- The paper introduces the ChangAn benchmark to differentiate between human and LLM-generated classical Chinese poetry.
- It evaluates both decision- and probability-based detection methods, highlighting significant accuracy gaps and detector limitations.
- Aggregating multiple poems boosts detection performance, though critique-driven refinement blurs statistical signals markedly.
Evaluating the Detection of LLM-Generated Classical Chinese Poetry: An Analysis of the ChangAn Benchmark
Introduction and Motivation
The paper "Who Wrote This Line? Evaluating the Detection of LLM-Generated Classical Chinese Poetry" (2604.10101) addresses the emergent need to discriminate between human-authored and LLM-generated classical Chinese poetry. The proliferation of high-fidelity generative models, whose textual outputs closely mimic human linguistic and stylistic markers, has precipitated both practical and ethical concerns regarding creative authenticity, particularly in culturally significant and highly formalized genres such as classical poetry. Existing research has concentrated predominantly on contemporary languages or more open-form literary genres, leaving a gap in the forensic analysis of classical Chinese poetry, which features condensed syntax, shared imagery, and rigorous formal constraints that confound conventional detection approaches.
Construction and Features of the ChangAn Benchmark
The core contribution is the introduction of the ChangAn dataset, a comprehensive benchmark specifically curated for the detection of LLM-generated classical Chinese poetry. With 30,664 total poems—10,276 written by 282 modern human authors and 20,388 produced by four representative LLMs (DeepSeek-V3.2, GPT-4.1, Kimi-K2, Doubao Seed-1.6)—the dataset ensures diversity in style, topic, and adherence to poetic convention. To avoid confounds from memorization effects on existing corpora, the human examples are drawn solely from modern poets and verified enthusiasts, not canonical ancient collections, and all sources are openly attributed for intellectual transparency.
The benchmark formalizes two axes of evaluation:
- Text Granularity: Single-Poem Detection (SPD) versus Multi-Poem Detection (MPD), with sets of 6 and 12 poems for MPD to mirror actual publication patterns and increase discriminative feature density.
- Generation Strategy: Direct generation from LLMs and critique-driven refinement, where models iteratively improve drafts via self-critique prompts, simulating interactive human creativity.
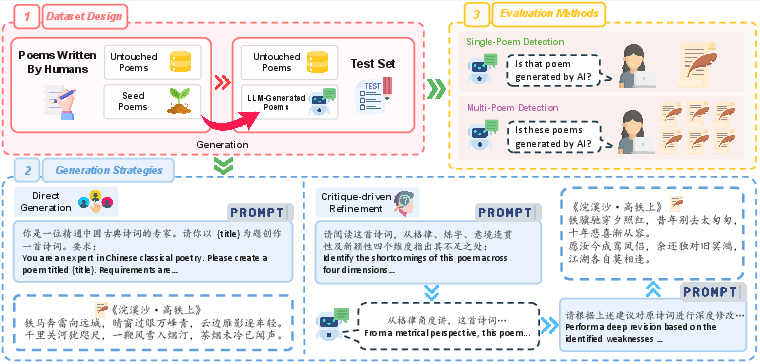
Figure 1: The overall structure of the ChangAn benchmark encapsulates collection, LLM prompting, critique-driven refinement, and detector evaluation pipeline.
Systematic Evaluation of Detection Methods
The paper conducts a comprehensive empirical assessment of both decision-based and probability-based AI detectors. The tested detectors include major open-domain LLMs (e.g., GPT-4.1, DeepSeek-V3.2), classical text-specific classifiers (LLM-Detector-Small-zh), statistical baselines (Log-Likelihood, Log-Rank, LRR), supervised classifiers (fine-tuned Roberta), and recent zero-shot detectors (Fast-DetectGPT, AIGC-Detector-v3).
Decision-based detectors exhibit poor discriminative capacity in the SPD scenario, with accuracy near random chance and a marked tendency to misclassify both AI-generated and human-written examples as human-authored. Even language-specific detectors do not generalize effectively under the formal and lexical constraints imposed by classical poetic forms.
