-optimized parallel filtering architecture combined with adaptive Gaussian shrinking, reducing filter time by up to 5× with less than 1% quality loss.
- It eliminates depth dependencies and redundant Gaussian-tile pairs by leveraging a two-step filter that uses content-aware metrics (KPC and GTC) for precise scene culling.
- The system boosts rendering throughput with over 200% FPS improvement and removes up to 75% redundant key-value pairs, setting a new benchmark for real-time 3D scene rendering.
FilterGS: Traversal-Free Parallel Filtering and Scene-Adaptive Shrinking for Large-Scale LoD 3D Gaussian Splatting
Introduction
Efficient large-scale neural scene rendering with high-fidelity geometry and appearance remains bottlenecked by the exponential growth in Gaussian primitives required by 3D Gaussian Splatting (3DGS) frameworks. Level-of-Detail (LoD) methods partially mitigate this problem by hierarchical Scene representation and culling. However, contemporary LoD-3DGS methods are fundamentally constrained by two inefficiencies: slow serial hierarchy traversal during filtering and an excess of redundant Gaussian-tile key-value pairs, each significantly degrading frame rates and impeding real-time deployment. FilterGS introduces a GPU-optimized parallel filtering architecture, eliminating depth dependencies and unlocking massive SIMD acceleration, alongside a GTC-guided, content-aware Gaussian shrinking mechanism targeting pre-rasterization redundancy. The result is a decisive improvement in rendering throughput without perceptual compromise in reconstruction quality.
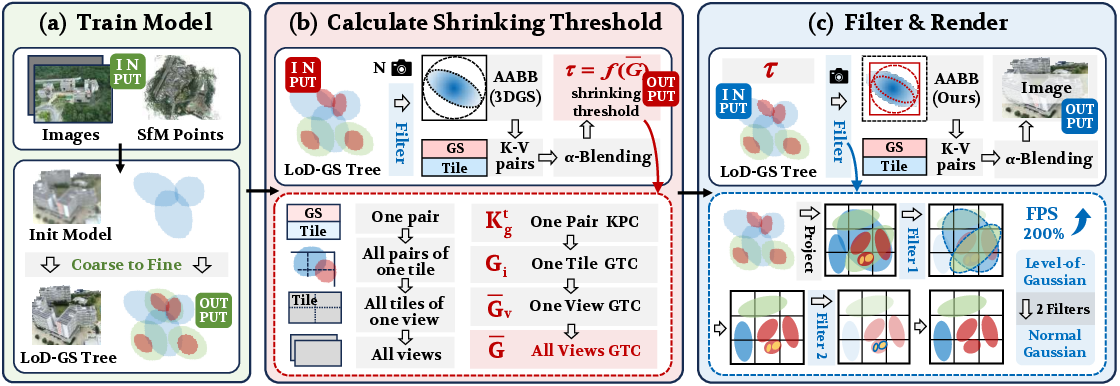
Figure 1: The framework of FilterGS, integrating parallel filtering and scene-adaptive Gaussian shrinking, dramatically boosts rendering efficiency while preserving reconstruction fidelity for large-scale LoD 3DGS scenes.
Methodology
Hierarchical Gaussian Structures in LoD-3DGS
Hierarchical LoD-3DGS models organize scene elements as trees, with each node a Gaussian primitive holding center, covariance, color, and opacity parameters. Coarse-to-fine subdivision proceeds recursively, creating a multiresolution space–geometric hierarchy, and supporting direct rasterization at selected detail levels. This node structure forms the basis for FilterGS’s invariant filtering and redundancy elimination strategies.
Traversal-Free Parallel Filtering
FilterGS’s core acceleration stems from two orthogonal filters:
(1) R{content}L Filter:
Each in-frustum node projects to 2D; if its screen-space radius is below a fixed threshold, it is retained for rasterization. Crucially, all leaves are always retained to guarantee branch coverage and avoid geometric holes.
(2) Ancestor Filter:
To eliminate redundant multi-level Gaussian rasterization, the filter traverses each selected node’s ancestor path (precomputed for each node). If any ancestor is also selected, the current node is culled. This ensures that only the coarsest sufficient node on each branch is retained, removing unnecessary fine-scale processing.
All nodes across all hierarchy levels are processed in a single CUDA kernel, decoupling runtime from tree depth and eliminating levelwise GPU synchronization. This parallel paradigm unlocks near-linear scaling in Gaussian count, in contrast to the classic O(L) depth-scaling in serial methods.
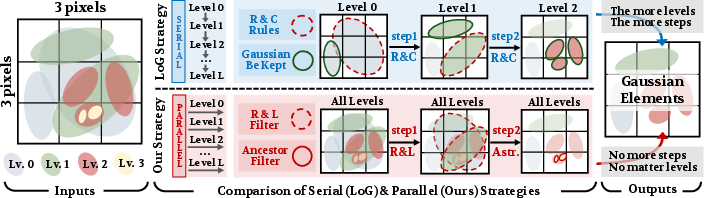
Figure 2: Serial versus parallel filtering: FilterGS's two-step, depth-independent parallel filtering eliminates levelwise passes entirely, in contrast to serial LoD filtering.