Probability-based detectors achieve moderate success; log-likelihood and log-rank measures yield AUROC values >80%, while a fine-tuned Chinese Roberta achieves a notably high AUROC of 95.03%. However, Fast-DetectGPT fails completely, confirming that its foundation on local curvature in token probabilities does not transfer to highly templatic, metrically-regulated text with a restricted token set.
Detection difficulty is significantly exacerbated by critique-driven refinement. For instance, the average AUROC of probability-based detectors drops by nearly 10 percentage points when moving from direct generation to critique-refined examples, indicating that refinement substantially obfuscates statistical artifacts typical of vanilla LLM outputs.
Text Granularity and Aggregated Detection
A critical finding is the dramatic improvement in detection performance as more poems per author or set are aggregated. MPD with 6 or 12 poems delivers sharp increases in accuracy and recall (more than 20 percentage points over SPD), but this benefit exhibits diminishing returns as set size increases beyond six poems.
This effect is hypothesized to result from the greater stylistic and structural feature density in larger sets, which allows robust pattern-matching or supervised models to "average out" the stochastic surface mimicry of LLMs and instead capture subtle but consistent stylistic irregularities in AI productions.
Cross-Model Analysis and Self-Recognition Capacity
Surprisingly, the evaluated LLMs—when deployed as zero-shot detectors—show near-total inability to recognize their own generated poems. Unlike detection of general AI-generated text, where self-recognition bias has been documented, here the poetic forms appear to mask any robust “identity signal” even from the originating model. This suggests that the intersection of pretraining on culturally dominant motifs and the dense formal regularity of classical poetry further erodes any detectable signature of AI authorship at the model-internal level.
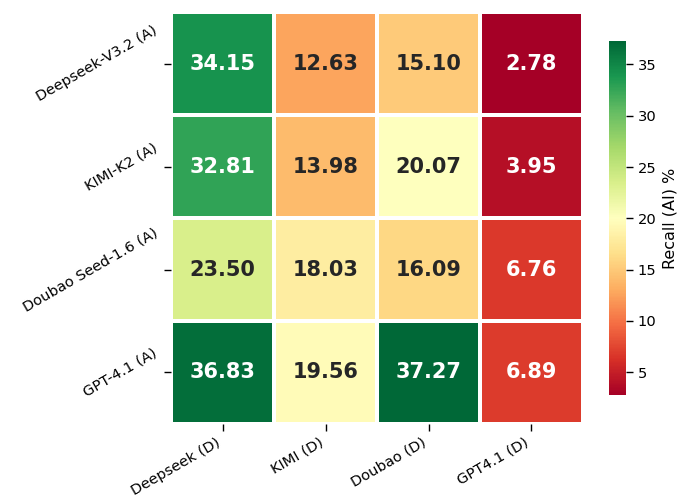
Figure 2: Cross-model recall for poetry detection highlights the equivalently poor self-recognition performance across all LLMs, with no discernible intra-class advantage.
Lexical, Semantic, and Stylistic Insights
Qualitative and quantitative analyses dissect the overlap and residual divergences in poetic diction between humans and LLMs. Both human and AI-generated poems share a common high-frequency imagery set, indicative of classical poetic tradition mastery by LLMs. However, detailed semantic clustering exposes pockets of human-only compositions with richer biological lexicons, idiosyncratic micro-actions, and non-formulaic narrative structure—features that remain challenging for contemporary generative models to replicate.
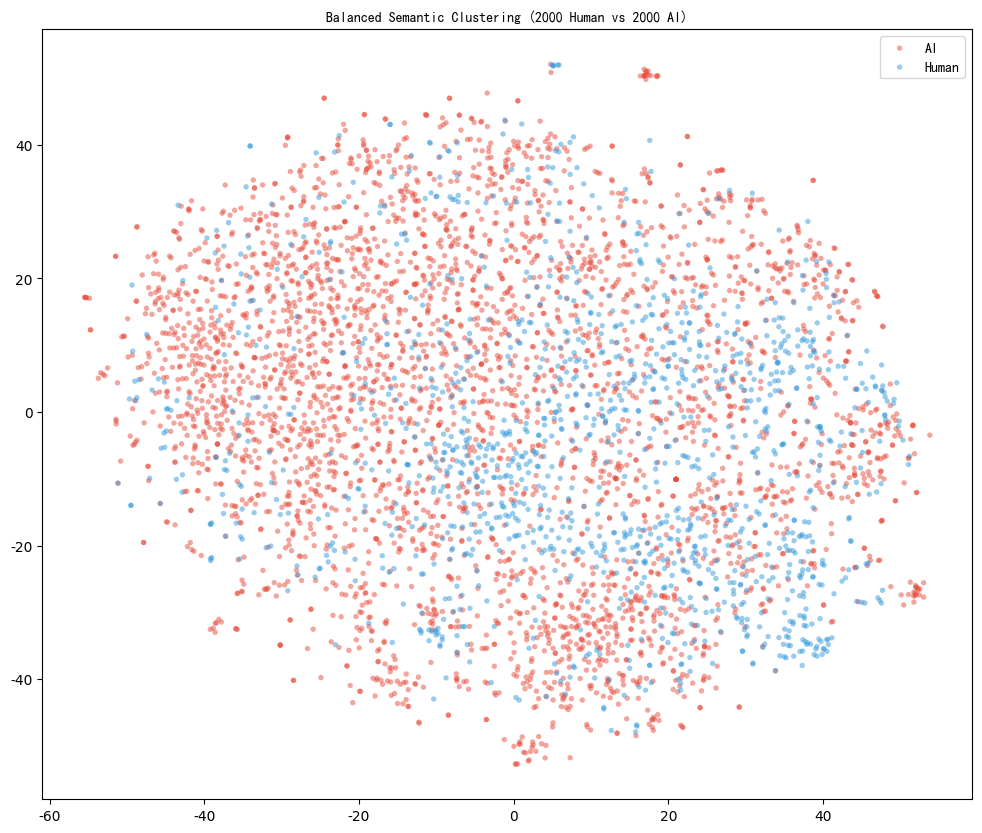
Figure 3: Embedding-based semantic clustering distinguishes between human and AI poetry, revealing human-exclusive regions tied to narrative specificity and lexical novelty.




Figure 4: Distribution of short imagery words in human-written poetry shows denser and more contextually rich vocabulary compared to more templatic AI generations.
Implications, Theoretical Reflections, and Future Directions
The results demonstrate both the efficacy and limitations of current detection paradigms in highly systematic, culturally entrenched genres like classical Chinese poetry. They expose the rapid convergence of LLM outputs to the stylistic mean of the training data, saturation of detection performance with increased text quantity, and the ability of critique-driven refinement to adversarially “wash out” discriminative signals.
From a theoretical perspective, these findings challenge the sustainability of content authentication based on simple statistical and pattern-based approaches in literary and creative domains. They highlight the necessity of purpose-built style and semantic-depth detectors, potentially using cross-modal or authorship-linked signals beyond pure text statistics.
For practice, the inability of either humans or state-of-the-art detectors to reliably discern AI authorship in classical poetry raises urgent concerns for intellectual property, authenticity certification, and the integrity of literary attribution in the digital era.
Conclusion
This work establishes a foundational resource—the ChangAn benchmark—for systematic research into AI-authorship detection in classical Chinese poetry. Experimental results reveal substantive weaknesses in both human and automated detection, particularly under adversarial refinement. The study suggests an urgent need for next-generation detection models that integrate deeper semantic modeling, incorporate broader contextual and cross-authorial cues, and resist adversarial attacks. ChangAn will serve as a critical testbed for subsequent advances in content authenticity for high-form creative AI outputs.