Scene-Adaptive Gaussian Shrinking
While LoD culling reduces the primitive count, rasterization remains bottlenecked by surplus Gaussian-tile pairs, with >70% being redundant in large-scale settings. FilterGS introduces a set of quantitative metrics for targeted elimination:
- Key-value Pair Contribution (KPC): For each Gaussian-tile pair, the sum across pixels of the blended opacity and transmittance; pairs with KPC below a threshold are deemed redundant.
- Gaussian to Tile Contribution (GTC): The average KPC per tile, measuring local Gaussian congestion; scene-wide mean GTC quantifies the global redundancy state.
A scene-adaptive pruning threshold τ is computed inversely proportional to the mean GTC, modulated by an aggressiveness parameter λG (see Figure 3). This adaptive pruning automatically intensifies in highly congested scenes, maximizing efficiency gains while leaving visually salient regions intact.
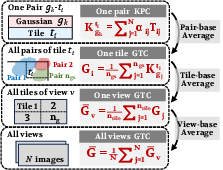
Figure 3: Progressive relationships between KPC, GTC, view-level averaging, and scene-adaptive thresholding in the FilterGS pruning pipeline.
Experimental Results
Throughput, Quality, and Ablations
FilterGS demonstrates superior Gaussian filtering efficiency—preparation time cut from ∼10ms (state-of-the-art LoG/OctreeGS) to just ∼1ms, and filtering FPS improvement consistently exceeding 200%. The combination with scene-adaptive shrinking delivers further speedups (>20%) while incurring minimal PSNR/SSIM degradation (<1% across all benchmarks).
Ablation isolates the individual impact of parallel filtering and shrinking. Parallel filtering alone delivers a 3–5× reduction in filter time with no loss in rendered quality, while adaptive shrinking provides the dominant reduction in Gaussian-tile pairs—removing up to 75% of redundant pairs in FilterGS, as confirmed by empirical KPC distributions.

Figure 4: Shrinking strategies compared on College and Modern-Building scenes: GTC-guided adaptive shrinking yields major pair count reduction with negligible perceptual impact.
Memory overhead for ancestor-path indexing (enabling the filter’s two-step operation) is a moderate 20% of the original LoD tree, a manageable cost for the net gains in throughput.
Efficiency–Quality Trade-Off Tuning
The aggressiveness of shrinking (λG) governs the fidelity–efficiency regime. With λG in [0.03,0.2], FilterGS attains a regime where a 1% drop in PSNR correlates to a 20% boost in FPS, which can be tuned dynamically for application-specific performance targets.
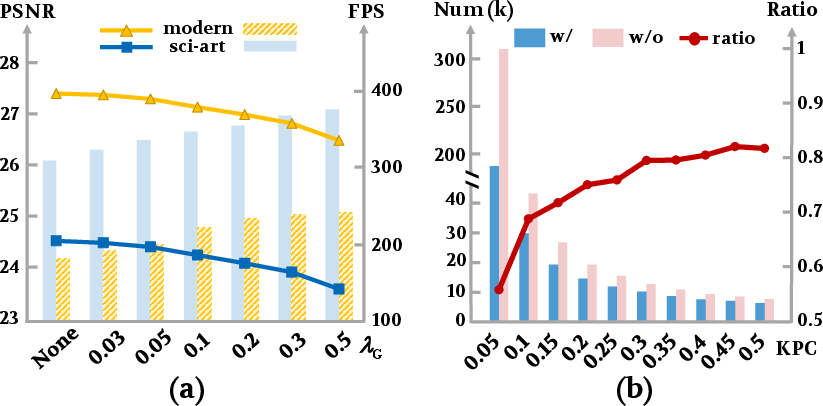
Figure 5: The trade-off between PSNR and FPS as a function of the shrinking aggressiveness parameter λG.

Figure 6: Visualization of the shrinking effect on key-value pruning and rendering details, illustrating selective redundancy elimination in low-frequency regions, with high-frequency structure preserved.
Implications and Future Directions
FilterGS’s traversal-free, parallel filtering paradigm defines a new standard for LoD-3DGS culling, particularly impactful for GPU architectures with massive parallelism. The adaptive shrinking pipeline’s GTC-based decision-making indicates a move toward content-adaptive acceleration strategies—generalizable to hybrid scene representations, dynamic LoD adjustment, and on-device/neural rendering scenarios with strict latency constraints.
Future research might extend the GTC metric for unified view- and object-dependent LoD, integrate multi-modal cues for more principled redundancy estimation, or explore hardware co-design for even richer intraframe and interframe parallelism.
Conclusion
FilterGS overcomes the dual bottlenecks of serial filtering and rasterization redundancy in LoD-3DGS by introducing a level-agnostic, massively parallel filtering mechanism and a GTC-guided, scene-adaptive Gaussian shrinking strategy. The resulting pipeline matches or exceeds state-of-the-art neural rendering efficiency, providing real-time throughput on large-scale urban and natural datasets with minimal perceptual compromise. This architecture establishes a foundation for the next generation of large-scale, real-time 3D scene understanding and neural rendering systems (2603.23891).